You might also like
- RP 8Document7 pagesRP 84NM21CS114 PRATHAM S SHETTYNo ratings yet
- Genomics For BeginnerDocument9 pagesGenomics For BeginnerludhangNo ratings yet
- Scaling Computation and Memory in Living Cells: SciencedirectDocument9 pagesScaling Computation and Memory in Living Cells: SciencedirectShampa SenNo ratings yet
- Comparison of High Throughput Next GenerDocument12 pagesComparison of High Throughput Next GenerAni IoanaNo ratings yet
- Next-Generation DNA Sequencing MethodsDocument18 pagesNext-Generation DNA Sequencing MethodsFederico BerraNo ratings yet
- Biotechnology Journal - 2019 - OliveiraDocument6 pagesBiotechnology Journal - 2019 - OliveiraSubash KhanNo ratings yet
- Bioinformatics Thesis DownloadDocument8 pagesBioinformatics Thesis Downloadkatrinagreeneugene100% (2)
- Recent Developments in The Monitoring, Modeling and Control of Biological Production SystemsDocument5 pagesRecent Developments in The Monitoring, Modeling and Control of Biological Production SystemsGabriel PatrascuNo ratings yet
- Shannon 2003 CytoscapeDocument8 pagesShannon 2003 Cytoscapehurdur321No ratings yet
- Integrative Work Ows For Metagenomic Analysis: Frontiers in Cell and Developmental Biology November 2014Document12 pagesIntegrative Work Ows For Metagenomic Analysis: Frontiers in Cell and Developmental Biology November 2014airsrchNo ratings yet
- Contoh Essay Biologi MolekulerDocument4 pagesContoh Essay Biologi MolekulerImam Taufiq RamadhanNo ratings yet
- E VITTADocument9 pagesE VITTA809600520No ratings yet
- Calero, 2018 - Review 2Document27 pagesCalero, 2018 - Review 2Eduardo Alonso Lopez OrnelasNo ratings yet
- Biosecurity Challenges PDFDocument5 pagesBiosecurity Challenges PDFValentina BetancourtNo ratings yet
- Combining LIANA and Tensor-Cell2cell To Decipher Cell-Cell Communication Across Multiple SamplesDocument39 pagesCombining LIANA and Tensor-Cell2cell To Decipher Cell-Cell Communication Across Multiple SamplesNateNo ratings yet
- Synthetic Genomes: Technologies and Impact: December 2004Document10 pagesSynthetic Genomes: Technologies and Impact: December 2004Sir TemplarNo ratings yet
- Benchmarking Metagenomic Classification ToolsDocument27 pagesBenchmarking Metagenomic Classification ToolsemilioNo ratings yet
- A Systems-Level Approach For Metabolic Engineering of Yeast Cell FactoriesDocument21 pagesA Systems-Level Approach For Metabolic Engineering of Yeast Cell FactoriesFernando Alexis Gonzales ZubiateNo ratings yet
- Bioprepardeness BrochureDocument4 pagesBioprepardeness BrochureGilbert MethewNo ratings yet
- 1324177.1324178Document32 pages1324177.1324178TeferiNo ratings yet
- Dissecting Complexity The Hidden Impact of ApplicaDocument26 pagesDissecting Complexity The Hidden Impact of ApplicaNealNo ratings yet
- High-Level Synthesis of Digital Microfluidic BiochipsDocument32 pagesHigh-Level Synthesis of Digital Microfluidic Biochipsmescribd11No ratings yet
- CG 14 11 PDFDocument14 pagesCG 14 11 PDFGlauce L TrevisanNo ratings yet
- Programming and Systems Biology: HapterDocument9 pagesProgramming and Systems Biology: HapterkofirNo ratings yet
- Bio in For Ma TicsDocument8 pagesBio in For Ma TicsAdrian IvanNo ratings yet
- Amrita 2021 ONTbarcoder & MinIONDocument20 pagesAmrita 2021 ONTbarcoder & MinIONabedoyag01No ratings yet
