You might also like
- IC Curve1Document2 pagesIC Curve1pyp_pypNo ratings yet
- Copy of Prak Geolistrik 18 Kel 1Document7 pagesCopy of Prak Geolistrik 18 Kel 1Andri Fatkhul AmriNo ratings yet
- Data Hujan HarianDocument34 pagesData Hujan HarianAgung RubianNo ratings yet
- Nama: Muhammad Rafli Zein NPM 193210113 Pengujian Sumur D: Pressure Buildup Test Data of Well XYZDocument7 pagesNama: Muhammad Rafli Zein NPM 193210113 Pengujian Sumur D: Pressure Buildup Test Data of Well XYZMohammad Rayhan Kim Abdul SalamNo ratings yet
- Reservoir LeakDocument3 pagesReservoir Leakfranzua patrick ricra dueñasNo ratings yet
- 2015 Lesson07 Example 1Document70 pages2015 Lesson07 Example 1abimalainNo ratings yet
- 2.6.5 Liquid Limit - One-Point Cone Penetrometer Method (BS1377: Part 2:1990:4.4)Document2 pages2.6.5 Liquid Limit - One-Point Cone Penetrometer Method (BS1377: Part 2:1990:4.4)Elvis Puma AramayoNo ratings yet
- NopeDocument14 pagesNopeSarah NeoSkyrerNo ratings yet
- Fluid Mechanics Lab 1 Handout-1Document4 pagesFluid Mechanics Lab 1 Handout-1HasanNo ratings yet
- Parte 2Document6 pagesParte 2Diego Alexander Aquino SánchezNo ratings yet
- Dashboard Fugas IMPALA - FJCC 0.3 - 2023Document145 pagesDashboard Fugas IMPALA - FJCC 0.3 - 2023Marco CanoNo ratings yet
- This Study Resource WasDocument6 pagesThis Study Resource WasKimberly Claire AtienzaNo ratings yet
- Book 1Document11 pagesBook 1TahirJabbarNo ratings yet
- Vrijeme Slijetanja T (S) : Masa M (G) 10 1,87 10 1.87 3600 1.87 20 1,27 20 1.27 2025 2.59 50 0,51 50 0.51 900 3.96Document3 pagesVrijeme Slijetanja T (S) : Masa M (G) 10 1,87 10 1.87 3600 1.87 20 1,27 20 1.27 2025 2.59 50 0,51 50 0.51 900 3.96Lukas KristovićNo ratings yet
- Am 2540: Strength of Materials Laboratory: 1.spring Stiffness TestDocument6 pagesAm 2540: Strength of Materials Laboratory: 1.spring Stiffness TestAditya KoutharapuNo ratings yet
- Lesson 2c Decimal To Fractions Worksheet Answer KeyDocument1 pageLesson 2c Decimal To Fractions Worksheet Answer KeyLuke FleriNo ratings yet
- Clase AmbientalDocument4 pagesClase AmbientalLuisa Fernanda Hoyos LorduyNo ratings yet
- Latihan 1Document3 pagesLatihan 119033 Fitria LandasnyNo ratings yet
- Libro1 (Version 1)Document6 pagesLibro1 (Version 1)Yeferson ParraNo ratings yet
- Backup Data Hasil Kerja Tukang Makam Tionghoa Trap SampingDocument2 pagesBackup Data Hasil Kerja Tukang Makam Tionghoa Trap Sampingsiti fatimahNo ratings yet
- Erori Relative de Masura Pentru Tensiune: T T P TDocument4 pagesErori Relative de Masura Pentru Tensiune: T T P TPalade Silviu-MariusNo ratings yet
- Process Capability Study TemplateDocument3 pagesProcess Capability Study Templateapi-3852736100% (4)
- Equivalent Pipe Length Elbow Tee Stop Valve Bore of Pipe MMDocument152 pagesEquivalent Pipe Length Elbow Tee Stop Valve Bore of Pipe MMAwokeNo ratings yet
- Laboratorio 01 EL NUMERO PIDocument4 pagesLaboratorio 01 EL NUMERO PIAnonymous spq6Rc9HCNo ratings yet
- Valoare Maxima Numar Intervale Oi: (Frecventa Obs.)Document3 pagesValoare Maxima Numar Intervale Oi: (Frecventa Obs.)SebastianCosminAlecuNo ratings yet
- UntitledDocument3 pagesUntitledDINI ISLAMI RAHMAWATINo ratings yet
- Ensayo de Penetracion Dinamica Ligera Modificada: DP - 1 Setiembre 2009Document1 pageEnsayo de Penetracion Dinamica Ligera Modificada: DP - 1 Setiembre 2009PabloNo ratings yet
- PhysChemLab Lab3Document3 pagesPhysChemLab Lab3Long NguyenNo ratings yet
- Tong Hop KLDocument28 pagesTong Hop KLHưng ĐặngNo ratings yet
- ISO System of Limits and Fits (Tolerances)Document4 pagesISO System of Limits and Fits (Tolerances)杜文欽No ratings yet
- Carta de Individuales Carta de Rangos MovilesDocument4 pagesCarta de Individuales Carta de Rangos Movilesruben constantitnoNo ratings yet
