You might also like
- HADOOP and PYTHON For BEGINNERS - 2 BOOKS in 1 - Learn Coding Fast! HADOOP and PYTHON Crash Course, A QuickStart Guide, Tutorial Book by Program Examples, in Easy Steps!Document89 pagesHADOOP and PYTHON For BEGINNERS - 2 BOOKS in 1 - Learn Coding Fast! HADOOP and PYTHON Crash Course, A QuickStart Guide, Tutorial Book by Program Examples, in Easy Steps!Antony George SahayarajNo ratings yet
- Microsoft Ms-Dos 1.25 (CDP Oem r2.11)Document196 pagesMicrosoft Ms-Dos 1.25 (CDP Oem r2.11)TheBluestoneGuyNo ratings yet
- Gate Os 2 2017Document50 pagesGate Os 2 2017basualok@rediffmail.comNo ratings yet
- Hadoop Ecosystem - GeeksforGeeksDocument7 pagesHadoop Ecosystem - GeeksforGeeksAkhiNo ratings yet
- Testing Big Data: Camelia RadDocument31 pagesTesting Big Data: Camelia RadCamelia Valentina StanciuNo ratings yet
- Network Design and ManagementDocument4 pagesNetwork Design and ManagementJhe MaejanNo ratings yet
- Big Data AnalyticsDocument12 pagesBig Data AnalyticsGautam PrajapatiNo ratings yet
- Hadoop Ecosystem PDFDocument6 pagesHadoop Ecosystem PDFKittuNo ratings yet
- Chapter - 2 HadoopDocument32 pagesChapter - 2 HadoopRahul PawarNo ratings yet
- Big Data Ana Unit - II Part - II (Hadoop Architecture)Document47 pagesBig Data Ana Unit - II Part - II (Hadoop Architecture)Mokshada YadavNo ratings yet
- High Performance Fault-Tolerant Hadoop Distributed File SystemDocument9 pagesHigh Performance Fault-Tolerant Hadoop Distributed File SystemEditor IJRITCCNo ratings yet
- What Is Hadoop Distributed File System (HDFS) PDFDocument3 pagesWhat Is Hadoop Distributed File System (HDFS) PDFMario SoaresNo ratings yet
- Big Data Analytics Unit-3Document15 pagesBig Data Analytics Unit-34241 DAYANA SRI VARSHANo ratings yet
- BDA Unit 3Document6 pagesBDA Unit 3SpNo ratings yet
- Haddob Lab ReportDocument12 pagesHaddob Lab ReportMagneto Eric Apollyon ThornNo ratings yet
- BDA Module 2 Chapter 1Document12 pagesBDA Module 2 Chapter 1Prathibha RangaswamyNo ratings yet
- HadoopDocument11 pagesHadoopInu KagNo ratings yet
- 02 Unit-II Hadoop Architecture and HDFSDocument18 pages02 Unit-II Hadoop Architecture and HDFSKumarAdabalaNo ratings yet
- .Analysis and Processing of Massive Data Based On Hadoop Platform A Perusal of Big Data Classification and Hadoop TechnologyDocument3 pages.Analysis and Processing of Massive Data Based On Hadoop Platform A Perusal of Big Data Classification and Hadoop TechnologyPrecious PearlNo ratings yet
- Module III NoteDocument36 pagesModule III Notejohnsonjoshal5No ratings yet
- HADOOPDocument18 pagesHADOOPmaiyi020106No ratings yet
- BigdataDocument3 pagesBigdatavipin kumar guptaNo ratings yet
- Hadoop Features 2Document3 pagesHadoop Features 2sharan kommiNo ratings yet
- Big Data - Unit 2 Hadoop FrameworkDocument19 pagesBig Data - Unit 2 Hadoop FrameworkAditya DeshpandeNo ratings yet
- Bda - 10Document7 pagesBda - 10deshpande.pxreshNo ratings yet
- Experiment No - 01Document14 pagesExperiment No - 01AYAAN SatkutNo ratings yet
- UNIT-I Introduction To Hadoop - A20Document24 pagesUNIT-I Introduction To Hadoop - A20Manoj ReddyNo ratings yet
- Hadoop Unit-4Document44 pagesHadoop Unit-4Kishore ParimiNo ratings yet
