You might also like
- Final ReportDocument13 pagesFinal Reportapi-465329396No ratings yet
- Final ReportDocument13 pagesFinal Reportapi-465329396No ratings yet
- 2011-01 - Best and Worst Performing National Networks, UNGCDocument3 pages2011-01 - Best and Worst Performing National Networks, UNGCGlobal Compact CriticsNo ratings yet
- Data Analysis CIA - 1Document6 pagesData Analysis CIA - 1Albert Davis 2027916No ratings yet
- The 2010 Legatum Prosperity IndexDocument4 pagesThe 2010 Legatum Prosperity IndexEleazar Narváez BelloNo ratings yet
- 2 Milk Production and ConsumptionDocument8 pages2 Milk Production and ConsumptionMonty KushwahaNo ratings yet
- ANALYSIS-ON-THE-CONSUMERS-SPENDING-HABIT-BASED-ON-AGE-RELATED-REVENUE-TRENDS-USING-A-SEX-BASED-DATA.pdfDocument13 pagesANALYSIS-ON-THE-CONSUMERS-SPENDING-HABIT-BASED-ON-AGE-RELATED-REVENUE-TRENDS-USING-A-SEX-BASED-DATA.pdfapollo越No ratings yet
- Bor RS 26 Juli 2021Document85 pagesBor RS 26 Juli 2021Anonymous TestingNo ratings yet
- ODB 4thedition GlobalReportDocument36 pagesODB 4thedition GlobalReportPhilip Finlay BryanNo ratings yet
- Materi Biostastitika TugasDocument8 pagesMateri Biostastitika Tugas084 Nurhalimatus SyadiyahNo ratings yet
- SOWC 2016 All Tables 261Document127 pagesSOWC 2016 All Tables 261Benjamin Barrera BautistaNo ratings yet
- ContentServer AspDocument150 pagesContentServer AspNastea SelariNo ratings yet
- Top 50 countries for planned meetings, unaffected meetings and hybrid meetings in 2021Document13 pagesTop 50 countries for planned meetings, unaffected meetings and hybrid meetings in 2021Jose María Mateu100% (1)
- USR2021 - Publications On Cross-Cutting Strategic TechnologiesDocument590 pagesUSR2021 - Publications On Cross-Cutting Strategic TechnologiesjosebermardorafaelNo ratings yet
- Cost - of - Living FINALDocument9 pagesCost - of - Living FINALAmrutha VNo ratings yet
- Bor RS 21 Juli 2021Document91 pagesBor RS 21 Juli 2021Anonymous TestingNo ratings yet
- Meter Manual 2 16Document27 pagesMeter Manual 2 16Gime PNo ratings yet
- Bor RS 17 Juli 2021Document84 pagesBor RS 17 Juli 2021Anonymous TestingNo ratings yet
- Instructions:: Answer Ques1Document11 pagesInstructions:: Answer Ques1Camilah RoslanNo ratings yet
- 4-GP 4 For 2017Document1 page4-GP 4 For 2017omkarbhaskarNo ratings yet
- World Oil Domestic Consumption StatisticsDocument4 pagesWorld Oil Domestic Consumption Statisticsanon_163808526No ratings yet
- ICCA Rankings 2022Document18 pagesICCA Rankings 2022Mirla LadinesNo ratings yet
- Current Protected Area (Pa) Coverage of Alliance For Zero Extinction (Aze) Sites by Country (Data Supplied by Birdlife International)Document4 pagesCurrent Protected Area (Pa) Coverage of Alliance For Zero Extinction (Aze) Sites by Country (Data Supplied by Birdlife International)rezaNo ratings yet
- Histogram Steps V V ImpDocument15 pagesHistogram Steps V V ImpAnirban BhowalNo ratings yet
- Effects of Sleep on Student GradesDocument8 pagesEffects of Sleep on Student GradesJohn Paul GuarinNo ratings yet
- 04 ACE Computers DataDocument5 pages04 ACE Computers Datapifana5995No ratings yet
- StatsDocument4 pagesStatsSteph GonzagaNo ratings yet
- Chapter 4 Marketing AspectDocument16 pagesChapter 4 Marketing AspectArbie ChuaNo ratings yet
- Ruspini Nearest NeighbourDocument8 pagesRuspini Nearest NeighbourTamara MaharaniNo ratings yet
- Bor RS 20 Juli 2021Document85 pagesBor RS 20 Juli 2021Anonymous TestingNo ratings yet
- 3.data - Milk Production and ConsumptionDocument7 pages3.data - Milk Production and ConsumptiondairyNo ratings yet
- Is There A Pattern of World DevelopmentDocument4 pagesIs There A Pattern of World DevelopmentSagnik KarNo ratings yet
