You might also like
- Ordinary Differential Equations Chapter 10: Fourier Series Student Solution ManualDocument30 pagesOrdinary Differential Equations Chapter 10: Fourier Series Student Solution ManualAmir SohailNo ratings yet
- Unit 1 Sequence & SeriesDocument24 pagesUnit 1 Sequence & SeriesTshering TashiNo ratings yet
- Exercices de Math Ematiques: Groups - PermutationsDocument8 pagesExercices de Math Ematiques: Groups - Permutationsنور هدىNo ratings yet
- SoluciónDocument1 pageSoluciónasuncion_fernandez_aNo ratings yet
- Matematica Fatorial Prof Judson SantosDocument9 pagesMatematica Fatorial Prof Judson SantoslucasNo ratings yet
- Assignment: Construct The Tree Diagram That Models The Prediction of Having Positive or Negative TestDocument4 pagesAssignment: Construct The Tree Diagram That Models The Prediction of Having Positive or Negative TestYhancie Mae TorresNo ratings yet
- Problem Solutions For Chapter 4: I B 2 3/2 e H 3/4 G BDocument11 pagesProblem Solutions For Chapter 4: I B 2 3/2 e H 3/4 G Bapi-19870706No ratings yet
- Assignment 4Document3 pagesAssignment 4Cesar Orlando Quiroz VillavicencioNo ratings yet
- Prob 3Document10 pagesProb 3Jawad Ul Hassan ShahNo ratings yet
- Probability: Sample Space SDocument5 pagesProbability: Sample Space SRazNo ratings yet
- Preface: Differential EquationsDocument5 pagesPreface: Differential EquationsShreyas SinghNo ratings yet
- RD Sharma Dec2020 Solution For Class 11 Maths Chapter 5 Ex 3Document11 pagesRD Sharma Dec2020 Solution For Class 11 Maths Chapter 5 Ex 3deepakpaul8181No ratings yet
- Toaz - Info Solution Manual Optical Fiber Communication Gerd Keiser 3rd Ed PRDocument63 pagesToaz - Info Solution Manual Optical Fiber Communication Gerd Keiser 3rd Ed PRdalvirphotonNo ratings yet
- 04 Cond ProbabilityDocument78 pages04 Cond ProbabilityLester LoteronoNo ratings yet
- Series: Mr. Rozhno OmerDocument50 pagesSeries: Mr. Rozhno OmerRahand KawaNo ratings yet
- Power Electronics Circuits Devices and Applications 4th Edition Rashid Solutions ManualDocument15 pagesPower Electronics Circuits Devices and Applications 4th Edition Rashid Solutions Manualrollingdistoma9zcylv100% (37)
- Exercise 6.1 (Solutions) : A N A A A ADocument2 pagesExercise 6.1 (Solutions) : A N A A A Aabdul qadeer AwanNo ratings yet
- Trigonometric Ratios and Identities-2Document58 pagesTrigonometric Ratios and Identities-2makreloadedNo ratings yet
- Xii MTK Wajib Kunci Jawaban MTK Sas 1 2022Document6 pagesXii MTK Wajib Kunci Jawaban MTK Sas 1 2022Teguh NurcahyoNo ratings yet
- Activity 2Document6 pagesActivity 2Soe YazarNo ratings yet
- Measures of Partition Quartiles, Deciles and PercentilesDocument5 pagesMeasures of Partition Quartiles, Deciles and Percentiles19GGB905 Zerafsah KhanamNo ratings yet
- Sheet No. (1) - Laplace Transform PDFDocument1 pageSheet No. (1) - Laplace Transform PDFMohamad DuhokiNo ratings yet
- Sheet No. (1) - Laplace TransformDocument1 pageSheet No. (1) - Laplace TransformMohamad DuhokiNo ratings yet
- 18-Assignment 1 - SolutionDocument12 pages18-Assignment 1 - Solutiondemro channelNo ratings yet
- Math III QuestionsDocument3 pagesMath III Questionsomaroymdmm999No ratings yet
- ISIT919 Knowledge Engineering: School of Computing and Information TechnologyDocument11 pagesISIT919 Knowledge Engineering: School of Computing and Information TechnologyAshish Presanna ChandranNo ratings yet
- Basics of Algorithm Analysis: What Is The Running Time of An AlgorithmDocument21 pagesBasics of Algorithm Analysis: What Is The Running Time of An AlgorithmasdasdNo ratings yet
- Answers To Selected Exercises For Chapter 1: Section 1.1 (Page 16)Document3 pagesAnswers To Selected Exercises For Chapter 1: Section 1.1 (Page 16)CisjeNo ratings yet
