You might also like
- Data Structures Notes 2 - TutorialsDuniyaDocument138 pagesData Structures Notes 2 - TutorialsDuniyaSana Mateen100% (1)
- Operations Research Applications in The Field of Information and CommunicationDocument6 pagesOperations Research Applications in The Field of Information and CommunicationrushabhrakholiyaNo ratings yet
- Data Structure Full NotesDocument72 pagesData Structure Full NotesSuper Hit MoviesNo ratings yet
- Real-Time Analytics: Techniques to Analyze and Visualize Streaming DataFrom EverandReal-Time Analytics: Techniques to Analyze and Visualize Streaming DataNo ratings yet
- Pilot Ladder SafetyDocument59 pagesPilot Ladder SafetyYamani100% (1)
- Chapter 01 - A Practical Introduction To Data Structures and Algorithm AnalysisDocument38 pagesChapter 01 - A Practical Introduction To Data Structures and Algorithm AnalysisReynaleen AgtaNo ratings yet
- DATA STRUCTURE AND ALGORITHMS NotesDocument74 pagesDATA STRUCTURE AND ALGORITHMS NotesBASSIENo ratings yet
- AD 331 - Open Top Box Girders For BridgesDocument2 pagesAD 331 - Open Top Box Girders For Bridgessymon ellimacNo ratings yet
- 5.case ToolsDocument16 pages5.case ToolsﱞﱞﱞﱞﱞﱞﱞﱞﱞﱞﱞﱞﱞﱞﱞﱞﱞﱞﱞﱞﱞﱞﱞﱞNo ratings yet
- DS - NotesDocument289 pagesDS - NotesSrinivas YarrapothuNo ratings yet
- Dewan KG Perwira Jaya 1Document1 pageDewan KG Perwira Jaya 1Fahmie SuhaimiNo ratings yet
- WEEK 1-MaterialDocument12 pagesWEEK 1-MaterialaaquibcaptainamericaNo ratings yet
- Unit 1 - 1Document3 pagesUnit 1 - 1Vijay ManeNo ratings yet
- AMIE DataStructure NotsDocument123 pagesAMIE DataStructure NotsNizam DeenNo ratings yet
- Introduction To Data Structures and Algorithm AnalysisDocument47 pagesIntroduction To Data Structures and Algorithm AnalysismrtvuranNo ratings yet
- Introduction To Data StructureDocument7 pagesIntroduction To Data StructureademolaNo ratings yet
- Kebere Goshu: Bahir Dar UniversityDocument22 pagesKebere Goshu: Bahir Dar UniversityTadele Molla ታደለ ሞላNo ratings yet
- Complexity Analysis of AlgorithmsDocument12 pagesComplexity Analysis of AlgorithmsSaad GhouriNo ratings yet
- Chapter 1Document62 pagesChapter 1tasheebedaneNo ratings yet
- BCAS Project Data Structures and AlgorithmDocument29 pagesBCAS Project Data Structures and AlgorithmDiluxan SoNo ratings yet
- cmsc420 Fall2020 LectsDocument156 pagescmsc420 Fall2020 LectsAnthony-Dimitri ANo ratings yet
- cmsc420 Fall2019 LectsDocument154 pagescmsc420 Fall2019 LectsLafoot BabuNo ratings yet
- Chapter 1 ALGODocument4 pagesChapter 1 ALGOAbraham woldeNo ratings yet
- CS350-CH01 - Data Structures and AlgorithmsDocument34 pagesCS350-CH01 - Data Structures and AlgorithmsprafullsinghNo ratings yet
- Data Structures and DBMS For CAD Systems - A ReviewDocument9 pagesData Structures and DBMS For CAD Systems - A ReviewseventhsensegroupNo ratings yet
- Adbms 2070-2076Document60 pagesAdbms 2070-2076adfsga artgasdgNo ratings yet
- Lecture 1-Introduction: Data Structure and Algorithm AnalysisDocument27 pagesLecture 1-Introduction: Data Structure and Algorithm Analysissami damtewNo ratings yet
