You might also like
- 3 STAT-602 Regression & CorrelationDocument4 pages3 STAT-602 Regression & CorrelationjazibNo ratings yet
- Regression and Multiple Regression AnalysisDocument21 pagesRegression and Multiple Regression AnalysisRaghu NayakNo ratings yet
- REGRESSION ANALYSIS AND CAUSALITYDocument31 pagesREGRESSION ANALYSIS AND CAUSALITYVikha Suryo KharismawanNo ratings yet
- Econometrics For FinanceDocument54 pagesEconometrics For Financenegussie birieNo ratings yet
- Simple Linear RegressionDocument95 pagesSimple Linear RegressionPooja GargNo ratings yet
- Transform Y to Correct Model InadequaciesDocument27 pagesTransform Y to Correct Model InadequaciesLookey_Loke_5014No ratings yet
- 1602083443940498Document9 pages1602083443940498mhamadhawlery16No ratings yet
- ML Assignment No. 1: 1.1 TitleDocument8 pagesML Assignment No. 1: 1.1 TitleKirti PhegadeNo ratings yet
- unit 5Document104 pagesunit 5downloadjain123No ratings yet
- Estimating Demand FunctionDocument45 pagesEstimating Demand FunctionManisha AdliNo ratings yet
- Regression: 9.1.1 DefinitionDocument20 pagesRegression: 9.1.1 DefinitionBhawna JoshiNo ratings yet
- Regression ModelDocument26 pagesRegression ModelkhadarcabdiNo ratings yet
- Statistics and Probability Week 7 - 8Document4 pagesStatistics and Probability Week 7 - 8Aguila AlvinNo ratings yet
- Linear Regression and Correlation AnalysisDocument54 pagesLinear Regression and Correlation AnalysisMohit VermaNo ratings yet
- Regression and CorrelationDocument13 pagesRegression and CorrelationzNo ratings yet
- Stat and Prob 7-8Document4 pagesStat and Prob 7-8Aguila AlvinNo ratings yet
- Chapter Eight 8 Simple Linear Regression and Correlation: N XY X Y N X XDocument5 pagesChapter Eight 8 Simple Linear Regression and Correlation: N XY X Y N X XtaysirbestNo ratings yet
- Stats and MathsDocument29 pagesStats and MathsMystiquemashalNo ratings yet
- Institute: Uie (Ait-Cse) : CST-229 Lecture - 1.5Document27 pagesInstitute: Uie (Ait-Cse) : CST-229 Lecture - 1.5Sarthak AgarwalNo ratings yet
- ArunRangrejDocument5 pagesArunRangrejArun RangrejNo ratings yet
- Chapter Five: Regression and CorrelationDocument12 pagesChapter Five: Regression and Correlationጌታ እኮ ነውNo ratings yet
- Regression and Correlation Analysis in One SampleDocument20 pagesRegression and Correlation Analysis in One SamplejesselNo ratings yet
- Chapter 2 SLRMDocument40 pagesChapter 2 SLRMmerondemekets12347No ratings yet
- QTDM Unit-2 Correlation & Regression AnalysisDocument12 pagesQTDM Unit-2 Correlation & Regression AnalysisAishwarya ManishNo ratings yet
- Derivation of The Ordinary Least Squares Estimator Multiple Regression CaseDocument10 pagesDerivation of The Ordinary Least Squares Estimator Multiple Regression CaseJ Cesar GallegoNo ratings yet
- Chapter 3 EconometricsDocument34 pagesChapter 3 EconometricsAshenafi ZelekeNo ratings yet
- 03 ES Regression CorrelationDocument14 pages03 ES Regression CorrelationMuhammad AbdullahNo ratings yet
- Math (Regression Theory)Document31 pagesMath (Regression Theory)Alina BorysenkoNo ratings yet
- Statistics of Two Variables: FunctionsDocument15 pagesStatistics of Two Variables: FunctionsAlinour AmenaNo ratings yet
- Final NoteDocument23 pagesFinal NoteSandeep SahaNo ratings yet
- Regression AnalysisDocument12 pagesRegression Analysispravesh1987No ratings yet
- Regression Analysis Explained in 40 CharactersDocument14 pagesRegression Analysis Explained in 40 Characterspranay0% (1)
- FM Project REPORT - Group3Document24 pagesFM Project REPORT - Group3Jagmohan SainiNo ratings yet
- STAT Q4 Week 9 Enhanced.v1Document11 pagesSTAT Q4 Week 9 Enhanced.v1queenkysultan14No ratings yet
- Regression Analysis (Spring, 2000) : by WonjaeDocument6 pagesRegression Analysis (Spring, 2000) : by WonjaeLucian MaxNo ratings yet
- Regression and Correlation AnalysisDocument16 pagesRegression and Correlation Analysisfrancis MagobaNo ratings yet
- Correlation and RegressionDocument16 pagesCorrelation and RegressionBonane AgnesNo ratings yet