- Bio in For Ma TicsDocument26 pagesBio in For Ma Ticscsonu2209No ratings yet
- How The Bio Revolution Could Transform The Competitive LandscapeDocument10 pagesHow The Bio Revolution Could Transform The Competitive Landscapeh5wwgbvbvmNo ratings yet
- Bio in For MaticsDocument4 pagesBio in For MaticsHarfebi FryonandaNo ratings yet
- MycoBank Gearing Up For New HorizonsDocument9 pagesMycoBank Gearing Up For New HorizonsjdfNo ratings yet
- Bioinformatics PaperDocument8 pagesBioinformatics PaperrashigaurNo ratings yet
- Msystems 00895-20Document12 pagesMsystems 00895-20gorkhmazabbaszadeNo ratings yet
- Smith 2015Document10 pagesSmith 2015László SágiNo ratings yet
- Sqmtools: Automated Processing and Visual Analysis of 'Omics Data With R and Anvi'ODocument11 pagesSqmtools: Automated Processing and Visual Analysis of 'Omics Data With R and Anvi'OshanmugapriyaNo ratings yet
- Concurrency and Computation - 2020 - Debauche - Cloud Architecture For Plant Phenotyping ResearchDocument16 pagesConcurrency and Computation - 2020 - Debauche - Cloud Architecture For Plant Phenotyping Researchhema3rNo ratings yet
- Bio in For Ma TicsDocument52 pagesBio in For Ma TicsSwapnesh SinghNo ratings yet
- Bioinformatics: Major Research AreasDocument2 pagesBioinformatics: Major Research AreasHanumant SuryawanshiNo ratings yet
- RP 6Document13 pagesRP 64NM21CS114 PRATHAM S SHETTYNo ratings yet
- Microelectronic Engineering: SciencedirectDocument15 pagesMicroelectronic Engineering: SciencedirectIvana Gadjanski StanićNo ratings yet
- Advancing the Metagenomics Revolution Through CAMERA 2.0Document23 pagesAdvancing the Metagenomics Revolution Through CAMERA 2.0Suresh ReddyNo ratings yet
- 1 s2.0 S0167739X19318230 MainDocument23 pages1 s2.0 S0167739X19318230 MainAnggaNo ratings yet
- Computer Networks: Falko Dressler, Ozgur B. AkanDocument20 pagesComputer Networks: Falko Dressler, Ozgur B. AkanIşık DemetiNo ratings yet
- Enabling Large-Scale Biomedical Analysis in The Cloud: Biomed Research International October 2013Document7 pagesEnabling Large-Scale Biomedical Analysis in The Cloud: Biomed Research International October 2013Camilo RestrepoNo ratings yet
- Bio in For Ma TicsDocument7 pagesBio in For Ma TicsHarshit TayalNo ratings yet
- Bioinformatics: Tina Elizabeth VargheseDocument9 pagesBioinformatics: Tina Elizabeth VargheseAnnonymous963258No ratings yet
- Genome Res.-2003-Shannon-2498-504Document8 pagesGenome Res.-2003-Shannon-2498-504Syed Shayan ZiaNo ratings yet
- SETR 02: Biotechnology and Synthetic BiologyDocument13 pagesSETR 02: Biotechnology and Synthetic BiologyHoover InstitutionNo ratings yet
- Bioinformatics OverviewDocument18 pagesBioinformatics OverviewBrijesh Singh YadavNo ratings yet
- Thacker - Bioinformatics and Bio-LogicsDocument31 pagesThacker - Bioinformatics and Bio-Logicsantonio damataNo ratings yet
- Research Paper About Anti VirusDocument8 pagesResearch Paper About Anti Virusgvzexnzh100% (1)
- Machine Learning Tools: (Scherf Et. Al. 2005)Document1 pageMachine Learning Tools: (Scherf Et. Al. 2005)SrinivasNo ratings yet
- BIO401 Wikipedia Bioinformatics 2.7.2012Document9 pagesBIO401 Wikipedia Bioinformatics 2.7.2012kinjalpcNo ratings yet
- Shean19 VaPID RefthroughGeneBankDocument8 pagesShean19 VaPID RefthroughGeneBankAnh H NguyenNo ratings yet
