You might also like
- Current Mirror CadenceDocument80 pagesCurrent Mirror Cadencejuni khisha100% (2)
- US Proxy List - Free Proxy List PDFDocument3 pagesUS Proxy List - Free Proxy List PDFEzequiel SalesNo ratings yet
- Thailand International Mathematical Olympiad Final 2019Document5 pagesThailand International Mathematical Olympiad Final 2019Doan Thi Luyen100% (1)
- Adobe Scan 8 Mar 2022Document8 pagesAdobe Scan 8 Mar 2022luze asdNo ratings yet
- Unit I IntroductionDocument54 pagesUnit I IntroductionMerbin JoseNo ratings yet
- Network Programming-MinDocument24 pagesNetwork Programming-MinManish AryalNo ratings yet
- Labwork 1 - Autocell A Language For Cellular AutomataDocument8 pagesLabwork 1 - Autocell A Language For Cellular AutomataTamazight BinaNo ratings yet
- CS6801 MULTI CORE ARCHITECTURE AND PROGRAMMING - WatermarkDocument96 pagesCS6801 MULTI CORE ARCHITECTURE AND PROGRAMMING - WatermarkShalini GuptaNo ratings yet
- CP4253 Map Unit IDocument31 pagesCP4253 Map Unit INivi VNo ratings yet
- ACA T1 SolutionsDocument17 pagesACA T1 SolutionsshardapatelNo ratings yet
- Labwork 1 - Autocell A Language For Cellular AutomataDocument8 pagesLabwork 1 - Autocell A Language For Cellular AutomataMortimer MeunierNo ratings yet
- Computer Architecture and OrganizationDocument50 pagesComputer Architecture and OrganizationJo SefNo ratings yet
- Ab Initio Quantum Chemistry On The Cray T3E Massively Parallel Supercomputer - II (Journal of Computational Chemistry, Vol. 19, Issue 9) (1998)Document11 pagesAb Initio Quantum Chemistry On The Cray T3E Massively Parallel Supercomputer - II (Journal of Computational Chemistry, Vol. 19, Issue 9) (1998)sepot24093No ratings yet
- Flynn's Taxonomy: 1. SisdDocument7 pagesFlynn's Taxonomy: 1. SisdJaweria SiddiquiNo ratings yet
- Lecture-27 Interconnection Networks+chapter-5 Slides-Version-2Document70 pagesLecture-27 Interconnection Networks+chapter-5 Slides-Version-2Abdul BariiNo ratings yet
- Advanced Computer ArchitectureDocument34 pagesAdvanced Computer Architectureharsh9808527912No ratings yet
- Distributed Operating Syst EM: 15SE327E Unit 1Document49 pagesDistributed Operating Syst EM: 15SE327E Unit 1Arun ChinnathambiNo ratings yet
- UDF MechanicsDocument47 pagesUDF Mechanicsmaninder singh sekhonNo ratings yet
- Hreads: Program Counter: RegistersDocument21 pagesHreads: Program Counter: RegistersRao AtifNo ratings yet
- ThreadsDocument24 pagesThreadsAjay Kumar RNo ratings yet
- The Need For High Performance ComputersDocument38 pagesThe Need For High Performance ComputersaymanwahbaNo ratings yet
- Final Unit5 CO NotesDocument7 pagesFinal Unit5 CO NotesMohd Ismail GourNo ratings yet
- CSCI 8150 Advanced Computer ArchitectureDocument18 pagesCSCI 8150 Advanced Computer Architecturesunnynnus100% (2)
- PDC - Lecture - No. 2Document31 pagesPDC - Lecture - No. 2nauman tariqNo ratings yet
- FinalDocument26 pagesFinalHứa Đăng KhoaNo ratings yet
- Parallel Computing (Unit5)Document25 pagesParallel Computing (Unit5)Shriniwas YadavNo ratings yet
- Ch12 Parallel Proc3-AulaDocument35 pagesCh12 Parallel Proc3-Aulalogu87No ratings yet
- oo'J..'E!Ver, : Made A LanquaqeDocument19 pagesoo'J..'E!Ver, : Made A LanquaqeLiz Mar CieloNo ratings yet
- COMPUTER NETWORK LAB MANUAL NewDocument64 pagesCOMPUTER NETWORK LAB MANUAL NewprachiNo ratings yet
- 5 Marks Q. Describe Array Processor ArchitectureDocument11 pages5 Marks Q. Describe Array Processor ArchitectureGaurav BiswasNo ratings yet
- Module 1 HpcaDocument13 pagesModule 1 HpcaAppukuttanNo ratings yet
- ACA Assignment 4Document16 pagesACA Assignment 4shresth choudharyNo ratings yet
- Ractice Roblems O S: I D P: Perating Ystems Nternals and Esign Rinciples S EDocument28 pagesRactice Roblems O S: I D P: Perating Ystems Nternals and Esign Rinciples S EHamza Asim Ghazi100% (1)
