You might also like
- MyCANIC User ManualDocument19 pagesMyCANIC User ManualSaddam Basim100% (2)
- MIB2 PQ unit guideDocument28 pagesMIB2 PQ unit guidetonyNo ratings yet
- Péugeut 206Document4 pagesPéugeut 206diegoNo ratings yet
- HP Pavilion TX1000 SchematicsDocument36 pagesHP Pavilion TX1000 Schematicsmeng798651100% (1)
- SM 36Document555 pagesSM 36Györök Peter100% (1)
- Challenging Cognitive Distortions HealthyPsych - ComDocument1 pageChallenging Cognitive Distortions HealthyPsych - ComLeila MargaridaNo ratings yet
- What is Cultural Heritage and Why it's ImportantDocument3 pagesWhat is Cultural Heritage and Why it's ImportantMiguel A. González LópezNo ratings yet
- Toshiba X-Ray Tube Product InfoDocument10 pagesToshiba X-Ray Tube Product InfoJairo ManzanedaNo ratings yet
- Polity by LaxmikantDocument3 pagesPolity by LaxmikantJk S50% (6)
- Flexray Module Training: Ti Safety MicrocontrollerDocument61 pagesFlexray Module Training: Ti Safety MicrocontrollerGuilherme PfeilstickerNo ratings yet
- FBAUTO-JS-v1 19 5Document169 pagesFBAUTO-JS-v1 19 5Barkez 77No ratings yet
- STAG TAP 01 02 Manual v1.3.5 Eng PDFDocument31 pagesSTAG TAP 01 02 Manual v1.3.5 Eng PDFประยงค์ แก่นจัทร์No ratings yet
- Car Compatible List For M501Document160 pagesCar Compatible List For M501Julian Jose GonzalezNo ratings yet
- BMW EBA 361831 Rear View Camera Retrofit InstructionsDocument14 pagesBMW EBA 361831 Rear View Camera Retrofit InstructionsisoxNo ratings yet
- Aakhri Jang e Azeem (Final Great War)Document18 pagesAakhri Jang e Azeem (Final Great War)WaMin Ansaril Mahdi HussainNo ratings yet
- LPC2148 Education Board Users Guide-Version 3.0 Rev CDocument38 pagesLPC2148 Education Board Users Guide-Version 3.0 Rev Cbujor_octavianNo ratings yet
- Fuses 407 AlternantiveDocument6 pagesFuses 407 AlternantiveCiprian NicolescuNo ratings yet
- Adaptronic Select ECU ManualDocument103 pagesAdaptronic Select ECU ManualDiogo VieiraNo ratings yet
- Audi A4 No. 303 / 1: 3.0 L - Injection Engine (162 KW - Motronic - 6 Cylinder) Engine Code AVKDocument20 pagesAudi A4 No. 303 / 1: 3.0 L - Injection Engine (162 KW - Motronic - 6 Cylinder) Engine Code AVKDaniel BuenoNo ratings yet
- ServiceDocument126 pagesServiceNaite SantosNo ratings yet
- Shopid Itemid Main - Name Product - NameDocument2,216 pagesShopid Itemid Main - Name Product - NameTrương Cao Hoàng MyNo ratings yet
- Control Servo With Visual Basic 2008Document7 pagesControl Servo With Visual Basic 2008Juan Pablo EspinalNo ratings yet
- Audi A6 2005-2009 Dash PinoutsDocument1 pageAudi A6 2005-2009 Dash Pinoutsosquitar20No ratings yet
- CG ASsignmentDocument20 pagesCG ASsignmentGoyal AdityaNo ratings yet
- Siglas Padrão OBDDocument35 pagesSiglas Padrão OBDCleiton AviNo ratings yet
- Bal22 La d803pDocument57 pagesBal22 La d803pAndres DarwinNo ratings yet
- 12V To 220V 100W InverterDocument2 pages12V To 220V 100W InverterYudi DopiNo ratings yet
- Condition: Technical Service BulletinDocument22 pagesCondition: Technical Service BulletinOleksiy OsiychukNo ratings yet