- Artigo BioinformaticaDocument8 pagesArtigo BioinformaticaRodolfoMadNo ratings yet
- What is BioinformaticsDocument6 pagesWhat is BioinformaticsvisiniNo ratings yet
- #157 Green-JDocument10 pages#157 Green-JekaphrpNo ratings yet
- Bioinformatics - Group21 - Report - Application of Bioinformatics in AgricultureDocument11 pagesBioinformatics - Group21 - Report - Application of Bioinformatics in AgricultureHuỳnh NhưNo ratings yet
- Roux14 MetaVir2AssembledViromeAnalysisDocument12 pagesRoux14 MetaVir2AssembledViromeAnalysisAnh H NguyenNo ratings yet
- Ch1 Bioinformatics... Basics, Development, and FutureDocument27 pagesCh1 Bioinformatics... Basics, Development, and FuturehadymatrixNo ratings yet
- Systems Biomedicine: Concepts and PerspectivesFrom EverandSystems Biomedicine: Concepts and PerspectivesEdison T. LiuNo ratings yet
- 11 Perilispi Wodak RuthDocument11 pages11 Perilispi Wodak RuthmwanaisNo ratings yet
- A Conceptual Framework For ConsciousnessDocument9 pagesA Conceptual Framework For ConsciousnessAnahí TessaNo ratings yet
- Virtual Communication Curbs Creative Idea Generation: ArticleDocument22 pagesVirtual Communication Curbs Creative Idea Generation: ArticleAnahí TessaNo ratings yet
- World View: Don't Ask If AI Is Good or Fair, Ask How It Shifts PowerDocument1 pageWorld View: Don't Ask If AI Is Good or Fair, Ask How It Shifts PowerAnahí TessaNo ratings yet
- AI Is Selecting Reviewers in ChinaDocument2 pagesAI Is Selecting Reviewers in ChinaAnahí TessaNo ratings yet
- Van Der Waals Integration of High-Oxides and Two-Dimensional SemiconductorsDocument8 pagesVan Der Waals Integration of High-Oxides and Two-Dimensional SemiconductorsAnahí TessaNo ratings yet
- Science - Abm1574 SMDocument19 pagesScience - Abm1574 SMAnahí TessaNo ratings yet
- The Language Machines: A Remarkable AI Can Write Like Humans - But With No Understanding of What It's SayingDocument4 pagesThe Language Machines: A Remarkable AI Can Write Like Humans - But With No Understanding of What It's SayingAnahí TessaNo ratings yet
- Science Abj6987Document11 pagesScience Abj6987Anahí TessaNo ratings yet
- Constraining The Response of Continental Scale Groundwater Flow To Climate ChangeDocument16 pagesConstraining The Response of Continental Scale Groundwater Flow To Climate ChangeAnahí TessaNo ratings yet
- Employers: Research Will Be Key To Successful Remote WorkingDocument1 pageEmployers: Research Will Be Key To Successful Remote WorkingAnahí TessaNo ratings yet
- Comment: Rewilding Argentina: Lessons For The 2030 Biodiversity TargetsDocument3 pagesComment: Rewilding Argentina: Lessons For The 2030 Biodiversity TargetsAnahí TessaNo ratings yet
- Texto 0Document10 pagesTexto 0Anahí TessaNo ratings yet
- Geographically Dispersed Zoonotic Tuberculosis in Pre-Contact South American Human PopulationsDocument12 pagesGeographically Dispersed Zoonotic Tuberculosis in Pre-Contact South American Human PopulationsAnahí TessaNo ratings yet
- DNA Replication Fork Speed Underlies Cell Fate Changes and Promotes ReprogrammingDocument27 pagesDNA Replication Fork Speed Underlies Cell Fate Changes and Promotes ReprogrammingAnahí TessaNo ratings yet
- Pronounced Loss of Amazon Rainforest Resilience Since The Early 2000sDocument10 pagesPronounced Loss of Amazon Rainforest Resilience Since The Early 2000sAnahí TessaNo ratings yet
