You might also like
- Computational Intelligence Applications for Text and Sentiment Data AnalysisFrom EverandComputational Intelligence Applications for Text and Sentiment Data AnalysisNo ratings yet
- NLP Report, 170280571Document32 pagesNLP Report, 170280571Jaiswal Technical MentorNo ratings yet
- Sentiment Analysis of Movie Reviews Using Machine Learning TechniquesDocument6 pagesSentiment Analysis of Movie Reviews Using Machine Learning Techniquesrojey79875No ratings yet
- Eeg Based Emotion Classification Using Deep Learning ModelsDocument4 pagesEeg Based Emotion Classification Using Deep Learning ModelsInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Survey Paper On Algorithms Used For Sentiment AnalysisDocument6 pagesSurvey Paper On Algorithms Used For Sentiment AnalysisIJRASETPublicationsNo ratings yet
- Amogh Seminar ReportDocument14 pagesAmogh Seminar ReportParth GadewarNo ratings yet
- 44-Article Text-223-2-10-20210422Document8 pages44-Article Text-223-2-10-20210422ShafNo ratings yet
- Report PDFDocument46 pagesReport PDFSumit KumarNo ratings yet
- Natural Language Processing For Analysis of Student Online Sentiment in A Postgraduate Program.Document17 pagesNatural Language Processing For Analysis of Student Online Sentiment in A Postgraduate Program.Jomar RamosNo ratings yet
- IndexDocument65 pagesIndexomkarsathe0000No ratings yet
- ThesisDocument240 pagesThesisgoNo ratings yet
- V4I9201545Document8 pagesV4I9201545KhizamuddinNo ratings yet
- Usage of Netflix by StudentsDocument15 pagesUsage of Netflix by StudentsRezaul Hossain AnikNo ratings yet
- Top JournalsDocument12 pagesTop Journalsrikaseo rikaNo ratings yet
- Maree NJDocument159 pagesMaree NJJohn DoeNo ratings yet
- Research On Chinese Emotion Classification Using BDocument15 pagesResearch On Chinese Emotion Classification Using BLmvqwNo ratings yet
- One Page Report For Event Mmar CsbsDocument7 pagesOne Page Report For Event Mmar CsbsanithatNo ratings yet
- G.H. Patel College of Engineering and Technology: Gujarat Technological UniversityDocument21 pagesG.H. Patel College of Engineering and Technology: Gujarat Technological UniversityHet ThankiNo ratings yet
- NLP Project ReportDocument27 pagesNLP Project ReportNitin kumar singhNo ratings yet
- Cattaneo-Idrobo-Titiunik 2020 CUPDocument117 pagesCattaneo-Idrobo-Titiunik 2020 CUPcharles luisNo ratings yet
- Conference Template A4 1Document6 pagesConference Template A4 1chaiNo ratings yet
- SentimentanalysisforuserreviewsusingBi LSTMself attentionbasedCNNmodelDocument16 pagesSentimentanalysisforuserreviewsusingBi LSTMself attentionbasedCNNmodelmr joneyNo ratings yet
- 40 - Sentiment Extraction From Bangla Text A Character Level Supervised Recurrent Neural Network ApproachDocument5 pages40 - Sentiment Extraction From Bangla Text A Character Level Supervised Recurrent Neural Network ApproachOffice WorkNo ratings yet
- Sentiment Analysis On Youtube CommentsDocument54 pagesSentiment Analysis On Youtube Commentshari prasad raoNo ratings yet
- Accepted Manuscript: 10.1016/j.infsof.2017.06.002Document37 pagesAccepted Manuscript: 10.1016/j.infsof.2017.06.002Kiran KumarNo ratings yet
- Data Visulization ReportDocument21 pagesData Visulization ReportRushikesh GaikheNo ratings yet
- Comparison of Sentiment Analysis Algorithms Using Twitter and Review DatasetDocument8 pagesComparison of Sentiment Analysis Algorithms Using Twitter and Review DatasetIJRASETPublicationsNo ratings yet
