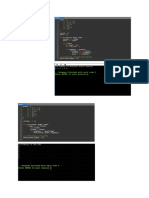
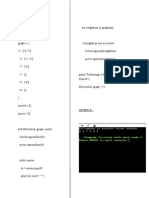
You might also like
- Zerotohero Python3 170809030243Document96 pagesZerotohero Python3 170809030243Kiran KumarNo ratings yet
- Flower Power VW Van Pillow: Patterns By: Deborah Bagley, Dana Bincer &Document5 pagesFlower Power VW Van Pillow: Patterns By: Deborah Bagley, Dana Bincer &Rodica Nicolau75% (4)
- Lufthansa Technical Training Troubleshooting Fundamentals CourseDocument160 pagesLufthansa Technical Training Troubleshooting Fundamentals CourseBELISARIONo ratings yet
- Learn Python: Why, What, and How with ExamplesDocument21 pagesLearn Python: Why, What, and How with ExamplesShivali Rishi100% (1)
- Women’s Christian College Python Programming WebinarDocument96 pagesWomen’s Christian College Python Programming WebinarRajaNo ratings yet
- PythonDocument77 pagesPythonahmed_sftNo ratings yet
- NumPy Matplotlib Data Visualization with PythonDocument22 pagesNumPy Matplotlib Data Visualization with PythonShailendra SapkotaNo ratings yet
- Top 50 Python Interview Question and Answers Powered by ©Document12 pagesTop 50 Python Interview Question and Answers Powered by ©Khadija LasriNo ratings yet
- Python Data StructuresDocument178 pagesPython Data Structuresdasoundofreason1065No ratings yet
- Definition of Total Quality Management (TQM)Document6 pagesDefinition of Total Quality Management (TQM)Tamizha Tamizha100% (1)
- Standard Operating ProcedureDocument39 pagesStandard Operating ProcedureAndrew Charles0% (1)
- Python For Data Analysis: Dr. Kishore KunalDocument43 pagesPython For Data Analysis: Dr. Kishore KunalShivangi Gupta100% (1)
- Python Numpy Pandas Interview QuestionsDocument8 pagesPython Numpy Pandas Interview QuestionsKinjal GoswamiNo ratings yet
- A Python Data Analyst’s Toolkit: Learn Python and Python-based Libraries with Applications in Data Analysis and StatisticsFrom EverandA Python Data Analyst’s Toolkit: Learn Python and Python-based Libraries with Applications in Data Analysis and StatisticsNo ratings yet
- ML Lab FileDocument53 pagesML Lab Fileshashank3256No ratings yet
- Entrepreneurship Pre-Test: Kyle's Typing Business ExpandsDocument3 pagesEntrepreneurship Pre-Test: Kyle's Typing Business ExpandsMutya Neri Cruz100% (1)
- Data TypeDocument10 pagesData TypeMir Yamin Uddin ZidanNo ratings yet
- Visualizing Random Forest Performance in TableauDocument6 pagesVisualizing Random Forest Performance in TableauAnurag SinghNo ratings yet
- Ass-1 pracDocument23 pagesAss-1 pracVedant AndhaleNo ratings yet
- Viva Questions For Python LabDocument9 pagesViva Questions For Python Labsweethaa harinishriNo ratings yet
- Q.1 What Is Numpy?: Creating A Dataframe Using ListDocument4 pagesQ.1 What Is Numpy?: Creating A Dataframe Using ListVills GondaliyaNo ratings yet
- Python 101: Understanding The Nuts and Bolts of PythonDocument46 pagesPython 101: Understanding The Nuts and Bolts of PythonKinnata NikkoNo ratings yet
- python notesDocument15 pagespython notesKoushal YadavNo ratings yet
- Python Intro to Data AnalysisDocument34 pagesPython Intro to Data AnalysisGargi Jana100% (1)
- Basic PythonDocument40 pagesBasic Python20021382 Phạm Công LânNo ratings yet
- Comprehensive Guide Data Exploration Sas Using Python Numpy Scipy Matplotlib PandasDocument12 pagesComprehensive Guide Data Exploration Sas Using Python Numpy Scipy Matplotlib PandasAhsan Ahmad Beg100% (1)
- DSBDA lab manualDocument155 pagesDSBDA lab manualharsh.sb03No ratings yet
