You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5795)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1091)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (345)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (121)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (400)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- SVDR-3000 Operation Manual - 071109 - Rev.1.2Document47 pagesSVDR-3000 Operation Manual - 071109 - Rev.1.2Alexander Smetankin100% (2)
- SFN Digital Voltmeter, Ammeter, Frequency MeterDocument8 pagesSFN Digital Voltmeter, Ammeter, Frequency MeterEng.MohamedNo ratings yet
- Machinery Diagnostic PlotsDocument16 pagesMachinery Diagnostic Plotsfazzlie100% (1)
- MDBOX Dynamic Platform Integrated Controller User MannualDocument83 pagesMDBOX Dynamic Platform Integrated Controller User MannualLuis Omar Nuñez RomeroNo ratings yet
- C4 CACTUS 1,2 e-THP-HNZ (EB2DT) 1.2 - (14-18)Document13 pagesC4 CACTUS 1,2 e-THP-HNZ (EB2DT) 1.2 - (14-18)Fabian Carrasco NaulaNo ratings yet
- Scitranslmed - Abo0699 Mdar Reproducibility ChecklistDocument5 pagesScitranslmed - Abo0699 Mdar Reproducibility Checklistmichael baileyNo ratings yet
- Pedometer Measured Physical Activity and Health.4Document7 pagesPedometer Measured Physical Activity and Health.4michael baileyNo ratings yet
- Gold 121006124956 Phpapp02Document27 pagesGold 121006124956 Phpapp02michael baileyNo ratings yet
- 3 Interview Transcripts From Healthy Body Healthy Hair The Truth About Hair LossDocument38 pages3 Interview Transcripts From Healthy Body Healthy Hair The Truth About Hair Lossmichael baileyNo ratings yet
- Zenbook 13S Oled Um5302Ta-Lx420W: Asus Facebook Twitter Youtube Pinterest Google+Document2 pagesZenbook 13S Oled Um5302Ta-Lx420W: Asus Facebook Twitter Youtube Pinterest Google+michael baileyNo ratings yet
- TVO Technology Highlight 41 Toroidal PropellerDocument2 pagesTVO Technology Highlight 41 Toroidal Propellermichael baileyNo ratings yet
- 217 Release Notes Firmware 11226Document1 page217 Release Notes Firmware 11226michael baileyNo ratings yet
- Sri Aurobindo's Integral Yoga: A Research Perspective: ISSN: 2454-132X Impact Factor: 4.295Document3 pagesSri Aurobindo's Integral Yoga: A Research Perspective: ISSN: 2454-132X Impact Factor: 4.295michael baileyNo ratings yet
- 226 Release Notes Firmware 10077Document4 pages226 Release Notes Firmware 10077michael baileyNo ratings yet
- 225 Release Notes Firmware 10637Document2 pages225 Release Notes Firmware 10637michael baileyNo ratings yet
- Sprac 87Document13 pagesSprac 87michael baileyNo ratings yet
- Infineon Scaling Processor Performance Safety Automotive WPDocument12 pagesInfineon Scaling Processor Performance Safety Automotive WPmichael baileyNo ratings yet
- Spruig 5 DDocument12 pagesSpruig 5 Dmichael baileyNo ratings yet
- Comparative Analysis of Conventional and Swath Passenger CatamaranDocument11 pagesComparative Analysis of Conventional and Swath Passenger Catamaranmichael baileyNo ratings yet
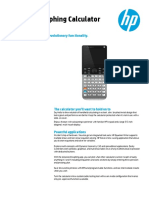
- HP Prime Graphing Calculator (G8X92AA) : Touch-Enabled. Full Color. Revolutionary FunctionalityDocument3 pagesHP Prime Graphing Calculator (G8X92AA) : Touch-Enabled. Full Color. Revolutionary Functionalitymichael baileyNo ratings yet
- Siemens SW Veloce Prototyping Solutions Accelerate Verification WP 84204 D3Document10 pagesSiemens SW Veloce Prototyping Solutions Accelerate Verification WP 84204 D3michael baileyNo ratings yet
- Forex Insiders: Superior FX Signals. ComDocument19 pagesForex Insiders: Superior FX Signals. Commichael baileyNo ratings yet
- Forex 1229535238837254 1Document25 pagesForex 1229535238837254 1michael bailey100% (1)
- Brochure Custom Units 20131Document2 pagesBrochure Custom Units 20131michael baileyNo ratings yet
- OSS Lyon - Oct'2019Document12 pagesOSS Lyon - Oct'2019michael baileyNo ratings yet
- Memory and Card Playing: How To Remember CardsDocument23 pagesMemory and Card Playing: How To Remember Cardsmichael baileyNo ratings yet
- Admiral X Lence and C Force: by Admiral Tecnomar - Yachting Hub of The Italian Sea GroupDocument5 pagesAdmiral X Lence and C Force: by Admiral Tecnomar - Yachting Hub of The Italian Sea Groupmichael baileyNo ratings yet