- Volkswagen Golf Mk8Document8 pagesVolkswagen Golf Mk8robertoNo ratings yet
- Flow DiagramDocument302 pagesFlow DiagramKaren Nallely MejiaNo ratings yet
- SimView ManualDocument18 pagesSimView ManualQweartyNo ratings yet
- Manual Scanmaster ELM327Document9 pagesManual Scanmaster ELM327Recambios FyRNo ratings yet
- Ncs DummyDocument45 pagesNcs DummyAdyNo ratings yet
- Ramdump Modem 2023-05-11 22-29-00 PropsDocument15 pagesRamdump Modem 2023-05-11 22-29-00 PropsFernando ValderramaNo ratings yet
- FiatECUScan - Read ECUs on Fiat, Alfa, LanciaDocument127 pagesFiatECUScan - Read ECUs on Fiat, Alfa, LanciaAlessandro De TommasiNo ratings yet
- Ecus DatabaseDocument16 pagesEcus DatabaseAirormexNo ratings yet
- Carlistfortagkeytool Avdi Simontouch Keyprogtools ProgrammingDocument13 pagesCarlistfortagkeytool Avdi Simontouch Keyprogtools ProgrammingEjejNo ratings yet
- Technical Manual Calibration Software For The Alisei Injection SystemDocument37 pagesTechnical Manual Calibration Software For The Alisei Injection SystemzilotNo ratings yet
- GPS Overview For NERPDocument5 pagesGPS Overview For NERPRaymart Florentino100% (1)
- ১০ টি হাসির শ্রুতি নাটকDocument62 pages১০ টি হাসির শ্রুতি নাটকabhilash sinhaNo ratings yet
- DSM Ecu Extended Map GuideDocument4 pagesDSM Ecu Extended Map GuideJohn MongielloNo ratings yet
- Manual Service-En USDocument590 pagesManual Service-En USparsec82No ratings yet
- Module of User Deined Function3Document30 pagesModule of User Deined Function3Vinayak SharmaNo ratings yet
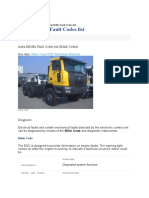
- Astra HD8Ec Fault Codes ListDocument5 pagesAstra HD8Ec Fault Codes ListCossack MykhailoNo ratings yet
- SUPPORT VWAGEA888EngineTuning 220922 1305Document21 pagesSUPPORT VWAGEA888EngineTuning 220922 1305mohnaserNo ratings yet
- Number System in C ProgrammingDocument78 pagesNumber System in C ProgrammingKashish GulatiNo ratings yet
- Mystique-1 Shark Bay Block Diagram: Project Code: 91.4LY01.001 PCB (Raw Card) : 12298-2Document80 pagesMystique-1 Shark Bay Block Diagram: Project Code: 91.4LY01.001 PCB (Raw Card) : 12298-2Ion PetruscaNo ratings yet
- Datashhet MS-7C91 PDFDocument72 pagesDatashhet MS-7C91 PDFRBN HMNo ratings yet
- Automotive Abbreviations: /min °C °DK °F °KW °NW 1/CM3 1L 1R 2L 2R 2WD 3L 3R 4was 4WD 4WS 4X4 A A/DDocument45 pagesAutomotive Abbreviations: /min °C °DK °F °KW °NW 1/CM3 1L 1R 2L 2R 2WD 3L 3R 4was 4WD 4WS 4X4 A A/DAlin AlexandruNo ratings yet
- Best automotive diagnostic tool on marketDocument227 pagesBest automotive diagnostic tool on marketВиктор ВикторовичNo ratings yet
- Bipolar SramDocument33 pagesBipolar SramRavinder VijayranNo ratings yet
- Ecu Sensor Simulation mst9000 InstructionDocument9 pagesEcu Sensor Simulation mst9000 InstructionJorge EspinoNo ratings yet
- ReadmeDocument1 pageReadmeNicholas HarmonNo ratings yet
- STAG-200 Leads DescriptionDocument1 pageSTAG-200 Leads DescriptionGerman SalasNo ratings yet
- London Zafira A wiring diagramDocument3 pagesLondon Zafira A wiring diagramG G100% (1)
