You might also like
- Into To Darknets Tor and I2pDocument93 pagesInto To Darknets Tor and I2pMatt TobiasNo ratings yet
- The Complete Landscape Photography Manual - October 2020Document195 pagesThe Complete Landscape Photography Manual - October 2020Big_GeorgeNo ratings yet
- P N M S: PNMSJ+ Installation Manual (Windows Server 2008, Windows Server 2008 R2, Windows Server 2012 R2)Document113 pagesP N M S: PNMSJ+ Installation Manual (Windows Server 2008, Windows Server 2008 R2, Windows Server 2012 R2)sergioNo ratings yet
- Ericsson AXE 810Document4 pagesEricsson AXE 810Kao Sun HoNo ratings yet
- Ruckus FastIron 08.0.91 MIB Reference GuideDocument528 pagesRuckus FastIron 08.0.91 MIB Reference GuiderbrtdlsNo ratings yet
- 16-Troubleshooting EtherChannel IDocument11 pages16-Troubleshooting EtherChannel Imansoorali_afNo ratings yet
- Classless SubnettingDocument27 pagesClassless Subnettingaref12345No ratings yet
- OptiX RTN 980 Product IntroductionDocument24 pagesOptiX RTN 980 Product IntroductionRafael LessaNo ratings yet
- WLC - Basic Concepts & Troubleshooting - sCRIBDocument30 pagesWLC - Basic Concepts & Troubleshooting - sCRIBshrilathNo ratings yet
- MNSeries Presentation GeneralDocument43 pagesMNSeries Presentation Generalkimlookman100% (1)
- Switching-Labs/ Using GNS3 For Switching LabsDocument7 pagesSwitching-Labs/ Using GNS3 For Switching LabsEdwin HNo ratings yet
- CRN - FPH1200 - Release - 5drop4 5.0.31.12Document10 pagesCRN - FPH1200 - Release - 5drop4 5.0.31.12Deutz SimanjorangNo ratings yet
- List of Generic Faults: LG F-H I T7 0 25 - R 4.2 .2 - 20 10 - W31 Su R Pass Hit7 0 25 R 4.2 .2Document27 pagesList of Generic Faults: LG F-H I T7 0 25 - R 4.2 .2 - 20 10 - W31 Su R Pass Hit7 0 25 R 4.2 .2Big_GeorgeNo ratings yet
- Errata lpc177x lpc178xDocument12 pagesErrata lpc177x lpc178x19thmnlfreemsNo ratings yet
- Resolved and Open Issues in The Ericsson IP Operating System For Smart Services Router 4.2, DP08Document6 pagesResolved and Open Issues in The Ericsson IP Operating System For Smart Services Router 4.2, DP08Cobra TxnNo ratings yet
- RT5370 RalinkDocument70 pagesRT5370 RalinkMiguel ArcosNo ratings yet
- List Barang Untuk SCADA - UPSDocument5 pagesList Barang Untuk SCADA - UPSRizky FajarNo ratings yet
- Conmutación Y Enrutamiento Paralelo 101 Laboratorio 5Document25 pagesConmutación Y Enrutamiento Paralelo 101 Laboratorio 5Dayanna MéndezNo ratings yet
- Chapter 7 Exam - Dpr7501-001v CCNPT 2019-1Document20 pagesChapter 7 Exam - Dpr7501-001v CCNPT 2019-1Jorge Luis Zuñiga PobleteNo ratings yet
- BOQDocument9 pagesBOQgoestJPNo ratings yet
- Using GNS3 For Switching LabsDocument8 pagesUsing GNS3 For Switching LabscoolporroNo ratings yet
- Srx110 Quick Start GuideDocument6 pagesSrx110 Quick Start Guidekevin100% (1)
- TRUTRAK Automatic Pitch Trim Installation ManualDocument17 pagesTRUTRAK Automatic Pitch Trim Installation ManualfasilpereiraNo ratings yet
- Lab 1 - FRATM - FRF.5Document7 pagesLab 1 - FRATM - FRF.5ClaudiuGovoNo ratings yet
- Intracom Operationg FrequenciesDocument74 pagesIntracom Operationg FrequenciesbfordessNo ratings yet
- 1064 - Toprun Auto - HP Server - 17 10 19Document1 page1064 - Toprun Auto - HP Server - 17 10 19ManikandanNo ratings yet
- 07.TAC03001-HO09-I1.3-7302 7330 5520 SHUB Basic Configuration CEDocument11 pages07.TAC03001-HO09-I1.3-7302 7330 5520 SHUB Basic Configuration CEStylish TshirtNo ratings yet
- Installation & Operating Instructions: Models 150T, 151T, & 152T Smartstep Programmable AttenuatorsDocument12 pagesInstallation & Operating Instructions: Models 150T, 151T, & 152T Smartstep Programmable AttenuatorsMehmet YıldızNo ratings yet
- My Basic Network Scan - OjcwdvDocument6 pagesMy Basic Network Scan - OjcwdvSandy DjadoelNo ratings yet