- Chapter 9 - M J Flynn ClassificationDocument14 pagesChapter 9 - M J Flynn ClassificationSantanu SenapatiNo ratings yet
- Advanced Computer Architecture Unit 1Document23 pagesAdvanced Computer Architecture Unit 1anujaNo ratings yet
- Introduction To Parallel ProcessingDocument49 pagesIntroduction To Parallel ProcessingShobhit MahawarNo ratings yet
- Organization of Multiprocessor SystemsDocument87 pagesOrganization of Multiprocessor Systemsbijan shresthaNo ratings yet
- Dsa Theory DaDocument41 pagesDsa Theory Daswastik rajNo ratings yet
- Threads: by Salman Memon 2K12/IT/109 University of Sindh JamshoroDocument16 pagesThreads: by Salman Memon 2K12/IT/109 University of Sindh JamshoroP VsNo ratings yet
- Unit-1 and Swayam Week 1 and Week 2 Revision Unit-1 Course ContentsDocument4 pagesUnit-1 and Swayam Week 1 and Week 2 Revision Unit-1 Course ContentsAbhinav aroraNo ratings yet
- EC04-Computer OrganizationDocument73 pagesEC04-Computer OrganizationJaimuchu 13No ratings yet
- CRGC Mcore PDFDocument124 pagesCRGC Mcore PDFandres pythonNo ratings yet
- Ab Initio Quantum Chemistry On The Ibm Pseries 690: Ibm Performance Technical ReportDocument19 pagesAb Initio Quantum Chemistry On The Ibm Pseries 690: Ibm Performance Technical ReportKOUROOSHNo ratings yet
- IT 201 Chapter 4 SummarizeDocument2 pagesIT 201 Chapter 4 SummarizeSami NoahNo ratings yet
- oo'J..'E!Ver, : Made A LanquaqeDocument19 pagesoo'J..'E!Ver, : Made A LanquaqeNinad KedareNo ratings yet
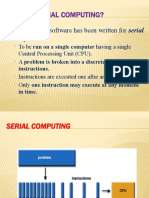
- What Is Serial Computing?: Traditionally, Software Has Been Written For Serial ComputationDocument22 pagesWhat Is Serial Computing?: Traditionally, Software Has Been Written For Serial ComputationDivya NigamNo ratings yet
- Advance Computer Architecture2Document36 pagesAdvance Computer Architecture2AnujNo ratings yet
- Parallel ComputingDocument32 pagesParallel ComputingKhushal BisaniNo ratings yet
- MCAP QP CT - I - 2 Marks - KeyDocument3 pagesMCAP QP CT - I - 2 Marks - KeysaradhsivaNo ratings yet
- Chapter 6 Advanced TopicsDocument14 pagesChapter 6 Advanced TopicsRoshanNo ratings yet
- Practice Problems: Concurrency: Lectures On Operating Systems (Mythili Vutukuru, IIT Bombay)Document38 pagesPractice Problems: Concurrency: Lectures On Operating Systems (Mythili Vutukuru, IIT Bombay)N S SujithNo ratings yet
- Introduction To Distributed Operating Systems Communication in Distributed SystemsDocument150 pagesIntroduction To Distributed Operating Systems Communication in Distributed SystemsSweta KamatNo ratings yet
- 5 PipelineDocument63 pages5 Pipeline1352 : NEEBESH PADHYNo ratings yet
- Labmanual Ecen474 PDFDocument81 pagesLabmanual Ecen474 PDFSURAJ GUPTANo ratings yet
- CSCI 8150 Advanced Computer ArchitectureDocument28 pagesCSCI 8150 Advanced Computer Architecturesunnynnus100% (2)
- Computer & Business TeminologyDocument39 pagesComputer & Business TeminologytimenetsolutionsNo ratings yet
- CN Lab ManualDocument62 pagesCN Lab ManualAmol MNo ratings yet
- Objectives:: CS311 Lecture: CPU Control: Hardwired Control and Microprogrammed ControlDocument13 pagesObjectives:: CS311 Lecture: CPU Control: Hardwired Control and Microprogrammed ControlVaibhav SharmaNo ratings yet
- NewScientistPrimordial Scanned300dpiOCRLayerDocument6 pagesNewScientistPrimordial Scanned300dpiOCRLayerZxNo ratings yet
- Microcoded ArchDocument12 pagesMicrocoded ArchAnonymous pHi4dXNo ratings yet
- Simstd Apr 2003 HintsDocument2 pagesSimstd Apr 2003 HintsGretchen BouNo ratings yet
- DS Notes CHP 1Document35 pagesDS Notes CHP 1luze asdNo ratings yet
- CHP 3Document70 pagesCHP 3luze asdNo ratings yet
