You might also like
- Computation of Fractional Derivatives of Analytic Functions: Bengt Fornberg Cécile PiretDocument23 pagesComputation of Fractional Derivatives of Analytic Functions: Bengt Fornberg Cécile PiretYousef AlamriNo ratings yet
- CS2210b Data Structures Algorithms Due ThursdayDocument6 pagesCS2210b Data Structures Algorithms Due ThursdayAijin JiangNo ratings yet
- MIT18 783S13 Pset10Document7 pagesMIT18 783S13 Pset10Michał BaduraNo ratings yet
- Fast Fourier Transform and Option PricingDocument7 pagesFast Fourier Transform and Option PricingALNo ratings yet
- Error Correcting Codes From General Linear Groups: Mahir Bilen CanDocument12 pagesError Correcting Codes From General Linear Groups: Mahir Bilen CanMd. Adnan NabibNo ratings yet
- Regularization of Feynman IntegralsDocument28 pagesRegularization of Feynman IntegralsRonaldo Rêgo100% (1)
- University of Cambridge International Examinations General Certificate of Education Advanced Subsidiary LevelDocument4 pagesUniversity of Cambridge International Examinations General Certificate of Education Advanced Subsidiary LevelhyyyNo ratings yet
- Examples4 PDFDocument2 pagesExamples4 PDFManuel OosNo ratings yet
- Irrationality of Values of The Riemann Zeta FunctionDocument54 pagesIrrationality of Values of The Riemann Zeta Functionari wiliamNo ratings yet
- Modified Cholesky Algorithms: New Approaches for LT LT FactorizationDocument42 pagesModified Cholesky Algorithms: New Approaches for LT LT FactorizationPino BacadaNo ratings yet
- ch05 1Document27 pagesch05 1vs sNo ratings yet
- Numerical Methods Convergence OrderDocument14 pagesNumerical Methods Convergence OrderDANIEL ALEJANDRO VARGAS UZURIAGANo ratings yet
- Computing The Permanent of (Some) Complex MatricesDocument14 pagesComputing The Permanent of (Some) Complex MatricesJainil ShahNo ratings yet
- Case StudyDocument9 pagesCase StudyMR. KASHAAFNo ratings yet
- Chapter 2 Devide and ConquerDocument33 pagesChapter 2 Devide and ConquerYenatu Lij BayeNo ratings yet
- 10.450 Process Dynamics, Operations, and Control Lecture Notes - 3 Lesson 3. Math Review. 3.0 ContextDocument9 pages10.450 Process Dynamics, Operations, and Control Lecture Notes - 3 Lesson 3. Math Review. 3.0 Contextse781No ratings yet
- Physics 127b: Statistical Mechanics Lecture 2: Dense Gas and The Liquid StateDocument7 pagesPhysics 127b: Statistical Mechanics Lecture 2: Dense Gas and The Liquid StateAdam JouamaaNo ratings yet
- Sample Midterm 1 PDFDocument3 pagesSample Midterm 1 PDFlolnodudeborshismineNo ratings yet
- Complex Lie Algebras of Order 3 ClassifiedDocument8 pagesComplex Lie Algebras of Order 3 ClassifiedArchit KumarNo ratings yet
- Finite Element Poisson SolverDocument6 pagesFinite Element Poisson SolverRuben Dario Guerrero ENo ratings yet
- Mathematical Tripos: at The End of The ExaminationDocument28 pagesMathematical Tripos: at The End of The ExaminationDedliNo ratings yet
- Kinematics of The Stewart PlatformDocument7 pagesKinematics of The Stewart PlatformTay le YongNo ratings yet
- Results On Multiples Ofprimitive Polynomials and Their Products Over GFDocument33 pagesResults On Multiples Ofprimitive Polynomials and Their Products Over GFgowdamandaviNo ratings yet
- Cluster AlgebraDocument63 pagesCluster Algebrasaw.unitNo ratings yet
- Dosang Joe and Hyungju Park: Nal Varieties. Rational Parametrizations of The Irreducible ComponentsDocument12 pagesDosang Joe and Hyungju Park: Nal Varieties. Rational Parametrizations of The Irreducible ComponentsMohammad Mofeez AlamNo ratings yet
- Sy - Integral CalculusDocument12 pagesSy - Integral CalculusNeelam KapoorNo ratings yet
- Computing Permanents of Complex Matrices in Nearly Linear TimeDocument12 pagesComputing Permanents of Complex Matrices in Nearly Linear TimeSimos SoldatosNo ratings yet
- 1970 22erdosDocument14 pages1970 22erdosvahid mesicNo ratings yet
- National Security Agency, Ft. Meade, MD, USA: CACR Visitor Jan.-June 1999Document23 pagesNational Security Agency, Ft. Meade, MD, USA: CACR Visitor Jan.-June 1999lapxlriqNo ratings yet
- Lambert ProblemDocument8 pagesLambert ProblemChinmay TambatNo ratings yet
- Spherical TriangleDocument22 pagesSpherical TriangleJoseph TobsNo ratings yet