- Difference Equations in Normed Spaces: Stability and OscillationsFrom EverandDifference Equations in Normed Spaces: Stability and OscillationsNo ratings yet
- 1.linear Regression PSPDocument92 pages1.linear Regression PSPsharadNo ratings yet
- LM10 Simple Linear Regression IFT NotesDocument28 pagesLM10 Simple Linear Regression IFT NotesYuri BNo ratings yet
- RegressionDocument6 pagesRegressionMansi ChughNo ratings yet
- Empirical Models: Data CollectionDocument16 pagesEmpirical Models: Data CollectionkayangNo ratings yet
- Linear Regression ModelsDocument42 pagesLinear Regression ModelsNomonde NatashaNo ratings yet
- Unit 9 Simple Linear Regression: StructureDocument22 pagesUnit 9 Simple Linear Regression: Structuresita rautelaNo ratings yet
- Chapter4 Regression ModelAdequacyCheckingDocument38 pagesChapter4 Regression ModelAdequacyCheckingAishat OmotolaNo ratings yet
- M422 Empirical Modeling GuideDocument14 pagesM422 Empirical Modeling GuidekeanshengNo ratings yet
- How Can We Explore The Association Between Two Quantitative Variables?Document7 pagesHow Can We Explore The Association Between Two Quantitative Variables?Avericl H n v ejkeNo ratings yet
- A Weak Convergence Approach to the Theory of Large DeviationsFrom EverandA Weak Convergence Approach to the Theory of Large DeviationsRating: 4 out of 5 stars4/5 (1)
- Solving Multicollinearity Problem: Int. J. Contemp. Math. Sciences, Vol. 6, 2011, No. 12, 585 - 600Document16 pagesSolving Multicollinearity Problem: Int. J. Contemp. Math. Sciences, Vol. 6, 2011, No. 12, 585 - 600Tiberiu TincaNo ratings yet
- Statistical Analysis: Linear RegressionDocument36 pagesStatistical Analysis: Linear RegressionDafter KhemboNo ratings yet
- Regression Analysis Linear and Multiple RegressionDocument6 pagesRegression Analysis Linear and Multiple RegressionPauline Kay Sunglao GayaNo ratings yet
- Regression Analysis Linear and Multiple RegressionDocument6 pagesRegression Analysis Linear and Multiple RegressionPauline Kay Sunglao GayaNo ratings yet
- Regression Analysis: Understanding Linear and Multiple Regression Models in 40 CharactersDocument6 pagesRegression Analysis: Understanding Linear and Multiple Regression Models in 40 CharactersPauline Kay Sunglao GayaNo ratings yet
- REGRESSION CHECKLIST GUIDEDocument3 pagesREGRESSION CHECKLIST GUIDEYixin XiaNo ratings yet
- Correlation and RegressionDocument10 pagesCorrelation and RegressionbudhailNo ratings yet
- Lab-3: Regression Analysis and Modeling Name: Uid No. ObjectiveDocument9 pagesLab-3: Regression Analysis and Modeling Name: Uid No. ObjectiveVishal RaminaNo ratings yet
- Lecture 6 Simple Linear RegressionDocument36 pagesLecture 6 Simple Linear RegressionAshley Sophia GarciaNo ratings yet
- task1Document9 pagestask1Dương Vũ MinhNo ratings yet
- Topic:-Regression: Name: - Teotia Nidhi Class: - M.SC BiotechnologyDocument10 pagesTopic:-Regression: Name: - Teotia Nidhi Class: - M.SC Biotechnologynidhi teotiaNo ratings yet
- GhazwatfullDocument22 pagesGhazwatfullSalman Nazir WattuNo ratings yet
- Wood 1981Document3 pagesWood 1981Salman Nazir WattuNo ratings yet
- Islamiyat Advanced MCQSDocument540 pagesIslamiyat Advanced MCQSSalman Nazir WattuNo ratings yet
- Cross 1996Document10 pagesCross 1996Salman Nazir WattuNo ratings yet
- Recent Advances in Volarization and Utilization of Fruits WasteDocument2 pagesRecent Advances in Volarization and Utilization of Fruits WasteSalman Nazir WattuNo ratings yet
- English Ree Cas Das CabiDocument7 pagesEnglish Ree Cas Das CabiSalman Nazir WattuNo ratings yet
- Essential Medicines Lists Punjab 2014Document65 pagesEssential Medicines Lists Punjab 2014Salman Nazir WattuNo ratings yet
- Cotton FactsDocument172 pagesCotton FactsSalman Nazir WattuNo ratings yet
- Natural Energy Resources in PunjabDocument13 pagesNatural Energy Resources in PunjabSalman Nazir WattuNo ratings yet
