You might also like
- Ass7 Write Up .FinalDocument11 pagesAss7 Write Up .Finaladagalepayale023No ratings yet
- A Language Independent Approach To Develop URDUIR SystemDocument10 pagesA Language Independent Approach To Develop URDUIR SystemCS & ITNo ratings yet
- What Is Structured Data?: Information RetrievalDocument6 pagesWhat Is Structured Data?: Information RetrievalSundar Shahi ThakuriNo ratings yet
- Chapter 1: Boolean RetrievalDocument9 pagesChapter 1: Boolean RetrievalAmber SaxenaNo ratings yet
- Effective Classification of TextDocument6 pagesEffective Classification of TextseventhsensegroupNo ratings yet
- Text and Graph Mining Algorithms ExplainedDocument21 pagesText and Graph Mining Algorithms Explainedshabir AhmadNo ratings yet
- Text MiningDocument12 pagesText Miningساره عبد المجيد المراكبى عبد المجيد احمد UnknownNo ratings yet
- Text Mining: Open Source Tokenization Tools - An AnalysisDocument11 pagesText Mining: Open Source Tokenization Tools - An Analysisacii journalNo ratings yet
- Anti-Serendipity: Finding Useless Documents and Similar DocumentsDocument9 pagesAnti-Serendipity: Finding Useless Documents and Similar DocumentsfeysalnurNo ratings yet
- Associative Text Retrieval From A Large Document Collection Using Unorganized Neural NetworksDocument10 pagesAssociative Text Retrieval From A Large Document Collection Using Unorganized Neural NetworkstpitikarisNo ratings yet
- Introduction To Information Storage and Retrieval Systems: BY-Research ScholarDocument42 pagesIntroduction To Information Storage and Retrieval Systems: BY-Research ScholarumraojigyasaNo ratings yet
- Informativeness-Based Keyword Extraction From Short DocumentsDocument11 pagesInformativeness-Based Keyword Extraction From Short DocumentsBekuma GudinaNo ratings yet
- IRS Unit-1Document27 pagesIRS Unit-1Venkatesh JNo ratings yet
- UNIT 4 Data MiningDocument11 pagesUNIT 4 Data MiningmahiNo ratings yet
- Minorproject IshantDocument18 pagesMinorproject IshantIshant KumawatNo ratings yet
- Multilingual Information RetrievalDocument18 pagesMultilingual Information RetrievalHarshithaNo ratings yet
- Text MiningDocument23 pagesText MiningChakkarawarthiNo ratings yet
- Jurnal Information RetrievalDocument4 pagesJurnal Information Retrievalkidoseno85No ratings yet
- NLP-Neuro Linguistic Programming: What Is A Corpus?Document3 pagesNLP-Neuro Linguistic Programming: What Is A Corpus?yousef shabanNo ratings yet
- IJCER (WWW - Ijceronline.com) International Journal of Computational Engineering ResearchDocument4 pagesIJCER (WWW - Ijceronline.com) International Journal of Computational Engineering ResearchInternational Journal of computational Engineering research (IJCER)No ratings yet
- Text Mining Through Semi Automatic Semantic AnnotationDocument12 pagesText Mining Through Semi Automatic Semantic AnnotationsatsriniNo ratings yet
- Text Pre Processing With NLTKDocument42 pagesText Pre Processing With NLTKMohsin Ali KhattakNo ratings yet
- Coba Coba UploadDocument3 pagesCoba Coba UploadOry JefryNo ratings yet
- Komputerisasi Penelitian Hukum DGN Teknologi Data MiningDocument8 pagesKomputerisasi Penelitian Hukum DGN Teknologi Data MiningsunnysamsuniNo ratings yet
- A Simple Information Retrieval TechniqueDocument4 pagesA Simple Information Retrieval TechniqueidescitationNo ratings yet
- A Web Text Mining Flexible Architecture: M. Castellano, G. Mastronardi, A. Aprile, and G. TarriconeDocument8 pagesA Web Text Mining Flexible Architecture: M. Castellano, G. Mastronardi, A. Aprile, and G. TarriconeKiagus Riza RachmadiNo ratings yet
