You might also like
- EMLabScript PartADocument10 pagesEMLabScript PartAAnonymous NiOFQtyINo ratings yet
- Kinetics LabDocument15 pagesKinetics LabMiguel Deleon100% (1)
- 1 GR 11 Functions Graphs and Exercise Questions AnswersDocument12 pages1 GR 11 Functions Graphs and Exercise Questions AnswersWalter Mazibuko100% (1)
- Fitting A Logistic Curve To DataDocument12 pagesFitting A Logistic Curve To DataXiaoyan ZouNo ratings yet
- PRO2 - 03e Instructions With REAL NumbersDocument7 pagesPRO2 - 03e Instructions With REAL NumbersSamehibrahemNo ratings yet
- Planck's Cons. Solar CellDocument6 pagesPlanck's Cons. Solar Cellprateekjain01100% (1)
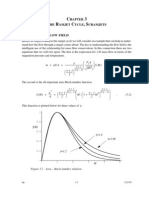
- CH 03 Ramjet CycleDocument42 pagesCH 03 Ramjet CycleHari Hara SudhanNo ratings yet
- Extract Pages From (George B. Arfken, Hans J.Document3 pagesExtract Pages From (George B. Arfken, Hans J.Alaa MohyeldinNo ratings yet
- (Winter 2021) : CS231A: Computer Vision, From 3D Reconstruction To Recognition Homework #2 Due: Friday, Februrary 12Document5 pages(Winter 2021) : CS231A: Computer Vision, From 3D Reconstruction To Recognition Homework #2 Due: Friday, Februrary 12Nono NonoNo ratings yet
- NUTFADocument9 pagesNUTFATarkes DoraNo ratings yet
- Orbit Determination Accuracy RequirementDocument16 pagesOrbit Determination Accuracy RequirementFrancisco CarvalhoNo ratings yet
- Matlab 2Document40 pagesMatlab 2Husam AL-QadasiNo ratings yet
- ch08 AnsDocument20 pagesch08 Ansrifdah abadiyahNo ratings yet
- Stress Concentration Factor Measurement of Tensile Plate With Circular and Elliptical Hole by Digital Hybrid Photoelastic ExperimentDocument4 pagesStress Concentration Factor Measurement of Tensile Plate With Circular and Elliptical Hole by Digital Hybrid Photoelastic ExperimentYasser BahaaNo ratings yet
- If emDocument14 pagesIf emraj kiranNo ratings yet
- Gupta1977 Design of Column Sections Subjected To Three Components of EarthquakeDocument5 pagesGupta1977 Design of Column Sections Subjected To Three Components of EarthquakeAnonymous pqzrPMJJFTNo ratings yet
- Methods To Analyze Structural Change Over Time and Space: A Typological SurveyDocument29 pagesMethods To Analyze Structural Change Over Time and Space: A Typological SurveyManuu RossiNo ratings yet
- New Segmentation Strategies: Figure 5: The Variable Section Segmentation Strategy For The CasingDocument2 pagesNew Segmentation Strategies: Figure 5: The Variable Section Segmentation Strategy For The Casingpearl301010No ratings yet
- LinearAlgebra MatlabDocument12 pagesLinearAlgebra MatlabAndres Felipe CisfNo ratings yet
- Daubechies 1991Document23 pagesDaubechies 1991santiago rodriguez sierraNo ratings yet
- Modal Mass IDocument41 pagesModal Mass Ivodugu123No ratings yet
- Lecture 1ADocument56 pagesLecture 1ADilruk GallageNo ratings yet
- MCHE485 Final Spring2016Document8 pagesMCHE485 Final Spring2016Mahdi KarimiNo ratings yet
- C 1 Quadratic InterpolationDocument18 pagesC 1 Quadratic InterpolationSukuje Je100% (1)
- Question #1: Calculating KHDocument4 pagesQuestion #1: Calculating KHKarthikeyan NatarajanNo ratings yet
- Feng 2019Document3 pagesFeng 2019Alioth F.a.mNo ratings yet
- G O T F: Graph of The Tangent FunctionDocument11 pagesG O T F: Graph of The Tangent FunctionVenesia WirandaNo ratings yet
- X-Ray Diffraction: NANO161 Lab Report 1Document14 pagesX-Ray Diffraction: NANO161 Lab Report 1wer809No ratings yet
- Homework3 Questions TemplateDocument15 pagesHomework3 Questions TemplateQuân Bảo NguyễnNo ratings yet
- A. Indeterminate BeamsDocument24 pagesA. Indeterminate BeamsMaxNo ratings yet