- Export LBG by Producer 2018 2019 ComparisonDocument38 pagesExport LBG by Producer 2018 2019 Comparisonmanuel.margarit6009No ratings yet
- BOR RS 14 JULI 2021 - All - New - v2Document83 pagesBOR RS 14 JULI 2021 - All - New - v2Mohammad PradictaNo ratings yet
- Bor RS 27 Juli 2021Document85 pagesBor RS 27 Juli 2021Anonymous TestingNo ratings yet
- Bor RS 4 Agustus 2021Document91 pagesBor RS 4 Agustus 2021Anonymous TestingNo ratings yet
- Statistics Exp1Document3 pagesStatistics Exp1AdityaNo ratings yet
- ICCA Statistics 2019Document39 pagesICCA Statistics 2019Jose María MateuNo ratings yet
- WASEDA Digital Government Ranking 2019 2020Document23 pagesWASEDA Digital Government Ranking 2019 2020Kiki PranowoNo ratings yet
- Ketepatan Pengembalian RM Rawat InapDocument4 pagesKetepatan Pengembalian RM Rawat InapciptaningtyasNo ratings yet
- App5 en 1 Appx 4.1Document1 pageApp5 en 1 Appx 4.1Al Jane Amisola EsverNo ratings yet
- Individual Project: BUS 250/ECON 265 Issue Date: September 26, 2021 Submission Date: October 21, 2021Document12 pagesIndividual Project: BUS 250/ECON 265 Issue Date: September 26, 2021 Submission Date: October 21, 2021haseeb ahmedNo ratings yet
- Statistical Yearbook of The Republic of China, 2006Document284 pagesStatistical Yearbook of The Republic of China, 2006api-3861618100% (1)
- Bor RS 27 Agustus 2021Document91 pagesBor RS 27 Agustus 2021Anonymous TestingNo ratings yet
- Statistics QuestionDocument2 pagesStatistics Questionashishamitav123No ratings yet
- Acts Igures: Philippines' Performance in The Covid-19 Resilience Ranking, 2021Document2 pagesActs Igures: Philippines' Performance in The Covid-19 Resilience Ranking, 2021Lau SianNo ratings yet
- Bor RS 5 Juli 2021Document91 pagesBor RS 5 Juli 2021Anonymous TestingNo ratings yet
- CGPSS4 Section IIIRetail PaymentsDocument94 pagesCGPSS4 Section IIIRetail PaymentsEko YuliantoNo ratings yet
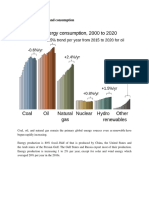
- Global energy production, consumption and trade in 2021Document10 pagesGlobal energy production, consumption and trade in 2021Sazzad HossainNo ratings yet
- Table 1: National Venture Capital Pools in Asia by Country and Year, in Billions of U.S. DollarsDocument26 pagesTable 1: National Venture Capital Pools in Asia by Country and Year, in Billions of U.S. DollarsoshimaxNo ratings yet
- Various Economic IndexDocument7 pagesVarious Economic IndexudayNo ratings yet
- Grade Distribution Subjectwise-GradewiseDocument2 pagesGrade Distribution Subjectwise-GradewiseAisha Coowar DurbassNo ratings yet
- Paper 1-26-36Document11 pagesPaper 1-26-36Cupe Quispe AlessandroNo ratings yet
- M Ridho HusaeniDocument16 pagesM Ridho HusaeniRidho HusaeniNo ratings yet
- Bor RS 29 Juni 2021Document91 pagesBor RS 29 Juni 2021Anonymous TestingNo ratings yet
- Testing of HypothesisDocument21 pagesTesting of Hypothesisvykuntha rao sahukariNo ratings yet
- Bor RS 30 Juni 2021Document94 pagesBor RS 30 Juni 2021amalaNo ratings yet
- Test-2 Test-3 Test-4 Initiating Planning Execution M&C Closing TotalDocument2 pagesTest-2 Test-3 Test-4 Initiating Planning Execution M&C Closing TotalPrashant TewariNo ratings yet
- Name Muhammad Ali Roll# F17-2103 Program M.B.A Assiment# 2Document6 pagesName Muhammad Ali Roll# F17-2103 Program M.B.A Assiment# 2Mirza ImranNo ratings yet
- Alaura Activity 16Document2 pagesAlaura Activity 16Monica AlauraNo ratings yet
- NAAADocument3 pagesNAAAMonica AlauraNo ratings yet
- Alaura - Activity 18Document4 pagesAlaura - Activity 18Monica AlauraNo ratings yet
- Meaning & Roles of ManagementDocument14 pagesMeaning & Roles of ManagementMonica AlauraNo ratings yet