- Forex "Trend Master " System: Michael SelimDocument27 pagesForex "Trend Master " System: Michael Selimmichael baileyNo ratings yet
- Terms & Conditions For Visitors To Tristan Da CunhaDocument6 pagesTerms & Conditions For Visitors To Tristan Da Cunhamichael baileyNo ratings yet
- The Art of The ApproachDocument9 pagesThe Art of The Approachmichael bailey100% (1)
- Summer Schedule 2013: Now Airing in A Plane Near You..Document1 pageSummer Schedule 2013: Now Airing in A Plane Near You..michael baileyNo ratings yet
- How To Charm A Woman:: 3 Qualities You Need To Develop, NOWDocument47 pagesHow To Charm A Woman:: 3 Qualities You Need To Develop, NOWmichael baileyNo ratings yet
- The Psychology of Love: Arif AneesDocument50 pagesThe Psychology of Love: Arif Aneesmichael baileyNo ratings yet
- Guy Gets Girl Ebook Reviews-How To Pickup Date and Seduce WomenDocument11 pagesGuy Gets Girl Ebook Reviews-How To Pickup Date and Seduce Womenmichael bailey0% (1)
- The Tao of Badass: Review of A "Popular Dating Coach System"Document104 pagesThe Tao of Badass: Review of A "Popular Dating Coach System"michael bailey100% (1)
- Etos TD and Etos ED Innovative Motor-Drive Solutions With Integrated MonitoringDocument12 pagesEtos TD and Etos ED Innovative Motor-Drive Solutions With Integrated MonitoringKelly chatukuNo ratings yet
- Digital Electronics - Principal and Application PDFDocument723 pagesDigital Electronics - Principal and Application PDFKamal Bhattacharjee100% (2)
- BC-1800 Service ManualDocument99 pagesBC-1800 Service Manualneeraj guptaNo ratings yet
- JMC iHSV57-30 User Manual PDFDocument24 pagesJMC iHSV57-30 User Manual PDFvictor rodriguezNo ratings yet
- Fm452 Operating Instructions en-USDocument200 pagesFm452 Operating Instructions en-USyasirdabirNo ratings yet
- 183-Design Review Check Tool For IT SystemDocument13 pages183-Design Review Check Tool For IT Systemvin ssNo ratings yet
- Ex TTsem 2Document7 pagesEx TTsem 2Madheswaran PGNo ratings yet
- Sri Ramakrishna Institute of Technology, Coimbatore-10: Mechatronics QUIZ-1Document4 pagesSri Ramakrishna Institute of Technology, Coimbatore-10: Mechatronics QUIZ-1Veerakumar SNo ratings yet
- Diagnostic Trouble Codes: TroubleshootingDocument19 pagesDiagnostic Trouble Codes: TroubleshootingMbahdiro KolenxNo ratings yet
- Signals and Systems Using MATLAB: Luis F. ChaparroDocument18 pagesSignals and Systems Using MATLAB: Luis F. ChaparroJoshua HernandezNo ratings yet
- Pacific NautilusDocument10 pagesPacific NautilusyamalieuNo ratings yet
- EE F19 F20 CurriculumDocument190 pagesEE F19 F20 CurriculumHuma MalikNo ratings yet
- Operation, Installation and Service Manual: Original Documentation / Keep For Future ReferenceDocument164 pagesOperation, Installation and Service Manual: Original Documentation / Keep For Future ReferenceRoyson Joseph100% (1)
- FMB70 Deltapilot S Medidor de Nivel HDocument44 pagesFMB70 Deltapilot S Medidor de Nivel HLICONSA MICHOACANNo ratings yet
- Conveyor Safety Switches 2 5Document16 pagesConveyor Safety Switches 2 5Bibhu Ranjan MohantyNo ratings yet
- Engineering and Applied Science - Graduate Studies, University of ReginaDocument32 pagesEngineering and Applied Science - Graduate Studies, University of Reginamanmohan singhNo ratings yet
- Arl-200 Electrical Diagrams v13Document88 pagesArl-200 Electrical Diagrams v13Fidan Latifi86% (22)
- Chapter 17 The Telephone CKTDocument3 pagesChapter 17 The Telephone CKTJ.A. RockwellNo ratings yet
- Process and Control System (General)Document16 pagesProcess and Control System (General)Sang Duong VanNo ratings yet
- Kistler Pressure SensorDocument23 pagesKistler Pressure SensorbmyertekinNo ratings yet
- Faculty of Engineering (FKJ) : Electronic Engineering (COMPUTER) UH6523002/HK20Document27 pagesFaculty of Engineering (FKJ) : Electronic Engineering (COMPUTER) UH6523002/HK20aibramai3No ratings yet
- ECM/PCM Input and Output TestsDocument2 pagesECM/PCM Input and Output TestsDhami NongNo ratings yet
- Module 3: Sampling and Reconstruction Lecture 25: Aliasing (Under Sampling)Document2 pagesModule 3: Sampling and Reconstruction Lecture 25: Aliasing (Under Sampling)Prasad KavthakarNo ratings yet
- Quiz Type ImagingDocument12 pagesQuiz Type Imagingjessamae.bucad.cvtNo ratings yet
- Paper Adrian K RahardjoDocument7 pagesPaper Adrian K RahardjoNaufal Reyhan FadhilNo ratings yet