You might also like
- CS2106 Lab 8Document3 pagesCS2106 Lab 8weitsangNo ratings yet
- Python Advanced Programming: The Guide to Learn Python Programming. Reference with Exercises and Samples About Dynamical Programming, Multithreading, Multiprocessing, Debugging, Testing and MoreFrom EverandPython Advanced Programming: The Guide to Learn Python Programming. Reference with Exercises and Samples About Dynamical Programming, Multithreading, Multiprocessing, Debugging, Testing and MoreNo ratings yet
- CS 342 - Assignment 1 - Sept - Nov - 2020Document4 pagesCS 342 - Assignment 1 - Sept - Nov - 2020Trinayan DasNo ratings yet
- Optimization 5 MicrobenchmarksDocument25 pagesOptimization 5 MicrobenchmarksdanielvmacedoNo ratings yet
- Computer Organization & Design The Hardware/Software Interface, 2nd Edition Patterson & HennessyDocument118 pagesComputer Organization & Design The Hardware/Software Interface, 2nd Edition Patterson & HennessyMr.Puppy80% (5)
- Set Questions 1Document7 pagesSet Questions 1Cristian IacoboaeiNo ratings yet
- 1.1 ParallelismDocument29 pages1.1 ParallelismVinay MishraNo ratings yet
- Ku 5th Sem AssignmentDocument44 pagesKu 5th Sem AssignmentChitrangada ChakrabortyNo ratings yet
- Assignment 5: Raw Memory: Bits and BytesDocument6 pagesAssignment 5: Raw Memory: Bits and BytesnikNo ratings yet
- UsingEclipse PDFDocument37 pagesUsingEclipse PDFashiNo ratings yet
- 10 Tips For Writing High-Performance Web ApplicationDocument9 pages10 Tips For Writing High-Performance Web ApplicationbrightjijinNo ratings yet
- Computer Science Textbook Solutions - 18Document31 pagesComputer Science Textbook Solutions - 18acc-expertNo ratings yet
- HW1 SolutionDocument3 pagesHW1 Solutionryle34No ratings yet
- ACA BigData Consolidated DumpDocument29 pagesACA BigData Consolidated DumpAhimed Habib HusenNo ratings yet
- Homework III 100 PointsDocument2 pagesHomework III 100 PointsNiaaNo ratings yet
- Project 1Document2 pagesProject 1kailash ramNo ratings yet
- Computer Notes 152Document2 pagesComputer Notes 152Biplap HomeNo ratings yet
- Parallel Computing: Charles KoelbelDocument12 pagesParallel Computing: Charles KoelbelSilvio DresserNo ratings yet
- Algorithms As A TechnologyDocument4 pagesAlgorithms As A TechnologyJosé M. RamírezNo ratings yet
- Computing and Informatics - An203/Ad303: Postal Test Paper - 2 MARKS:100 DURATION:3 HoursDocument1 pageComputing and Informatics - An203/Ad303: Postal Test Paper - 2 MARKS:100 DURATION:3 HourskaviatchennaiNo ratings yet
- 3BSE029193R101 - en Control Module - When and Why - ArticleDocument10 pages3BSE029193R101 - en Control Module - When and Why - ArticleRaj ChavanNo ratings yet
- Sheet 02Document2 pagesSheet 02eir.gnNo ratings yet
- Architecture ComputerDocument3 pagesArchitecture Computerlillyren2808No ratings yet
- Theory Research at GoogleDocument19 pagesTheory Research at GoogleΑλέξανδρος ΓεωργίουNo ratings yet
- B34 R3Document3 pagesB34 R3Hari KalathilNo ratings yet
- Cse-Vii-Advanced Computer Architectures (10cs74) - SolutionDocument111 pagesCse-Vii-Advanced Computer Architectures (10cs74) - SolutionShinu100% (1)
- CS 349 Assignment 1 (Spring - 2019) PDFDocument2 pagesCS 349 Assignment 1 (Spring - 2019) PDFsahilNo ratings yet
- OS hw3Document2 pagesOS hw3universeNo ratings yet
- Modern TutorialDocument18 pagesModern TutorialAnalystSENo ratings yet
- 1.1 Parallelism and Computing: 1.1.1 Trends in ApplicationsDocument25 pages1.1 Parallelism and Computing: 1.1.1 Trends in ApplicationskarunakarNo ratings yet
- 1 Difference Between Compiler and Interpreter: 2 What Is A Class in C# Net?Document5 pages1 Difference Between Compiler and Interpreter: 2 What Is A Class in C# Net?ThakurKumudsing ThakurkumudNo ratings yet
