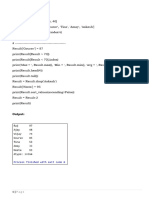
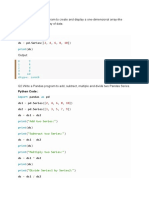
You might also like
- Pandas Library Problems For ParcticeDocument13 pagesPandas Library Problems For ParcticeMAXI 32No ratings yet
- PracticalDocument28 pagesPracticalDhruti PatelNo ratings yet
- Assignment # 3Document8 pagesAssignment # 3Bushi BaloochNo ratings yet
- Assignment-1 (Python Pandas-Series Object and Data Frame: 1. Answer The FollowingDocument8 pagesAssignment-1 (Python Pandas-Series Object and Data Frame: 1. Answer The FollowingVaishnavi KesarwaniNo ratings yet
- Only PandasDocument8 pagesOnly PandasJyotirmay SahuNo ratings yet
- Tuple ProgramsDocument6 pagesTuple Programsganavisp0505No ratings yet
- DataFrame 2Document38 pagesDataFrame 2rohan jhaNo ratings yet
- DMT FunctionDocument10 pagesDMT FunctionMuhammad SalmanNo ratings yet
- Python BasicsDocument15 pagesPython BasicsGirraj DohareNo ratings yet
- 2 Pandas Basics Practice 2 PDFDocument1 page2 Pandas Basics Practice 2 PDFShubham TagalpallewarNo ratings yet
- Python ProgramsDocument9 pagesPython ProgramsHarsh Pawar100% (1)
- Python GTU Study Material E-Notes 3 16012021061619AMDocument36 pagesPython GTU Study Material E-Notes 3 16012021061619AMZainab KhatriNo ratings yet
- Python Rat La Co Ban - Vo Duy Tuan 2Document92 pagesPython Rat La Co Ban - Vo Duy Tuan 2ThangPhanNo ratings yet
- Pandas & MysqlDocument20 pagesPandas & MysqlSahil AhmadNo ratings yet
- Journal 12Document54 pagesJournal 12Be xNo ratings yet
- IP - Pandas 1 & 2 (Worksheet) Class 12Document16 pagesIP - Pandas 1 & 2 (Worksheet) Class 12WhiteNo ratings yet
- Lab 8Document9 pagesLab 8358PRAKHAR DUBEYNo ratings yet
- Unit-03: Capturing, Preparing and Working With DataDocument41 pagesUnit-03: Capturing, Preparing and Working With DataMubaraka KundawalaNo ratings yet
- Worksheet of PracticalDocument6 pagesWorksheet of PracticalIndu GoyalNo ratings yet
- Python PracticalsDocument26 pagesPython Practicalsvenkat krishnanNo ratings yet
- Info Programs QuestionsDocument18 pagesInfo Programs QuestionspatNo ratings yet
- Assignment 61Document4 pagesAssignment 61deepakkashya100% (2)
- PANDASDocument74 pagesPANDASyomikay302No ratings yet
- SLK Software Python Interview QuestionsDocument4 pagesSLK Software Python Interview QuestionsSrinimfNo ratings yet
- Dictionary: Dict ('Name': 'Geeks', 1: (1, 2, 3, 4) )Document14 pagesDictionary: Dict ('Name': 'Geeks', 1: (1, 2, 3, 4) )ahmedNo ratings yet
- Ip-12-2023-24 Practical FileDocument19 pagesIp-12-2023-24 Practical FilekashinathchandakNo ratings yet
- Practical File: School Name School LogoDocument35 pagesPractical File: School Name School Logovinayak chandra100% (1)
- Worksheet - PandasDocument16 pagesWorksheet - PandasDrishtiNo ratings yet
- Int-215-Ca-2: Numpy NPDocument5 pagesInt-215-Ca-2: Numpy NPSHASANKNo ratings yet
- I.P. PracticalDocument31 pagesI.P. PracticalAyushi BishtNo ratings yet
- Answers Practical FileDocument19 pagesAnswers Practical Filesinghaladitya006No ratings yet
- Cheat Sheet: The Pandas Dataframe Object: Preliminaries Get Your Data Into A DataframeDocument10 pagesCheat Sheet: The Pandas Dataframe Object: Preliminaries Get Your Data Into A DataframeRaju Rimal100% (1)
