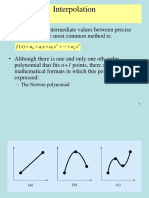
You might also like
- Lagrange Interpolation ChapterDocument59 pagesLagrange Interpolation ChapterSky FireNo ratings yet
- InterpolationDocument12 pagesInterpolationHa Hamza Al-rubasiNo ratings yet
- Lecture 11Document7 pagesLecture 11mavisXzeref 17No ratings yet
- Lagrange Interpolating Polynomials: X X X X X LDocument23 pagesLagrange Interpolating Polynomials: X X X X X Larjay plataNo ratings yet
- Newton Raphson MethodDocument16 pagesNewton Raphson MethodMinh Duy LêNo ratings yet
- Numerical MethodsDocument23 pagesNumerical Methodsarjay plataNo ratings yet
- InterpolationDocument51 pagesInterpolationMuddys007No ratings yet
- Differential Calculus: Function y F (X)Document18 pagesDifferential Calculus: Function y F (X)SilvaSunnyNo ratings yet
- Ma6468-Probability and Statistics Unit I - Random Variables Ma6468-Probability and Statistics Unit I - Random VariablesDocument110 pagesMa6468-Probability and Statistics Unit I - Random Variables Ma6468-Probability and Statistics Unit I - Random VariablesMahendran KNo ratings yet
- Solution of Algebric Trancendental EquationDocument6 pagesSolution of Algebric Trancendental EquationEngineer JONo ratings yet
- Fill in The Blankets With Proper Answers (5 Marks Each, Total 40 Marks)Document5 pagesFill in The Blankets With Proper Answers (5 Marks Each, Total 40 Marks)adbeanNo ratings yet
- Interpolation Methods GuideDocument18 pagesInterpolation Methods GuideDocTor DOOMNo ratings yet
- Class20/24: 1 Stream Ciphers and ApplicationsDocument6 pagesClass20/24: 1 Stream Ciphers and ApplicationsHeetakNo ratings yet
- Visualizing The Components of Lagrange and Newton InterpolationDocument17 pagesVisualizing The Components of Lagrange and Newton InterpolationjemuelNo ratings yet
- 3 InterpolationDocument24 pages3 InterpolationmipunqNo ratings yet
- NA Lecture 25 ADocument53 pagesNA Lecture 25 AAli BhaiNo ratings yet
- Chapter 4 Numerical Differentiation and IntegrationDocument110 pagesChapter 4 Numerical Differentiation and IntegrationKaplan yuNo ratings yet
- GD2203 04 NewtonInterpolation DSDocument36 pagesGD2203 04 NewtonInterpolation DSJames BarnerNo ratings yet
- Week2 Lecture1 PDFDocument25 pagesWeek2 Lecture1 PDFAbdullah AloglaNo ratings yet
- Fourier Series' & Its Application'Document18 pagesFourier Series' & Its Application'Nikunj JhaNo ratings yet
- Lecture5 Withleftover TaylorSeries ErrorAnalysis Aug10 2022Document22 pagesLecture5 Withleftover TaylorSeries ErrorAnalysis Aug10 2022rohit kumarNo ratings yet
- Interpolation TechniquesDocument22 pagesInterpolation TechniquesRudra DharNo ratings yet
- Solution Seç. 10.4 Diprima e BoyceDocument14 pagesSolution Seç. 10.4 Diprima e BoyceharylyNo ratings yet
- Discrete, Continuous and Mixed Random VariablesDocument9 pagesDiscrete, Continuous and Mixed Random VariablesIrma DenaNo ratings yet
- ch1 PPTDocument74 pagesch1 PPTEFRA BININo ratings yet
- Binomial, Poisson, Geometric, Uniform, Exponential, Gamma and Normal DistributionsDocument77 pagesBinomial, Poisson, Geometric, Uniform, Exponential, Gamma and Normal Distributionssangavi kaliyaperumalNo ratings yet