- Burkardt 1983Document12 pagesBurkardt 1983Martin PanicioNo ratings yet
- Modal MassDocument36 pagesModal MassvisvisvisvisNo ratings yet
- AISI DSM Design Guide Schafer VersionDocument180 pagesAISI DSM Design Guide Schafer VersionOmar Eduardo Alvarado Valle100% (1)
- Matrix Algebra1Document17 pagesMatrix Algebra1Gerardo Pastor Herrera SepulvedaNo ratings yet
- MATLAB and Simulink: Prof. Dr. Ottmar BeucherDocument71 pagesMATLAB and Simulink: Prof. Dr. Ottmar BeucherShubham ChauhanNo ratings yet
- Magnetic LevitationDocument7 pagesMagnetic LevitationshivkumarNo ratings yet
- Wednesday Paper 3Document6 pagesWednesday Paper 3avinsaini05No ratings yet
- Physics SATDocument9 pagesPhysics SATgraciawright14No ratings yet
- Conjugate Beam MethodDocument5 pagesConjugate Beam MethodBeatrice CastilloNo ratings yet
- K00228 - 20191014013308 - Lecture Note - Chapter 3 Vector Space Part 1Document65 pagesK00228 - 20191014013308 - Lecture Note - Chapter 3 Vector Space Part 1yaya 98No ratings yet
- Applications of LADocument13 pagesApplications of LAGanagarajan RajendrenNo ratings yet
- 2015 Add maths-SEMINAR PAPER 1 PDFDocument18 pages2015 Add maths-SEMINAR PAPER 1 PDFAriss LeeNo ratings yet
- Modal MassDocument25 pagesModal MassVarga ZoranNo ratings yet
- Three Moment EquationDocument11 pagesThree Moment EquationChristian Josh DomingoNo ratings yet
- Applied Physics Lab Report 3Document7 pagesApplied Physics Lab Report 3Wamiq SohailNo ratings yet
- Final 2.34 PDFDocument15 pagesFinal 2.34 PDFmbmonvilleNo ratings yet
- 2019 Exam Papers With SolutionsDocument22 pages2019 Exam Papers With Solutionsrain wilsonNo ratings yet
- DSRSSTMKNDL 8Document1 pageDSRSSTMKNDL 8Yesi Indri HeryaniNo ratings yet
- 2.1 Cofactor ExpansionDocument5 pages2.1 Cofactor ExpansionChloeNo ratings yet
- Btech Ce 3 Sem Engineering Mechanics Kce 301 2023Document4 pagesBtech Ce 3 Sem Engineering Mechanics Kce 301 2023HS EDITZNo ratings yet
- Me 2560 Statics: Chapter II. VectorsDocument19 pagesMe 2560 Statics: Chapter II. VectorsdaviddrizzyNo ratings yet
- Structure II - ManualDocument15 pagesStructure II - Manualsarathkumar sebastinNo ratings yet
- Unit 5 - Mathematics I - WWW - Rgpvnotes.inDocument31 pagesUnit 5 - Mathematics I - WWW - Rgpvnotes.inRajesh KumarNo ratings yet
- Week 6 - Lecture 1 - CE 2011 Structural Analysis IDocument17 pagesWeek 6 - Lecture 1 - CE 2011 Structural Analysis IAhamad MusharraffNo ratings yet
- Linear Algebra Refresher ExercisesDocument6 pagesLinear Algebra Refresher ExercisesjimenaNo ratings yet
- Using Trapezoidal Rule For The Area Under A Curve CalculationDocument4 pagesUsing Trapezoidal Rule For The Area Under A Curve CalculationJonathan Xavier RiveraNo ratings yet
- Guia 03 MathScript (2023-04-03) 09.25Document9 pagesGuia 03 MathScript (2023-04-03) 09.25Gustavo gallegos cornejoNo ratings yet
- Double Angle IdentitiesDocument2 pagesDouble Angle IdentitiesJerry FoliasNo ratings yet
- 3.4 Parametric Surfaces in Matlab: Sketch The Surface Defined by The Parametric EquationsDocument20 pages3.4 Parametric Surfaces in Matlab: Sketch The Surface Defined by The Parametric EquationsARJUN SIKKANo ratings yet
- The Cubic Equation Made Simple: Abdel Missa, Chrif Youssfi October 13, 2020Document30 pagesThe Cubic Equation Made Simple: Abdel Missa, Chrif Youssfi October 13, 2020Dwi BambangNo ratings yet
- Basics of Stability Hand Calculation Vs FEM 1599738959Document11 pagesBasics of Stability Hand Calculation Vs FEM 1599738959Ahsan KhanNo ratings yet
- Lecture12 06Document4 pagesLecture12 06GONZALONo ratings yet