- HITACHIDocument5 pagesHITACHIEta CoursesNo ratings yet
- HPE Wired by Bizgram Whatsapp 87776955 PDFDocument6 pagesHPE Wired by Bizgram Whatsapp 87776955 PDFBizgram AsiaNo ratings yet
- Felt-B Uds 3fe69486aaaatqzza03Document16 pagesFelt-B Uds 3fe69486aaaatqzza03Akm AnisuzzamanNo ratings yet
- Quiz 7Document23 pagesQuiz 7Buddy BigBNo ratings yet
- Deif Hybrid Controller Compatibility 4189341288 UkDocument11 pagesDeif Hybrid Controller Compatibility 4189341288 UkWaseem AhmadNo ratings yet
- Ge SNP XDocument3 pagesGe SNP XIgor SuraevNo ratings yet
- MSI - 86b81 - MS-7037Document30 pagesMSI - 86b81 - MS-7037Débo OrellanoNo ratings yet
- (Compact Smart NID) : Raisecom Technology Co., LTDDocument5 pages(Compact Smart NID) : Raisecom Technology Co., LTDFrancois BeunierNo ratings yet
- Hcie-Carrier Ip Lab Mock Test Issue 1.00Document15 pagesHcie-Carrier Ip Lab Mock Test Issue 1.00Ghallab AlsadehNo ratings yet
- Device 3 Connection GuideDocument9 pagesDevice 3 Connection Guidemochammad aripinNo ratings yet
- SCADALink 485HUB User Manual Black White - 2Document12 pagesSCADALink 485HUB User Manual Black White - 2Eko SarjonoNo ratings yet
- RSTP 2Document42 pagesRSTP 2preetamnNo ratings yet
- EIGRP Summarization Active and Passive Routes: Network Consulting EngineerDocument17 pagesEIGRP Summarization Active and Passive Routes: Network Consulting Engineersandeep kumarNo ratings yet
- Stratix 5700 and ArmorStratix 5700 - A - 15.2 (7) E3 (Released 9 - 2020) - 15.2 (8) E1 (Released 12 - 2021)Document17 pagesStratix 5700 and ArmorStratix 5700 - A - 15.2 (7) E3 (Released 9 - 2020) - 15.2 (8) E1 (Released 12 - 2021)Ricardo PradoNo ratings yet
- Read Chapter 3, The 8051 Microcontroller Architecture, Programming and Applications by Kenneth .J.AyalaDocument32 pagesRead Chapter 3, The 8051 Microcontroller Architecture, Programming and Applications by Kenneth .J.AyalapsmeeeNo ratings yet
- Driver Manual: (Supplement To The Fieldserver Instruction Manual)Document16 pagesDriver Manual: (Supplement To The Fieldserver Instruction Manual)Felipe FeitosaNo ratings yet
- SiemensDocument3 pagesSiemensHesham SharakyNo ratings yet
- HITACHI H Series (CPU Port) : HMI SettingDocument4 pagesHITACHI H Series (CPU Port) : HMI SettingsunhuynhNo ratings yet
- ABX00042 ABX00045 ABX00046 DatasheetDocument20 pagesABX00042 ABX00045 ABX00046 Datasheetagussetiawan082233No ratings yet
- rtl83055 PDFDocument160 pagesrtl83055 PDFMariuszChreptakNo ratings yet
- ASA Failover Troubleshooting On 7.x and 8Document5 pagesASA Failover Troubleshooting On 7.x and 8Akash ThakurNo ratings yet
- Zwf26!01!006 New Ul DPCCH Slot FormatDocument19 pagesZwf26!01!006 New Ul DPCCH Slot FormatlikameleNo ratings yet
- Sleu 078Document27 pagesSleu 078Belen Dall OglioNo ratings yet
- Chapter 1 Overview: 1.1 Introduction To HSDPADocument9 pagesChapter 1 Overview: 1.1 Introduction To HSDPAAnonymous kC8oFmSNo ratings yet
- Ericsson AXE 810: Switch (ROTD)Document4 pagesEricsson AXE 810: Switch (ROTD)Kao Sun HoNo ratings yet
- Ericsson AXE 810: Switch (ROTD)Document4 pagesEricsson AXE 810: Switch (ROTD)Kao Sun HoNo ratings yet
- Ericsson AXE 810: Switch (ROTD)Document4 pagesEricsson AXE 810: Switch (ROTD)Kao Sun HoNo ratings yet
- Router PerformanceDocument4 pagesRouter Performancegunm64No ratings yet
- CRN-Infinera 7080R445 V2Document14 pagesCRN-Infinera 7080R445 V2ThomasNo ratings yet
- Simplex Time Recorder Company - 4100 Computer Port Protocol: DescriptionDocument7 pagesSimplex Time Recorder Company - 4100 Computer Port Protocol: DescriptionRabah AmidiNo ratings yet
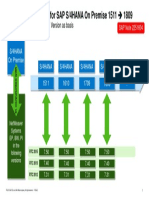
