You might also like
- Euros Cope Cheat SheetDocument2 pagesEuros Cope Cheat SheetCesar BermudezNo ratings yet
- DS Cheat SheetsDocument18 pagesDS Cheat SheetspunmapiNo ratings yet
- Optical Fiber CommunicationDocument21 pagesOptical Fiber CommunicationKaranDhamijaNo ratings yet
- SNU Korean Language Textbook 1ADocument261 pagesSNU Korean Language Textbook 1Acelyn100% (1)
- Kumon Math LevelsDocument2 pagesKumon Math Levelsjbolzan100% (1)
- Creating Tables and Charts in ExcelDocument11 pagesCreating Tables and Charts in ExcelTiffaney BowlinNo ratings yet
- Volumes by Integration1 TRIGONOMETRYDocument8 pagesVolumes by Integration1 TRIGONOMETRYChristopherOropelNo ratings yet
- Volumes by Integration1 TRIGONOMETRYDocument8 pagesVolumes by Integration1 TRIGONOMETRYChristopherOropelNo ratings yet
- What Is Bug Bounty HuntingDocument36 pagesWhat Is Bug Bounty HuntingnetskyonNo ratings yet
- Linear Algebra of Quantum Mechanics and The Simulation of A Quantum ComputerDocument9 pagesLinear Algebra of Quantum Mechanics and The Simulation of A Quantum Computeraniruddhamishra26No ratings yet
- Machine Learning NotesDocument11 pagesMachine Learning NotesxX ANGEL XxNo ratings yet
- Transmission Line Write UpDocument10 pagesTransmission Line Write UpAbhishek AgrawalNo ratings yet
- CS231n Convolutional Neural Networks For Visual RecognitionDocument9 pagesCS231n Convolutional Neural Networks For Visual RecognitionDongwoo LeeNo ratings yet
- Neural Networks: Derivation: 1 ModelDocument9 pagesNeural Networks: Derivation: 1 ModelChristine StraubNo ratings yet
- Lecture 9: Linear Programming Duality: 1.1 Max FlowDocument6 pagesLecture 9: Linear Programming Duality: 1.1 Max FlowMukesh KumarNo ratings yet
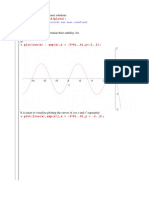
- Problem 1: 2.2.7: With (Detools) : With (Plots)Document14 pagesProblem 1: 2.2.7: With (Detools) : With (Plots)Romy RamadhanNo ratings yet
- nef-2023-tutorialDocument9 pagesnef-2023-tutorialMd Sahin SirajNo ratings yet
- Additional Exercises for Convex Optimization TopicsDocument152 pagesAdditional Exercises for Convex Optimization TopicsnudalaNo ratings yet
- Recitation 8: Continuous Optimization: For I End ForDocument12 pagesRecitation 8: Continuous Optimization: For I End ForWenjun HouNo ratings yet
- Chapter 2Document10 pagesChapter 2Fatima AbaidNo ratings yet
- hw01 Linear System ControlsDocument5 pageshw01 Linear System ControlsAnselm AdrianNo ratings yet
- Properties of Logarithms ExplainedDocument22 pagesProperties of Logarithms ExplainedYvonne CarolNo ratings yet
- Properties of Logarithms ExplainedDocument22 pagesProperties of Logarithms ExplainedVansh RajpootNo ratings yet
- Additional Exercises For Convex Optimization: Stephen Boyd Lieven Vandenberghe March 30, 2012Document143 pagesAdditional Exercises For Convex Optimization: Stephen Boyd Lieven Vandenberghe March 30, 2012api-127299018No ratings yet
- Aditional Exercises Boyd PDFDocument164 pagesAditional Exercises Boyd PDFlandinluklaNo ratings yet
- BV Cvxbook Extra ExercisesDocument156 pagesBV Cvxbook Extra ExercisesAnonymous WkbmWCa8MNo ratings yet
- BV Cvxbook Extra ExercisesDocument139 pagesBV Cvxbook Extra ExercisesAkhil AmritaNo ratings yet
- Materi 5 - Integral Akar Dan Kuadrat+Tugas 5Document13 pagesMateri 5 - Integral Akar Dan Kuadrat+Tugas 5Muhammad LiftoNo ratings yet
- 07 - Telegrapher EquationDocument9 pages07 - Telegrapher EquationSaddam HusainNo ratings yet
- Quotient Vector Spaces ExplainedDocument5 pagesQuotient Vector Spaces ExplainedVATSAL KEDIANo ratings yet
- 1 When Heteroskedasticity Is Known Up To A Multiplicative ConstantDocument4 pages1 When Heteroskedasticity Is Known Up To A Multiplicative ConstantgestafNo ratings yet
- Clustering With Gradient Descent: 1 PerformanceDocument4 pagesClustering With Gradient Descent: 1 PerformanceChristine StraubNo ratings yet
- Assignment 2Document5 pagesAssignment 2Thanh NguyenNo ratings yet
- Exterior BallisticsDocument8 pagesExterior BallisticsrNo ratings yet
- Lab 03Document14 pagesLab 03Musa MohammadNo ratings yet