- Semantic Information Retrieval Based On Domain OntologyDocument4 pagesSemantic Information Retrieval Based On Domain OntologyIntegrated Intelligent ResearchNo ratings yet
- Multimedia Information Retrieval TechniquesDocument29 pagesMultimedia Information Retrieval TechniquesAre ZelanNo ratings yet
- A New Approach To Represent Textual Documents Using CVSMDocument6 pagesA New Approach To Represent Textual Documents Using CVSMParimalla SubhashNo ratings yet
- Perfectionof Classification Accuracy in Text CategorizationDocument5 pagesPerfectionof Classification Accuracy in Text CategorizationIJAR JOURNALNo ratings yet
- IRS B Tech CSE Part 1Document161 pagesIRS B Tech CSE Part 1Rajput SinghNo ratings yet
- Lecture 7Document126 pagesLecture 7suchi9mayNo ratings yet
- Unit - 3 Ir QuestionbankDocument27 pagesUnit - 3 Ir QuestionbankVctw CseNo ratings yet
- PPT08-Natural Language ProcessingDocument44 pagesPPT08-Natural Language ProcessingGuntur WibisonoNo ratings yet
- Term Paper: Title: Multiword Detection in Natural Language Processing (NLP)Document3 pagesTerm Paper: Title: Multiword Detection in Natural Language Processing (NLP)Susmith John RoyNo ratings yet
- Preprocessing Stemin JIDocument3 pagesPreprocessing Stemin JIkidoseno85No ratings yet
- UNIT 1 IRS WWWWWDocument26 pagesUNIT 1 IRS WWWWWnikhilsinha789No ratings yet
- en Single Document Automatic Text SummarizaDocument10 pagesen Single Document Automatic Text SummarizaAlfikri HikmatiarNo ratings yet
- KmeanseppcsitDocument5 pagesKmeanseppcsitchandrashekarbh1997No ratings yet
- (IJCST-V9I6P4) :mohamed MinhajDocument7 pages(IJCST-V9I6P4) :mohamed MinhajEighthSenseGroupNo ratings yet
- Unit 1Document4 pagesUnit 1Shiv MNo ratings yet
- Week 7 Seminar Notes Terminology and CorpusDocument8 pagesWeek 7 Seminar Notes Terminology and CorpusIuliana AursuleseiNo ratings yet
- Saravanan ThesisDocument207 pagesSaravanan ThesisUnimarks Legal Solutions100% (1)
- Text mining techniques and approachesDocument35 pagesText mining techniques and approachesshabir AhmadNo ratings yet
- Text Analysis: Why Do We Need Text AnalyticsDocument2 pagesText Analysis: Why Do We Need Text AnalyticsVivian LauNo ratings yet
- Unit-2Document40 pagesUnit-2Sree DhathriNo ratings yet
- 1-What Is Text Mining - IBMDocument5 pages1-What Is Text Mining - IBMNagendra KumarNo ratings yet
- Text MiningDocument10 pagesText MiningAmy AungNo ratings yet
- Item normalization and indexing processDocument7 pagesItem normalization and indexing processShushanth munnaNo ratings yet
- Text Mining AssignmentDocument12 pagesText Mining AssignmentBzuwerk YemerNo ratings yet
- IR Algorithms Survey: Representation and Searching TechniquesDocument8 pagesIR Algorithms Survey: Representation and Searching TechniquesshanthinisampathNo ratings yet
- A Web Text Mining Flexible Architecture: M. Castellano, G. Mastronardi, A. Aprile, and G. TarriconeDocument8 pagesA Web Text Mining Flexible Architecture: M. Castellano, G. Mastronardi, A. Aprile, and G. TarriconeHanh TruongNo ratings yet
- Natural-language-processing-revision-notesDocument4 pagesNatural-language-processing-revision-notesanupriyasoundararajNo ratings yet
- An Introduction To Information Retrieval Systems: Intelligent Systems March 18, 2004 Ramashis DasDocument25 pagesAn Introduction To Information Retrieval Systems: Intelligent Systems March 18, 2004 Ramashis DasShivanshu RastogiNo ratings yet
- Information Storage And: Retrieval TechniquesDocument56 pagesInformation Storage And: Retrieval Techniquesamirthaa sriNo ratings yet
- Tamrakar 2015Document6 pagesTamrakar 2015First UnboxNo ratings yet
- Using language models for generic entity extractionDocument1 pageUsing language models for generic entity extractionmeNo ratings yet