- Exp 1aDocument4 pagesExp 1asanketNo ratings yet
- Chapter 3Document20 pagesChapter 3Omed. HNo ratings yet
- Engineering Mathematics NotesDocument5 pagesEngineering Mathematics NotesSyed Beeban BashaNo ratings yet
- Inverse Interpolation: For Example, Let's Suppose That We Want To Calculate A Zero of The FunctionDocument10 pagesInverse Interpolation: For Example, Let's Suppose That We Want To Calculate A Zero of The FunctionSaad AliKhanNo ratings yet
- RM2Document102 pagesRM2Anonymous eWMnRr70qNo ratings yet
- Fin Dif InterDocument21 pagesFin Dif Inter20E024- GOWTHAMAN. MNo ratings yet
- Unit IIDocument37 pagesUnit IIE.ANANDAPERUMALNo ratings yet
- Unit IIDocument37 pagesUnit IIsamthegamer75No ratings yet
- Verifying Fourier Series with MapleDocument7 pagesVerifying Fourier Series with Mapleaye pyoneNo ratings yet
- ch04 Ma1300Document11 pagesch04 Ma1300rimskysNo ratings yet
- CHAPTER 5 Up 9Document33 pagesCHAPTER 5 Up 9Belay BeleteNo ratings yet
- Numericla MethodDocument45 pagesNumericla Methodsubrozn GamerNo ratings yet
- Differential Calculus: Function y F (X)Document19 pagesDifferential Calculus: Function y F (X)Wasik BillahNo ratings yet
- Polynomial Interpolation TechniquesDocument5 pagesPolynomial Interpolation TechniquesMohammed FouadNo ratings yet
- DerivativesDocument5 pagesDerivativesnochekervinpaulNo ratings yet
- Introduction To Calculus SetDocument58 pagesIntroduction To Calculus SetparvezalamkhanNo ratings yet
- Fourier Series 2Document5 pagesFourier Series 2mrinvictusthefirstNo ratings yet
- Distribution Function of A Random Variable: X If X IfDocument8 pagesDistribution Function of A Random Variable: X If X IfNomad Soul MusicNo ratings yet
- Chapter 3: InterpolationDocument4 pagesChapter 3: InterpolationGoura Sundar TripathyNo ratings yet
- c04 MathexpDocument8 pagesc04 MathexpCharleneMendozaEspirituNo ratings yet
- Interpolation: X A X A X A A X FDocument11 pagesInterpolation: X A X A X A A X FKukuh KurniadiNo ratings yet
- Chapter 4: Derivatives of Logarithmic Function Logarithmic FunctionsDocument19 pagesChapter 4: Derivatives of Logarithmic Function Logarithmic Functionsathia solehahNo ratings yet
- Calc 03 Derivative ApplicationsDocument28 pagesCalc 03 Derivative Applicationsmaciej czekalaNo ratings yet
- PQT Unit1Document61 pagesPQT Unit1Navin0% (1)
- Taylor Series in Economics - Brief OverviewDocument4 pagesTaylor Series in Economics - Brief Overviewpinfeng100% (1)
- Interpolation by Newtons Divided MethodDocument11 pagesInterpolation by Newtons Divided Methodtahiruabdulrahmanbaaba3No ratings yet
- Maths 3 Compiled A.T.EshwarDocument47 pagesMaths 3 Compiled A.T.Eshwarsvc8670No ratings yet
- Divided differences are symmetric functions of their argumentsDocument45 pagesDivided differences are symmetric functions of their argumentsGlory UsoroNo ratings yet
- Lagrange IntepolationDocument10 pagesLagrange IntepolationceanilNo ratings yet
- Theorem On The CircleDocument5 pagesTheorem On The CircleNganku JuniorNo ratings yet