- Innate Immunity: The First Line of Defense Against Sars-Cov-2Document12 pagesInnate Immunity: The First Line of Defense Against Sars-Cov-2Anahí TessaNo ratings yet
- Perspectives in Machine Learning For Wildlife Conservation: PerspectiveDocument15 pagesPerspectives in Machine Learning For Wildlife Conservation: PerspectiveAnahí TessaNo ratings yet
- A Genetically Encoded Sensor For in Vivo Imaging of Orexin NeuropeptidesDocument34 pagesA Genetically Encoded Sensor For in Vivo Imaging of Orexin NeuropeptidesAnahí TessaNo ratings yet
- A Cattle Graph Genome Incorporating Global Breed Diversity: ArticleDocument14 pagesA Cattle Graph Genome Incorporating Global Breed Diversity: ArticleAnahí TessaNo ratings yet
- Where I Work: Lucía SpangenbergDocument1 pageWhere I Work: Lucía SpangenbergAnahí TessaNo ratings yet
- Protein Sequence Design With A Learned Potential: ArticleDocument11 pagesProtein Sequence Design With A Learned Potential: ArticleAnahí TessaNo ratings yet
- Early Prediction of Preeclampsia in Pregnancy With Cell-Free RNADocument24 pagesEarly Prediction of Preeclampsia in Pregnancy With Cell-Free RNAAnahí TessaNo ratings yet
- Twin Study Reveals Non-Heritable Immune Perturbations in Multiple SclerosisDocument23 pagesTwin Study Reveals Non-Heritable Immune Perturbations in Multiple SclerosisAnahí TessaNo ratings yet
- Comment: Pregnancy in The LabDocument2 pagesComment: Pregnancy in The LabAnahí TessaNo ratings yet
- Retention of Deposited Ammonium and Nitrate and Its Impact On The Global Forest Carbon SinkDocument9 pagesRetention of Deposited Ammonium and Nitrate and Its Impact On The Global Forest Carbon SinkAnahí TessaNo ratings yet
- A Python Library For Probabilistic Analysis of Single-Cell Omics DataDocument4 pagesA Python Library For Probabilistic Analysis of Single-Cell Omics DataAnahí TessaNo ratings yet
- The Einstein Effect Provides Global Evidence For Scientific Source Credibility Effects and The Influence of ReligiosityDocument16 pagesThe Einstein Effect Provides Global Evidence For Scientific Source Credibility Effects and The Influence of ReligiosityAnahí TessaNo ratings yet
- The Chronic Growing Pains of Communicating Science OnlineDocument3 pagesThe Chronic Growing Pains of Communicating Science OnlineAnahí TessaNo ratings yet
- Delhi Public School, Durgapur Class 5 Sub: English Literature Topic: The Fir Tree Assignment 1Document13 pagesDelhi Public School, Durgapur Class 5 Sub: English Literature Topic: The Fir Tree Assignment 1adatta785031No ratings yet
- CPT 4.2: Introduction to Animal BehaviourDocument28 pagesCPT 4.2: Introduction to Animal BehaviourKshitija Mehta100% (1)
- Aphid, (Family Aphididae), Also Called Plant Louse, Greenfly, or Ant Cow, Any of A Group of SapDocument11 pagesAphid, (Family Aphididae), Also Called Plant Louse, Greenfly, or Ant Cow, Any of A Group of SapAmjadRashidNo ratings yet
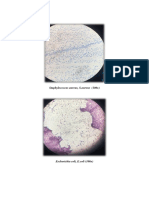
- Result:: Staphylococcus Aureus, S.aureus (100x)Document3 pagesResult:: Staphylococcus Aureus, S.aureus (100x)Ayuni Nadrah Bt KamarujamanNo ratings yet
- Media Bulletin 12 08 2020Document58 pagesMedia Bulletin 12 08 2020sandeep yadavNo ratings yet
- Score 360 in BiologyDocument18 pagesScore 360 in BiologyOfficially MedicoNo ratings yet
