You might also like
- Words, Wit, and Wonder: Writing Your Own PoemFrom EverandWords, Wit, and Wonder: Writing Your Own PoemRating: 4.5 out of 5 stars4.5/5 (4)
- 07 StringsDocument15 pages07 Stringsyoung bloodNo ratings yet
- ACTIVITY On METER and SCANSIONDocument2 pagesACTIVITY On METER and SCANSIONRezitte Jonathan Annika MablesNo ratings yet
- Phonetic Book Latest-2Document208 pagesPhonetic Book Latest-2lynn htetNo ratings yet
- Eng Sound DevicesDocument17 pagesEng Sound DevicesNoob KidNo ratings yet
- Rhythm and Meter in English PoetryDocument5 pagesRhythm and Meter in English PoetryNicolas OjedaNo ratings yet
- Ch. L. Hanon - Pijanista VirtuozDocument42 pagesCh. L. Hanon - Pijanista VirtuozTihomir Books and Manuals100% (3)
- PracticeDocument16 pagesPracticeshh shhNo ratings yet
- Handouts in LinguisticsDocument14 pagesHandouts in LinguisticsMA. CARLA JOANNA FABILANo ratings yet
- Worksheets HMDocument7 pagesWorksheets HMgagaismcsjsNo ratings yet
- Worksheets HMDocument7 pagesWorksheets HMgagaismcsjsNo ratings yet
- Worksheets HMDocument7 pagesWorksheets HMHssgshsvvsNo ratings yet
- Worksheets HMDocument7 pagesWorksheets HMgagaismcsjsNo ratings yet
- Elements of PoetryDocument32 pagesElements of PoetryAlan FlorenceNo ratings yet
- PoetryDocument38 pagesPoetryRachel Jane TanNo ratings yet
- Cambridge Primary English Phonics Workbook A - PublicDocument13 pagesCambridge Primary English Phonics Workbook A - Publicbmkannan197350% (8)
- English in Mind 3. Student's Book (PDFDrive) - Split - 2Document14 pagesEnglish in Mind 3. Student's Book (PDFDrive) - Split - 2MessigoNo ratings yet
- Rhythm, Meter, and Scansion Made EasyDocument7 pagesRhythm, Meter, and Scansion Made EasyGrace Kelly100% (1)
- Lexicology HomeworkDocument7 pagesLexicology HomeworkDaniela IsaevichNo ratings yet
- Teaching & PerformingDocument90 pagesTeaching & PerformingParag ShrivastavaNo ratings yet
- There Will Come Soft RainsDocument8 pagesThere Will Come Soft Rainsapi-243289491No ratings yet
- Understanding Poetry ROSEDocument98 pagesUnderstanding Poetry ROSEChe RishNo ratings yet
- Poetic MeterFeetStanzasDocument30 pagesPoetic MeterFeetStanzasMcFadden 07No ratings yet
- 2016 Introduction To Literature CoursebookDocument61 pages2016 Introduction To Literature CoursebookKristína PalackováNo ratings yet
- NERO332 Document 6Document4 pagesNERO332 Document 6Sultan MezaNo ratings yet
- EngA M5 Prep For Summative Week 1Document11 pagesEngA M5 Prep For Summative Week 1Linda Kozma-VigNo ratings yet
- PoetryDocument19 pagesPoetryPhoebe PitallanoNo ratings yet
- Phonetic Alphabets Reference PDFDocument1 pagePhonetic Alphabets Reference PDFshfileNo ratings yet
- Scansion RhymeDocument2 pagesScansion Rhymeroberto.colombo127No ratings yet
- Phonetic Alphabets Reference: AntimoonDocument1 pagePhonetic Alphabets Reference: AntimoonAlex IsNo ratings yet
- Introduction To Poetry: Presented By: Hussam MohammedDocument52 pagesIntroduction To Poetry: Presented By: Hussam MohammeddaekmmmmNo ratings yet
- Intro To Poetry 1Document51 pagesIntro To Poetry 1Rhonel Galutera100% (1)
- English Elements of Poetry QuizDocument10 pagesEnglish Elements of Poetry QuizAnonymous vWGIbfP100% (1)
- 9 FSMDocument6 pages9 FSMJoaquínNo ratings yet
- Handouts Session2Document13 pagesHandouts Session2Евгения ХвостенкоNo ratings yet
- What Is PoetryDocument36 pagesWhat Is PoetryAldila wahyuniNo ratings yet
- ExercisesDocument5 pagesExercisesAydana NurlanNo ratings yet
