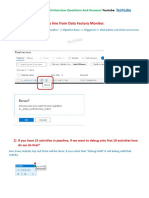
You might also like
- Report Futuriom SD Wan Managed Services Survey 2021Document35 pagesReport Futuriom SD Wan Managed Services Survey 2021masterlinh2008No ratings yet
- Hoyne Versus Meyer On ElasticitiesDocument3 pagesHoyne Versus Meyer On ElasticitiesGlennKesslerWPNo ratings yet
- Congress of Mobile Medical Professionals (CoMMP) - Education Position PaperDocument15 pagesCongress of Mobile Medical Professionals (CoMMP) - Education Position PaperJonathon Feit100% (1)
- Transmission Case 2Document2 pagesTransmission Case 2Alex BravoNo ratings yet
- Acid Mine Drainage Workshop - 1995Document102 pagesAcid Mine Drainage Workshop - 1995Scott DownsNo ratings yet
- Question 4Document2 pagesQuestion 4Mahin MittalNo ratings yet
- Discrete Maths Quiz2 2Document9 pagesDiscrete Maths Quiz2 2maryamNo ratings yet
- Azure Data Factory Interview QuestionsDocument33 pagesAzure Data Factory Interview Questionskubir nannawareNo ratings yet
- Cfa Level 2 2023 SummaryDocument100 pagesCfa Level 2 2023 SummaryDAKSH KUSHWAH IPM 2020 -25 BatchNo ratings yet
- QB ML U3,4,5Document1 pageQB ML U3,4,5Narasimha KanduriNo ratings yet
- 01 Introduction - KeyDocument39 pages01 Introduction - Key오현진No ratings yet
- Data Structures (A5502) Important Questions: TH THDocument2 pagesData Structures (A5502) Important Questions: TH THsaiNo ratings yet
- Physics - Concepts MechanicsDocument1 pagePhysics - Concepts Mechanicslgazzola79No ratings yet
- Using Tech EffectivelyDocument5 pagesUsing Tech Effectivelyapi-621629070No ratings yet
- Prac L - 4 Job Satisfaction Scale: Robert HoppockDocument17 pagesPrac L - 4 Job Satisfaction Scale: Robert HoppockRiya SharmaNo ratings yet
- Mca - V20pca104 - Ec2332251010489Document3 pagesMca - V20pca104 - Ec2332251010489Tushar ChaudharyNo ratings yet
- Investigation Friday May 5thDocument2 pagesInvestigation Friday May 5thSinael CarrilloNo ratings yet
- Wasim Jafri: Professional ProfileDocument2 pagesWasim Jafri: Professional ProfileWaseem JafriNo ratings yet
- Σύνοψη σημειώσεων 2Document28 pagesΣύνοψη σημειώσεων 2Fotini NotiNo ratings yet
- Aies Final - 7 - 8 - 9Document15 pagesAies Final - 7 - 8 - 9virgulatiit21a1068No ratings yet
- Mehak ResumeDocument2 pagesMehak ResumeParminder SinghNo ratings yet
- Formative Task Myp4 U2Document4 pagesFormative Task Myp4 U2Harvey HarryNo ratings yet
- Psychological Point of ViewDocument3 pagesPsychological Point of ViewForam PatelNo ratings yet
- Technical Project ManagerDocument3 pagesTechnical Project Managerhtc1phonem7No ratings yet
- Indoor Posi Oning in The Health Care SectorDocument3 pagesIndoor Posi Oning in The Health Care SectorRishi TNo ratings yet
- Unit-3 EconomicsDocument23 pagesUnit-3 Economicsrakshit konchadaNo ratings yet
- Understanding EMC and EMI Basics With Wurth ElectronikDocument5 pagesUnderstanding EMC and EMI Basics With Wurth ElectronikHnos. Carrillo-RamirezNo ratings yet
- Advanced Javascript Concepts Cheat Sheet: Zero To MasteryDocument96 pagesAdvanced Javascript Concepts Cheat Sheet: Zero To MasteryRohan Gupta100% (2)
- Resume Work PDFDocument4 pagesResume Work PDFayesha siddiquiNo ratings yet
- Ds Task Job LossDocument3 pagesDs Task Job Lossenjy amrNo ratings yet
- Soap Note Practice 2Document1 pageSoap Note Practice 2api-644828371No ratings yet
- Plan 1: Hoi Wai Chau Pelvis Clinical Lab AssignmentDocument13 pagesPlan 1: Hoi Wai Chau Pelvis Clinical Lab Assignmentapi-527782385No ratings yet
- SPSS ExamDocument17 pagesSPSS ExamSourabhNo ratings yet