- Introducing CPP Con Currency Run TimeDocument20 pagesIntroducing CPP Con Currency Run TimeTertelie Vasile IonNo ratings yet
- Chapter2.2-Thread QuestionDocument3 pagesChapter2.2-Thread QuestionNguyễn Trí DũngNo ratings yet
- Node JS in 24 HoursDocument393 pagesNode JS in 24 HoursloroNo ratings yet
- COD Ch. 2 The Role of PerformanceDocument28 pagesCOD Ch. 2 The Role of PerformanceMohammad Abdul RafehNo ratings yet
- Measure Early For Perf 2Document5 pagesMeasure Early For Perf 2Diego MendesNo ratings yet
- 7 Steps To Writing A Simple Cooperative Scheduler PDFDocument5 pages7 Steps To Writing A Simple Cooperative Scheduler PDFReid LindsayNo ratings yet
- Computer Science Textbook Solutions - 13Document30 pagesComputer Science Textbook Solutions - 13acc-expertNo ratings yet
- Week 2 Project - Search Algorithms - CSMMDocument8 pagesWeek 2 Project - Search Algorithms - CSMMRaj kumar manepallyNo ratings yet
- Part 1: What Is N-Tier Architecture?: Karim HyattDocument8 pagesPart 1: What Is N-Tier Architecture?: Karim HyattSurendra BansalNo ratings yet
- 1-Program Design and AnalysisDocument6 pages1-Program Design and AnalysisUmer AftabNo ratings yet
- PracticeProblems COA8eDocument40 pagesPracticeProblems COA8eAnousith PhompidaNo ratings yet
- CS 6290: High-Performance Computer Architecture: Summer 2019Document5 pagesCS 6290: High-Performance Computer Architecture: Summer 2019playboi partieNo ratings yet
- Performances of Computer Systems: CSE 675.02: Introduction To Computer ArchitectureDocument52 pagesPerformances of Computer Systems: CSE 675.02: Introduction To Computer ArchitectureshubhamNo ratings yet
- High Performance Techniques For Microsoft SQL Server PDFDocument307 pagesHigh Performance Techniques For Microsoft SQL Server PDFmaghnus100% (1)
- How Do Optimization Your CodeDocument9 pagesHow Do Optimization Your CodeTruong Le DuyNo ratings yet
- Lecture1 NotesDocument19 pagesLecture1 Notesl215376No ratings yet
- Principles of Parallel Algorithm DesignDocument78 pagesPrinciples of Parallel Algorithm DesignKarthik LaxmikanthNo ratings yet
- QB1Document21 pagesQB1Lavanya KarthikNo ratings yet
- Algorithms and Complexity IDocument102 pagesAlgorithms and Complexity ISly2518100% (1)
- E2 AnswersDocument19 pagesE2 AnswersAditya MishraNo ratings yet
- Chapter 1 IntroductionDocument17 pagesChapter 1 IntroductionYaseen AshrafNo ratings yet
- Webspeed Tricks and TipsDocument44 pagesWebspeed Tricks and Tipschill_migrane_23No ratings yet
- Scimakelatex 20425 xxx6Document6 pagesScimakelatex 20425 xxx6borlandspamNo ratings yet
- Recognizing The ImportanceDocument2 pagesRecognizing The ImportanceRadha GuptaNo ratings yet
- Com 419 - CSD - Cat 2 2023Document5 pagesCom 419 - CSD - Cat 2 2023vimintiuasNo ratings yet
- Doctor Dobbs'Document12 pagesDoctor Dobbs'Carlos Perez Chavez100% (1)
- Performance BigQuery Vs RedshiftDocument14 pagesPerformance BigQuery Vs RedshiftKamal ManchandaNo ratings yet
- Tristram FP 443Document6 pagesTristram FP 443sandokanaboliNo ratings yet
- Assignment4 DSP Fall2022Document4 pagesAssignment4 DSP Fall2022Mowahhid ShakeelNo ratings yet
- Assignment 3Document1 pageAssignment 3Mowahhid ShakeelNo ratings yet
- Side - C - Crash - Course - BerkleyDocument33 pagesSide - C - Crash - Course - BerkleyMowahhid ShakeelNo ratings yet
- Assignment 4Document2 pagesAssignment 4Mowahhid ShakeelNo ratings yet
- Assignment 2Document1 pageAssignment 2Mowahhid ShakeelNo ratings yet
- Assignment 3Document2 pagesAssignment 3Mowahhid ShakeelNo ratings yet
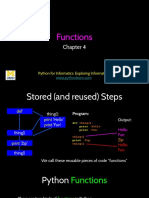
- Functions: Python For Informatics: Exploring InformationDocument24 pagesFunctions: Python For Informatics: Exploring InformationNaruto PatelNo ratings yet