- Unit 1 - Data Structure - WWW - Rgpvnotes.inDocument9 pagesUnit 1 - Data Structure - WWW - Rgpvnotes.inswatikhushi943No ratings yet
- Data Structures Interview Questions Set - 1Document3 pagesData Structures Interview Questions Set - 1Swastik AcharyaNo ratings yet
- Chapter 1+DSTRUDocument48 pagesChapter 1+DSTRULeary John TambagahanNo ratings yet
- Active Database: IS Department, AASTMT Cairo, EgyptDocument6 pagesActive Database: IS Department, AASTMT Cairo, EgyptAbdullah_Rady_8844No ratings yet
- Title: Powerful Basic Concepts of Database System Target Population: Second Year BSCS/ICT and First Year ACT Students III - OverviewDocument6 pagesTitle: Powerful Basic Concepts of Database System Target Population: Second Year BSCS/ICT and First Year ACT Students III - OverviewArnel CuetoNo ratings yet
- Complete Doc - LavanyaDocument95 pagesComplete Doc - LavanyaHarikrishnan ShunmugamNo ratings yet
- Problem Definition 2. Objective 3. Data Base Concept 4. Oracle Data Base 5. Environment and Tools Used VC++ Odbc 6.implementation & ResultDocument35 pagesProblem Definition 2. Objective 3. Data Base Concept 4. Oracle Data Base 5. Environment and Tools Used VC++ Odbc 6.implementation & ResultSatu Aseem BansalNo ratings yet
- MC0076 Q. What Do You Understand by Information Processes Data?Document10 pagesMC0076 Q. What Do You Understand by Information Processes Data?Shilpa AshokNo ratings yet
- Chapter 1 - Algorithm Analysis ConceptDocument15 pagesChapter 1 - Algorithm Analysis ConceptGetaneh AwokeNo ratings yet
- Data - Structure NotesDocument72 pagesData - Structure Notespa7pkjNo ratings yet
- AA-Test-1 - HandoutDocument11 pagesAA-Test-1 - HandoutDM STUDIO TUBENo ratings yet
- UntitledDocument6 pagesUntitledAnthony GozoNo ratings yet
- Object-Oriented Programm Ing: Hapter 1Document56 pagesObject-Oriented Programm Ing: Hapter 1Aakash Deep RawatNo ratings yet
- 07 IismDocument49 pages07 IismLuminita Maria TrifuNo ratings yet
- Ans: A: 1. Describe The Following: Dimensional ModelDocument8 pagesAns: A: 1. Describe The Following: Dimensional ModelAnil KumarNo ratings yet
- Chapter 1.0 Introduction To Algorithm 4th EditionDocument4 pagesChapter 1.0 Introduction To Algorithm 4th EditionGiovanni Israel Alvarez OsorioNo ratings yet
- Case Tools:: Matrices, Hierarchies, Process ModelingDocument10 pagesCase Tools:: Matrices, Hierarchies, Process ModelingAndre BocoNo ratings yet
- MC0076 Q. What Do You Understand by Information Processes Data?Document10 pagesMC0076 Q. What Do You Understand by Information Processes Data?Shilpa AshokNo ratings yet
- VillanuevaMI PrelimsWE1Document4 pagesVillanuevaMI PrelimsWE1Mico VillanuevaNo ratings yet
- Software Modelling and Design: Unit IIIIDocument57 pagesSoftware Modelling and Design: Unit IIIIvbcvbcvbNo ratings yet
- Assignment TasksDocument5 pagesAssignment TasksLaiza Cristella SarayNo ratings yet
- Introduction To Database Systems: Responsible Persons: Stephan Nebiker, Susanne BleischDocument24 pagesIntroduction To Database Systems: Responsible Persons: Stephan Nebiker, Susanne BleischRishikesh JatekarNo ratings yet
- Unit V PDFDocument12 pagesUnit V PDFRoshan ShresthaNo ratings yet