- Edu 2008 Spring C SolutionsDocument117 pagesEdu 2008 Spring C SolutionswillhsladeNo ratings yet
- NCERT Solutions For Class 11 Maths Chapter 9 Sequences and Series Miscellaneous ExerciseDocument29 pagesNCERT Solutions For Class 11 Maths Chapter 9 Sequences and Series Miscellaneous ExerciseimmanuelcyriltNo ratings yet
- More More Maths StuffDocument15 pagesMore More Maths Stuffjlawler69420No ratings yet
- Q4 Basic Calculus 11 - Module 3Document15 pagesQ4 Basic Calculus 11 - Module 3Niña LadNo ratings yet
- Arithmetic Sequences and Series4Document40 pagesArithmetic Sequences and Series4Romel Andrew RomeroNo ratings yet
- YT +Sequence+and+Series+L1+-+11th+Elite+Document96 pagesYT +Sequence+and+Series+L1+-+11th+Elite+John WickNo ratings yet
- VizeDocument4 pagesVizeMehmet KayhanNo ratings yet
- 6 Sequence & Series Part 1 of 2Document20 pages6 Sequence & Series Part 1 of 2Ayush PateriaNo ratings yet
- Day 4 Finding-N-And-Nth-Term-Given-2-TermsDocument18 pagesDay 4 Finding-N-And-Nth-Term-Given-2-TermsPaul Andrew GonzalesNo ratings yet
- Tutorial 10 AnswersDocument10 pagesTutorial 10 AnswersTetzNo ratings yet
- TMF1814 Tutorial 4 AnsDocument6 pagesTMF1814 Tutorial 4 AnsDemus JohneyNo ratings yet
- 1GP Math - August - Peer Tutoring MaterialDocument29 pages1GP Math - August - Peer Tutoring MaterialCedrick Nicolas ValeraNo ratings yet
- Maths05 PDFDocument7 pagesMaths05 PDFJoseNo ratings yet
- String Matching Algorithms: Antonio CarzanigaDocument11 pagesString Matching Algorithms: Antonio CarzanigavickimgoreNo ratings yet
- 15-381 Spring 2007 Assignment 6: LearningDocument14 pages15-381 Spring 2007 Assignment 6: LearningsandeepanNo ratings yet
- Marks) : Trial STPM 2010 Marking Scheme 954/2Document11 pagesMarks) : Trial STPM 2010 Marking Scheme 954/2exammyNo ratings yet
- Arithmetic SequenceDocument23 pagesArithmetic SequenceNarendra SolankiNo ratings yet
- Assignment4 - SolutionDocument4 pagesAssignment4 - SolutionMiranda WongNo ratings yet
- ACET June 2022 SolutionDocument11 pagesACET June 2022 SolutionNafis AlamNo ratings yet
- Find The First 4 Terms in Each Sequence. A) T 3 (-2)Document11 pagesFind The First 4 Terms in Each Sequence. A) T 3 (-2)NmNo ratings yet
- Chapter-1 Sequence and Series (Mathematics)Document16 pagesChapter-1 Sequence and Series (Mathematics)tychrNo ratings yet
- Lista de EjerciciosDocument26 pagesLista de Ejerciciosttp96ngwqtNo ratings yet
- Lialy Sarti - 17029064 - Task XIIDocument15 pagesLialy Sarti - 17029064 - Task XIIlialy sartiNo ratings yet
- Maths PadleDocument31 pagesMaths PadleDude AccNo ratings yet
- 02 - HW - Series ProblemsDocument2 pages02 - HW - Series ProblemsMaxNo ratings yet
- Arithmetic and Geometric ProgressionDocument19 pagesArithmetic and Geometric Progressiontanmoy8554No ratings yet
- Math 10 Demo yDocument61 pagesMath 10 Demo yJason MartinNo ratings yet
- Online Prac GCET # 01 (For MBA) : Objective KeyDocument4 pagesOnline Prac GCET # 01 (For MBA) : Objective Keydipak4ever100% (1)
- Number Patterns, Sequences and Series Grade 12 Notes - Mathematics Study GuidesDocument20 pagesNumber Patterns, Sequences and Series Grade 12 Notes - Mathematics Study GuidesphumucpNo ratings yet
- GT 4 SolutionsDocument11 pagesGT 4 Solutionssri sai surajNo ratings yet
- Selina Solution Concise Maths Class 10 Chapter 10Document22 pagesSelina Solution Concise Maths Class 10 Chapter 10Kanti VermaNo ratings yet
- Lecture 10Document35 pagesLecture 10tarun guptaNo ratings yet
- Lecture 3Document24 pagesLecture 3tarun guptaNo ratings yet
- Lecture 5Document31 pagesLecture 5tarun guptaNo ratings yet
- Lecture 2Document32 pagesLecture 2tarun guptaNo ratings yet
- 10-701/15-781, Machine Learning: Homework 1: Aarti Singh Carnegie Mellon UniversityDocument6 pages10-701/15-781, Machine Learning: Homework 1: Aarti Singh Carnegie Mellon Universitytarun guptaNo ratings yet