- GUI in PythonDocument58 pagesGUI in PythonANKUR CHOUDHARYNo ratings yet
- Programming Fundamentals Lab 06 (Simple Loops and Switch)Document6 pagesProgramming Fundamentals Lab 06 (Simple Loops and Switch)Ahmad AbduhuNo ratings yet
- Continuous Deployment Everything: David Cramer @Document28 pagesContinuous Deployment Everything: David Cramer @Cihad GündoğduNo ratings yet
- Lab - 07 1 InglesDocument8 pagesLab - 07 1 InglesJeferson SallesNo ratings yet
- CS411 FinalTerm Subjective Solved by Arslan Arshad (Zain Nasar) (BvuCgr) 2Document7 pagesCS411 FinalTerm Subjective Solved by Arslan Arshad (Zain Nasar) (BvuCgr) 2Abbas JaffriNo ratings yet
- Mini Project - 1 Report - 143, 144 - IT - 3Document31 pagesMini Project - 1 Report - 143, 144 - IT - 3L. PoojithaNo ratings yet
- Build A CMS in An Afternoon With PHP and MySQLDocument45 pagesBuild A CMS in An Afternoon With PHP and MySQLhnguyen_698971No ratings yet
- Test Review: View Answers and Explanation For This Test.: Control Instructions Discuss in ForumDocument14 pagesTest Review: View Answers and Explanation For This Test.: Control Instructions Discuss in ForumsajithNo ratings yet
- IRM Chapter 6e 15Document41 pagesIRM Chapter 6e 15ralucutza_neculaNo ratings yet
- C Programming For Computer Graphics: 1 IntroductionDocument26 pagesC Programming For Computer Graphics: 1 IntroductionPawan AroraNo ratings yet
- List in HTMLDocument24 pagesList in HTMLParulNo ratings yet
- Acciojob: Start Your Tech Career, Pay Us After Your First SalaryDocument13 pagesAcciojob: Start Your Tech Career, Pay Us After Your First Salarythink smartNo ratings yet
- Introduction To Computers, Programs, and Java: Servers, Desktop Computers, and Small Hand-Held DevicesDocument18 pagesIntroduction To Computers, Programs, and Java: Servers, Desktop Computers, and Small Hand-Held DevicesKartik SharmaNo ratings yet
- Compare Web Authoring Tools PDFDocument11 pagesCompare Web Authoring Tools PDFPujik Itu PanggilankuNo ratings yet
- Orchestration and Automation - Ryan Darst - Marco GarciaDocument41 pagesOrchestration and Automation - Ryan Darst - Marco GarciaMachhindra PawarNo ratings yet
- Chapter 4Document62 pagesChapter 4yola chattpgNo ratings yet
- Makino Milling Machine Libraries (MML) Mccomm - Ocx Reference ManualDocument28 pagesMakino Milling Machine Libraries (MML) Mccomm - Ocx Reference ManualErich KreisederNo ratings yet
- CourseMarial - e22d8CSE 302Document1 pageCourseMarial - e22d8CSE 302Aman VermaNo ratings yet
- Whats New in Visual FoxPro 8.0 Chapter 06Document24 pagesWhats New in Visual FoxPro 8.0 Chapter 06APP EXCELNo ratings yet
- Codeigniter Library: 77 Free Scripts, Addons, Tutorials and VideosDocument6 pagesCodeigniter Library: 77 Free Scripts, Addons, Tutorials and VideosmbahsomoNo ratings yet
- Mobile Primer CourseDocument4 pagesMobile Primer CoursePushpendra SinghNo ratings yet
- Advanced Java Questions MCQ 2 PDFDocument102 pagesAdvanced Java Questions MCQ 2 PDFadithyata6No ratings yet
- Chaining of Custom Services in DFSDocument4 pagesChaining of Custom Services in DFSthemaddy2002No ratings yet
- Anonymous ResumeDocument1 pageAnonymous ResumeKeaton MacLeodNo ratings yet
- Blazor For ASP NET Web Forms DevelopersDocument98 pagesBlazor For ASP NET Web Forms DevelopersE- MarShalL100% (1)
- Assignment 3 - Advanced Project in Axure RPDocument4 pagesAssignment 3 - Advanced Project in Axure RPSarahWangNo ratings yet
- Compiler Construction: Nguyen Thi Thu Huong Department of Computer Science-HUST Email: Cell Phone 0903253796Document35 pagesCompiler Construction: Nguyen Thi Thu Huong Department of Computer Science-HUST Email: Cell Phone 0903253796Huy Đỗ QuangNo ratings yet
- AI Lab Manual Version 1.3Document123 pagesAI Lab Manual Version 1.3vagajNo ratings yet