- Beams and Framed Structures: Structures and Solid Body MechanicsFrom EverandBeams and Framed Structures: Structures and Solid Body MechanicsRating: 3 out of 5 stars3/5 (2)
- Digital Communication Systems by Simon Haykin-97Document6 pagesDigital Communication Systems by Simon Haykin-97matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-96Document6 pagesDigital Communication Systems by Simon Haykin-96matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-98Document6 pagesDigital Communication Systems by Simon Haykin-98matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-103Document6 pagesDigital Communication Systems by Simon Haykin-103matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-100Document6 pagesDigital Communication Systems by Simon Haykin-100matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-99Document6 pagesDigital Communication Systems by Simon Haykin-99matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-107Document6 pagesDigital Communication Systems by Simon Haykin-107matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-104Document6 pagesDigital Communication Systems by Simon Haykin-104matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-101Document6 pagesDigital Communication Systems by Simon Haykin-101matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-105Document6 pagesDigital Communication Systems by Simon Haykin-105matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-102Document6 pagesDigital Communication Systems by Simon Haykin-102matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-108Document6 pagesDigital Communication Systems by Simon Haykin-108matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-106Document6 pagesDigital Communication Systems by Simon Haykin-106matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-115Document6 pagesDigital Communication Systems by Simon Haykin-115matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-116Document6 pagesDigital Communication Systems by Simon Haykin-116matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-110Document6 pagesDigital Communication Systems by Simon Haykin-110matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-112Document6 pagesDigital Communication Systems by Simon Haykin-112matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-111Document6 pagesDigital Communication Systems by Simon Haykin-111matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-113Document6 pagesDigital Communication Systems by Simon Haykin-113matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-117Document6 pagesDigital Communication Systems by Simon Haykin-117matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-115Document6 pagesDigital Communication Systems by Simon Haykin-115matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-125Document6 pagesDigital Communication Systems by Simon Haykin-125matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-118Document6 pagesDigital Communication Systems by Simon Haykin-118matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-129Document6 pagesDigital Communication Systems by Simon Haykin-129matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-121Document6 pagesDigital Communication Systems by Simon Haykin-121matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-128Document6 pagesDigital Communication Systems by Simon Haykin-128matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-126Document6 pagesDigital Communication Systems by Simon Haykin-126matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-124Document6 pagesDigital Communication Systems by Simon Haykin-124matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-127Document6 pagesDigital Communication Systems by Simon Haykin-127matildaNo ratings yet
