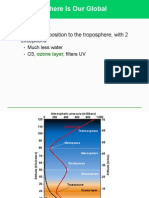
You might also like
- Image Classification - Digital Image ProcessingDocument16 pagesImage Classification - Digital Image ProcessingSharmishtha SarkarNo ratings yet
- Image ProcessingDocument3 pagesImage ProcessingRashmi SharmaNo ratings yet
- An Efficient Approach To Predict Tumor in 2D Brain Image Using Classification TechniquesDocument6 pagesAn Efficient Approach To Predict Tumor in 2D Brain Image Using Classification Techniqueshub23No ratings yet
- Component-I (A) - Personal Details: Supervised ClassificationDocument17 pagesComponent-I (A) - Personal Details: Supervised ClassificationTechZenNo ratings yet
- Feature Extraction and ClassificationDocument15 pagesFeature Extraction and Classificationmak78No ratings yet
- Object Recognition System Design in Computer Vision: A Universal ApproachDocument18 pagesObject Recognition System Design in Computer Vision: A Universal ApproachGlmNo ratings yet
- Medical Image Processing - Detection of Cancer BrainDocument7 pagesMedical Image Processing - Detection of Cancer BrainIntegrated Intelligent ResearchNo ratings yet
- IJETR031551Document6 pagesIJETR031551erpublicationNo ratings yet
- Classification (Unit3)Document11 pagesClassification (Unit3)Bijaya DhamiNo ratings yet
- Dip 13-17Document52 pagesDip 13-17sgrrscNo ratings yet
- Supervised Vs Unsupervised ClassificationDocument2 pagesSupervised Vs Unsupervised ClassificationMario UltimateAddiction HyltonNo ratings yet
- Unit - 3 RS PDFDocument16 pagesUnit - 3 RS PDFSanthosh GivariNo ratings yet
- Image Classification Techniques-A SurveyDocument4 pagesImage Classification Techniques-A SurveyInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Abstract: Instance-Aware Semantic Segmentation For Autonomous VehiclesDocument7 pagesAbstract: Instance-Aware Semantic Segmentation For Autonomous Vehiclesnishant ranaNo ratings yet
- (IJCST-V3I5P35) : P.V Nishana Rasheed, R. ShreejDocument11 pages(IJCST-V3I5P35) : P.V Nishana Rasheed, R. ShreejEighthSenseGroupNo ratings yet
- Digital Image ClassificationDocument53 pagesDigital Image ClassificationClintone OmondiNo ratings yet
- 22-A Survey On Image ClassificationDocument5 pages22-A Survey On Image Classificationdiankusuma123No ratings yet
- Prediction Analysis Techniques of Data Mining: A ReviewDocument7 pagesPrediction Analysis Techniques of Data Mining: A ReviewEdwardNo ratings yet
- DMWH M3Document21 pagesDMWH M3BINESHNo ratings yet
- duttasurajit34gmailcomCLASSIFICATION OF ACCURACY ASSESSMENT2Document8 pagesduttasurajit34gmailcomCLASSIFICATION OF ACCURACY ASSESSMENT2THIRSHATH VNo ratings yet
- Laporan Klasifikasi MultispektralDocument28 pagesLaporan Klasifikasi MultispektralOctavia AzzahrahNo ratings yet
- PR Assignment 01 - Seemal Ajaz (206979)Document7 pagesPR Assignment 01 - Seemal Ajaz (206979)Azka NawazNo ratings yet
- Classification and PredictionDocument41 pagesClassification and Predictionkolluriniteesh111No ratings yet
- Reconnaissance: Supervised Classification Is The Technique Most Often Used For TheDocument5 pagesReconnaissance: Supervised Classification Is The Technique Most Often Used For TheKalsa KatashoNo ratings yet
- For More Visit WWW - Ktunotes.inDocument21 pagesFor More Visit WWW - Ktunotes.inArcha RajanNo ratings yet
- International Journal of Engineering Research and Development (IJERD)Document5 pagesInternational Journal of Engineering Research and Development (IJERD)IJERDNo ratings yet
- Fruit Recognition and Nutrition Measurement ReportDocument12 pagesFruit Recognition and Nutrition Measurement ReportBirinchi MedhiNo ratings yet