- Cs3361 Data Science LaboratoryDocument139 pagesCs3361 Data Science LaboratorykarthickamsecNo ratings yet
- InternshipDocument31 pagesInternshipsuji myneediNo ratings yet
- Daniela Andrea Fuentes Carillo - Cheat SheetDocument16 pagesDaniela Andrea Fuentes Carillo - Cheat SheetScarlet Sofia Colmenares VargasNo ratings yet
- Unit 5Document11 pagesUnit 5SwastikNo ratings yet
- Python AnswersDocument33 pagesPython AnswersSHUBHAN SNo ratings yet
- Py-6 HimDocument7 pagesPy-6 HimHimanshu SNo ratings yet
- DM FileDocument22 pagesDM FileCSD70 Vinay SelwalNo ratings yet
- DSBDA Lab ManualDocument155 pagesDSBDA Lab ManualNeha KardileNo ratings yet
- Programming Notes (Pythun) Chapter WiseDocument41 pagesProgramming Notes (Pythun) Chapter Wisemuhammad afzzalNo ratings yet
- Python DataStructure QuestionDocument12 pagesPython DataStructure QuestionAarav HarithasNo ratings yet
- Datatypes - Ipynb - ColaboratoryDocument15 pagesDatatypes - Ipynb - ColaboratorykoyalNo ratings yet
- Esc Enter M Y A B D + D Z F Shift + Up/Down Space Shift + SpaceDocument12 pagesEsc Enter M Y A B D + D Z F Shift + Up/Down Space Shift + SpacekishoremokkaNo ratings yet
- Sma Exp 4Document3 pagesSma Exp 4pameluftNo ratings yet
- 19cs2205a KeyDocument8 pages19cs2205a KeySuryateja KokaNo ratings yet
- Python Solve CAT2Document17 pagesPython Solve CAT2Er Sachin ShandilyaNo ratings yet
- Variables, Data Types and Keywords in PythonDocument8 pagesVariables, Data Types and Keywords in Pythonahmedshifa59No ratings yet
- Python CCE - II by Atul Sadiwal?Document7 pagesPython CCE - II by Atul Sadiwal?Harsha ChoudharyNo ratings yet
- AWP Interview QuestionDocument4 pagesAWP Interview Questionpratikmovie999No ratings yet
- Python Viva Q-ANSDocument8 pagesPython Viva Q-ANSMit ShahNo ratings yet
- Python DocumentDocument25 pagesPython DocumentEAIESBNo ratings yet
- Histogram and QunatilesDocument12 pagesHistogram and QunatilesVipul PartapNo ratings yet
- 15 Essential Data Structure and AlgorithmDocument8 pages15 Essential Data Structure and Algorithmjikhlin23No ratings yet
- Robocoupler ReportDocument9 pagesRobocoupler ReportPavan KumarNo ratings yet
- Unit 5 PythonDocument10 pagesUnit 5 PythonVikas PareekNo ratings yet
- DSBDL Write Ups 8 To 10Document7 pagesDSBDL Write Ups 8 To 10sdaradeytNo ratings yet
- Numpyand PandasDocument9 pagesNumpyand PandasHansraj KumarNo ratings yet
- Chapter7 PDFDocument31 pagesChapter7 PDFZADOD YASSINENo ratings yet
- Python Objects and DatastructureDocument30 pagesPython Objects and Datastructuretokedeg243No ratings yet
- Python For Data AnalysisDocument96 pagesPython For Data AnalysisFarheen NawaziNo ratings yet
- Python Interview Q A 1709697988Document26 pagesPython Interview Q A 1709697988Suman SaurabhNo ratings yet
- Assignment 2 Data TypesDocument6 pagesAssignment 2 Data TypesSajjad Ali SagErNo ratings yet
- Python Programming NotesDocument76 pagesPython Programming NotesJayyant ChaudhariNo ratings yet
- Computer Science Holiday HomeworkDocument7 pagesComputer Science Holiday HomeworkAnsh VohraNo ratings yet
- Lesson 3Document54 pagesLesson 3Ken_nerveNo ratings yet
- D P Lab ManualDocument54 pagesD P Lab Manualsanketwakde100No ratings yet
- Python fRRADocument12 pagesPython fRRAVishal TarwatkarNo ratings yet
- 03-Data AnalysisDocument18 pages03-Data AnalysisDebashish DekaNo ratings yet
- PYTHON DATA SCIENCE FOR BEGINNERS: Unlock the Power of Data Science with Python and Start Your Journey as a Beginner (2023 Crash Course)From EverandPYTHON DATA SCIENCE FOR BEGINNERS: Unlock the Power of Data Science with Python and Start Your Journey as a Beginner (2023 Crash Course)No ratings yet