- Intro To Poetry 1Document51 pagesIntro To Poetry 1Lilia RaniNo ratings yet
- Poetry. Formal AspectsDocument3 pagesPoetry. Formal AspectsMaría PFNo ratings yet
- Introduction To PoetryDocument8 pagesIntroduction To PoetryThea RañolaNo ratings yet
- University The Punjab HS.: Euesfion AllDocument11 pagesUniversity The Punjab HS.: Euesfion AllKhushbakhat BilalNo ratings yet
- PoetryDocument68 pagesPoetryLhea IldefonsoNo ratings yet
- Monochord MattersDocument24 pagesMonochord MattersLawrence DunnNo ratings yet
- Lesson 3 PHONICSDocument5 pagesLesson 3 PHONICS20223327No ratings yet
- The Mutation Al Alchemy TarotDocument424 pagesThe Mutation Al Alchemy TarotPatrícia Carla100% (1)
- Wishart, Trevor - FABULOUS PARIS A Virtual Oratorio PDFDocument3 pagesWishart, Trevor - FABULOUS PARIS A Virtual Oratorio PDFvalsNo ratings yet
- Seminar 1 2017Document3 pagesSeminar 1 2017FerreNo ratings yet
- Literary Devices MacbethDocument10 pagesLiterary Devices MacbethDaynee Mavel PascualNo ratings yet
- MAJOR ReviewerDocument46 pagesMAJOR ReviewerIyen Dalisay100% (2)
- Lesson 3 Poetry and Its ElementsDocument44 pagesLesson 3 Poetry and Its ElementsMoira Kelly ToleroNo ratings yet
- Intro Poetry 2015Document52 pagesIntro Poetry 2015Тимур ИбрагимовNo ratings yet
- Resúmenes y Análisis Literary TextsDocument66 pagesResúmenes y Análisis Literary TextsVero GuigeNo ratings yet
- Nuevas Ideas para Enseñar VocabularioDocument26 pagesNuevas Ideas para Enseñar VocabularioJeanJames KöningNo ratings yet
- First Species CounterpointDocument2 pagesFirst Species CounterpointJoshua Marvin CastilloNo ratings yet
- Alphabet Juice: The Energies, Gists, and Spirits of Letters, Words, and Combinations Thereof; Their Roots, Bones, Innards, Piths, Pips, and Secret Parts, Tinctures, Tonics, and Essences; With Examples of Their Usage Foul and SavoryFrom EverandAlphabet Juice: The Energies, Gists, and Spirits of Letters, Words, and Combinations Thereof; Their Roots, Bones, Innards, Piths, Pips, and Secret Parts, Tinctures, Tonics, and Essences; With Examples of Their Usage Foul and SavoryRating: 3.5 out of 5 stars3.5/5 (86)
- Integrating New Technologies Into The Power System: Long Range System PlanningDocument26 pagesIntegrating New Technologies Into The Power System: Long Range System PlanningEdmund ZinNo ratings yet
- 5 Natural Gasvs Electric RestructuringDocument26 pages5 Natural Gasvs Electric RestructuringEdmund ZinNo ratings yet
- CS 294-73 Software Engineering For Scientific Computing Lecture 14: Development For PerformanceDocument40 pagesCS 294-73 Software Engineering For Scientific Computing Lecture 14: Development For PerformanceEdmund ZinNo ratings yet
- CS 294-73 Software Engineering For Scientific Computing Lecture 14: Performance On Cache-Based Systems, Profiling & Tips For C++Document34 pagesCS 294-73 Software Engineering For Scientific Computing Lecture 14: Performance On Cache-Based Systems, Profiling & Tips For C++Edmund ZinNo ratings yet
- CS 294-73 Software Engineering For Scientific Computing Lecture 16: Multigrid (Structured Grids Revisited)Document32 pagesCS 294-73 Software Engineering For Scientific Computing Lecture 16: Multigrid (Structured Grids Revisited)Edmund ZinNo ratings yet
- 3 Economic Markets For PowerDocument42 pages3 Economic Markets For PowerEdmund ZinNo ratings yet
- FERC & Electric Industry RestructuringDocument26 pagesFERC & Electric Industry RestructuringEdmund ZinNo ratings yet