- Chapter 3 (Annotated - 1)Document26 pagesChapter 3 (Annotated - 1)Taylor ZhangNo ratings yet
- 教育部来华留学英语授课品牌课程Document27 pages教育部来华留学英语授课品牌课程creation portalNo ratings yet
- CalTA-derivative (Drawn)Document4 pagesCalTA-derivative (Drawn)HowardNo ratings yet
- Tables of Laguerre Polynomials and Functions: Mathematical Tables Series, Vol. 39From EverandTables of Laguerre Polynomials and Functions: Mathematical Tables Series, Vol. 39No ratings yet
- Adobe Scan Feb 23, 2023Document4 pagesAdobe Scan Feb 23, 2023Beckham ChaileNo ratings yet
- For Nothing KoDocument30 pagesFor Nothing KoBeckham ChaileNo ratings yet
- Hydraulics Notes 0809 RevDocument43 pagesHydraulics Notes 0809 RevS.h. Fahad FiazNo ratings yet
- VIA VA Cat 1 BrochureDocument2 pagesVIA VA Cat 1 BrochureBeckham ChaileNo ratings yet
- Taxi receipt template with date and detailsDocument1 pageTaxi receipt template with date and detailsBeckham ChaileNo ratings yet
- Quiz2 1 April 2022Document2 pagesQuiz2 1 April 2022Beckham ChaileNo ratings yet
- Q 1 SolutionsDocument6 pagesQ 1 SolutionsBeckham ChaileNo ratings yet
- University of Zambia Tutorial on Metal Machining TheoryDocument4 pagesUniversity of Zambia Tutorial on Metal Machining TheoryBeckham ChaileNo ratings yet
- Adobe Scan Feb 23, 2023Document1 pageAdobe Scan Feb 23, 2023Beckham ChaileNo ratings yet
- Mat 3110 Final Exam 2019 20Document4 pagesMat 3110 Final Exam 2019 20Beckham ChaileNo ratings yet
- MEC 4601 Tutorial sheet 5 – PIPE FLOW assignmentDocument1 pageMEC 4601 Tutorial sheet 5 – PIPE FLOW assignmentBeckham ChaileNo ratings yet
- Tutorial 1 ControlDocument3 pagesTutorial 1 ControlBeckham ChaileNo ratings yet
- Lab 6. Mini Project. 2 2022.Document1 pageLab 6. Mini Project. 2 2022.Beckham ChaileNo ratings yet
- MEC 4601 Flow Around Submerged BodiesDocument1 pageMEC 4601 Flow Around Submerged BodiesBeckham ChaileNo ratings yet
- MEC 4402 - Steam Turbines - Air Pollution From ICEs - Assignment 6 - 2022.Document1 pageMEC 4402 - Steam Turbines - Air Pollution From ICEs - Assignment 6 - 2022.Beckham ChaileNo ratings yet
- MEC 3001-AutoCAD 3D Test-2021Document3 pagesMEC 3001-AutoCAD 3D Test-2021Beckham ChaileNo ratings yet
- 2.8 Restricted and Unrestricted RegressionDocument7 pages2.8 Restricted and Unrestricted RegressionNguyen Hoang ThaoNo ratings yet
- Dynare - TutorialDocument27 pagesDynare - TutorialSEBASTIAN DAVID GARCIA ECHEVERRYNo ratings yet
- Chapter 03 TestbankDocument108 pagesChapter 03 TestbankanukshaNo ratings yet
- Chapter 7 Activity Analysis TFDocument14 pagesChapter 7 Activity Analysis TFsyedwajihuddinNo ratings yet
- Nonlinear System Identification of A MIMO Quadruple Tanks System Using NARX ModelDocument7 pagesNonlinear System Identification of A MIMO Quadruple Tanks System Using NARX ModelLilian FabrícioNo ratings yet
- Ordinary Least Square Technique: Advantage of The Principle of Least SquaresDocument9 pagesOrdinary Least Square Technique: Advantage of The Principle of Least SquaresGiri PrasadNo ratings yet
- Wireless RSSI Fingerprinting Localization: Impact of AP Density and Outdated MapsDocument10 pagesWireless RSSI Fingerprinting Localization: Impact of AP Density and Outdated MapsNicoli LourençoNo ratings yet