- Workshop 03Document9 pagesWorkshop 03nikaneydi1984No ratings yet
- Zynq Power DownDocument2 pagesZynq Power DownMayur RaulNo ratings yet
- Applied Aspects 3rd Substage Head and NeckDocument4 pagesApplied Aspects 3rd Substage Head and NeckTaimoor QadeerNo ratings yet
- Hydrogen in Box - Concept NoteDocument5 pagesHydrogen in Box - Concept NoteTunde KallaiNo ratings yet
- Alexandria 100 Day Report Card Part IIDocument2 pagesAlexandria 100 Day Report Card Part IIKALB DIGITALNo ratings yet
- Non-Disclosure Agreement - MLDocument2 pagesNon-Disclosure Agreement - MLvishwas.mishra1234No ratings yet
- Logic Path Inside Digital Draw Description Can Ask For Balancing Concerns Can Trust The Usage Utility of Expected Stuff Leaf LikeDocument7 pagesLogic Path Inside Digital Draw Description Can Ask For Balancing Concerns Can Trust The Usage Utility of Expected Stuff Leaf LikessfofoNo ratings yet
- PATHFUND Whitepaper - 0Document12 pagesPATHFUND Whitepaper - 0DOMINIKUS SKOMNo ratings yet
- APEUni Write Essay TemplateDocument4 pagesAPEUni Write Essay TemplateNauman KhanNo ratings yet
- QUESTION BANK With Answers IotDocument7 pagesQUESTION BANK With Answers IotNaman BhatiaNo ratings yet
- Ac N Internship Offer LetterDocument1 pageAc N Internship Offer LetterClassicNo ratings yet
- 24 KWC Players Terms and Condicionts UKDocument2 pages24 KWC Players Terms and Condicionts UKMohammed --22No ratings yet
- Q 3: What Is The Use of Regularisa/on? Explain L1 and L2 Regulariza/onDocument2 pagesQ 3: What Is The Use of Regularisa/on? Explain L1 and L2 Regulariza/onMahin MittalNo ratings yet
- Question 3Document2 pagesQuestion 3Mahin MittalNo ratings yet
- FORM - Source of Wealth Declaration 2023 PDFDocument1 pageFORM - Source of Wealth Declaration 2023 PDFgopo4062No ratings yet
- Javascript CheatsheetDocument96 pagesJavascript CheatsheetConstruction GuideNo ratings yet
- Alexandria 100 Day Report Card Part IDocument4 pagesAlexandria 100 Day Report Card Part IKALB DIGITALNo ratings yet
- Core Group Mains 2021Document7 pagesCore Group Mains 2021Peeyush SharmaNo ratings yet
- Contract WorkerDocument9 pagesContract WorkerrocioNo ratings yet
- Tutorial 1 WorksheetDocument1 pageTutorial 1 WorksheetKobe ChungNo ratings yet
- Tanish Mehta ResumeDocument1 pageTanish Mehta Resumeanush.agarwal1603No ratings yet
- ATRANS Bus Ridership Press ReleaseDocument1 pageATRANS Bus Ridership Press ReleaseKALB DIGITALNo ratings yet
- AphishmDocument1 pageAphishmAmit RajputNo ratings yet
- PDF DocumentDocument2 pagesPDF DocumentKxng MindCtrl OrevaNo ratings yet
- Couette Flow DerivationDocument12 pagesCouette Flow DerivationramizNo ratings yet
- Explore: Apple Watch Innova3on VHS Learning Page of 2 1Document2 pagesExplore: Apple Watch Innova3on VHS Learning Page of 2 1Arijus JohnsonNo ratings yet
- Anxiety Ebook FreeDocument22 pagesAnxiety Ebook Freeفقير نقشبندي مجددي حسنيNo ratings yet
- 006 Course Guide - Bug Bounty & Web Security by ZTMDocument5 pages006 Course Guide - Bug Bounty & Web Security by ZTMDarshan ChindarkarNo ratings yet
- Question 3Document2 pagesQuestion 3Mahin MittalNo ratings yet
- Q 2: Difference Between Numpy Array and Python List ? Ans-Numpy Is The Core Library For Scien4fic Compu4ng in Python. It Provides ADocument1 pageQ 2: Difference Between Numpy Array and Python List ? Ans-Numpy Is The Core Library For Scien4fic Compu4ng in Python. It Provides AMahin MittalNo ratings yet
