You might also like
- BIOSTATISTICS - PPTX SidhathabDocument99 pagesBIOSTATISTICS - PPTX SidhathabSidhartha BordoloiNo ratings yet
- Samplin G Design: Presented By:-Siddharth KishanDocument43 pagesSamplin G Design: Presented By:-Siddharth KishanSiddharth KishanNo ratings yet
- MMW Group-4 Lesson 4 Data ManagementDocument68 pagesMMW Group-4 Lesson 4 Data ManagementRey MarkNo ratings yet
- L6 Sampling MethodsDocument99 pagesL6 Sampling MethodsASHENAFI LEMESANo ratings yet
- Statistics For MGMT I & IIDocument161 pagesStatistics For MGMT I & IIewnetuNo ratings yet
- Definition of Statistics and Key ConceptsDocument7 pagesDefinition of Statistics and Key ConceptsLavinia Delos SantosNo ratings yet
- Discussion For Today: Probability Sampling Non Probability Sampling QuestionnaireDocument31 pagesDiscussion For Today: Probability Sampling Non Probability Sampling QuestionnaireSheraz AhmedNo ratings yet
- Prof. Hemant KombrabailDocument32 pagesProf. Hemant KombrabailBalaji N100% (2)
- Statistics Chapter 1 IntroductionDocument111 pagesStatistics Chapter 1 IntroductionGebru GetachewNo ratings yet
- Statistics NotesDocument118 pagesStatistics NotesBenson Mwathi Mungai100% (1)
- StatisticsDocument50 pagesStatisticsAGEY KAFUI HANSELNo ratings yet
- BASIC STATISTICS Reviewer 1st QuarterDocument4 pagesBASIC STATISTICS Reviewer 1st QuarterAngelitaBejeranoNo ratings yet
- Chapter 4 Sampling DesignDocument34 pagesChapter 4 Sampling DesignYasinNo ratings yet
- Stat Manual 10Document83 pagesStat Manual 10Franz Baudin Toledo100% (1)
- The Nature of Probability and StatisticsDocument22 pagesThe Nature of Probability and StatisticsPavel PrakopchykNo ratings yet
- ResearchDocument39 pagesResearchHaq KaleemNo ratings yet
- Sasa ReviewerDocument8 pagesSasa ReviewerPatrick John LumutanNo ratings yet
- Chapter 1Document4 pagesChapter 1Pamela Judith GalopeNo ratings yet
- Statistics and Probability: Clariza Jane L. Metro Teacher IiiDocument53 pagesStatistics and Probability: Clariza Jane L. Metro Teacher IiiClariza Jane MetroNo ratings yet
- SamplingDocument14 pagesSamplingRitam DasNo ratings yet
- Statistics NotesDocument15 pagesStatistics NotesBalasubrahmanya K. R.No ratings yet
- Business Statistics - IntroductionDocument71 pagesBusiness Statistics - IntroductionMuthukrishnaveni AnandNo ratings yet
- The Difference Between Sampling in Quantitative and Qualitative ResearchDocument8 pagesThe Difference Between Sampling in Quantitative and Qualitative ResearchVilayat AliNo ratings yet
- Practical Research - Module 4 - Part 2 (Sampling)Document7 pagesPractical Research - Module 4 - Part 2 (Sampling)Maria AngelaNo ratings yet
- The Law of Carriage of Goods by Sea and Marine InsuranceDocument8 pagesThe Law of Carriage of Goods by Sea and Marine InsuranceAndrew MwingaNo ratings yet
- IntnetDocument82 pagesIntnetSamuelErmiyasNo ratings yet
- SAMPLINGDocument5 pagesSAMPLINGMylen Noel Elgincolin ManlapazNo ratings yet
- Basic concepts of statistical sampling methodsDocument6 pagesBasic concepts of statistical sampling methodsjeevalakshmanan29No ratings yet
- Sampling and Sampling DistributionDocument80 pagesSampling and Sampling DistributionMohammed AbdelaNo ratings yet
- Introduction To SamplingDocument11 pagesIntroduction To SamplingtekleyNo ratings yet
- Intro To StatisticsDocument11 pagesIntro To StatisticsVincent KimaniNo ratings yet
- Important Thing For TSDocument24 pagesImportant Thing For TShongye liNo ratings yet
- Statistics - DR Malinga - Notes For StudentsDocument34 pagesStatistics - DR Malinga - Notes For StudentsRogers Soyekwo KingNo ratings yet