- Digital Communication Systems by Simon Haykin-130Document6 pagesDigital Communication Systems by Simon Haykin-130matildaNo ratings yet
- Fractional Calculus For Scientists PDFDocument114 pagesFractional Calculus For Scientists PDFcris100% (1)
- SAS FunctionsDocument5 pagesSAS FunctionsSan DeepNo ratings yet
- Fresnel IntegralsDocument4 pagesFresnel Integrals최재혁No ratings yet
- Matlab Report File: Amity School of Engineering and TechnologyDocument8 pagesMatlab Report File: Amity School of Engineering and TechnologySagar WadhwaNo ratings yet
- CS2 Programming 1Document17 pagesCS2 Programming 1Hadji TejucoNo ratings yet
- Katzgraber - Topology in PhysicsDocument461 pagesKatzgraber - Topology in Physicscool_gardens20074304No ratings yet
- Calculus 7th Edition - Ch07Document81 pagesCalculus 7th Edition - Ch07يقين عبدالرحمنNo ratings yet
- #6FINAL-Core 11 General Mathematics q1 CLAS6 Exponential-function-equation-And-Inequalities v1 - RHEA ANN NAVILLADocument17 pages#6FINAL-Core 11 General Mathematics q1 CLAS6 Exponential-function-equation-And-Inequalities v1 - RHEA ANN NAVILLAEm TorresNo ratings yet
- Complex Analysis: Problems With Solutions: August 2016Document84 pagesComplex Analysis: Problems With Solutions: August 2016Um nrNo ratings yet
- Chapter 3.6Document18 pagesChapter 3.6Shahminan ShahNo ratings yet
- Mathematics For Economics and Business 10Th Edition Ian Jacques Download PDF ChapterDocument51 pagesMathematics For Economics and Business 10Th Edition Ian Jacques Download PDF Chaptercharmaine.charles779100% (14)
- Algebra I m3 Topic D Lesson 23 TeacherDocument8 pagesAlgebra I m3 Topic D Lesson 23 TeacherArysa TerryNo ratings yet
- Business Mathematics I Bba Bi New CourseDocument2 pagesBusiness Mathematics I Bba Bi New CourseSubrat PantaNo ratings yet
- DLS - Lab Manual PDFDocument24 pagesDLS - Lab Manual PDFNitin PrajapatiNo ratings yet
- Ma110 Course Outline 1 1Document4 pagesMa110 Course Outline 1 1HarrisonNo ratings yet
- Chap 9 Indices, Exponentials and Logarithms Part 1 PDFDocument44 pagesChap 9 Indices, Exponentials and Logarithms Part 1 PDFArahNo ratings yet
- Chapter 3 PDFDocument30 pagesChapter 3 PDFAswaja313No ratings yet
- General Algebraic Modeling Systems (Model Answers)Document37 pagesGeneral Algebraic Modeling Systems (Model Answers)nada abdelrahmanNo ratings yet
- 1402390491ls 8Document12 pages1402390491ls 8USBNo ratings yet
- Fractional Calculus - ApplicationsDocument306 pagesFractional Calculus - ApplicationsJohn Alain Stanley Viraca Vega100% (1)
- AIEEE (All India Engineering/ Pharmacy/ Architecture Entrance Examination)Document17 pagesAIEEE (All India Engineering/ Pharmacy/ Architecture Entrance Examination)Pradheep ArunNo ratings yet
- Unit - IV Laplace TransfromsDocument21 pagesUnit - IV Laplace TransfromsMuthu Ezhilan100% (1)
- 3 - Exponential Log Functions Chapter ReviewDocument10 pages3 - Exponential Log Functions Chapter ReviewMath 30-1 EDGE Study Guide Workbook - by RTD LearningNo ratings yet
- Airtronics MX Sport ManualDocument29 pagesAirtronics MX Sport ManualAlberto TarsiaNo ratings yet
- Functions 2.6 AssessmentDocument7 pagesFunctions 2.6 AssessmentbriNo ratings yet
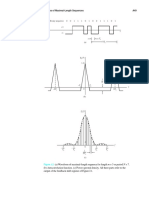
- Complex Fourier Series PDFDocument15 pagesComplex Fourier Series PDFJihan PacerNo ratings yet