- Version Interoperability For SAP S/4HANA On Premise 1511 1809Document1 pageVersion Interoperability For SAP S/4HANA On Premise 1511 1809vinodhNo ratings yet
- RA8875 DS V19 EngDocument178 pagesRA8875 DS V19 EngGonzalo RiveraNo ratings yet
- 03 TAC42047 S01M03edI2.0 IHUB Turn-Up Procedure CEDocument29 pages03 TAC42047 S01M03edI2.0 IHUB Turn-Up Procedure CEmatheus santosNo ratings yet
- Topologia LabDocument1 pageTopologia LabChristian B de LimaNo ratings yet
- ROUTING INFORMATION PROTOCOL: RIP DYNAMIC ROUTING LAB CONFIGURATIONFrom EverandROUTING INFORMATION PROTOCOL: RIP DYNAMIC ROUTING LAB CONFIGURATIONNo ratings yet
- JLT-Raman AmplificationDocument14 pagesJLT-Raman AmplificationBig_GeorgeNo ratings yet
- List of Generic Faults: L G F - H I T 73 0 0 - 5 - 00 00 - 2 01 1 - W4 2 Nokia Siemens Networks Hit 7300 5.00Document55 pagesList of Generic Faults: L G F - H I T 73 0 0 - 5 - 00 00 - 2 01 1 - W4 2 Nokia Siemens Networks Hit 7300 5.00Big_GeorgeNo ratings yet
- List of Generic FaultsDocument39 pagesList of Generic FaultsBig_GeorgeNo ratings yet
- NodeMCU MQTT Client With Arduino IDE - NodeMCUDocument11 pagesNodeMCU MQTT Client With Arduino IDE - NodeMCUstudentNo ratings yet
- Rip Version 1 (Ripv1)Document54 pagesRip Version 1 (Ripv1)AtmanNo ratings yet
- WiFi QnsDocument5 pagesWiFi QnsJayakrishnan MarangattNo ratings yet
- Home Wireless Network DesignDocument14 pagesHome Wireless Network DesignSai Rohit PaturiNo ratings yet
- The OSI Model and The TCP/IP Protocol Suite: ObjectivesDocument56 pagesThe OSI Model and The TCP/IP Protocol Suite: ObjectivesPooja ReddyNo ratings yet
- Soundwin 2 4 Ip PBXDocument2 pagesSoundwin 2 4 Ip PBXAris SunaryoNo ratings yet
- Mule Event ProcessingDocument10 pagesMule Event ProcessingsaikrishnatadiboyinaNo ratings yet
- ITN instructorPPT Chapter4Document66 pagesITN instructorPPT Chapter4AndryGunawanNo ratings yet
- CEH Module 06 Enumeration PDFDocument17 pagesCEH Module 06 Enumeration PDFAbdo ElmamounNo ratings yet
- CheckPoint R77 Gaia AdminGuideDocument234 pagesCheckPoint R77 Gaia AdminGuideSachin Guda100% (2)
- ACN - Lab - 2Document4 pagesACN - Lab - 2Jagrit SharmaNo ratings yet
- CE303 Lecture 5Document43 pagesCE303 Lecture 5bob.rice04No ratings yet
- Huawei AirEngine 5761R-11 & AirEngine 5761R-11E Access Points DatasheetDocument16 pagesHuawei AirEngine 5761R-11 & AirEngine 5761R-11E Access Points Datasheetyuri meloNo ratings yet
- Internet Protocol: Internet Protocol Is The Principal Communication Protocols Used For Relaying Datagrams (PACKETS)Document17 pagesInternet Protocol: Internet Protocol Is The Principal Communication Protocols Used For Relaying Datagrams (PACKETS)Mohamed AbubackerNo ratings yet
- BT-PON BT-215XR XPON ONU ONT DatasheetDocument5 pagesBT-PON BT-215XR XPON ONU ONT Datasheetnayux ruizNo ratings yet
- ApexDC Windows User GuideDocument16 pagesApexDC Windows User Guidenikubej100% (1)
- Forouzan Sol 19Document6 pagesForouzan Sol 19Anurag UpadhyayNo ratings yet
- 4.1.3.5 Packet Tracer - Configure Standard IPv4 ACLs - ILMDocument13 pages4.1.3.5 Packet Tracer - Configure Standard IPv4 ACLs - ILMdiego rubioNo ratings yet
- Microchip Gigabit Ethernet Solutions: Presenter: Brandon Kim, Embedded Solutions EngineerDocument44 pagesMicrochip Gigabit Ethernet Solutions: Presenter: Brandon Kim, Embedded Solutions EngineerDaniel IliescuNo ratings yet
- TP Link Hx220Document2 pagesTP Link Hx220armando.corralesNo ratings yet
- Reviewer 3rd QuarterDocument3 pagesReviewer 3rd QuarterbriarnoldjrNo ratings yet
- Huawei CloudEngine 9860 Switch DatasheetDocument12 pagesHuawei CloudEngine 9860 Switch Datasheetremart24No ratings yet
- Ethernet: Introduction To NetworksDocument61 pagesEthernet: Introduction To Networksllekhanya-1No ratings yet
- UDPDocument7 pagesUDPMit Thakore100% (1)