- Big Data With Hadoop - For Data Management, Processing and StoringDocument7 pagesBig Data With Hadoop - For Data Management, Processing and StoringYesNo ratings yet
- Assignment 5 (Hadoop)Document1 pageAssignment 5 (Hadoop)hapiness1131No ratings yet
- What Is The Hadoop EcosystemDocument5 pagesWhat Is The Hadoop EcosystemZahra MeaNo ratings yet
- Introduction To HadoopDocument5 pagesIntroduction To HadoopHanumanthu GouthamiNo ratings yet
- CASE STUDY On Application of HadoopDocument16 pagesCASE STUDY On Application of Hadoophaqueashraful713No ratings yet
- Bda Summer 2022 SolutionDocument30 pagesBda Summer 2022 SolutionVivekNo ratings yet
- Hadoop Ecosystem: An Introduction: Sneha Mehta, Viral MehtaDocument6 pagesHadoop Ecosystem: An Introduction: Sneha Mehta, Viral MehtaSivaprakash ChidambaramNo ratings yet
- Apache HadoopDocument11 pagesApache HadoopImaad UkayeNo ratings yet
- Unit 3Document15 pagesUnit 3xcgfxgvxNo ratings yet
- Compusoft, 2 (11), 370-373 PDFDocument4 pagesCompusoft, 2 (11), 370-373 PDFIjact EditorNo ratings yet
- A Review of Hadoop Security Issues, Threats and SolutionsDocument6 pagesA Review of Hadoop Security Issues, Threats and SolutionsAbhishek DasNo ratings yet
- HADOOPDocument10 pagesHADOOPdebasmita.sahaNo ratings yet
- MapreduceDocument15 pagesMapreducemanasaNo ratings yet
- BDA Mod2@AzDOCUMENTS - inDocument64 pagesBDA Mod2@AzDOCUMENTS - inramyaNo ratings yet
- Subject: Data Driven Decision Making: Apache Hadoop For Big DataDocument5 pagesSubject: Data Driven Decision Making: Apache Hadoop For Big DataTarun MaheshwariNo ratings yet
- Big Data Module 2Document23 pagesBig Data Module 2Srikanth MNo ratings yet
- Cloud ComputingDocument19 pagesCloud ComputingAfia FaryadNo ratings yet
- Fbda Unit-3Document27 pagesFbda Unit-3Aruna ArunaNo ratings yet
- Unit 3Document61 pagesUnit 3Ramstage TestingNo ratings yet
- Bigdata and Hadoop NotesDocument5 pagesBigdata and Hadoop NotesNandini MalviyaNo ratings yet
- Bda Unit 4 MaterialDocument37 pagesBda Unit 4 MaterialSiva Saikumar Reddy KNo ratings yet
- HadoopDocument6 pagesHadoopVikas SinhaNo ratings yet
- Large-Scale Encryption in The Hadoop Environment Challenges and SolutionsDocument8 pagesLarge-Scale Encryption in The Hadoop Environment Challenges and SolutionsAbhishek DasNo ratings yet
- HadoopDocument13 pagesHadoopkajole7693No ratings yet
- A Survey On Estimation of Time On Hadoop Cluster For Data ComputationDocument4 pagesA Survey On Estimation of Time On Hadoop Cluster For Data ComputationNikhil TengliNo ratings yet
- BDA NotesDocument25 pagesBDA Notesmrudula.sbNo ratings yet
- BDA Unit 2 Q&ADocument14 pagesBDA Unit 2 Q&AviswakranthipalagiriNo ratings yet
- Big Data RAJNEESH CCCDocument11 pagesBig Data RAJNEESH CCCvidhya associateNo ratings yet
- Os BittuDocument10 pagesOs BittuVishwa MoorthyNo ratings yet
- Had Oop CancerDocument6 pagesHad Oop CancerAnil Kumar GuptaNo ratings yet
- Mainreport PDFDocument29 pagesMainreport PDFJyotishmoy saikiaNo ratings yet
- Big Data AnalyticsDocument26 pagesBig Data Analyticsiasccoe354No ratings yet
- Unit-Iv CC&BD CS71Document148 pagesUnit-Iv CC&BD CS71HaelNo ratings yet
- HadoopDocument58 pagesHadoopduggyNo ratings yet