- Alau - Illustration-Benefits of DanceDocument6 pagesAlau - Illustration-Benefits of DanceMonica AlauraNo ratings yet
- Week 1 Topic 1 - 3Document15 pagesWeek 1 Topic 1 - 3Monica AlauraNo ratings yet
- Course GuideDocument24 pagesCourse GuideMonica AlauraNo ratings yet
- CIO 100 2011 - Google Apps For Business-Keval Shah-SumariaDocument9 pagesCIO 100 2011 - Google Apps For Business-Keval Shah-SumariaCIOEastAfricaNo ratings yet
- Amanda Barrera Final Draft Career EssayDocument4 pagesAmanda Barrera Final Draft Career Essayapi-527317832No ratings yet
- Test Procedure Offer 019-14V 3015Document5 pagesTest Procedure Offer 019-14V 3015sohaibNo ratings yet
- Breaking Containment Checklist EssentialsDocument4 pagesBreaking Containment Checklist Essentialsromedic36No ratings yet
- CCIE SPv4 Topology DiagramsDocument17 pagesCCIE SPv4 Topology DiagramsTilak RoyNo ratings yet
- CTG7 SG Eng 3.0Document103 pagesCTG7 SG Eng 3.0Caalaa Dabalaa LamuuNo ratings yet
- 3 Hours / 70 Marks: Seat NoDocument2 pages3 Hours / 70 Marks: Seat Nopr gamingNo ratings yet
- Bank Account Details enDocument4 pagesBank Account Details enAliyev ElvinNo ratings yet
- Experimental Phonetics 311Document7 pagesExperimental Phonetics 311Ebinabo EriakumaNo ratings yet
- 2. CHUYÊN ĐỀ 2 (LỖI SAI + VIẾT CÂU)Document4 pages2. CHUYÊN ĐỀ 2 (LỖI SAI + VIẾT CÂU)farm 3 chi di0% (1)
- Risk Assessment of Consumables SuppliesDocument9 pagesRisk Assessment of Consumables SuppliesanfiboleNo ratings yet
- Literature Review of Marketing PlanDocument6 pagesLiterature Review of Marketing Planc5nc3whz100% (1)
- Transforming Education in The Digital AgeDocument4 pagesTransforming Education in The Digital AgeAnalyn AgotoNo ratings yet
- SQLPlus Concurrent Program in Oracle AppsDocument5 pagesSQLPlus Concurrent Program in Oracle AppsTikendra Kumar PalNo ratings yet
- UntitledDocument880 pagesUntitledmahdi beheshti100% (1)
- Test and MeasurementDocument23 pagesTest and Measurementcloudprintsph13No ratings yet
- Advanced Isometric Configuration in AutoCADPlant3DDocument49 pagesAdvanced Isometric Configuration in AutoCADPlant3DRoobens SC Lara100% (1)
- ConocoPhilips Addendum To Norsok Z-010Document11 pagesConocoPhilips Addendum To Norsok Z-010XamiPatiNo ratings yet
- Oferta Bodor: Model (E) Pret ( Fara TVA) Garantie Modele CO2Document3 pagesOferta Bodor: Model (E) Pret ( Fara TVA) Garantie Modele CO2Librarie PapetarieNo ratings yet
- Concept-and-Technical-Drawing-RelationshipDocument13 pagesConcept-and-Technical-Drawing-RelationshipcyeishamaekielaNo ratings yet
- Atswa: Study TextDocument479 pagesAtswa: Study TextBrittney JamesNo ratings yet
- Bess-Sm-3q90041-Qams-003 Method of Statement - Cable Termination PDFDocument5 pagesBess-Sm-3q90041-Qams-003 Method of Statement - Cable Termination PDFChristian BulaongNo ratings yet
- Prashant KumarDocument47 pagesPrashant KumarAftab AhmadNo ratings yet
- Chapter 04 - Batch Input MethodsDocument21 pagesChapter 04 - Batch Input MethodsnivasNo ratings yet
- Harmonic Patterns: Guides To Profitable TradingDocument7 pagesHarmonic Patterns: Guides To Profitable TradingalokNo ratings yet
- Data Mining 1-3Document29 pagesData Mining 1-3Singer JerowNo ratings yet
- Definition of Total Quality Management (TQM)Document6 pagesDefinition of Total Quality Management (TQM)Tamizha Tamizha100% (1)
- Mechanical Engineering M.Abdul GhoziDocument4 pagesMechanical Engineering M.Abdul GhoziRizaldy PhoenksNo ratings yet
- Call Letter To Attaend Certificate Verification 190713004943 Guntur Anm Ward Health Secretary (Grade-Iii) PDFDocument2 pagesCall Letter To Attaend Certificate Verification 190713004943 Guntur Anm Ward Health Secretary (Grade-Iii) PDFMahesh sunnyNo ratings yet