You might also like
- Transformers For NLPDocument42 pagesTransformers For NLPMynam MeghanaNo ratings yet
- Autoencoders: Presented By: 2019220013 Balde Lansana (Document21 pagesAutoencoders: Presented By: 2019220013 Balde Lansana (BALDENo ratings yet
- SegmentationDocument31 pagesSegmentationsourabh gotheNo ratings yet
- S.Y SyllabusDocument57 pagesS.Y Syllabusapdeshmukh371122No ratings yet
- R19 Cse (Iot)Document368 pagesR19 Cse (Iot)pushpa lathaNo ratings yet
- Final - CSE - V Semester - New - Syllabus PDFDocument13 pagesFinal - CSE - V Semester - New - Syllabus PDFsaurabh303No ratings yet
- II Year (CSE) SyllabusDocument36 pagesII Year (CSE) SyllabusAdarsha GandyadapuNo ratings yet
- CAD82: 5th International Conference and Exhibition on Computers in Design EngineeringFrom EverandCAD82: 5th International Conference and Exhibition on Computers in Design EngineeringNo ratings yet
- Nith Btech Scheme Syllabus Aug2015 PDFDocument62 pagesNith Btech Scheme Syllabus Aug2015 PDFNilaksh PundirNo ratings yet
- Concurrent Programming With Threads: Rajkumar BuyyaDocument168 pagesConcurrent Programming With Threads: Rajkumar BuyyaSurangma ParasharNo ratings yet
- Resume 2023 - Alexander Juncaj 1Document1 pageResume 2023 - Alexander Juncaj 1api-627578266No ratings yet
- Csvtu Syllabus Be Cse 6 SemDocument25 pagesCsvtu Syllabus Be Cse 6 SemCSE - Roshan PradhanNo ratings yet
- CS DS2Document37 pagesCS DS2Srinivas KanakalaNo ratings yet
- VNR Vignana Jyothi Institute of Engineering & Technology Hyderabad B.Tech. Ii Year (Information Technology) Iii Semester R19Document37 pagesVNR Vignana Jyothi Institute of Engineering & Technology Hyderabad B.Tech. Ii Year (Information Technology) Iii Semester R19Sumanth MerugaNo ratings yet
- SIATEC and SIA Efficient Algorithms For TranslatioDocument62 pagesSIATEC and SIA Efficient Algorithms For TranslatioJasper ChenNo ratings yet
- B TechinDataScienceDocument5 pagesB TechinDataSciencePrashantNo ratings yet
- Exam Time Table Nov 19, 2022Document6 pagesExam Time Table Nov 19, 2022Motive to MotivateNo ratings yet
- EECS 252 Graduate Computer Architecture Lec 1 - IntroductionDocument60 pagesEECS 252 Graduate Computer Architecture Lec 1 - IntroductionElisée NdjabuNo ratings yet
- Multi ThreadingDocument168 pagesMulti ThreadingSumanth GangappaNo ratings yet
- Btech Syllabus Cse 2018 31545Document100 pagesBtech Syllabus Cse 2018 31545Yakshit JoshiNo ratings yet
- DL Unit1Document91 pagesDL Unit1Alex SonNo ratings yet
- Vidyavardhini's College of Engineering & Technology: IndexDocument54 pagesVidyavardhini's College of Engineering & Technology: Indexsairaj varavdekarNo ratings yet
- Project Phase-2 Second Review On: Design of Efficient BCD Adder Using Different Logic GatesDocument27 pagesProject Phase-2 Second Review On: Design of Efficient BCD Adder Using Different Logic Gatessaikiranm031No ratings yet
- S6CSEHand OutDocument59 pagesS6CSEHand OutPathivadaSantoshNaiduNo ratings yet
- Logic Design for Array-Based Circuits: A Structured Design MethodologyFrom EverandLogic Design for Array-Based Circuits: A Structured Design MethodologyNo ratings yet
- FinalDocument27 pagesFinalsaikiranm031No ratings yet
- Machine Learning Applications in Physical Design: Recent Results and DirectionsDocument114 pagesMachine Learning Applications in Physical Design: Recent Results and DirectionsNitin GNo ratings yet
- CYS-R19 (1,2,3,4,5,6,7&8) TH Sem Course StructureDocument6 pagesCYS-R19 (1,2,3,4,5,6,7&8) TH Sem Course StructureSrinivas KanakalaNo ratings yet
- Vidyavardhini's College of Engineering & Technology: IndexDocument54 pagesVidyavardhini's College of Engineering & Technology: Indexsairaj varavdekarNo ratings yet