- More Examples On Lagrange's EquationDocument18 pagesMore Examples On Lagrange's Equationafshin kkNo ratings yet
- ECE330 Fall 16 Lecture4 PDFDocument10 pagesECE330 Fall 16 Lecture4 PDFPhùng Đức AnhNo ratings yet
- HW 3Document7 pagesHW 3BenNo ratings yet
- Machine Learning and Pattern Recognition Week 8_backpropDocument8 pagesMachine Learning and Pattern Recognition Week 8_backpropzeliawillscumbergNo ratings yet
- Matlab Chapter2Document15 pagesMatlab Chapter2Giulia IoriNo ratings yet
- Lagrange Multipliers: Solving Multivariable Optimization ProblemsDocument5 pagesLagrange Multipliers: Solving Multivariable Optimization ProblemsOctav DragoiNo ratings yet
- Basic Control System With Matlab ExamplesDocument19 pagesBasic Control System With Matlab ExamplesMostafa8425No ratings yet
- Vector Calc SummaryDocument7 pagesVector Calc SummaryJedwin VillanuevaNo ratings yet
- Solving Optimal Control Problems With MATLABDocument21 pagesSolving Optimal Control Problems With MATLABxarthrNo ratings yet
- 18 GenfuncDocument20 pages18 GenfuncDương Minh ĐứcNo ratings yet
- Lect02 HandoutsDocument23 pagesLect02 HandoutsXaocyc hosseiniNo ratings yet
- Machine Learning and Pattern Recognition_mathsDocument3 pagesMachine Learning and Pattern Recognition_mathszeliawillscumbergNo ratings yet
- TP 1initiation Programmation MatlabDocument4 pagesTP 1initiation Programmation MatlabroseNo ratings yet
- BV Cvxbook Extra ExercisesDocument165 pagesBV Cvxbook Extra ExercisesscatterwalkerNo ratings yet
- Lecture6 NotesDocument5 pagesLecture6 NotesMelanie2023No ratings yet
- Ch4 Kinetics of Systems of ParticlesDocument9 pagesCh4 Kinetics of Systems of ParticlesGian MorenoNo ratings yet
- Fundamental Theorem of Calculus ProofDocument4 pagesFundamental Theorem of Calculus ProofGarcia RaphNo ratings yet
- Inverse Laplace Transforms and the Heaviside FunctionDocument7 pagesInverse Laplace Transforms and the Heaviside FunctionuploadingpersonNo ratings yet
- Essay DraftDocument6 pagesEssay DraftEdgars VītiņšNo ratings yet
- Group Theory: 1. Show That The Wave Equation For The Propagation of An Impulse at The Speed of Light CDocument2 pagesGroup Theory: 1. Show That The Wave Equation For The Propagation of An Impulse at The Speed of Light CdaegunleeNo ratings yet
- The Kernel Trick: Transforming Data to Make it Linearly SeparableDocument4 pagesThe Kernel Trick: Transforming Data to Make it Linearly SeparableShankaranarayanan GopalNo ratings yet
- 3 DerivativesDocument125 pages3 DerivativescontactsakyNo ratings yet
- TutorialDocument4 pagesTutorialAnonymous WkbmWCa8MNo ratings yet
- Additional Exercises for Convex Optimization ProblemsDocument175 pagesAdditional Exercises for Convex Optimization ProblemsMorokot AngelaNo ratings yet
- NumerovDocument5 pagesNumerovdiego-crNo ratings yet
- CalcI Integral AppsDocument50 pagesCalcI Integral AppsdarnaNo ratings yet
- Funcnd Limcont PDFDocument24 pagesFuncnd Limcont PDFSurabhi mallickNo ratings yet
- L'Hospital's Rule for Multivariable FunctionsDocument13 pagesL'Hospital's Rule for Multivariable FunctionslalasoisNo ratings yet
- Introduction To L TEXDocument6 pagesIntroduction To L TEXMotumba Uwakwe MarcelitoNo ratings yet
- Aula 7 - Teoria de Cordas MITDocument7 pagesAula 7 - Teoria de Cordas MITErick MouraNo ratings yet
- Green's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)From EverandGreen's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)No ratings yet
- The Spectral Theory of Toeplitz Operators. (AM-99), Volume 99From EverandThe Spectral Theory of Toeplitz Operators. (AM-99), Volume 99No ratings yet
- Pri FunctionsDocument5 pagesPri FunctionsDhaval PatelNo ratings yet
- Data Analysis With Graphs: Statistics Is The Gathering, Organization, Analysis, andDocument13 pagesData Analysis With Graphs: Statistics Is The Gathering, Organization, Analysis, andDhaval PatelNo ratings yet
- Appendix 9: Areas in The Tail of The Standard Normal DistributionDocument2 pagesAppendix 9: Areas in The Tail of The Standard Normal DistributionDhaval PatelNo ratings yet