- Research On PanasonicDocument34 pagesResearch On PanasonicNakul Kathrotia0% (1)
- Sentiment Analysis of Text and Audio Data IJERTV10IS120009Document4 pagesSentiment Analysis of Text and Audio Data IJERTV10IS120009Tiktok Viral UnofficialNo ratings yet
- Jatin Shinde ANN MINIPROJECTDocument13 pagesJatin Shinde ANN MINIPROJECTjatinshindeNo ratings yet
- Journal Pre-Proof: Digital Communications and NetworksDocument28 pagesJournal Pre-Proof: Digital Communications and NetworksHana FebriantiNo ratings yet
- Sentiment Analysis Using Deep Learning ApproachDocument11 pagesSentiment Analysis Using Deep Learning ApproachFuntyNo ratings yet
- Sentimental Analysis and Its Applications - A ReviewDocument4 pagesSentimental Analysis and Its Applications - A ReviewEditor IJRITCCNo ratings yet
- Exploiting Deep Learning For Persian Sentiment AnalysisDocument8 pagesExploiting Deep Learning For Persian Sentiment AnalysisAyon DattaNo ratings yet
- Analysis of Customer Opinion Using Machine Learning and NLP TechniquesDocument6 pagesAnalysis of Customer Opinion Using Machine Learning and NLP Techniquespardhu colabNo ratings yet
- Topic Classification and Sentiment Analysis For Vietnamese Education Survey SystemDocument9 pagesTopic Classification and Sentiment Analysis For Vietnamese Education Survey SystemQuyền NguyễnNo ratings yet
- Sentiment Analysis On Social Media Reviews Datasets With Deep Learning ApproachDocument15 pagesSentiment Analysis On Social Media Reviews Datasets With Deep Learning Approachjunior TongaNo ratings yet
- Question Generator and Text Summarizer Using NLPDocument9 pagesQuestion Generator and Text Summarizer Using NLPIJRASETPublicationsNo ratings yet
- Scientists Sense Making When Hypothesizing About Disease Mechanisms From Expression Data and Their Needs For Visualization SupportDocument12 pagesScientists Sense Making When Hypothesizing About Disease Mechanisms From Expression Data and Their Needs For Visualization SupportKarim ElghachtoulNo ratings yet
- Sentiment Analysis and Review Classification Using Deep LearningDocument8 pagesSentiment Analysis and Review Classification Using Deep LearningIJRASETPublicationsNo ratings yet
- Sentiments Analysis of Amazon Reviews Dataset by Using Machine LearningDocument9 pagesSentiments Analysis of Amazon Reviews Dataset by Using Machine LearningIJRASETPublicationsNo ratings yet
- 12,14 Mini Project ReportDocument20 pages12,14 Mini Project ReportAditya RautNo ratings yet
- Technical Seminar Fuzzy Based FrameworkDocument32 pagesTechnical Seminar Fuzzy Based FrameworkTHANYANo ratings yet
- Evolution of Hybrid Distance Based KNN ClassificationDocument9 pagesEvolution of Hybrid Distance Based KNN ClassificationIAES IJAINo ratings yet
- Aspect-Based Sentiment Analysis in Education DomainDocument8 pagesAspect-Based Sentiment Analysis in Education Domainmrsenpai1993No ratings yet
- Sentiment Analysis Based On Deep Learning - A Comparative StudyDocument29 pagesSentiment Analysis Based On Deep Learning - A Comparative StudyToni BuiNo ratings yet
- Semester-Long Internship Report: Tanmay Srinath (BMSCE, Bangalore)Document31 pagesSemester-Long Internship Report: Tanmay Srinath (BMSCE, Bangalore)hiiNo ratings yet
- Transparency and Accountability in AI Decision Support: Explaining and Visualizing Convolutional Neural Networks For Text InformationDocument35 pagesTransparency and Accountability in AI Decision Support: Explaining and Visualizing Convolutional Neural Networks For Text InformationEmmanuel TizNo ratings yet