- CHP 2Document103 pagesCHP 2luze asdNo ratings yet
- Adobe Scan 8 Mar 2022Document8 pagesAdobe Scan 8 Mar 2022luze asdNo ratings yet
- Customer Behavior Analysis in E-Commerce Using Decision Tree Machine Learning ApproachDocument9 pagesCustomer Behavior Analysis in E-Commerce Using Decision Tree Machine Learning ApproachBryan PabloNo ratings yet
- Residential Standby Power System: Installation Review WorksheetDocument2 pagesResidential Standby Power System: Installation Review WorksheetbaljeetjatNo ratings yet
- Ewse SDP FPS 514600 CM Man 10002 R0Document132 pagesEwse SDP FPS 514600 CM Man 10002 R0Enrique ColomboNo ratings yet
- LAB-03 Learning Matlab Basics Part 03 Generating Functions and Introduction To Simulink Objectives/lab GoalsDocument4 pagesLAB-03 Learning Matlab Basics Part 03 Generating Functions and Introduction To Simulink Objectives/lab GoalsSumbalNo ratings yet
- Modulos de EntradaDocument4 pagesModulos de EntradaYury AlejandraNo ratings yet
- Installation & System Management: Microsoft Business Solutions-Navision Database ServerDocument174 pagesInstallation & System Management: Microsoft Business Solutions-Navision Database ServersofieneNo ratings yet
- IBI ASP Round 1Document2 pagesIBI ASP Round 1Yash AhujaNo ratings yet
- Reset Default Password and MFADocument13 pagesReset Default Password and MFASridhar GuptaNo ratings yet
- Nikol Braçellari CVDocument1 pageNikol Braçellari CVNiki BracellariNo ratings yet
- Technical Guide: US GAAP Financial Reporting Taxonomy and Data Quality Committee Rules TaxonomyDocument29 pagesTechnical Guide: US GAAP Financial Reporting Taxonomy and Data Quality Committee Rules TaxonomyCarlosNo ratings yet
- A1117267892 - 23494 - 26 - 2019 - Mini Project Report FormatDocument13 pagesA1117267892 - 23494 - 26 - 2019 - Mini Project Report FormatAnshul SinghNo ratings yet
- Regulations For B.Tech. in Computer Science and Social Sciences (CSSS) ProgramDocument5 pagesRegulations For B.Tech. in Computer Science and Social Sciences (CSSS) ProgramTaral jainNo ratings yet
- A Brief Introduction To Controller Area Network PDFDocument6 pagesA Brief Introduction To Controller Area Network PDFSiva100% (1)
- CS8591 CN Unit 1Document61 pagesCS8591 CN Unit 1Nagu StudyNo ratings yet
- Distributed Databases: by Allyson MoranDocument37 pagesDistributed Databases: by Allyson Moranعلاء شكرجيNo ratings yet
- CS8080 Information Retrieval Techniques Reg 2017 Question BankDocument6 pagesCS8080 Information Retrieval Techniques Reg 2017 Question BankProject 21-22No ratings yet
- GSM With CKT, Flow CodeDocument18 pagesGSM With CKT, Flow CodeNithesh K SuvarnaNo ratings yet
- SAP B1 On Cloud - Accounting Information Systems OutlineDocument2 pagesSAP B1 On Cloud - Accounting Information Systems OutlineChristine Jane LaciaNo ratings yet
- Flatron User ManualDocument29 pagesFlatron User Manualbigboi11No ratings yet
- Especificaciones Tecnicas SentryumDocument42 pagesEspecificaciones Tecnicas SentryumJuan Mansilla IsidroNo ratings yet
- Web Development IntroductionDocument17 pagesWeb Development IntroductionkaifNo ratings yet
- Sae J220-2017Document2 pagesSae J220-2017tiramisuweitaoNo ratings yet
- Spife NexusDocument4 pagesSpife NexusRita LeongNo ratings yet
- A Survey On Empathetic Dialogue SystemsDocument69 pagesA Survey On Empathetic Dialogue SystemsAbdul WahabNo ratings yet
- BookDocument3 pagesBookLimuel Galima AyapNo ratings yet
- Access Modifiers Interview QuestionsDocument4 pagesAccess Modifiers Interview QuestionsAnudeep PatnaikNo ratings yet
- Experiment 9 AIM: Pick Up Test For Differential Relay: Writing SequenceDocument2 pagesExperiment 9 AIM: Pick Up Test For Differential Relay: Writing SequenceRutuparna KelkarNo ratings yet