- The Role of Planning in Grid ComputingDocument10 pagesThe Role of Planning in Grid ComputingquamrulahsanNo ratings yet
- A Brief Survey On Data Mining For Biological and Environmental Problems.Document46 pagesA Brief Survey On Data Mining For Biological and Environmental Problems.Harikrishnan ShunmugamNo ratings yet
- Block Introduction: Unit 1 Introduction To Object Oriented Database Management System Relational ModelDocument50 pagesBlock Introduction: Unit 1 Introduction To Object Oriented Database Management System Relational ModelalwaysharshaNo ratings yet
- Recommended BooksDocument24 pagesRecommended BooksnouraizNo ratings yet
- Principles of Object Oriented Systems: Software Engineering DepartmentDocument34 pagesPrinciples of Object Oriented Systems: Software Engineering DepartmentQuynh KhuongNo ratings yet
- Object Oriented Analysis and Design UNIT-1Document41 pagesObject Oriented Analysis and Design UNIT-1Maha LakshmiNo ratings yet
- BCA Data Structures NotesDocument24 pagesBCA Data Structures NotesBittuNo ratings yet
- Decimal To Binary, Octal and Hexadecimal Convertor Using StackDocument26 pagesDecimal To Binary, Octal and Hexadecimal Convertor Using Stackmaneesh sNo ratings yet
- Data Structures and Algorithms BBIT 2.2 L1Document5 pagesData Structures and Algorithms BBIT 2.2 L1wanjiku kibuiNo ratings yet
- Data Structure QuestionsDocument9 pagesData Structure Questionsujjawalsharma507No ratings yet
- Data StructuresDocument225 pagesData Structuresyopmail1comaaaayopmail.comNo ratings yet
- Algorithms and Data Structures: An Easy Guide to Programming SkillsFrom EverandAlgorithms and Data Structures: An Easy Guide to Programming SkillsNo ratings yet
- Restrict The Rows Returned Using The WHERE Condition: Module of InstructionDocument13 pagesRestrict The Rows Returned Using The WHERE Condition: Module of InstructionJoshua RecintoNo ratings yet
- Locomotor and Non-Locomotor ActivitiesDocument2 pagesLocomotor and Non-Locomotor ActivitiesJoshua RecintoNo ratings yet
- CASE STUDY IN NETWORK FUNDAMENTALS - For MergeDocument58 pagesCASE STUDY IN NETWORK FUNDAMENTALS - For MergeJoshua RecintoNo ratings yet
- Feature 3rd GDocument2 pagesFeature 3rd GJoshua RecintoNo ratings yet
- Proposal and Case StudyDocument75 pagesProposal and Case StudyJoshua RecintoNo ratings yet
- Recinto Joshua MP1Document10 pagesRecinto Joshua MP1Joshua RecintoNo ratings yet
- Noyce of Fairchild Semiconductor. The Use of IC Chip Increased TheDocument2 pagesNoyce of Fairchild Semiconductor. The Use of IC Chip Increased TheJoshua RecintoNo ratings yet
- Title ProposalDocument1 pageTitle ProposalJoshua RecintoNo ratings yet
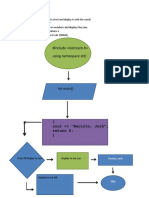
- #Include Using Namespace STD : (Cout "Recinto, Josh" Return 0 )Document1 page#Include Using Namespace STD : (Cout "Recinto, Josh" Return 0 )Joshua RecintoNo ratings yet
- TechwriteDocument39 pagesTechwriteJoshua RecintoNo ratings yet
- DimalantaDocument1 pageDimalantaJoshua RecintoNo ratings yet
- Abstract Hi-Tech Hexagons PowerPoint TemplatesDocument49 pagesAbstract Hi-Tech Hexagons PowerPoint Templatesmultimedia kbuNo ratings yet