- Sentiments Analysis Using Ai: Project ReportDocument27 pagesSentiments Analysis Using Ai: Project ReportShivangi GargNo ratings yet
- Performance and Feedback AnalyzerDocument6 pagesPerformance and Feedback AnalyzerIJRASETPublicationsNo ratings yet
- Fyp 4203Document3 pagesFyp 4203Niko JayeNo ratings yet
- A Project ReportDocument38 pagesA Project ReporttejaswiniNo ratings yet
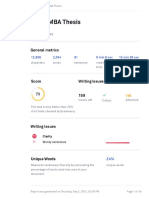
- JW01-MBA Thesis: General MetricsDocument10 pagesJW01-MBA Thesis: General MetricsAMIT PANDEYNo ratings yet
- Analysis of Spoken Dialog Systems: A Project Report OnDocument23 pagesAnalysis of Spoken Dialog Systems: A Project Report OnTanpreet KaurNo ratings yet
- "Mood Detection Using Artificial Intelligence And: Machine LearningDocument38 pages"Mood Detection Using Artificial Intelligence And: Machine LearningAshish ShindeNo ratings yet
- A Novel Meta-Embedding Technique For Drug Reviews Sentiment AnalysisDocument9 pagesA Novel Meta-Embedding Technique For Drug Reviews Sentiment AnalysisIAES IJAINo ratings yet
- Final Project ReportDocument43 pagesFinal Project ReportUtsho GhoshNo ratings yet
- Abhay Raj 2019ugcs005r NLP ReportDocument21 pagesAbhay Raj 2019ugcs005r NLP Reportraksha fauzdarNo ratings yet
- La VanyaDocument44 pagesLa VanyaMahendran vmsNo ratings yet
- Sentimental Analysis On Live Twitter DataDocument7 pagesSentimental Analysis On Live Twitter DataIJRASETPublicationsNo ratings yet
- Yuktha101Document199 pagesYuktha101yukthaNo ratings yet
- YukthaShree InternshalaResume (1) 512Document2 pagesYukthaShree InternshalaResume (1) 512yukthaNo ratings yet
- Simulation Techniques CA 2Document3 pagesSimulation Techniques CA 2yukthaNo ratings yet
- Machin e Learnin G: Lab Record Implementation in RDocument30 pagesMachin e Learnin G: Lab Record Implementation in RyukthaNo ratings yet
- Economic Order QuantityDocument8 pagesEconomic Order QuantityyukthaNo ratings yet
- Internal Assessment (1) 500Document5 pagesInternal Assessment (1) 500yukthaNo ratings yet
- Sequencing & SchedulingDocument19 pagesSequencing & SchedulingyukthaNo ratings yet
- Data Science Report PDFDocument20 pagesData Science Report PDFyukthaNo ratings yet
- Fa Ca2 19BSR18029-2Document6 pagesFa Ca2 19BSR18029-2yukthaNo ratings yet
- Advanced Analytics PPT-1Document21 pagesAdvanced Analytics PPT-1yukthaNo ratings yet
- Project Predictive ModelingDocument69 pagesProject Predictive Modelingyuktha50% (2)
- Advanced AnalyticsDocument12 pagesAdvanced AnalyticsyukthaNo ratings yet
- Social Network Nodes Presentation - AADocument21 pagesSocial Network Nodes Presentation - AAyukthaNo ratings yet
- Group-4: Sanath C Kashyap-19BSR18018 Dhyan Kushalappa P U-19BSR18028 Laxman-19BSR18010 Vishal S-19BSR18025Document17 pagesGroup-4: Sanath C Kashyap-19BSR18018 Dhyan Kushalappa P U-19BSR18028 Laxman-19BSR18010 Vishal S-19BSR18025yukthaNo ratings yet
- Backwards Design - Jessica W Maddison CDocument20 pagesBackwards Design - Jessica W Maddison Capi-451306299100% (1)
- Web-Based Attendance Management System Using Bimodal Authentication TechniquesDocument61 pagesWeb-Based Attendance Management System Using Bimodal Authentication TechniquesajextopeNo ratings yet
- Lalit Resume-2023-LatestDocument2 pagesLalit Resume-2023-LatestDrew LadlowNo ratings yet