- NYOUG Hadoop PresentatonDocument47 pagesNYOUG Hadoop PresentatonV KalyanNo ratings yet
- Chap Insert ManipulateDocument26 pagesChap Insert ManipulateV KalyanNo ratings yet
- Seminar CorrectedDocument24 pagesSeminar CorrectedV KalyanNo ratings yet
- BD 11Document17 pagesBD 11V KalyanNo ratings yet
- Challenge Lab 1 - Request PDFDocument3 pagesChallenge Lab 1 - Request PDFCruz M. Galán LuisNo ratings yet
- Abhishek SharmaDocument4 pagesAbhishek Sharmasneha.moreNo ratings yet
- Timers and Time Base Generation: Experiment 10Document7 pagesTimers and Time Base Generation: Experiment 10Suleman SaleemNo ratings yet
- Oncommand® System Manager 2.0.2: Quick Start GuideDocument19 pagesOncommand® System Manager 2.0.2: Quick Start GuideaslanwarezNo ratings yet
- COMPAQ Nc8000 SpecificationsDocument33 pagesCOMPAQ Nc8000 SpecificationsSteve Frm YellowstoneNo ratings yet
- h10938 VNX Best Practices WPDocument37 pagesh10938 VNX Best Practices WPtmourad83No ratings yet
- Iverilog VpiDocument2 pagesIverilog VpizxcasdqwerfvNo ratings yet
- Rhul Ma 2015 8Document126 pagesRhul Ma 2015 8Tony TroxNo ratings yet
- UnixDocument10 pagesUnixgdeepthiNo ratings yet
- CrashDocument1 pageCrashKerby RivraNo ratings yet
- v4/v6 L3VPN Over IP Core - Tutorial: Madhusudan NanjanagudDocument30 pagesv4/v6 L3VPN Over IP Core - Tutorial: Madhusudan NanjanagudPierre PaulNo ratings yet
- Networking FullDocument10 pagesNetworking FullsupriyaNo ratings yet
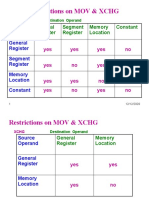
- Restrictions On MOV & XCHG: General Register Segment Register Memory Location ConstantDocument31 pagesRestrictions On MOV & XCHG: General Register Segment Register Memory Location ConstantABRAR RASUL QADRINo ratings yet
- OS-Question BankDocument3 pagesOS-Question BankFunny BunnyNo ratings yet
- USER MANUAL Falcon IP Kit (PDFDrive)Document46 pagesUSER MANUAL Falcon IP Kit (PDFDrive)rootNo ratings yet
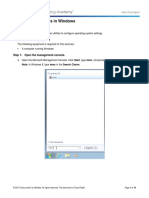
- 6.1.5.6 Lab - System Utilities in WindowsDocument10 pages6.1.5.6 Lab - System Utilities in WindowsMai FrensNo ratings yet
- Arm7 FamilyDocument4 pagesArm7 FamilydanielNo ratings yet
- Melsec Iq-R Online Module Change ManualDocument62 pagesMelsec Iq-R Online Module Change ManualVladu AdrianNo ratings yet
- DeltaV M-Series MQ Controller PDSDocument5 pagesDeltaV M-Series MQ Controller PDSMushfiqur RahmanNo ratings yet
- WORKSHEET - Data RepresentationDocument3 pagesWORKSHEET - Data Representationloduke9No ratings yet
- CCNP Ccie 350 601 107 Q 27 5 2020Document60 pagesCCNP Ccie 350 601 107 Q 27 5 2020Domainci BabaNo ratings yet
- E Puck Libraries Reference ManualDocument374 pagesE Puck Libraries Reference ManualantonellagrandeNo ratings yet
- 7.1 Iec61850 Iet600 Chpau RoadmapDocument1 page7.1 Iec61850 Iet600 Chpau RoadmapDebabrata Das TutulNo ratings yet
- Network Forensic of ImoDocument20 pagesNetwork Forensic of Imohadiamubeen100% (1)
- RegistryDocument27 pagesRegistryDanijela MijailovicNo ratings yet
- My The Awesome Ict CrosswordDocument1 pageMy The Awesome Ict CrosswordpoopdewhoopNo ratings yet
- Connector: Connector:: P5 P6 P4 P1 P4Document4 pagesConnector: Connector:: P5 P6 P4 P1 P4roby djNo ratings yet