- DM Lecture 06Document32 pagesDM Lecture 06Sameer AhmadNo ratings yet
- Image Classification: Supervised ClassificationDocument15 pagesImage Classification: Supervised ClassificationYomif BokuNo ratings yet
- Cluster AnalysisDocument6 pagesCluster AnalysisDeepak BhardwajNo ratings yet
- Overviewof Data Mining Techniques and Image SegmentationDocument5 pagesOverviewof Data Mining Techniques and Image SegmentationIntegrated Intelligent ResearchNo ratings yet
- Guide to Image Processing Techniques for Plant Disease DetectionDocument20 pagesGuide to Image Processing Techniques for Plant Disease DetectionSayantan Banerjee100% (1)
- Breast Cancer Prediction With Evaluating Performance of Elastography Image Using Deep LearningDocument8 pagesBreast Cancer Prediction With Evaluating Performance of Elastography Image Using Deep LearningJayachandran VivekanandanNo ratings yet
- Random Forest Algorithm For Land Cover Classification: Arun D. Kulkarni and Barrett LoweDocument6 pagesRandom Forest Algorithm For Land Cover Classification: Arun D. Kulkarni and Barrett LoweEditor IJRITCCNo ratings yet
- Unit 3Document41 pagesUnit 3Venkatesh SharmaNo ratings yet
- Comparative Analysis of K-Means and Fuzzy C-Means AlgorithmsDocument5 pagesComparative Analysis of K-Means and Fuzzy C-Means AlgorithmsFormat Seorang LegendaNo ratings yet
- Remote Sensing: Improvements in Sample Selection Methods For Image ClassificationDocument12 pagesRemote Sensing: Improvements in Sample Selection Methods For Image ClassificationThales Sehn KörtingNo ratings yet
- Unit 4Document20 pagesUnit 4aknumsn7724No ratings yet
- Klasifikasi Citra: Astuti, Ike SariDocument44 pagesKlasifikasi Citra: Astuti, Ike Sarialya nabilaNo ratings yet
- Geoenrichment and Visualizing Well DataDocument5 pagesGeoenrichment and Visualizing Well DataFatma Zohra OUIRNo ratings yet
- PPAI PaperDocument9 pagesPPAI PaperMOHAMMED HANZLA HUSSAINNo ratings yet
- Land Cover/Land Use Classification Based On Decision Tree ApproachDocument7 pagesLand Cover/Land Use Classification Based On Decision Tree ApproachlambanaveenNo ratings yet
- Lecture 6: Classifying The Terrestrial Environment Using Optical Earth Observed ImagesDocument16 pagesLecture 6: Classifying The Terrestrial Environment Using Optical Earth Observed ImagesJayesh ShindeNo ratings yet
- Visual Categorization With Bags of KeypointsDocument17 pagesVisual Categorization With Bags of Keypoints6688558855No ratings yet
- Image segmentation using histogram analysis and soft thresholdingDocument6 pagesImage segmentation using histogram analysis and soft thresholdingSaeideh OraeiNo ratings yet
- Image Recognition Using CNNDocument12 pagesImage Recognition Using CNNshilpaNo ratings yet
- Multimode Foreground Detection Using Surf Algorithm: Abstract-Video Surveillance Is Active Research Topic inDocument4 pagesMultimode Foreground Detection Using Surf Algorithm: Abstract-Video Surveillance Is Active Research Topic inTechnos_IncNo ratings yet
- AI Unit-5 NotesDocument25 pagesAI Unit-5 NotesRajeev SahaniNo ratings yet
- Genetic Algorithms For Object Recognition IN A: Complex SceneDocument4 pagesGenetic Algorithms For Object Recognition IN A: Complex Scenehvactrg1No ratings yet
- Solutions To DM I MID (A)Document19 pagesSolutions To DM I MID (A)jyothibellaryv100% (1)
- RS & Gis Mse 2Document13 pagesRS & Gis Mse 2MANIRAJ HonnavarkarNo ratings yet