- AphsDocument111 pagesAphsDebarshi MajumderNo ratings yet
- PGDCADocument13 pagesPGDCAteyox19540No ratings yet
- High Speed Multiplication Using BCD Codes For DSP ApplicationsDocument6 pagesHigh Speed Multiplication Using BCD Codes For DSP ApplicationskuddNo ratings yet
- MTech Final Curriculum Senate-2092022Document9 pagesMTech Final Curriculum Senate-2092022Srinivas VCENo ratings yet
- DD Slides Merged Till Quiz 1Document101 pagesDD Slides Merged Till Quiz 1Aman AgNo ratings yet
- Ge6161 Computer Practices Lab PDFDocument61 pagesGe6161 Computer Practices Lab PDFAnoop MohanNo ratings yet
- Cse (Aiml) Ii Year R22Document52 pagesCse (Aiml) Ii Year R22ballakarivarun96No ratings yet
- Course Information Sheet CIS-ITC (Theory) - FALL2022Document6 pagesCourse Information Sheet CIS-ITC (Theory) - FALL2022bilawal khanNo ratings yet
- Lab Manual DsaDocument36 pagesLab Manual DsaJaveria KhanNo ratings yet
- Cse Cys2 PDFDocument36 pagesCse Cys2 PDFHari BoppanaNo ratings yet
- 352ccs - Lab ManualDocument48 pages352ccs - Lab ManualGaNo ratings yet
- Chap 0Document9 pagesChap 0Nguyen DanhNo ratings yet
- L5 Digital System Modeling1Document15 pagesL5 Digital System Modeling1madhu ningareddyNo ratings yet
- R20 - II To IV Year Syllabus CSEDocument25 pagesR20 - II To IV Year Syllabus CSEbeulahNo ratings yet
- DataFlow Modeling in VerilogDocument22 pagesDataFlow Modeling in VerilogWaqas Ahmed0% (1)
- R19ITDocument372 pagesR19IT20071a1290No ratings yet
- Apj Abdul Kalam Kerala Technological University: (Kolam Cluster - 02)Document79 pagesApj Abdul Kalam Kerala Technological University: (Kolam Cluster - 02)vishal bijiNo ratings yet
- S3CSEHand OutDocument66 pagesS3CSEHand OutHitha MathewNo ratings yet
- Computer Architecture Technology TrendsFrom EverandComputer Architecture Technology TrendsRating: 4 out of 5 stars4/5 (1)
- Lecture 1: Introduction To Digital Logic Design: CK Cheng CSE Dept. UC San DiegoDocument20 pagesLecture 1: Introduction To Digital Logic Design: CK Cheng CSE Dept. UC San DiegojarjarNo ratings yet
- 3distribution DesignDocument65 pages3distribution Designsriram sharathNo ratings yet
- Autocad ThesisDocument8 pagesAutocad Thesisdwfz48q3100% (2)
- Syllabus BCA BSC New 2023 24Document191 pagesSyllabus BCA BSC New 2023 24SHAMAPRASAD H P SDM College(Autonomous), UjireNo ratings yet
- Adding Analog and Mixed Signal Concerns To A Digital VLSI CourseDocument8 pagesAdding Analog and Mixed Signal Concerns To A Digital VLSI CourseLavanya SelvarajNo ratings yet
- M.tech - Artificial Intelligence and Data ScienceDocument57 pagesM.tech - Artificial Intelligence and Data ScienceJagadish JagsNo ratings yet
- B.Tech. (CSE) - AI&DSDocument37 pagesB.Tech. (CSE) - AI&DSSrinivas KanakalaNo ratings yet
- KSOU Distance MCA SyllabusDocument26 pagesKSOU Distance MCA SyllabusSunil JhaNo ratings yet
- CAD For VLSIDocument2 pagesCAD For VLSIKapasi TejasNo ratings yet
- ELEC522-Final-Project-4 X 4 Linear System Solver With ARM Core and CORDIC QRD and Matrix-Multiplication Accelerator IntegrationDocument15 pagesELEC522-Final-Project-4 X 4 Linear System Solver With ARM Core and CORDIC QRD and Matrix-Multiplication Accelerator IntegrationKenny LuNo ratings yet
- Ashika Nayak: EducationDocument2 pagesAshika Nayak: EducationAnil DharavathNo ratings yet
- Time Series CharacteristicDocument72 pagesTime Series Characteristicsourabh gotheNo ratings yet
- Image CaptioningDocument45 pagesImage Captioningsourabh gotheNo ratings yet
- FirstLecture FinancialAnalyticsDocument32 pagesFirstLecture FinancialAnalyticssourabh gotheNo ratings yet
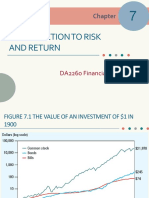
- Introduction To Riskand ReturnDocument36 pagesIntroduction To Riskand Returnsourabh gotheNo ratings yet