- PandaDocument33 pagesPandakrNo ratings yet
- PandasDocument82 pagesPandasaacharyadhruv1310No ratings yet
- Practical File Class - Xii Informatics Practices (New) : 1. How To Create A Series From A List, Numpy Array and Dict?Document17 pagesPractical File Class - Xii Informatics Practices (New) : 1. How To Create A Series From A List, Numpy Array and Dict?AHMED NAEEM 2No ratings yet
- Practical List IpDocument10 pagesPractical List IpRaj aditya Shrivastava100% (1)
- Algo LearningDocument3 pagesAlgo Learningkarthi maniNo ratings yet
- Subset Selection Class AssignmentDocument5 pagesSubset Selection Class AssignmentAashu NemaNo ratings yet
- Outliers, Hypothesis and Natural Language ProcessingDocument7 pagesOutliers, Hypothesis and Natural Language Processingsubhajitbasak001100% (1)
- Artificial Intelligence LabDocument35 pagesArtificial Intelligence LabMaria NeyveliNo ratings yet
- Exercise 7 - PandasDocument2 pagesExercise 7 - PandasPawan GosaviNo ratings yet
- Make A 5 Example On The Pandas Library: AnswerDocument2 pagesMake A 5 Example On The Pandas Library: AnswerChristineJoy LaurianNo ratings yet
- Sheet 5 PandasDocument13 pagesSheet 5 PandasIrene GabrielNo ratings yet
- Python BuiltInListDocument4 pagesPython BuiltInListroy.scar2196No ratings yet
- Python BuiltInListDocument4 pagesPython BuiltInListroy.scar2196No ratings yet
- Practical File PythonDocument25 pagesPractical File Pythonkaizenpro01No ratings yet
- Data Science With PythonDocument12 pagesData Science With PythonMugdho HossainNo ratings yet
- Pandas Questions Ip FileDocument13 pagesPandas Questions Ip FileAISHI SHARMANo ratings yet
- Saish IP ProjectDocument16 pagesSaish IP ProjectSaish ParkarNo ratings yet
- CurveDocument2 pagesCurveAntonio FernandezNo ratings yet
- Python Lab Working CodeDocument35 pagesPython Lab Working CodeViolet MarsNo ratings yet
- Experiment No 6 PythonDocument14 pagesExperiment No 6 PythonShubham PalavNo ratings yet
- Experiment 5 To 8Document2 pagesExperiment 5 To 8pandikumar.sNo ratings yet
- Fdspracticals - Ipynb - ColaboratoryDocument21 pagesFdspracticals - Ipynb - Colaboratorycc76747321No ratings yet
- Nadya Faudilla - 1806198471 - Geologi Komputasi 5 Dan 6 - Jupyter NotebookDocument9 pagesNadya Faudilla - 1806198471 - Geologi Komputasi 5 Dan 6 - Jupyter NotebookEmir RakhimNo ratings yet
- Pandas Practicals - Term-1Document18 pagesPandas Practicals - Term-1Rudra DewanganNo ratings yet
- Pandasmatplotlib Practical FileDocument15 pagesPandasmatplotlib Practical FilegodayushshrivastavaNo ratings yet
- Practical File Part 1Document17 pagesPractical File Part 1Om Rane XII CNo ratings yet
- Jamir, Dewan R. EMGT Field Project Part 1Document116 pagesJamir, Dewan R. EMGT Field Project Part 1fucker66No ratings yet
- Literature ReviewDocument3 pagesLiterature ReviewAina Reyes100% (1)
- Dividing Fractions : and What It MeansDocument22 pagesDividing Fractions : and What It MeansFlors BorneaNo ratings yet
- Kantha Embroidery by Nanduri Asha, Shreya Gulati, Saloni PriyaDocument17 pagesKantha Embroidery by Nanduri Asha, Shreya Gulati, Saloni PriyaShreyaa Gulati100% (3)