- Renewableenergyresourcesinpakistan 150307040457 Conversion Gate01Document47 pagesRenewableenergyresourcesinpakistan 150307040457 Conversion Gate01Salman Nazir WattuNo ratings yet
- Pakistan Phyto Society Report 2013-2018Document3 pagesPakistan Phyto Society Report 2013-2018Salman Nazir WattuNo ratings yet
- Steamed Vegetables With Chile Lime ButterDocument2 pagesSteamed Vegetables With Chile Lime ButterSalman Nazir WattuNo ratings yet
- CIVIL ENGINEERING RESULTSDocument55 pagesCIVIL ENGINEERING RESULTSJahnavi NaniNo ratings yet
- Course2 - DataAnalysis With Python - Week3 - Exploratory Data AnalysisDocument23 pagesCourse2 - DataAnalysis With Python - Week3 - Exploratory Data AnalysisStefano PenturyNo ratings yet
- Solution Manual For Decision Analysis For Management Judgment, 4th EditionDocument1 pageSolution Manual For Decision Analysis For Management Judgment, 4th EditionMaria Cabral0% (2)
- Action ResearchDocument14 pagesAction ResearchAngelo SorianoNo ratings yet
- Master's Applied Econometrics SyllabusDocument4 pagesMaster's Applied Econometrics SyllabusZulfa KamiliaNo ratings yet
- 2006 Examination of Econometrics PrinciplesDocument99 pages2006 Examination of Econometrics Principles이찬호No ratings yet
- Modern engineering analysis tools in NX CAEDocument1 pageModern engineering analysis tools in NX CAEAaushKumarNo ratings yet
- Research Paper Outline About HIVDocument4 pagesResearch Paper Outline About HIVzen142No ratings yet
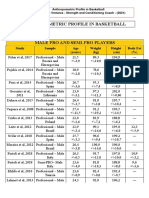
- Basketball: Anthropometric Profile of PlayersDocument6 pagesBasketball: Anthropometric Profile of PlayersAdriano VretarosNo ratings yet
- Error, Their Types, Their Measurements: Presented By: Marta ZelekeDocument54 pagesError, Their Types, Their Measurements: Presented By: Marta ZelekeEndalk SimegnNo ratings yet
- Epom405eecs411 Course SyllabusDocument7 pagesEpom405eecs411 Course SyllabusDavid VarkeyNo ratings yet
- MRD-004 June 2020Document4 pagesMRD-004 June 2020Sagar DagarNo ratings yet
- SEMDocument10 pagesSEMshona75No ratings yet
- Assessment in Early-Childhood EduDocument203 pagesAssessment in Early-Childhood EduRahma 'mbja' Jayanti100% (3)
- Introduction To Methods of Data AnalysisDocument2 pagesIntroduction To Methods of Data Analysisbinny25No ratings yet
- G12 SLM4 PR2 Q4 v2 - FinalDocument26 pagesG12 SLM4 PR2 Q4 v2 - FinalNancy LantinganNo ratings yet
- Research Methods: Content Analysis Field ResearchDocument30 pagesResearch Methods: Content Analysis Field ResearchBeytullah ErdoğanNo ratings yet
- Chapter 5 Measure - GBDocument134 pagesChapter 5 Measure - GBKaranShindeNo ratings yet
- SamplingDocument13 pagesSamplingArun Mishra100% (1)
- How Does The Sample Size Affect GARCH Model?: H.S. NG and K.P. LamDocument4 pagesHow Does The Sample Size Affect GARCH Model?: H.S. NG and K.P. LamSurendra Pal SinghNo ratings yet
- Definition of Marketing ResearchDocument13 pagesDefinition of Marketing Researchjoydeep12No ratings yet
- Calibrating Eyepiece Graticule Using Micrometer / Calculating Linear MagnificationDocument17 pagesCalibrating Eyepiece Graticule Using Micrometer / Calculating Linear MagnificationAida MalikovaNo ratings yet
- Practical Research 2Document26 pagesPractical Research 2albayalvinjohnNo ratings yet
- Testing Mediation Using Medsem' Package in StataDocument17 pagesTesting Mediation Using Medsem' Package in StataAftab Tabasam0% (1)
- Unit-4 - Hypothesis TestingDocument24 pagesUnit-4 - Hypothesis TestingMANTHAN JADHAVNo ratings yet
- What Is Sampling?: PopulationDocument4 pagesWhat Is Sampling?: PopulationFarhaNo ratings yet
- Failure Rate Estimation: M.Lampton UCB SSLDocument7 pagesFailure Rate Estimation: M.Lampton UCB SSLgokulm2202No ratings yet
- Bank of ActivitiesDocument8 pagesBank of ActivitiesreinaterNo ratings yet
- PR1 Long Quiz CookeryDocument34 pagesPR1 Long Quiz CookeryKEVIN RANSOM BAYRONNo ratings yet
- The Aharonov-Bohm Effect in Relativistic Quantum TheoryDocument31 pagesThe Aharonov-Bohm Effect in Relativistic Quantum Theoryfurrygerbil100% (5)