- Dont Open Its TrashDocument22 pagesDont Open Its TrashEXERV SNo ratings yet
- iPhone Unlocked for the Non-Tech Savvy: Color Images & Illustrated Instructions to Simplify the Smartphone Use for Beginners & Seniors [COLOR EDITION]From EverandiPhone Unlocked for the Non-Tech Savvy: Color Images & Illustrated Instructions to Simplify the Smartphone Use for Beginners & Seniors [COLOR EDITION]Rating: 5 out of 5 stars5/5 (2)
- iPhone 14 Guide for Seniors: Unlocking Seamless Simplicity for the Golden Generation with Step-by-Step ScreenshotsFrom EverandiPhone 14 Guide for Seniors: Unlocking Seamless Simplicity for the Golden Generation with Step-by-Step ScreenshotsRating: 5 out of 5 stars5/5 (3)
- RHCSA Red Hat Enterprise Linux 9: Training and Exam Preparation Guide (EX200), Third EditionFrom EverandRHCSA Red Hat Enterprise Linux 9: Training and Exam Preparation Guide (EX200), Third EditionNo ratings yet
- Kali Linux - An Ethical Hacker's Cookbook - Second Edition: Practical recipes that combine strategies, attacks, and tools for advanced penetration testing, 2nd EditionFrom EverandKali Linux - An Ethical Hacker's Cookbook - Second Edition: Practical recipes that combine strategies, attacks, and tools for advanced penetration testing, 2nd EditionRating: 5 out of 5 stars5/5 (1)
- Linux For Beginners: The Comprehensive Guide To Learning Linux Operating System And Mastering Linux Command Line Like A ProFrom EverandLinux For Beginners: The Comprehensive Guide To Learning Linux Operating System And Mastering Linux Command Line Like A ProNo ratings yet
- Hacking : The Ultimate Comprehensive Step-By-Step Guide to the Basics of Ethical HackingFrom EverandHacking : The Ultimate Comprehensive Step-By-Step Guide to the Basics of Ethical HackingRating: 5 out of 5 stars5/5 (3)
- Mastering Swift 5 - Fifth Edition: Deep dive into the latest edition of the Swift programming language, 5th EditionFrom EverandMastering Swift 5 - Fifth Edition: Deep dive into the latest edition of the Swift programming language, 5th EditionNo ratings yet
- Linux: A Comprehensive Guide to Linux Operating System and Command LineFrom EverandLinux: A Comprehensive Guide to Linux Operating System and Command LineNo ratings yet
- Excel : The Ultimate Comprehensive Step-By-Step Guide to the Basics of Excel Programming: 1From EverandExcel : The Ultimate Comprehensive Step-By-Step Guide to the Basics of Excel Programming: 1Rating: 4.5 out of 5 stars4.5/5 (3)
- Mastering Linux Security and Hardening - Second Edition: Protect your Linux systems from intruders, malware attacks, and other cyber threats, 2nd EditionFrom EverandMastering Linux Security and Hardening - Second Edition: Protect your Linux systems from intruders, malware attacks, and other cyber threats, 2nd EditionNo ratings yet
- React.js for A Beginners Guide : From Basics to Advanced - A Comprehensive Guide to Effortless Web Development for Beginners, Intermediates, and ExpertsFrom EverandReact.js for A Beginners Guide : From Basics to Advanced - A Comprehensive Guide to Effortless Web Development for Beginners, Intermediates, and ExpertsNo ratings yet
- Azure DevOps Engineer: Exam AZ-400: Azure DevOps Engineer: Exam AZ-400 Designing and Implementing Microsoft DevOps SolutionsFrom EverandAzure DevOps Engineer: Exam AZ-400: Azure DevOps Engineer: Exam AZ-400 Designing and Implementing Microsoft DevOps SolutionsNo ratings yet
- Hello Swift!: iOS app programming for kids and other beginnersFrom EverandHello Swift!: iOS app programming for kids and other beginnersNo ratings yet
- RHCSA Exam Pass: Red Hat Certified System Administrator Study GuideFrom EverandRHCSA Exam Pass: Red Hat Certified System Administrator Study GuideNo ratings yet