- CHAPTER 8 Sampling and Sampling DistributionsDocument54 pagesCHAPTER 8 Sampling and Sampling DistributionsAyushi Jangpangi0% (1)
- Sampling and Sampling DistributionDocument6 pagesSampling and Sampling DistributiontemedebereNo ratings yet
- Biostatistics essentialsDocument73 pagesBiostatistics essentialsSaloni KatiyarNo ratings yet
- Basic Concepts 2Document18 pagesBasic Concepts 2HarijaNo ratings yet
- Basic concepts of statisticsDocument5 pagesBasic concepts of statisticsamanah abdullahNo ratings yet
- Chapter Four sampling design and procedureDocument27 pagesChapter Four sampling design and proceduredemilieNo ratings yet
- Module 18 The Need For SamplingDocument9 pagesModule 18 The Need For SamplingAlayka Mae Bandales LorzanoNo ratings yet
- Statistics: Basic ConceptsDocument5 pagesStatistics: Basic ConceptsMon MonNo ratings yet
- ADIGRAT UNIVERSITY Bass NewDocument8 pagesADIGRAT UNIVERSITY Bass Newmebrahtuhadush3No ratings yet
- Unit IiiDocument45 pagesUnit Iii05Bala SaatvikNo ratings yet
- Math Finals ReviewerDocument5 pagesMath Finals ReviewerIvy VergaraNo ratings yet
- 4 SamplingDocument89 pages4 SamplingBiruk WorkuNo ratings yet
- Research Methodology: Week 9 October 11-15, 2021Document57 pagesResearch Methodology: Week 9 October 11-15, 2021Catherine BandolonNo ratings yet
- LAS 9 Population and Sampling 1Document7 pagesLAS 9 Population and Sampling 1Stephanie Joan BonacuaNo ratings yet
- Module 1 STAT GSDocument5 pagesModule 1 STAT GSJohn Rainier QuijadaNo ratings yet
- Steps in Sample Design and Types of SamplingDocument7 pagesSteps in Sample Design and Types of Samplingsejal chowhanNo ratings yet
- Data ManagementDocument21 pagesData ManagementKervin AlubNo ratings yet
- Research Ch4Document25 pagesResearch Ch4Bantamkak FikaduNo ratings yet
- Dersnot 4626 1666356899Document16 pagesDersnot 4626 1666356899Samet ÖzdemirNo ratings yet
- Benjamin Alvarez Dillena JR., Ed.DDocument51 pagesBenjamin Alvarez Dillena JR., Ed.Dceledonio borricano.jrNo ratings yet
- Introduction: Demystifying The Art of SamplingDocument9 pagesIntroduction: Demystifying The Art of Samplingavnish54321stubbyNo ratings yet
- Chapter 2 Intro To StatisticsDocument42 pagesChapter 2 Intro To StatisticsLee SuarezNo ratings yet
- Module III-Sampling DesignDocument26 pagesModule III-Sampling DesignSUICIDE SQUAD THAMIZH YTNo ratings yet
- Unit One Sampling and Sampling DistributionDocument41 pagesUnit One Sampling and Sampling DistributionEbsa AdemeNo ratings yet
- Introduction To SamplingDocument14 pagesIntroduction To Samplingseifeldin374No ratings yet
- Collection of Data: ObjectivesDocument7 pagesCollection of Data: Objectivesapple gutierrezNo ratings yet
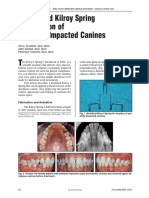
- Management of Impacted Maxillary Canines Using The Kilroy Spring: A Case SeriesDocument7 pagesManagement of Impacted Maxillary Canines Using The Kilroy Spring: A Case SeriesThang Nguyen TienNo ratings yet
- Mod Kilroy 2015Document3 pagesMod Kilroy 2015Harish Kumar.THOTANo ratings yet
- CANINEDocument10 pagesCANINEHarish Kumar.THOTANo ratings yet
- Erickosn and KurolDocument13 pagesErickosn and KurolHarish Kumar.THOTANo ratings yet
- Distalization Using Lever ArmDocument12 pagesDistalization Using Lever ArmHarish Kumar.THOTANo ratings yet
- JC 2 A RefDocument5 pagesJC 2 A RefHarish Kumar.THOTANo ratings yet
- 123Document1 page123Harish Kumar.THOTANo ratings yet
- Theories of Growth (Autosaved)Document53 pagesTheories of Growth (Autosaved)Harish Kumar.THOTANo ratings yet
- Good MorningDocument115 pagesGood MorningHarish Kumar.THOTANo ratings yet