- Q 3: What Is The Use of Regularisa/on? Explain L1 and L2 Regulariza/onDocument2 pagesQ 3: What Is The Use of Regularisa/on? Explain L1 and L2 Regulariza/onMahin MittalNo ratings yet
- Q 5: What Are Hyperparameters? Give Two Examples of Hyperparameters andDocument2 pagesQ 5: What Are Hyperparameters? Give Two Examples of Hyperparameters andMahin MittalNo ratings yet
- SR - NO: Name of Practile Date OF Practile Teacher Signature: Data Structure Practile File IndexDocument4 pagesSR - NO: Name of Practile Date OF Practile Teacher Signature: Data Structure Practile File IndexMahin MittalNo ratings yet
- 3 Mic125Document8 pages3 Mic125nadiazkiNo ratings yet
- Activate Your Soul Tribe Ebook 1Document34 pagesActivate Your Soul Tribe Ebook 1IlidioVitoria100% (1)
- Calculations and Verifications of Shredding Chamber of Two-Shaft Shredder For Crushing of Concrete, Rubber, Plastic and WoodDocument2 pagesCalculations and Verifications of Shredding Chamber of Two-Shaft Shredder For Crushing of Concrete, Rubber, Plastic and WoodEdosael KefyalewNo ratings yet
- MSI DocumentDocument1 pageMSI DocumentjuballerNo ratings yet
- Reading 5-M-9Document7 pagesReading 5-M-9YuliNo ratings yet
- MNP DS 4023Document6 pagesMNP DS 4023Dinesh RajNo ratings yet
- 4000 Series: 4008TAG2ADocument5 pages4000 Series: 4008TAG2ALuis GiraldoNo ratings yet
- Form Brother SisterDocument3 pagesForm Brother SisterPankajNo ratings yet
- EC6403 Electromagnetic FieldsDocument13 pagesEC6403 Electromagnetic Fieldssrinureddy2014No ratings yet
- Practice Test 4 - Mid Term 2 - English 7Document3 pagesPractice Test 4 - Mid Term 2 - English 7Duy AnhNo ratings yet
- Form PDFDocument8 pagesForm PDFChitresh143No ratings yet
- 4th LectureDocument4 pages4th Lectureمحمد عدنان مصطفىNo ratings yet
- Ong vs. Ca: DownloadDocument1 pageOng vs. Ca: DownloadMackie SaidNo ratings yet
- DWSD Lifeline Plan - June 2022Document12 pagesDWSD Lifeline Plan - June 2022Malachi BarrettNo ratings yet
- How To Register A Business in The Philippines: A Guide To BIR, DTI, SEC Application and OthersDocument9 pagesHow To Register A Business in The Philippines: A Guide To BIR, DTI, SEC Application and OthersJovelyn MosulaNo ratings yet
- Neurodiab 2023.9Document146 pagesNeurodiab 2023.9pw8gwc952cNo ratings yet
- F.A.L. Conducive Engineering Review Center: 2 Floor Cartimar Building, CM Recto Ave., Quiapo, ManilaDocument2 pagesF.A.L. Conducive Engineering Review Center: 2 Floor Cartimar Building, CM Recto Ave., Quiapo, ManilaRosette de AsisNo ratings yet
- Pocahontas Geological SurveyDocument356 pagesPocahontas Geological SurveyNorman Lee AldermanNo ratings yet
- Ethics in AccountingDocument5 pagesEthics in Accountingxaraprotocol100% (1)
- Measuring Body TemperatureDocument5 pagesMeasuring Body TemperatureJan Jamison ZuluetaNo ratings yet
- Joe Watson - CMM Software - How It BeganDocument122 pagesJoe Watson - CMM Software - How It Beganpm089No ratings yet
- English Creative Writing Coursework Mark SchemeDocument4 pagesEnglish Creative Writing Coursework Mark Schemebcqneexy100% (1)
- Hi 60881Document2 pagesHi 60881Mohamed RafihNo ratings yet
- Numbers As Words 1Document13 pagesNumbers As Words 1Kaushal KumarNo ratings yet
- Resume of ManjerulDocument1 pageResume of ManjerulNirban MitraNo ratings yet
- Sensor77 VLC Ieee Sensors JDocument9 pagesSensor77 VLC Ieee Sensors JHai LeNo ratings yet
- QuestionsDocument16 pagesQuestionsMaram SyegNo ratings yet
- SSAT Prep Guide: Tips and Strategies For Every Section of The TestDocument64 pagesSSAT Prep Guide: Tips and Strategies For Every Section of The Testthomson100% (1)