- Dna & RnaDocument70 pagesDna & RnaEvette dela PenaNo ratings yet
- Effectiveness of Treatments Against Plum PathogensDocument6 pagesEffectiveness of Treatments Against Plum PathogensAndrei MariusNo ratings yet
- Population Formation by HybridisationDocument50 pagesPopulation Formation by Hybridisationvarsha pNo ratings yet
- Unit 3.2 Vertebrates and InvertebratesDocument6 pagesUnit 3.2 Vertebrates and InvertebratesruszitasetapaNo ratings yet
- Transcription and Translation AS Biology Questions AQA OCR EdexcelDocument3 pagesTranscription and Translation AS Biology Questions AQA OCR EdexcelMeeta DeviNo ratings yet
- Instructions First PartialDocument2 pagesInstructions First PartialIván MartinezNo ratings yet
- Science: Quarter 4 - Module 10: Roles of Organisms in The Cycling of MaterialsDocument20 pagesScience: Quarter 4 - Module 10: Roles of Organisms in The Cycling of MaterialsShiela Tecson GamayonNo ratings yet
- 15.4 Changing PopulationsDocument12 pages15.4 Changing PopulationsINR /ينرNo ratings yet
- Uh Kelas 10Document2 pagesUh Kelas 10smaqu wahdahkendariNo ratings yet
- The Taxonomy and Phylogeny of Austropleospora Ochracea Sp. Nov.Document13 pagesThe Taxonomy and Phylogeny of Austropleospora Ochracea Sp. Nov.jScribdNo ratings yet
- Protect™ Covid-19 RT-QPCR Kit 2.0: FeaturesDocument2 pagesProtect™ Covid-19 RT-QPCR Kit 2.0: FeaturesSagar KarvandeNo ratings yet
- Aspect BiologyDocument45 pagesAspect Biologytawsifahmedanan01761No ratings yet
- Chapter 1: Biodiversity 1.2 Classification of Organisms: Invertebrates VertebratesDocument1 pageChapter 1: Biodiversity 1.2 Classification of Organisms: Invertebrates VertebratesEu Ern TanNo ratings yet
- Managing Free-Ranging Dogs in Indian Wildlife AreasDocument105 pagesManaging Free-Ranging Dogs in Indian Wildlife AreasAd MinaNo ratings yet
- Chilomastix Mesnili: Chilomastix Mesnili Is Cosmopolitan in Distribution Although Found More Frequently inDocument3 pagesChilomastix Mesnili: Chilomastix Mesnili Is Cosmopolitan in Distribution Although Found More Frequently inNurul HidayatiNo ratings yet
- Incomplete DominanceDocument31 pagesIncomplete Dominanceregine13 ikiNo ratings yet
- Science Year 4 Chapter 2Document11 pagesScience Year 4 Chapter 2Aidah BaharomNo ratings yet
- Host TypesDocument14 pagesHost TypesMayuri Vohra100% (1)
- Takara Bio Lenti-X Packaging Single Shots ProtocolDocument5 pagesTakara Bio Lenti-X Packaging Single Shots ProtocolMildred MondayNo ratings yet
- Protein Synthesis Worksheet PART A. Read The Following:: 9. What Are The Stop Codons? (Use Your mRNA Chart) UAA UAG UGADocument7 pagesProtein Synthesis Worksheet PART A. Read The Following:: 9. What Are The Stop Codons? (Use Your mRNA Chart) UAA UAG UGAJamesBuensalidoDellava100% (1)
- B. Relevance of Ecological Agriculture Practices To Food SecurityDocument18 pagesB. Relevance of Ecological Agriculture Practices To Food SecurityKRIZZAPEARL VERNo ratings yet
- Mendelism: The Basic Principles of InheritanceDocument35 pagesMendelism: The Basic Principles of InheritanceUmmi Nur AfinniNo ratings yet
- Neontology - WikipediaDocument3 pagesNeontology - WikipediaRommelBaldagoNo ratings yet
- DIVERSITY IN LIVING ORGANISMSDocument18 pagesDIVERSITY IN LIVING ORGANISMSSunnu BabyNo ratings yet