- Bite Registration Construction TechniquesDocument37 pagesBite Registration Construction TechniquesHarish Kumar.THOTANo ratings yet
- Endocrinological Aspects of OrthoDocument38 pagesEndocrinological Aspects of OrthoHarish Kumar.THOTA100% (1)
- Statistics and Probability Module 1Document24 pagesStatistics and Probability Module 1Nathalia VallesNo ratings yet
- Further Statistics 1 Unit Test 7 Central Limit TheoremDocument3 pagesFurther Statistics 1 Unit Test 7 Central Limit TheoremJade BARTONNo ratings yet
- Stat520 Fa23 Asg 1Document4 pagesStat520 Fa23 Asg 1sudeep pathakNo ratings yet
- Probability IDocument62 pagesProbability IVivek SinghNo ratings yet
- Analysis of Variance: AnovaDocument13 pagesAnalysis of Variance: Anovaandre mariusNo ratings yet
- Chapter 5 Sampling DistributionDocument35 pagesChapter 5 Sampling DistributionSURIA ATIKA AHMAD ASRINo ratings yet
- Lecture12 PDFDocument36 pagesLecture12 PDFApoorav DhingraNo ratings yet
- Chi Square Test Case Processing SummaryDocument5 pagesChi Square Test Case Processing SummaryeshuNo ratings yet
- Analysing the Effect of Preaching on Church Growth TodayDocument16 pagesAnalysing the Effect of Preaching on Church Growth TodayAris SetyawanNo ratings yet
- Homework 1Document2 pagesHomework 1AlizesketitNo ratings yet
- 08 Tree AdvancedDocument68 pages08 Tree AdvancedNosheen RamzanNo ratings yet
- Common Statistical Densities: Appendix 1Document59 pagesCommon Statistical Densities: Appendix 1S.Sangeetha SwamydhasNo ratings yet
- STAT 230 Midterm 1 Statistics TestDocument4 pagesSTAT 230 Midterm 1 Statistics TestIan SmithNo ratings yet
- Even in The Odds PDFDocument2 pagesEven in The Odds PDFRonaldNo ratings yet
- Grade 11 Module 1-2: Probability Distributions and Random VariablesDocument9 pagesGrade 11 Module 1-2: Probability Distributions and Random VariablesMichelleC. VerandaNo ratings yet
- Statistical Learning: Problem Set 1: Problem 1 - Frequentist Decision TheoryDocument4 pagesStatistical Learning: Problem Set 1: Problem 1 - Frequentist Decision TheorySalman AlghifaryNo ratings yet
- Statistics and Probability: Quarter 4 - Module 4: Test Concerning Proportions (Central Limit Theorem)Document21 pagesStatistics and Probability: Quarter 4 - Module 4: Test Concerning Proportions (Central Limit Theorem)Jelai MedinaNo ratings yet
- Sia Notes 2013Document279 pagesSia Notes 2013pineappleshirt241No ratings yet
- 2 Way AnovaDocument20 pages2 Way Anovachawlavishnu100% (1)
- 14.5.6 Minitab Time Series and ForecastingDocument9 pages14.5.6 Minitab Time Series and ForecastingRiska PrakasitaNo ratings yet
- Homework 13 - SolutionDocument3 pagesHomework 13 - SolutionMarco Perez HernandezNo ratings yet
- Probability: F/ Written Preparation For BCS & BankDocument57 pagesProbability: F/ Written Preparation For BCS & BankMinhazul AbedinNo ratings yet
- Chapter1 Lesson 2Document1 pageChapter1 Lesson 2Jacquelyn GuintoNo ratings yet
- MATH 524 Nonparametric StatisticsDocument16 pagesMATH 524 Nonparametric StatisticsPatrick LeungNo ratings yet
- A First Course in Machine Learning - ErrataDocument2 pagesA First Course in Machine Learning - Erratasynchronicity27No ratings yet
- IE005 Lab Exercise 1 and 2mnDocument7 pagesIE005 Lab Exercise 1 and 2mnApril Dawates100% (1)
- Basic Statistics ConceptsDocument29 pagesBasic Statistics ConceptsthinagaranNo ratings yet
- Digital Notes on Probability & StatisticsDocument200 pagesDigital Notes on Probability & StatisticsLingannaNo ratings yet
- GFDSKJDocument5 pagesGFDSKJSanjiv MainaliNo ratings yet
- Mediation and Multi-Group ModerationDocument41 pagesMediation and Multi-Group ModerationTehrani SanazNo ratings yet