- Riqas Ri RQ9142 11aDocument6 pagesRiqas Ri RQ9142 11aGrescia Ramos VegaNo ratings yet
- Fake News Infographics by SlidesgoDocument33 pagesFake News Infographics by SlidesgoluanavicunhaNo ratings yet
- Engineering DrawingDocument1 pageEngineering DrawingDreamtech PressNo ratings yet
- L5V 00004Document2 pagesL5V 00004Jhon LinkNo ratings yet
- Contemporary Philippine Arts From The Regions: Quarter 1Document11 pagesContemporary Philippine Arts From The Regions: Quarter 1JUN GERONANo ratings yet
- International Freight 01Document5 pagesInternational Freight 01mature.ones1043No ratings yet
- LFF MGDocument260 pagesLFF MGRivo RoberalimananaNo ratings yet
- 160kW SOFT STARTER - TAP HOLE 1Document20 pages160kW SOFT STARTER - TAP HOLE 1Ankit Uttam0% (1)
- Advertisement: National Institute of Technology, Tiruchirappalli - 620 015 TEL: 0431 - 2503365, FAX: 0431 - 2500133Document4 pagesAdvertisement: National Institute of Technology, Tiruchirappalli - 620 015 TEL: 0431 - 2503365, FAX: 0431 - 2500133dineshNo ratings yet
- Generalized Class of Sakaguchi Functions in Conic Region: Saritha. G. P, Fuad. S. Al Sarari, S. LathaDocument5 pagesGeneralized Class of Sakaguchi Functions in Conic Region: Saritha. G. P, Fuad. S. Al Sarari, S. LathaerpublicationNo ratings yet
- All India Civil Services Coaching Centre, Chennai - 28Document4 pagesAll India Civil Services Coaching Centre, Chennai - 28prakashNo ratings yet
- Muscles of The Dog 2: 2012 Martin Cake, Murdoch UniversityDocument11 pagesMuscles of The Dog 2: 2012 Martin Cake, Murdoch UniversityPiereNo ratings yet
- Enrile v. SalazarDocument26 pagesEnrile v. SalazarMaria Aerial AbawagNo ratings yet
- MolnarDocument8 pagesMolnarMaDzik MaDzikowskaNo ratings yet
- Week - 2 Lab - 1 - Part I Lab Aim: Basic Programming Concepts, Python InstallationDocument13 pagesWeek - 2 Lab - 1 - Part I Lab Aim: Basic Programming Concepts, Python InstallationSahil Shah100% (1)
- RECYFIX STANDARD 100 Tipe 010 MW - C250Document2 pagesRECYFIX STANDARD 100 Tipe 010 MW - C250Dadang KurniaNo ratings yet
- Academic Socialization and Its Effects On Academic SuccessDocument2 pagesAcademic Socialization and Its Effects On Academic SuccessJustin LargoNo ratings yet
- Homeopatija I KancerDocument1 pageHomeopatija I KancermafkoNo ratings yet
- Arbans Complete Conservatory Method For Trumpet Arbans Complete ConservatoryDocument33 pagesArbans Complete Conservatory Method For Trumpet Arbans Complete ConservatoryRicardo SoldadoNo ratings yet
- RSC Article Template-Mss - DaltonDocument15 pagesRSC Article Template-Mss - DaltonIon BadeaNo ratings yet
- Cosmopolitanism in Hard Times Edited by Vincenzo Cicchelli and Sylvie MesureDocument433 pagesCosmopolitanism in Hard Times Edited by Vincenzo Cicchelli and Sylvie MesureRev. Johana VangchhiaNo ratings yet
- MDI - Good Fellas - ScriptDocument20 pagesMDI - Good Fellas - ScriptRahulSamaddarNo ratings yet
- Openvpn ReadmeDocument7 pagesOpenvpn Readmefzfzfz2014No ratings yet
- Unit 2 - Industrial Engineering & Ergonomics - WWW - Rgpvnotes.inDocument15 pagesUnit 2 - Industrial Engineering & Ergonomics - WWW - Rgpvnotes.inSACHIN HANAGALNo ratings yet
- Table of Specification 1st QDocument5 pagesTable of Specification 1st QVIRGILIO JR FABINo ratings yet
- WBCS 2023 Preli - Booklet CDocument8 pagesWBCS 2023 Preli - Booklet CSurajit DasNo ratings yet
- ACCA F2 2012 NotesDocument18 pagesACCA F2 2012 NotesThe ExP GroupNo ratings yet