- 2 International CompetitionDocument25 pages2 International CompetitionEdmund ZinNo ratings yet
- CS 294-73 Software Engineering For Scientific Computing Lecture 17: Final Project Homework #4Document46 pagesCS 294-73 Software Engineering For Scientific Computing Lecture 17: Final Project Homework #4Edmund ZinNo ratings yet
- CS 294-73 Software Engineering For Scientific Computing Lecture 13: Homework 3 Final ProjectDocument47 pagesCS 294-73 Software Engineering For Scientific Computing Lecture 13: Homework 3 Final ProjectEdmund ZinNo ratings yet
- CS 294-73 Software Engineering For Scientific Computing Lecture 18: Performance Measurements For MultigridDocument20 pagesCS 294-73 Software Engineering For Scientific Computing Lecture 18: Performance Measurements For MultigridEdmund ZinNo ratings yet
- CS 294-73 Software Engineering For Scientific Computing Lecture 8: Unstructured Grids and Sparse MatricesDocument25 pagesCS 294-73 Software Engineering For Scientific Computing Lecture 8: Unstructured Grids and Sparse MatricesEdmund ZinNo ratings yet
- CS 294-73 Software Engineering For Scientific Computing Lecture 12: Particle Methods Homework 3Document32 pagesCS 294-73 Software Engineering For Scientific Computing Lecture 12: Particle Methods Homework 3Edmund ZinNo ratings yet
- CS 294-73 Software Engineering For Scientific Computing: Pcolella@berkeley - Edu Pcolella@lbl - GovDocument39 pagesCS 294-73 Software Engineering For Scientific Computing: Pcolella@berkeley - Edu Pcolella@lbl - GovEdmund ZinNo ratings yet
- CS 294-73 Software Engineering For Scientific ComputingDocument31 pagesCS 294-73 Software Engineering For Scientific ComputingEdmund ZinNo ratings yet
- CS 294-73 Software Engineering For Scientific Computing Lecture 6: Git, Homework #1, Coding StandardsDocument32 pagesCS 294-73 Software Engineering For Scientific Computing Lecture 6: Git, Homework #1, Coding StandardsEdmund ZinNo ratings yet
- CS 294-73 Software Engineering For Scientific ComputingDocument40 pagesCS 294-73 Software Engineering For Scientific ComputingEdmund ZinNo ratings yet
- CS 294-73 Software Engineering For Scientific Computing Lecture 9: Dense Linear AlgebraDocument43 pagesCS 294-73 Software Engineering For Scientific Computing Lecture 9: Dense Linear AlgebraEdmund ZinNo ratings yet
- CS 294-73 Software Engineering For Scientific ComputingDocument42 pagesCS 294-73 Software Engineering For Scientific ComputingEdmund ZinNo ratings yet
- 4 Tail Inequalities: 4.1 Markov's InequalityDocument11 pages4 Tail Inequalities: 4.1 Markov's InequalityEdmund ZinNo ratings yet
- CS 294-73 Software Engineering For Scientific ComputingDocument35 pagesCS 294-73 Software Engineering For Scientific ComputingEdmund ZinNo ratings yet
- 3 Randomized Binary Search Trees: 3.1 TreapsDocument15 pages3 Randomized Binary Search Trees: 3.1 TreapsEdmund ZinNo ratings yet
- Barenberg A - 208 PDFDocument7 pagesBarenberg A - 208 PDFEdmund ZinNo ratings yet
- 2 Nuts and Bolts: 2.1 Deterministic vs. Randomized AlgorithmsDocument13 pages2 Nuts and Bolts: 2.1 Deterministic vs. Randomized AlgorithmsEdmund ZinNo ratings yet
- 1.1 Discrete Probability SpacesDocument23 pages1.1 Discrete Probability SpacesEdmund ZinNo ratings yet
- B SC Economics Honours 2013-14 Syllabus PDFDocument22 pagesB SC Economics Honours 2013-14 Syllabus PDFEdmund ZinNo ratings yet
- Article7 PDFDocument22 pagesArticle7 PDFEdmund ZinNo ratings yet