- Introduction To Corp FinanceDocument16 pagesIntroduction To Corp Financesourabh gotheNo ratings yet
- How Summer Students Perceive The Closed Summer Program: in The Case of Jimma UniversityDocument17 pagesHow Summer Students Perceive The Closed Summer Program: in The Case of Jimma UniversityКонстантин НечетNo ratings yet
- Iso SpinDocument5 pagesIso SpinjhgsgsNo ratings yet
- Sheena HSMDocument8 pagesSheena HSMdesign12No ratings yet
- Have A One Track Mind: Lorna WingDocument4 pagesHave A One Track Mind: Lorna WingsophilauNo ratings yet
- Lesson Plan in Mathematics Grade9Document6 pagesLesson Plan in Mathematics Grade9Abegail VillanuevaNo ratings yet
- Find The Belt Length at A 72 in Distance Connected in Open Belt. The Pulley Diameters Are 6 and 12 inDocument4 pagesFind The Belt Length at A 72 in Distance Connected in Open Belt. The Pulley Diameters Are 6 and 12 inGeoffrey GolbequeNo ratings yet
- Surveying Lab ManualDocument76 pagesSurveying Lab ManualIan Lawrence YupanoNo ratings yet
- Is - 2026-4Document27 pagesIs - 2026-4jm.mankavil6230No ratings yet
- Project LoveDocument6 pagesProject LoveANAVIC BANDINo ratings yet
- Thomson Catalog CompressedDocument210 pagesThomson Catalog CompressedCharlesNo ratings yet
- Exam 2 ND Semester 201516Document10 pagesExam 2 ND Semester 201516Samson SeiduNo ratings yet
- How To "Revert-Back" To "Previous-Version"???: Build 1 Testing DeploymentDocument19 pagesHow To "Revert-Back" To "Previous-Version"???: Build 1 Testing DeploymentClaudiu Stefan HaiduNo ratings yet
- Reference Manual: Buildings and Infrastructure Protection SeriesDocument514 pagesReference Manual: Buildings and Infrastructure Protection SeriesmydearteacherNo ratings yet
- Karma: "Dove La Legge Della Grazia È Attiva, Finisce La Legge Del Karma"Document37 pagesKarma: "Dove La Legge Della Grazia È Attiva, Finisce La Legge Del Karma"Lars JensenNo ratings yet
- Json Out InvoiceDocument2 pagesJson Out Invoicetkpatel529No ratings yet
- Rele A Gas BuchholtsDocument18 pagesRele A Gas BuchholtsMarco GiraldoNo ratings yet
- Business Statistics I: Hypothesis TestingDocument58 pagesBusiness Statistics I: Hypothesis TestingJamesNo ratings yet
- Citaion Style GuideDocument2 pagesCitaion Style Guideedustar330No ratings yet
- BARAKA Modelling ProposalDocument9 pagesBARAKA Modelling Proposalmurali.5482No ratings yet
- Lemon BatteryDocument6 pagesLemon BatteryMohammed AsifNo ratings yet
- Black Mirror Analysis: 15 Million Merits (Due 27/04/16)Document11 pagesBlack Mirror Analysis: 15 Million Merits (Due 27/04/16)Will MunnyNo ratings yet
- Short Time Current Rating of ConductorDocument12 pagesShort Time Current Rating of ConductorAbhinav SinhaNo ratings yet
- Cpu 2000 App ListDocument11 pagesCpu 2000 App ListKaiser IqbalNo ratings yet
- IMES Brochure 2010 04Document7 pagesIMES Brochure 2010 04Jose Luis RattiaNo ratings yet
- University of Tehran Faculty of New Science & Technology Master's Thesis Proposal DefenseDocument46 pagesUniversity of Tehran Faculty of New Science & Technology Master's Thesis Proposal DefenseSoheilDarvishMotavalliNo ratings yet
- LV07 KDocument11 pagesLV07 KSalman Shah83% (6)
- 4 Essays of CSS.Document17 pages4 Essays of CSS.Asma Parvez100% (6)
- Norton Introduction To Philosophy 2nd Edition Rosen Test BankDocument9 pagesNorton Introduction To Philosophy 2nd Edition Rosen Test Bankbenjaminhernandezfecmxjzrdt100% (14)
- ZXR10 8900 Series: Hardware Installation ManualDocument109 pagesZXR10 8900 Series: Hardware Installation ManualErnestoLopezGonzalezNo ratings yet
- Contribucion de Las FE A La AutorregulacionDocument24 pagesContribucion de Las FE A La AutorregulacionAmanda Riedemann CarrilloNo ratings yet