- AIRDOPES True Wireless Series Walkthrough and FAQsDocument150 pagesAIRDOPES True Wireless Series Walkthrough and FAQskarthikeyan rajendranNo ratings yet
- Exchange 2013 DAG - Database SwitchoverDocument44 pagesExchange 2013 DAG - Database SwitchoverNeo LiveNo ratings yet
- FT4015 Parts ManualDocument256 pagesFT4015 Parts ManualCaroline DanielNo ratings yet
- UCLM ENGINEERING TSHIRT (MECHANICAL ENGINEERING) (Responses) - Form Responses 1Document1 pageUCLM ENGINEERING TSHIRT (MECHANICAL ENGINEERING) (Responses) - Form Responses 1Mahusay Neil DominicNo ratings yet
- CH - 08 - #1 Distortion CriteriaDocument9 pagesCH - 08 - #1 Distortion CriteriaSh MNo ratings yet
- HD11 - Ship SpecificationDocument1 pageHD11 - Ship SpecificationLuu Quang HoaNo ratings yet
- Fyreye Conventional Ultra-Violet Flame Detector: (FEUV2000)Document1 pageFyreye Conventional Ultra-Violet Flame Detector: (FEUV2000)motaNo ratings yet
- Week 1 Course Plan IntroductionDocument10 pagesWeek 1 Course Plan IntroductioncakegurlNo ratings yet
- CSE3001Document34 pagesCSE3001Majety S LskshmiNo ratings yet
- Interviewer User GuideDocument7 pagesInterviewer User GuideJa NiceNo ratings yet
- Adaptor Otg: NO Description Stok Harga (Per PCS)Document10 pagesAdaptor Otg: NO Description Stok Harga (Per PCS)MARSELO MELKYNo ratings yet
- تقرير مادة الرسم الهندسيDocument7 pagesتقرير مادة الرسم الهندسيHASHIM ADELNo ratings yet
- Impcat of Climate Change On Urban Drainage of Goranchatbari DhakaDocument16 pagesImpcat of Climate Change On Urban Drainage of Goranchatbari DhakaAvisheak PalNo ratings yet
- GROUP II PPT (2 5pm) Chapter 7, Food IndustryDocument29 pagesGROUP II PPT (2 5pm) Chapter 7, Food IndustryMaryjo RamirezNo ratings yet
- SRN/ SEN15/ SEN25: General Electric HornDocument4 pagesSRN/ SEN15/ SEN25: General Electric HornRigoberto GomezNo ratings yet
- Budget LP (Week 1) 2020-2021Document2 pagesBudget LP (Week 1) 2020-2021Kalabit PengeNo ratings yet
- Whaleys Encyclopedic Dictionary of Magic 1584-2000 PDFDocument2 pagesWhaleys Encyclopedic Dictionary of Magic 1584-2000 PDFmanuel barriosNo ratings yet
- Sciencedirect Paper Received - Libdl - IrDocument9 pagesSciencedirect Paper Received - Libdl - IrSadegh AhmadiNo ratings yet
- Humastar 300Sr - : Software Update ProcedureDocument8 pagesHumastar 300Sr - : Software Update Procedureluisoft88No ratings yet
- Tele Room DimensionDocument23 pagesTele Room DimensionRobbin BajpaiNo ratings yet
- Unix and Shell Programming SolutionsDocument54 pagesUnix and Shell Programming SolutionsDeejay Sahir100% (2)
- Savage Et Al 2010Document17 pagesSavage Et Al 2010Integrante TreceNo ratings yet
- 73-Article Text-136-1-10-20200623Document10 pages73-Article Text-136-1-10-20200623Vero AndopaNo ratings yet
- 4GR-FES Engine WiringDocument14 pages4GR-FES Engine WiringMillington MambweNo ratings yet
- Regression Diagnostic Ii: Heteroscedasticity: Damodar GujaratiDocument7 pagesRegression Diagnostic Ii: Heteroscedasticity: Damodar GujaratisampritcNo ratings yet
- Frost Fire Katana ThoriumDocument4 pagesFrost Fire Katana ThoriumDudika 5704No ratings yet