- Active OMNI Channels: Services SolutionDocument2 pagesActive OMNI Channels: Services SolutionPhayeSoneHeinNo ratings yet
- Power Cable Intern ReportDocument34 pagesPower Cable Intern ReportParteek KansalNo ratings yet
- JB Assignment 4Document8 pagesJB Assignment 4Simran Radheshyam SoniNo ratings yet
- Libro 1Document2 pagesLibro 1ulisesNo ratings yet
- 3 Peluqueros FormulasDocument8 pages3 Peluqueros FormulasAraceli PerezNo ratings yet
- Daffa Amara Dzikri - 0101518004 - MonteCarloDocument6 pagesDaffa Amara Dzikri - 0101518004 - MonteCarloDaffa Amara DzikriNo ratings yet
- Phys 131 Ex1Document5 pagesPhys 131 Ex1raindashy2No ratings yet
- Injection Table (CITY)Document1 pageInjection Table (CITY)Hasilwan ChanNo ratings yet
- Gr8am (Autoguardado)Document23 pagesGr8am (Autoguardado)Yarledis judith Moreno MezaNo ratings yet
- PLTB CDocument31 pagesPLTB CShijo AntonyNo ratings yet
- Lecture 4 - Simulation of A Queuing ProblemDocument13 pagesLecture 4 - Simulation of A Queuing ProblemMihlaliNo ratings yet
- Acknowledgement For Summer Internship Project ReportDocument23 pagesAcknowledgement For Summer Internship Project ReportBadisa NaveenNo ratings yet
- 3 2Document2 pages3 2Mustafa Al-GhoulNo ratings yet
- Opration Management TAMDocument5 pagesOpration Management TAMHK 'sNo ratings yet
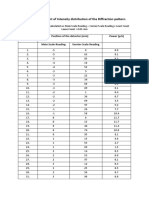
- (A) Measurement of Intensity Distribution of The Diffraction PatternDocument2 pages(A) Measurement of Intensity Distribution of The Diffraction PatternBhupesh YadavNo ratings yet
- LM4 - Galih Rahadian A - 205090707111007Document4 pagesLM4 - Galih Rahadian A - 205090707111007Galih Rahadian AnandyaNo ratings yet
- 3 - Drilled ShaftDocument58 pages3 - Drilled ShaftTalis BattleNo ratings yet
- Fitting Infiltration Models Data Using The Ms. ExcelDocument12 pagesFitting Infiltration Models Data Using The Ms. ExcelDESIREE VICENTENo ratings yet
- 23cem3r13 Time - Headway ExlDocument8 pages23cem3r13 Time - Headway Exlbn23cem3r15No ratings yet
- Absheron Cdfw-Feb06-2017Document13 pagesAbsheron Cdfw-Feb06-2017Seymur AkbarovNo ratings yet
- Executive Summary: Oracle SQL Developer MigrationsDocument19 pagesExecutive Summary: Oracle SQL Developer MigrationsmtaburNo ratings yet
- Din 976-1 1995Document6 pagesDin 976-1 1995Charmaine DrafkeNo ratings yet
- P ColigativasDocument3 pagesP ColigativasEmmanuel BonillaNo ratings yet
- NPS, Pipe Schedule Outside Diameter, KG / M Vol. / MDocument8 pagesNPS, Pipe Schedule Outside Diameter, KG / M Vol. / MnazimNo ratings yet
- Datasets For Research and Development COVID-19 Datasets For Research and DevelopmentDocument6 pagesDatasets For Research and Development COVID-19 Datasets For Research and DevelopmentAsmatullah KhanNo ratings yet
- Pg068 - T11 Conductor ResistanceDocument1 pagePg068 - T11 Conductor ResistanceDolyNo ratings yet
- VertederoDocument4 pagesVertederoIván VargasNo ratings yet
- FORM A. Sensus Harian Indikator MutuDocument12 pagesFORM A. Sensus Harian Indikator MutuNurul IsnaeniNo ratings yet
- Math Practice Simplified: Decimals & Percents (Book H): Practicing the Concepts of Decimals and PercentagesFrom EverandMath Practice Simplified: Decimals & Percents (Book H): Practicing the Concepts of Decimals and PercentagesRating: 5 out of 5 stars5/5 (3)
- isom3031 功課5 第4,5,6題 (update)Document13 pagesisom3031 功課5 第4,5,6題 (update)mak wangNo ratings yet
- Medical Gas System Applied for Hospital in Hong Kong (已自動回復)Document9 pagesMedical Gas System Applied for Hospital in Hong Kong (已自動回復)mak wangNo ratings yet
- About The Film Capitães de Abril, Questions (Assignment Quiz 2)Document2 pagesAbout The Film Capitães de Abril, Questions (Assignment Quiz 2)mak wangNo ratings yet