- Integrated Chassis ManagementDocument1 pageIntegrated Chassis ManagementOliver AlfaroNo ratings yet
- N1404W NXP SW Libraries For NFC Readers - Introduction v1.0 PublicDocument39 pagesN1404W NXP SW Libraries For NFC Readers - Introduction v1.0 PublicLee RickHunterNo ratings yet
- Buk9222 55aDocument13 pagesBuk9222 55aAnthony AndreyNo ratings yet
- Launch x431 Padii Manual enDocument55 pagesLaunch x431 Padii Manual enMohammed EssamNo ratings yet
- الإسراء والمعراج للامام ابن عباس - 82234Document50 pagesالإسراء والمعراج للامام ابن عباس - 82234Muhammad Al-hadedyNo ratings yet
- BMW Transmission Designations ExplainedDocument5 pagesBMW Transmission Designations ExplainedPaulGdlNo ratings yet
- Chhotaray Singh (C.S) VCGFDocument38 pagesChhotaray Singh (C.S) VCGFKrìsHna BäskēyNo ratings yet
- C++ program to create employee management systemDocument27 pagesC++ program to create employee management systemSubhamNo ratings yet
- Project Salary ManagmentDocument34 pagesProject Salary ManagmentSamir ParmarNo ratings yet
- Driver Avalon MinerDocument24 pagesDriver Avalon MineralexandrNo ratings yet
- Driver IcarusDocument47 pagesDriver IcarusalexandrNo ratings yet
- Driver KlondikeDocument28 pagesDriver KlondikealexandrNo ratings yet
- FpgautilsDocument11 pagesFpgautilsalexandrNo ratings yet
- CG MinerDocument184 pagesCG MineralexandrNo ratings yet
- Driver SPI Dragonmint t1Document27 pagesDriver SPI Dragonmint t1alexandrNo ratings yet
- Driver Spondoolies Sp10Document8 pagesDriver Spondoolies Sp10alexandrNo ratings yet
- Driver SPI Bitmine A1Document20 pagesDriver SPI Bitmine A1alexandrNo ratings yet
- Driver Bitfury16Document95 pagesDriver Bitfury16alexandrNo ratings yet
- Driver BabDocument54 pagesDriver BabalexandrNo ratings yet
- Driver BitmainDocument58 pagesDriver BitmainalexandrNo ratings yet
- UtilDocument64 pagesUtilalexandrNo ratings yet
- Driver Spondoolies Sp30 PDocument1 pageDriver Spondoolies Sp30 PalexandrNo ratings yet
- UsbutilsDocument76 pagesUsbutilsalexandrNo ratings yet
- Driver Avalon7Document47 pagesDriver Avalon7alexandrNo ratings yet
- Driver DrillbitDocument20 pagesDriver DrillbitalexandrNo ratings yet
- Driver Spondoolies Sp30Document9 pagesDriver Spondoolies Sp30alexandrNo ratings yet
- bf16 GpiodeviceDocument2 pagesbf16 GpiodevicealexandrNo ratings yet
- Hex DumpDocument2 pagesHex DumpalexandrNo ratings yet
- KlistDocument8 pagesKlistalexandrNo ratings yet
- Driver Spondoolies Sp30 PDocument1 pageDriver Spondoolies Sp30 PalexandrNo ratings yet
- Driver BitfuryDocument29 pagesDriver BitfuryalexandrNo ratings yet
- Driver AvalonDocument30 pagesDriver AvalonalexandrNo ratings yet
- Driver Avalon2Document20 pagesDriver Avalon2alexandrNo ratings yet
- KNC AsicDocument10 pagesKNC AsicalexandrNo ratings yet
- bf16 SpideviceDocument2 pagesbf16 SpidevicealexandrNo ratings yet
- Bitforce Firmware FlashDocument3 pagesBitforce Firmware FlashalexandrNo ratings yet
- A1 Board Selector CCDDocument2 pagesA1 Board Selector CCDalexandrNo ratings yet