- 4.5.redistrribution - PBR Quiz AnswersDocument4 pages4.5.redistrribution - PBR Quiz AnswersffbugbuggerNo ratings yet
- 2019 MIPS Quality Historic BenchmarksDocument158 pages2019 MIPS Quality Historic BenchmarksJoe GellatlyNo ratings yet
- Bergeron Et Al 2023 Use of Invasive Brain Computer Interfaces in Pediatric Neurosurgery Technical and EthicalDocument16 pagesBergeron Et Al 2023 Use of Invasive Brain Computer Interfaces in Pediatric Neurosurgery Technical and EthicalPriscilla MelindaNo ratings yet
- 09.3090 USTR2433b T Series Cassettes Omega IFU enDocument51 pages09.3090 USTR2433b T Series Cassettes Omega IFU enAdi SaputraNo ratings yet
- Digital DividesDocument25 pagesDigital DividesKumaraswamy ChannabasaiahNo ratings yet
- Grade 11 Learning GuideDocument28 pagesGrade 11 Learning GuideMary-Rose Casuyon100% (1)
- Class 12 Psychology PDFDocument209 pagesClass 12 Psychology PDFSoumyashis Bhattacharya0% (1)
- Homework 3rd SteelDocument4 pagesHomework 3rd SteelPiseth HengNo ratings yet
- Bruce Lyon - Occult CosmologyDocument55 pagesBruce Lyon - Occult Cosmologyeponymos100% (1)
- By Beholding We Are ChangedDocument2 pagesBy Beholding We Are ChangedAdrian EbensNo ratings yet
- Cross Border Pack 2 SumDocument35 pagesCross Border Pack 2 SumYến Như100% (1)
- Aeration PaperDocument11 pagesAeration PapersehonoNo ratings yet
- Research Article: International Research Journal of PharmacyDocument5 pagesResearch Article: International Research Journal of PharmacyAlfrets Marade SianiparNo ratings yet
- 3rd Quarter PHYSICAL SCIENCE ExamDocument19 pages3rd Quarter PHYSICAL SCIENCE ExamZhering RodulfoNo ratings yet
- Exam of Refinery PDF 2Document20 pagesExam of Refinery PDF 2ئارام ناصح محمد حسێن0% (1)
- Operating Manual For Kipor Mobile Gic-Pg Kipor Quick Guide OmDocument8 pagesOperating Manual For Kipor Mobile Gic-Pg Kipor Quick Guide OmIan CutinNo ratings yet
- LEED v4 For Interior Design and Construction ChecklistDocument3 pagesLEED v4 For Interior Design and Construction Checklisttarek.abbas8598No ratings yet
- b0700sv F PDFDocument188 pagesb0700sv F PDFabdel taibNo ratings yet
- Module 1 - AE4 - Review of Basic Mathematical Concepts (For Discussion)Document36 pagesModule 1 - AE4 - Review of Basic Mathematical Concepts (For Discussion)Kimberly Jean LautrizoNo ratings yet
- Hostel B Menu From 16 March To 31 March'2024Document4 pagesHostel B Menu From 16 March To 31 March'2024govindkauNo ratings yet
- Project Sanjay YadavDocument51 pagesProject Sanjay YadavriyacomputerNo ratings yet
- Essay Flooding and MitigationDocument3 pagesEssay Flooding and MitigationCindy HosianiNo ratings yet
- TDC Calculation For The Determination of Drill Bit PerformanceDocument3 pagesTDC Calculation For The Determination of Drill Bit Performancejanuar baharuliNo ratings yet
- Ground Investigation ReportDocument49 pagesGround Investigation Reportjoemacx6624No ratings yet
- Astm E1975 - 1 (En)Document17 pagesAstm E1975 - 1 (En)Dinesh Sai100% (1)
- Essential Oil ExtractionDocument159 pagesEssential Oil ExtractionAubrey Hernandez100% (4)