- The Urban-Rural Differences of Inflation in ChinaDocument23 pagesThe Urban-Rural Differences of Inflation in ChinaEdmund ZinNo ratings yet
- Homework 2 For NetworksDocument4 pagesHomework 2 For NetworksOburu David KatandiNo ratings yet
- Digital Marketing Strategy Guide: CloudspottingDocument17 pagesDigital Marketing Strategy Guide: Cloudspottingbrian steelNo ratings yet
- Programmer Manual TDS 340 PDFDocument164 pagesProgrammer Manual TDS 340 PDFMegan SmithNo ratings yet
- PDF File From ALV - SAP Q&ADocument3 pagesPDF File From ALV - SAP Q&Aphogat projectNo ratings yet
- Computers For Africa Solutions Company ProfileDocument8 pagesComputers For Africa Solutions Company ProfileMwila KasondeNo ratings yet
- CANOpen DS301Document129 pagesCANOpen DS301Judin HNo ratings yet
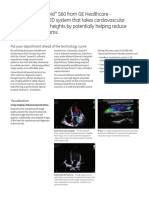
- Vivid S60 Brochure-2Document1 pageVivid S60 Brochure-2Quan NguyenngocNo ratings yet
- The SQL EXISTS OperatorDocument5 pagesThe SQL EXISTS OperatorBharathNo ratings yet
- Mid 221Document28 pagesMid 221danecuprijaNo ratings yet
- Arrays: LengthDocument11 pagesArrays: LengthBilal MuhammadNo ratings yet
- Koralgo Presentation For Intelak - Feb 2022Document11 pagesKoralgo Presentation For Intelak - Feb 2022Lax KutyNo ratings yet
- Installation Guide Bare 2WD V1.0.0Document26 pagesInstallation Guide Bare 2WD V1.0.0anuruddhadsNo ratings yet
- A S A P S: Ccelerated Urface Rea and Orosimetry YstemDocument373 pagesA S A P S: Ccelerated Urface Rea and Orosimetry Ystemmaterials porousNo ratings yet
- Transaction Id: 160216DEUTDEFFXXX886793 (DB REF) : Receiver Bo Provide Receiver Bo ProvideDocument2 pagesTransaction Id: 160216DEUTDEFFXXX886793 (DB REF) : Receiver Bo Provide Receiver Bo Providebimobimoprabowo100% (1)
- CP Lab ManualDocument48 pagesCP Lab ManualBhagyaNo ratings yet
- WTM Synch-EDocument11 pagesWTM Synch-EAhmed YunesNo ratings yet
- DMS Annexure 2 (Group 18) Deepak GaundDocument12 pagesDMS Annexure 2 (Group 18) Deepak Gaund68 DEEPAK GAUNDNo ratings yet
- NEC Datasheet P402-EnglishDocument2 pagesNEC Datasheet P402-EnglishbuzduceanuNo ratings yet
- PDFDocument3 pagesPDFLuis Alberto González Campos100% (1)
- Basics of 3D Printing PDFDocument62 pagesBasics of 3D Printing PDFnihco gallo100% (4)
- MIS Report On Online BankingDocument31 pagesMIS Report On Online BankingMurtaza MoizNo ratings yet
- Correspondence in SAPDocument15 pagesCorrespondence in SAPshamshu zamanNo ratings yet
- Software Requirement SpecificationDocument10 pagesSoftware Requirement SpecificationAyush Agrawal0% (1)
- LTE Optimization Tool PresentationDocument12 pagesLTE Optimization Tool PresentationAhmed Mansour SereerNo ratings yet
- Methods and Applications For Modeling and Simulation of Complex SystemsDocument282 pagesMethods and Applications For Modeling and Simulation of Complex Systemssu binNo ratings yet
- TCS NQT Problem StatementsDocument9 pagesTCS NQT Problem StatementsSrinivas Ch (Vasu)No ratings yet
- Lenovo Thinkpad t14 I7 10510u 14 16 512 Win 10 P 20s00013feDocument3 pagesLenovo Thinkpad t14 I7 10510u 14 16 512 Win 10 P 20s00013feELYOU89No ratings yet
- Stateful Widget Lifecycle: ExampleDocument6 pagesStateful Widget Lifecycle: ExampleAmit VermaNo ratings yet
- An Introduction To JavaScriptDocument6 pagesAn Introduction To JavaScriptJjfreak ReedsNo ratings yet
- Codebasics BrochureDocument50 pagesCodebasics BrochureManikandan SundaramNo ratings yet