- Document Ranking Using Customizes Vector MethodDocument6 pagesDocument Ranking Using Customizes Vector MethodEditor IJTSRDNo ratings yet
- Medicinal PlantDocument13 pagesMedicinal PlantNeelum iqbalNo ratings yet
- Flexible Ductwork Report - November 2011v2Document69 pagesFlexible Ductwork Report - November 2011v2bommobNo ratings yet
- Technical Description: BoilerDocument151 pagesTechnical Description: BoilerÍcaro VianaNo ratings yet
- 3.1 C 4.5 Algorithm-19Document10 pages3.1 C 4.5 Algorithm-19nayan jainNo ratings yet
- Openness To Experience: Intellect & Openness: Lecture Notes 8Document8 pagesOpenness To Experience: Intellect & Openness: Lecture Notes 8Danilo Pesic100% (1)
- Athenaze 1 Chapter 7a Jun 18th 2145Document3 pagesAthenaze 1 Chapter 7a Jun 18th 2145maverickpussNo ratings yet
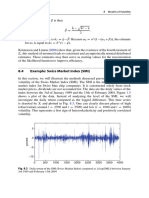
- 8.4 Example: Swiss Market Index (SMI) : 188 8 Models of VolatilityDocument3 pages8.4 Example: Swiss Market Index (SMI) : 188 8 Models of VolatilityNickesh ShahNo ratings yet
- $R6RN116Document20 pages$R6RN116chinmay gulhaneNo ratings yet
- Oas Community College: Republic of The Philippines Commission On Higher Education Oas, AlbayDocument22 pagesOas Community College: Republic of The Philippines Commission On Higher Education Oas, AlbayJaycel NepalNo ratings yet
- GD&T WIZ Tutor Covers The Vast Breadth of Geometric Dimensioning and Tolerancing Without Compromising On The Depth. The Topics Covered AreDocument1 pageGD&T WIZ Tutor Covers The Vast Breadth of Geometric Dimensioning and Tolerancing Without Compromising On The Depth. The Topics Covered AreVinay ManjuNo ratings yet
- Hisar CFC - Approved DPRDocument126 pagesHisar CFC - Approved DPRSATYAM KUMARNo ratings yet
- Mad LabDocument66 pagesMad LabBalamurugan MNo ratings yet
- Bhakti Trader Ram Pal JiDocument232 pagesBhakti Trader Ram Pal JiplancosterNo ratings yet
- X RayDocument16 pagesX RayMedical Physics2124No ratings yet
- 266 009-336Document327 pages266 009-336AlinaE.BarbuNo ratings yet
- Tuberculin Skin Test: Facilitator GuideDocument31 pagesTuberculin Skin Test: Facilitator GuideTiwi NaloleNo ratings yet
- Service Parts List: 54-26-0005 2551-20 M12™ FUEL™ SURGE™ 1/4" Hex Hydraulic Driver K42ADocument2 pagesService Parts List: 54-26-0005 2551-20 M12™ FUEL™ SURGE™ 1/4" Hex Hydraulic Driver K42AAmjad AlQasrawi100% (1)
- Week 1 Gec 106Document16 pagesWeek 1 Gec 106Junjie FuentesNo ratings yet
- ElectricalDocument30 pagesElectricalketerNo ratings yet
- Fehniger Steve-Pump VibrationDocument35 pagesFehniger Steve-Pump VibrationSheikh Shoaib100% (1)
- 19 Unpriced BOM, Project & Manpower Plan, CompliancesDocument324 pages19 Unpriced BOM, Project & Manpower Plan, CompliancesAbhay MishraNo ratings yet
- Cyber Security 2017Document8 pagesCyber Security 2017Anonymous i1ClcyNo ratings yet
- Body Shaming Among School Going AdolesceDocument5 pagesBody Shaming Among School Going AdolesceClara Widya Mulya MNo ratings yet
- 1 PBDocument11 pages1 PBAnggita Wulan RezkyanaNo ratings yet
- Steel Glossary RBC Capital GoodDocument10 pagesSteel Glossary RBC Capital Goodrajesh pal100% (1)
- Telephone Triggered SwitchesDocument22 pagesTelephone Triggered SwitchesSuresh Shah100% (1)
- Omobonike 1Document13 pagesOmobonike 1ODHIAMBO DENNISNo ratings yet
- FM 5130Document66 pagesFM 5130Aswini Kr KarmakarNo ratings yet
- Barcelona Smart City TourDocument44 pagesBarcelona Smart City TourPepe JeansNo ratings yet
- Inventory Storage and Retrieval System PatentDocument15 pagesInventory Storage and Retrieval System PatentdevanasokaNo ratings yet