- Clustering the Results of PKL Collection Object Images as Data Mining Learning Digital Libraries Using OrangeDocument5 pagesClustering the Results of PKL Collection Object Images as Data Mining Learning Digital Libraries Using Orangeyucke auliaNo ratings yet
- Knowledge Mining Using Classification Through ClusteringDocument6 pagesKnowledge Mining Using Classification Through ClusteringGaurav GuptaNo ratings yet
- IRMA - Content-Based Image Retrieval in Medical ApplicationsDocument5 pagesIRMA - Content-Based Image Retrieval in Medical ApplicationsPammi KavithaNo ratings yet
- Integrating Image Segmentation and Classification Using Texture Primitives For Natural and Aerial ImagesDocument8 pagesIntegrating Image Segmentation and Classification Using Texture Primitives For Natural and Aerial ImagesInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Paddy Crop Disease Finder Using Probabilistic Approach: P.Tamije Selvy, Kowsalya N, Priyanka KrishnanDocument6 pagesPaddy Crop Disease Finder Using Probabilistic Approach: P.Tamije Selvy, Kowsalya N, Priyanka KrishnanerpublicationNo ratings yet
- ICIP 2005 Tutorial: Presented byDocument55 pagesICIP 2005 Tutorial: Presented byanabikpalNo ratings yet
- Deep Learning Image Segmentation Methods & AppsDocument12 pagesDeep Learning Image Segmentation Methods & AppsHema maliniNo ratings yet
- A Review of Image Classification Approaches and TechniquesDocument6 pagesA Review of Image Classification Approaches and TechniquesArtur JNo ratings yet
- Digital Image ProcessingDocument1 pageDigital Image ProcessingSmitha AsokNo ratings yet
- DIPNotes Formats&FileStructures SADocument4 pagesDIPNotes Formats&FileStructures SASmitha AsokNo ratings yet
- DIPNotes Formats&FileStructures SADocument4 pagesDIPNotes Formats&FileStructures SASmitha AsokNo ratings yet
- DIP Notes-Image Rectification and Enhancement-SADocument4 pagesDIP Notes-Image Rectification and Enhancement-SASmitha AsokNo ratings yet
- Digital Image ProcessingDocument15 pagesDigital Image ProcessingSmitha AsokNo ratings yet
- Ecotourism NotesDocument8 pagesEcotourism NotesSmitha AsokNo ratings yet
- Biotic Factor SmithaDocument20 pagesBiotic Factor SmithaSmitha AsokNo ratings yet
- Dem DTM DSM TinDocument27 pagesDem DTM DSM TinSmitha Asok0% (1)
- Laws of Limiting Factor S1Document5 pagesLaws of Limiting Factor S1Smitha AsokNo ratings yet
- Topographic MapsDocument4 pagesTopographic MapsSmitha AsokNo ratings yet
- Energy Budget Near The Surface of The EarthDocument27 pagesEnergy Budget Near The Surface of The EarthSmitha AsokNo ratings yet
- Environmenta Hazards SaDocument8 pagesEnvironmenta Hazards SaSmitha AsokNo ratings yet
- Earth's Radiation Balance: Insolation, Temperature, and Global DistributionDocument7 pagesEarth's Radiation Balance: Insolation, Temperature, and Global DistributionSmitha AsokNo ratings yet
- Earth Sun Relationship SADocument15 pagesEarth Sun Relationship SASmitha AsokNo ratings yet
- Stress PhysiologyDocument2 pagesStress PhysiologySmitha AsokNo ratings yet
- BiodiversityDocument10 pagesBiodiversitySmitha AsokNo ratings yet
- Airpoll 2Document30 pagesAirpoll 2Smitha AsokNo ratings yet
- Unesco Iiitmk WorkshopDocument2 pagesUnesco Iiitmk WorkshopSmitha AsokNo ratings yet
- EqDocument1 pageEqSmitha AsokNo ratings yet
- Smitha Air PolnDocument25 pagesSmitha Air PolnSmitha AsokNo ratings yet
- Cna Part7Document10 pagesCna Part7AlnZmNo ratings yet
- A Convenient Approach For Penalty Parameter Selection in Robust Lasso RegressionDocument12 pagesA Convenient Approach For Penalty Parameter Selection in Robust Lasso Regressionasfar as-salafiyNo ratings yet