- CG Lab Assignment Part 2Document2 pagesCG Lab Assignment Part 2Parth IsasareNo ratings yet
- Assignment No 1 - ADocument5 pagesAssignment No 1 - AParth IsasareNo ratings yet
- Inputt OutpuyyDocument5 pagesInputt OutpuyyParth IsasareNo ratings yet
- Computer Networks & SecurityDocument528 pagesComputer Networks & SecurityParth IsasareNo ratings yet
- Input of AIDocument7 pagesInput of AIParth IsasareNo ratings yet
- P 11.4A Pressurization System InspectionDocument3 pagesP 11.4A Pressurization System Inspectioncrye shotNo ratings yet
- Mohd Aiman Saleem Java RecordDocument59 pagesMohd Aiman Saleem Java RecordHemanth NaikNo ratings yet
- B. Tech-in-Computer-Science-and-Engineering-Data-Science-Thir-Year-2023-24Document73 pagesB. Tech-in-Computer-Science-and-Engineering-Data-Science-Thir-Year-2023-24Sushant5inghrajputNo ratings yet
- SQLPlus Concurrent Program in Oracle AppsDocument5 pagesSQLPlus Concurrent Program in Oracle AppsTikendra Kumar PalNo ratings yet
- Luanshya Technical College SCADA Scan IntervalDocument5 pagesLuanshya Technical College SCADA Scan IntervalAlfred K ChilufyaNo ratings yet
- Dvr-100G-F1 Turbo HD DVR: Key FeatureDocument4 pagesDvr-100G-F1 Turbo HD DVR: Key FeatureEsmailNo ratings yet
- Jadenlimkaijie w1Document4 pagesJadenlimkaijie w1api-518329636No ratings yet
- What is an Operating SystemDocument46 pagesWhat is an Operating SystemomviskarNo ratings yet
- Sharepoint Job ProfileDocument2 pagesSharepoint Job ProfilePrasad KshirsagarNo ratings yet
- Redwan Ahmed Miazee - HW - 1Document3 pagesRedwan Ahmed Miazee - HW - 1REDWAN AHMED MIAZEENo ratings yet
- Striker CM500 1350mm Mobile Cone CrusherDocument2 pagesStriker CM500 1350mm Mobile Cone CrusherBenjamin MurphyNo ratings yet
- M I M Nafrees QSDocument2 pagesM I M Nafrees QSnafreesmimNo ratings yet
- Annex E - Financial Offer Form - FinalDocument3 pagesAnnex E - Financial Offer Form - FinalMerito MhlangaNo ratings yet
- CRD - c48 CRD-C48-92 Standard Test Method For Water Permeability of ConcreteDocument4 pagesCRD - c48 CRD-C48-92 Standard Test Method For Water Permeability of ConcreteazharbNo ratings yet
- ZXUN USPP Load BalancingDocument69 pagesZXUN USPP Load BalancingTawhid AlamNo ratings yet
- Ip Half Yearly Exam 1 - 2022Document7 pagesIp Half Yearly Exam 1 - 2022Ayushmaan MaithaniNo ratings yet
- Guidelines For Safety in E O T Cranes: IPSS: 2-02-007-18 (First Revision)Document4 pagesGuidelines For Safety in E O T Cranes: IPSS: 2-02-007-18 (First Revision)Mohammad Safdar SadatNo ratings yet
- Java Basics - Key Elements of a Java ProgramDocument21 pagesJava Basics - Key Elements of a Java ProgramAsh LeeNo ratings yet
- HEC HMS - User's - Manual v4.11 20231018Document1,039 pagesHEC HMS - User's - Manual v4.11 20231018carmona.eitNo ratings yet
- CIO 100 2011 - Google Apps For Business-Keval Shah-SumariaDocument9 pagesCIO 100 2011 - Google Apps For Business-Keval Shah-SumariaCIOEastAfricaNo ratings yet
- 6 Axis Breakout Board Wiring and SetupDocument5 pages6 Axis Breakout Board Wiring and SetupJalaj ChhalotreNo ratings yet
- E176 PDFDocument20 pagesE176 PDFAhmad Zubair RasulyNo ratings yet
- CT18 Spare Part Book Without EngineDocument86 pagesCT18 Spare Part Book Without EngineTSPSRL Import ExportNo ratings yet
- Even 1819 Result - Results at IET LucknowDocument1 pageEven 1819 Result - Results at IET LucknowDurgesh MauryaNo ratings yet
- Product BrochureDocument19 pagesProduct BrochureMohamed ChahmiNo ratings yet