- 10-701/15-781, Machine Learning: Homework 5: Aarti Singh Carnegie Mellon UniversityDocument13 pages10-701/15-781, Machine Learning: Homework 5: Aarti Singh Carnegie Mellon Universitytarun guptaNo ratings yet
- Presentation 1Document25 pagesPresentation 1tarun guptaNo ratings yet
- Yokogawa ExaQuantum Usage Procedure Rev1Document34 pagesYokogawa ExaQuantum Usage Procedure Rev1adadehNo ratings yet
- Bank Islam IBDocument3 pagesBank Islam IBAjad PangNo ratings yet
- ECE5590 Introduction To MPCDocument4 pagesECE5590 Introduction To MPCPabloNo ratings yet
- Instruction Manual Series 880 CIU Plus: July 2009 Part No.: 4416.526 Rev. 6Document44 pagesInstruction Manual Series 880 CIU Plus: July 2009 Part No.: 4416.526 Rev. 6nknico100% (1)
- WPL-Lab-Manual-fatima 13084Document17 pagesWPL-Lab-Manual-fatima 13084HABIBA -No ratings yet
- Exit Clearance Form: CompletedDocument1 pageExit Clearance Form: CompletedUjang BaniNo ratings yet
- DW Akademie - MIL - Guidebook - 2018 - Materials - Chapter 5Document20 pagesDW Akademie - MIL - Guidebook - 2018 - Materials - Chapter 5RYAN BANARIANo ratings yet
- Pro-Lcd Data SheetDocument2 pagesPro-Lcd Data Sheetapi-170472102No ratings yet
- 附件03-CP R80.40 SitetoSiteVPN AdminGuideDocument240 pages附件03-CP R80.40 SitetoSiteVPN AdminGuide000-924680No ratings yet
- Intel Annual Report 2021: Form 10-K (NASDAQ:INTC)Document10 pagesIntel Annual Report 2021: Form 10-K (NASDAQ:INTC)WigglepikeNo ratings yet
- Stata Session 1 KA (Class)Document6 pagesStata Session 1 KA (Class)jmn 06No ratings yet
- Experiment 9: Bank Database ObjectiveDocument4 pagesExperiment 9: Bank Database Objectiveprudhvi chowdaryNo ratings yet
- Q Star InfoDocument53 pagesQ Star InfogothictoroNo ratings yet
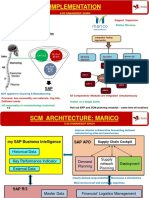
- S-55 Implementation RamandeepMarico SCMDocument2 pagesS-55 Implementation RamandeepMarico SCMSandeep KhatriNo ratings yet
- Bhavesh Krishan Garg Cse2b-G1 (Lab-04)Document10 pagesBhavesh Krishan Garg Cse2b-G1 (Lab-04)Bhavesh GargNo ratings yet
- A Secure Proxy-Based Cross-Domain Communication FoDocument9 pagesA Secure Proxy-Based Cross-Domain Communication FobruteforceNo ratings yet
- Oracle Hospitality Simphony POS On The AWS CloudDocument25 pagesOracle Hospitality Simphony POS On The AWS CloudKo Ko AungNo ratings yet
- SWAT 3 - Tactical Game of The Year Edition - Manual - PCDocument95 pagesSWAT 3 - Tactical Game of The Year Edition - Manual - PCAnonymous utXYfMAXNo ratings yet
- Ed Adjectives BingoDocument17 pagesEd Adjectives BingoN B80No ratings yet
- W IPRODocument26 pagesW IPROSamad Bilgi50% (2)
- Elegance Redefined: Pricelist: June 2021Document3 pagesElegance Redefined: Pricelist: June 2021Kamal JaswalNo ratings yet
- Mahesh R Pujar: (Volume3, Issue2)Document6 pagesMahesh R Pujar: (Volume3, Issue2)Ignited MindsNo ratings yet
- CEM60 Firmware UpgradeDocument6 pagesCEM60 Firmware UpgradePraahas AminNo ratings yet
- E-Healthcare Management System: Final Year ProjectDocument63 pagesE-Healthcare Management System: Final Year ProjectMuhammad AjmalNo ratings yet
- Ascendance VillivakkamDocument3 pagesAscendance Villivakkamsonaiya software solutionsNo ratings yet
- DAS-000010revA - Osprey-UVX Customer DatasheetDocument2 pagesDAS-000010revA - Osprey-UVX Customer DatasheetEduardo DmgzNo ratings yet
- Maple For Math Majors: Solve FsolveDocument21 pagesMaple For Math Majors: Solve FsolveAleksandar MicicNo ratings yet
- TB037 (Rev2) - Measuring BacklashDocument2 pagesTB037 (Rev2) - Measuring BacklashCarlos RodriguezNo ratings yet
- FoE. ASU Drives and YouTube Channels LinksDocument3 pagesFoE. ASU Drives and YouTube Channels Linksabdelhameed saedNo ratings yet
- Blockchain Essentials & DappsDocument125 pagesBlockchain Essentials & DappsBharath Kumar T V100% (1)