- Bayes Practice BookDocument229 pagesBayes Practice BookhsuyabNo ratings yet
- The Modelling and Computer Simulation of Mineral TreatmentDocument25 pagesThe Modelling and Computer Simulation of Mineral TreatmentDirceu NascimentoNo ratings yet
- 2008 Book InformationVisualizationDocument184 pages2008 Book InformationVisualizationluisyepez13100% (1)
- (Lecture Notes in Control and Information Sciences) Andrzej Janczak - Identification of Nonlinear Systems Using Neural Networks and Polynomial Models - A Block-Oriented Approach-Springer (2004)Document208 pages(Lecture Notes in Control and Information Sciences) Andrzej Janczak - Identification of Nonlinear Systems Using Neural Networks and Polynomial Models - A Block-Oriented Approach-Springer (2004)Michael CifuentesNo ratings yet
- 2018 Book FoundationsOfBiostatistics PDFDocument474 pages2018 Book FoundationsOfBiostatistics PDFferi100% (2)
- PSOC Two Marks 4Document3 pagesPSOC Two Marks 4gavinilaaNo ratings yet
- ForecastingDocument16 pagesForecastingLily SuckerNo ratings yet
- Mas - Activity Cost and CVP Analysis Part 1Document6 pagesMas - Activity Cost and CVP Analysis Part 1Ma Teresa B. CerezoNo ratings yet
- Lesson 7 - Linear Correlation and Simple Linear RegressionDocument8 pagesLesson 7 - Linear Correlation and Simple Linear Regressionchloe frostNo ratings yet
- Chapter 12 - Lecture 1 Linear Regression Model and Estimation of ParametersDocument19 pagesChapter 12 - Lecture 1 Linear Regression Model and Estimation of ParametersNdomaduNo ratings yet
- Radar Emitter Localization Using UAVs and Shipborne SensorsDocument14 pagesRadar Emitter Localization Using UAVs and Shipborne SensorssourabhbasuNo ratings yet
- Econometric Analysis Course OutlineDocument10 pagesEconometric Analysis Course OutlineAlison LimNo ratings yet
- IDL Handiguide v5.4Document88 pagesIDL Handiguide v5.4Robin BeckNo ratings yet
- Research Paper On Magic SquareDocument6 pagesResearch Paper On Magic Squarevstxevplg100% (1)
- Formulationforfree Standingstaircase PDFDocument8 pagesFormulationforfree Standingstaircase PDFjames112522100% (1)
- Crimes in IndiaDocument88 pagesCrimes in Indiateja internet xeroxNo ratings yet
- (M) Calculating The Gutenberg-Richter B Value - FelzerDocument21 pages(M) Calculating The Gutenberg-Richter B Value - FelzerEkrar WinataNo ratings yet
- cs229 Notes1 PDFDocument28 pagescs229 Notes1 PDFRichieQCNo ratings yet
- Analysis of Time SeriesDocument32 pagesAnalysis of Time SeriesAnika KumarNo ratings yet
- BPB31103 Production & Operations Management ch8Document89 pagesBPB31103 Production & Operations Management ch8Anis TajuldinNo ratings yet
- AText BookDocument545 pagesAText BookranganathanpsgNo ratings yet
- Complete Lab Manual Lab VIIDocument49 pagesComplete Lab Manual Lab VIIShweta ChaudhariNo ratings yet
- The Effects of The COVID-19 Pandemic On The Philippine Stock Exchange IndexDocument39 pagesThe Effects of The COVID-19 Pandemic On The Philippine Stock Exchange IndexericNo ratings yet