- Slides 6 - Risk ManagementDocument24 pagesSlides 6 - Risk Managementmak wangNo ratings yet
- Heteroscedasticity:: Testing and Correcting in SPSSDocument32 pagesHeteroscedasticity:: Testing and Correcting in SPSSaziz haqNo ratings yet
- Homework 1 - Simple Linear Regression - Neal PaniaDocument4 pagesHomework 1 - Simple Linear Regression - Neal PaniaJohn SmithNo ratings yet
- AP Stats ChaptersDocument46 pagesAP Stats ChaptersNatural Spring WaterNo ratings yet
- Stock Price Predictions Using A Geometric Brownian Motion - Joel LidénDocument41 pagesStock Price Predictions Using A Geometric Brownian Motion - Joel LidénMaxNo ratings yet
- The SunGard APT Risk Management SystemDocument6 pagesThe SunGard APT Risk Management SystemFabio PolpettiniNo ratings yet
- People Living in Ageing Buildings Their Quality of Life and Sense of BelongingDocument14 pagesPeople Living in Ageing Buildings Their Quality of Life and Sense of BelongingMilan VeljkovicNo ratings yet
- CW Model Calibration ProcedureDocument35 pagesCW Model Calibration ProcedureVineet KumarNo ratings yet
- Multiple Regression Assignment - No Home SalesDocument8 pagesMultiple Regression Assignment - No Home SalesAhad SultanNo ratings yet
- Time Series Analysis and Its Applications CodeDocument23 pagesTime Series Analysis and Its Applications Codevtt20121981100% (2)
- Influence of Entrepreneurial Characteristics On Business Performance of SMES in Osun StateDocument7 pagesInfluence of Entrepreneurial Characteristics On Business Performance of SMES in Osun StateInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Minitab Statguide Time SeriesDocument72 pagesMinitab Statguide Time SeriesSuraj singhNo ratings yet
- Module 5Document28 pagesModule 5Eugene James Gonzales PalmesNo ratings yet
- Chapter 10. Simple Regression and CorrelationDocument34 pagesChapter 10. Simple Regression and CorrelationchingyhoNo ratings yet
- Ole Rummel 4 Feb State Space Models and The KF ErciseDocument57 pagesOle Rummel 4 Feb State Space Models and The KF ErciseBrian GorstNo ratings yet
- Annotated Output Complete Annotated Output Documents SASDocument29 pagesAnnotated Output Complete Annotated Output Documents SASAnonymous lQKm8bmYNo ratings yet
- Car Price PredictionDocument67 pagesCar Price PredictionKrishnapradeepNo ratings yet
- Gil Alana2010Document21 pagesGil Alana2010DANY CREATIONSNo ratings yet
- Forecasting IntroductionDocument29 pagesForecasting IntroductionRajan ManchandaNo ratings yet
- Econometric Exam 2 Flashcards - QuizletDocument18 pagesEconometric Exam 2 Flashcards - QuizletMaham Nadir MinhasNo ratings yet
- Introduction To ANOVADocument11 pagesIntroduction To ANOVAFernando Josafath AñorveNo ratings yet
- Financial Time Series ModelsDocument11 pagesFinancial Time Series ModelsAbdi HiirNo ratings yet
- Principles of Econometrics 4th Edition Hill Solutions ManualDocument34 pagesPrinciples of Econometrics 4th Edition Hill Solutions Manualcourtneyriceacnmbxqiky100% (13)
- Machine Learning Activity-Based Costing: Conceptual TestDocument45 pagesMachine Learning Activity-Based Costing: Conceptual Testhasan najiNo ratings yet
- An Analysis On The Demand For Rice in THDocument57 pagesAn Analysis On The Demand For Rice in THDex LicongNo ratings yet
- Mufita2016 Sas LogDocument2 pagesMufita2016 Sas LogmuffitaraniNo ratings yet
- Regression in Data MiningDocument15 pagesRegression in Data MiningpoonamNo ratings yet
- Statistical Analysis - An Overview IntroductionDocument57 pagesStatistical Analysis - An Overview IntroductionRajeev SharmaNo ratings yet
- Homework AnswersDocument7 pagesHomework AnswersRamsha SohailNo ratings yet
- Chi Square HipotesisDocument6 pagesChi Square HipotesisTimothy JordanNo ratings yet
- QBM101Document37 pagesQBM101Shang BinNo ratings yet