- APS1070: Foundations of Data Analytics and Machine Learning J.RiordonDocument2 pagesAPS1070: Foundations of Data Analytics and Machine Learning J.RiordonHannaNo ratings yet
- Spatial AODA PDFDocument6 pagesSpatial AODA PDFkeertiNo ratings yet
- Calculus 12 Formula Sheet : Pythagorean: DerivativesDocument2 pagesCalculus 12 Formula Sheet : Pythagorean: DerivativesDhaval PatelNo ratings yet
- Math 1112 CurrbDocument160 pagesMath 1112 Currbswickramasinha100% (1)
- Science Unit 3: Matter and Energy: Understanding Pure Substances and MixturesDocument6 pagesScience Unit 3: Matter and Energy: Understanding Pure Substances and MixturesDhaval PatelNo ratings yet
- 2 Statistics of One VariableDocument1 page2 Statistics of One VariableDhaval PatelNo ratings yet
- Structures & Properties Unit Plan (Feb. 2020)Document1 pageStructures & Properties Unit Plan (Feb. 2020)Dhaval PatelNo ratings yet
- 2 Statistics of One VariableDocument1 page2 Statistics of One VariableDhaval PatelNo ratings yet
- Quantum NumbersDocument7 pagesQuantum NumbersDhaval PatelNo ratings yet
- Quantum NumbersDocument7 pagesQuantum NumbersDhaval PatelNo ratings yet
- Latest RRB NTPC Exam Questions & AnswersDocument28 pagesLatest RRB NTPC Exam Questions & AnswerssalimNo ratings yet
- Knowledge Creation - and Management New Challenges For ManagersDocument364 pagesKnowledge Creation - and Management New Challenges For ManagersDeelstra Evert JanNo ratings yet
- Shipmate GPS RS5700 Manual PDFDocument62 pagesShipmate GPS RS5700 Manual PDFsaxonpirate50% (6)
- All New ASAC XFactor Complete Guide To Adsense Authority WebsitesDocument217 pagesAll New ASAC XFactor Complete Guide To Adsense Authority WebsitesKārlis Šēns100% (1)
- Cabezal Movil PLS 575-2 (13CH)Document10 pagesCabezal Movil PLS 575-2 (13CH)Bruno Cominetti GarciasNo ratings yet
- CICA - Cloud Computing - A PrimerDocument29 pagesCICA - Cloud Computing - A PrimerjackjustnewsNo ratings yet
- Topic3-Taylors, Eulers, R-K Method Engineering m4 PDFDocument15 pagesTopic3-Taylors, Eulers, R-K Method Engineering m4 PDFDivakar c.sNo ratings yet
- Social Media: A Double-Edged SwordDocument4 pagesSocial Media: A Double-Edged SwordrosellerNo ratings yet
- Scoping and Testing: Professor Jennifer Rexford COS 217Document34 pagesScoping and Testing: Professor Jennifer Rexford COS 217DaWheng VargasNo ratings yet
- CSS Position: What Is Document Normal Flow?Document20 pagesCSS Position: What Is Document Normal Flow?dorian451No ratings yet
- Financial Statements Sole Proprietor SampleDocument37 pagesFinancial Statements Sole Proprietor SampleNori Fajardo0% (1)
- ACDC and audio files metadataDocument531 pagesACDC and audio files metadataMarckie Roldan TajoNo ratings yet
- CC Notes PDFDocument25 pagesCC Notes PDFAnkith C RNo ratings yet
- Edge Tech3400 Portable SBP Hardware ManualDocument166 pagesEdge Tech3400 Portable SBP Hardware ManualCapouNo ratings yet
- M25P80Document53 pagesM25P80api-3736976No ratings yet
- The rarest scripts compilationDocument6 pagesThe rarest scripts compilationAMD-65 enjoyerNo ratings yet
- Metal Oxide Film Resistors GuideDocument2 pagesMetal Oxide Film Resistors GuidekgskgmNo ratings yet
- Goulds Vertical Lineshaft and Submersible PumpsDocument16 pagesGoulds Vertical Lineshaft and Submersible Pumpsiam_drn1024No ratings yet
- Lica Unit2Document59 pagesLica Unit2Sri Prakash NarayanamNo ratings yet
- NBCPDocument17 pagesNBCPArch. Jan EchiverriNo ratings yet
- Ds r16 - Unit-4 (Ref-2)Document15 pagesDs r16 - Unit-4 (Ref-2)Hemanth SankaramanchiNo ratings yet
- Marketing Manager in San Diego CA Resume Eva LangerDocument3 pagesMarketing Manager in San Diego CA Resume Eva LangerevalangerNo ratings yet
- Livestock Census 2019Document3 pagesLivestock Census 2019pratik desaiNo ratings yet
- Mathematics ISC Question Paper XII (Commerce & Science Group) - 2009Document5 pagesMathematics ISC Question Paper XII (Commerce & Science Group) - 2009sraj68No ratings yet
- Ansys 13.design Xplorer PDFDocument146 pagesAnsys 13.design Xplorer PDFVimes LabNo ratings yet