- bf16 Bitfury16Document22 pagesbf16 Bitfury16alexandrNo ratings yet
- bf16 UartdeviceDocument3 pagesbf16 UartdevicealexandrNo ratings yet
- Natural Fibres For Composites in EthiopiaDocument12 pagesNatural Fibres For Composites in EthiopiaTolera AderieNo ratings yet
- Design of Grounding System For GIS Indoor SubstationDocument4 pagesDesign of Grounding System For GIS Indoor Substationzerferuz67% (3)
- Autoencoder Asset Pricing ModelsDocument22 pagesAutoencoder Asset Pricing ModelsEdson KitaniNo ratings yet
- Mechanical Engineering Semester SchemeDocument35 pagesMechanical Engineering Semester Schemesantvan jagtapNo ratings yet
- Odoo JS Framework Rewrite Brings New Views and TestingDocument68 pagesOdoo JS Framework Rewrite Brings New Views and TestingglobalknowledgeNo ratings yet
- Fazaia College of Education For WomenDocument10 pagesFazaia College of Education For WomenZahra TahirNo ratings yet
- Caed102: Financial MarketsDocument2 pagesCaed102: Financial MarketsXytusNo ratings yet
- Cis Bin Haider GRP LTD - HSBC BankDocument5 pagesCis Bin Haider GRP LTD - HSBC BankEllerNo ratings yet
- The Multi Faceted Nature of The Multi Grade TeacherDocument23 pagesThe Multi Faceted Nature of The Multi Grade TeacherTEDLYN JOY ESPINONo ratings yet
- Samahan NG Manggagawa NG Hanjin Vs BLRDocument11 pagesSamahan NG Manggagawa NG Hanjin Vs BLRPhrexilyn PajarilloNo ratings yet
- One SheetDocument1 pageOne Sheetadeel ghouseNo ratings yet
- DP8 Series Manual - English PDFDocument48 pagesDP8 Series Manual - English PDFluis enrique de la rosa sanchezNo ratings yet
- HW1Document1 pageHW1mohsenanNo ratings yet
- TU20Document6 pagesTU20Manikumar KNo ratings yet
- The Beatles Album Back CoverDocument1 pageThe Beatles Album Back CoverSophia AvraamNo ratings yet
- Advance Corporate StrategyDocument2 pagesAdvance Corporate StrategyPassionate_to_LearnNo ratings yet
- Assignment 1 Front Sheet: Qualification BTEC Level 4 HND Diploma in BusinessDocument14 pagesAssignment 1 Front Sheet: Qualification BTEC Level 4 HND Diploma in BusinessQuan PhanNo ratings yet
- SolidWorks Motion Tutorial 2010Document31 pagesSolidWorks Motion Tutorial 2010Hector Adan Lopez GarciaNo ratings yet
- Report of Six Months Industrial TrainingDocument38 pagesReport of Six Months Industrial TrainingJibran BashirNo ratings yet
- Best Frequency Strategies - How Often To Post On Social Media PDFDocument24 pagesBest Frequency Strategies - How Often To Post On Social Media PDFLiet CanasNo ratings yet
- Distributor AgreementDocument10 pagesDistributor Agreementsanket_hiremathNo ratings yet
- Andrija Kacic Miosic - Razgovor Ugodni Naroda Slovinskoga (1862)Document472 pagesAndrija Kacic Miosic - Razgovor Ugodni Naroda Slovinskoga (1862)paravelloNo ratings yet
- Entry Test Result MPhil 2014 PDFDocument11 pagesEntry Test Result MPhil 2014 PDFHafizAhmadNo ratings yet
- Anand FDocument76 pagesAnand FSunil BharadwajNo ratings yet
- Matrix 210N Reference Manual 2017 PDFDocument167 pagesMatrix 210N Reference Manual 2017 PDFiozsa cristianNo ratings yet