- Humalyzer Primus: Semi-Automatic Microprocessor Controlled PhotometerDocument2 pagesHumalyzer Primus: Semi-Automatic Microprocessor Controlled Photometerali zeidNo ratings yet
- Allison HD4060 Service Manual 4Document1 pageAllison HD4060 Service Manual 4Jasm LiuNo ratings yet
- Sharp NoteVision PGB10SDocument1 pageSharp NoteVision PGB10StmursetNo ratings yet
- Radiance Tutorial 2Document13 pagesRadiance Tutorial 2hoangpalestineNo ratings yet
- The Importance of Additive ManufacturingDocument9 pagesThe Importance of Additive ManufacturingraviNo ratings yet
- Customer Experience Management A Handbook To Acquire and Retain Valuable CustomersDocument10 pagesCustomer Experience Management A Handbook To Acquire and Retain Valuable CustomersFranco Garcia VillenaNo ratings yet
- PPM BluePrintDocument163 pagesPPM BluePrintSanjay Govil67% (3)
- X and y I.e., For Arguments and Entries Values, and Plot The Different Points On The Graph ForDocument4 pagesX and y I.e., For Arguments and Entries Values, and Plot The Different Points On The Graph ForFinanti Puja DwikasihNo ratings yet
- Cmyk 100 66 0 2: Mobile Radio User GuideDocument9 pagesCmyk 100 66 0 2: Mobile Radio User GuideMario Javier GonzalesNo ratings yet
- Chapter 04 - Batch Input MethodsDocument21 pagesChapter 04 - Batch Input MethodsnivasNo ratings yet
- C Data 2Document149 pagesC Data 2Abhijit BarmanNo ratings yet
- NVIDIA Quadro 4000 by PNYDocument1 pageNVIDIA Quadro 4000 by PNYPrues WongNo ratings yet
- KIMBERLY CLARK VIETNAM ERP ImplementationDocument24 pagesKIMBERLY CLARK VIETNAM ERP ImplementationLamTraMy13No ratings yet
- Sokkia DT4 Electronic Theodolite ManualDocument27 pagesSokkia DT4 Electronic Theodolite Manualheri purwokoNo ratings yet
- Aoc XML ConventionsDocument4 pagesAoc XML Conventionsjoseph.mangan1892No ratings yet
- Unit VI 80386DX Signals, Bus Cycles, 80387 CoprocessorDocument26 pagesUnit VI 80386DX Signals, Bus Cycles, 80387 CoprocessorShanti GuruNo ratings yet
- Microprocessors Lecture SlidesDocument30 pagesMicroprocessors Lecture Slidestourist101No ratings yet
- TourismDocument39 pagesTourismDinesh Vashisth D C50% (6)
- A Ransomware Hacker Origin Story PDFDocument47 pagesA Ransomware Hacker Origin Story PDFRupa DeviNo ratings yet
- Pilz-Pss Gm504s Documentation EnglishDocument55 pagesPilz-Pss Gm504s Documentation EnglishLuis angel RamirezNo ratings yet
- 6se3190 0XX87 8BF0 Opm Clear Text Display Siemens ManualDocument76 pages6se3190 0XX87 8BF0 Opm Clear Text Display Siemens Manualyoshdog@gmail.comNo ratings yet
- Majesco Limited: Insurance Tech Company ProfileDocument3 pagesMajesco Limited: Insurance Tech Company ProfileSanjay Kanchan PrajapatNo ratings yet
- Mathematics in The Modern World Chapter 5-Mathematical-SystemDocument26 pagesMathematics in The Modern World Chapter 5-Mathematical-SystemMarc Loui RiveroNo ratings yet
- Faces Flow in JSF 2.2 - Part 1: Basics: For Live Training On JSF 2, Primefaces, or OtherDocument32 pagesFaces Flow in JSF 2.2 - Part 1: Basics: For Live Training On JSF 2, Primefaces, or OtherMarouane AmhidiNo ratings yet
- BMW TIS HandbookDocument3 pagesBMW TIS Handbookandcm0% (1)
- 7.2.3.1.4 Block Waiting Time: ETSI TS 102 221 V17.1.0 (2022-02) 44Document3 pages7.2.3.1.4 Block Waiting Time: ETSI TS 102 221 V17.1.0 (2022-02) 44sdfksd iroroooNo ratings yet
- Manual Octa Switch mk3Document5 pagesManual Octa Switch mk3Phil BrownNo ratings yet
- Connecting To Linux Using PuttyDocument9 pagesConnecting To Linux Using Puttydilip4682794No ratings yet