- 4442exercise 3Document2 pages4442exercise 3Roy VeseyNo ratings yet
- Homework 1 SolutionsDocument6 pagesHomework 1 SolutionsPeter Okidi Agara OyoNo ratings yet
- SESA6061 Coursework 2 (Hand in via e-assignments by Wed 4th Dec 23:00Document8 pagesSESA6061 Coursework 2 (Hand in via e-assignments by Wed 4th Dec 23:00Giulio MarkNo ratings yet
- Generalized QCD Via The Bilocal Method: Igor PesandoDocument14 pagesGeneralized QCD Via The Bilocal Method: Igor PesandotareghNo ratings yet
- Linear Algebra Notes on DeterminantsDocument5 pagesLinear Algebra Notes on DeterminantsDebashish PalNo ratings yet
- National Institute of Technology Silchar: Answer All QuestionsDocument1 pageNational Institute of Technology Silchar: Answer All QuestionsRituraj NathNo ratings yet
- Perturbation Theory 1Document9 pagesPerturbation Theory 1jaswin90No ratings yet
- PHYS 381 W23 Assignment 4Document8 pagesPHYS 381 W23 Assignment 4Nathan NgoNo ratings yet
- Canonical Polyadic Decomposition With Orthogonality ConstraintsDocument24 pagesCanonical Polyadic Decomposition With Orthogonality ConstraintsBilius LauraNo ratings yet
- PH474 and 574 HW SetDocument6 pagesPH474 and 574 HW SetlolnationNo ratings yet
- MATH415 FALL2017 Exam2 Practice SolutionsDocument21 pagesMATH415 FALL2017 Exam2 Practice SolutionsAidi .WafiNo ratings yet
- Practice Exam 3Document13 pagesPractice Exam 3mmbeesleyNo ratings yet
- Paper 48Document5 pagesPaper 48KaustubhNo ratings yet
- Winograd FFTDocument6 pagesWinograd FFTLeon HibnikNo ratings yet
- Exercise DGCL MeshDeformationDocument12 pagesExercise DGCL MeshDeformationtijsnoyonNo ratings yet
- FP2 Practice Paper ADocument4 pagesFP2 Practice Paper AchequillasNo ratings yet
- Paper 47Document6 pagesPaper 47KaustubhNo ratings yet
- Definit IntegralDocument5 pagesDefinit IntegrallorenzangelobalawagNo ratings yet
- Higher Order Interpolation and QuadratureDocument12 pagesHigher Order Interpolation and QuadratureTahir AedNo ratings yet
- Convergent Inversion Approximations For Polynomials in Bernstein FormDocument18 pagesConvergent Inversion Approximations For Polynomials in Bernstein FormMaiah DinglasanNo ratings yet
- Connection Matrices for Generalized Hypergeometric FunctionsDocument27 pagesConnection Matrices for Generalized Hypergeometric Functions3873263No ratings yet
- Algorithms For Solving Linear Systems of EquationsDocument10 pagesAlgorithms For Solving Linear Systems of EquationsVedant PawarNo ratings yet
- On the Tangent Space to the Space of Algebraic Cycles on a Smooth Algebraic Variety. (AM-157)From EverandOn the Tangent Space to the Space of Algebraic Cycles on a Smooth Algebraic Variety. (AM-157)No ratings yet
- Ten-Decimal Tables of the Logarithms of Complex Numbers and for the Transformation from Cartesian to Polar Coordinates: Volume 33 in Mathematical Tables SeriesFrom EverandTen-Decimal Tables of the Logarithms of Complex Numbers and for the Transformation from Cartesian to Polar Coordinates: Volume 33 in Mathematical Tables SeriesNo ratings yet
- Modeling Electromagnetic Interference Between a 500 kV Power Line and Pipeline with Complex Geometry and Multilayered SoilDocument8 pagesModeling Electromagnetic Interference Between a 500 kV Power Line and Pipeline with Complex Geometry and Multilayered SoillovelifeNo ratings yet
- Ucalgary 2016 Kuang DaDocument212 pagesUcalgary 2016 Kuang DalovelifeNo ratings yet
- CMP ResponseDocument274 pagesCMP ResponselovelifeNo ratings yet
- Voltage Induction On Pipelines Caused by Power Line Harmonic CurrentsDocument160 pagesVoltage Induction On Pipelines Caused by Power Line Harmonic CurrentslovelifeNo ratings yet
- MMTP TDR Biophys Terrain and SoilsDocument102 pagesMMTP TDR Biophys Terrain and SoilslovelifeNo ratings yet
- MGF Reportr2 - Public Redacted Per Pub Letter December 19, 2017Document258 pagesMGF Reportr2 - Public Redacted Per Pub Letter December 19, 2017lovelifeNo ratings yet
- SourcegraphDocument1 pageSourcegraphlovelifeNo ratings yet
- Project Plan Version 1Document26 pagesProject Plan Version 1lovelifeNo ratings yet
- Par Keewatinohk SwitchyardDocument2 pagesPar Keewatinohk SwitchyardlovelifeNo ratings yet
- CDEGS Users Group Constitution (Revised 2021.06.15)Document10 pagesCDEGS Users Group Constitution (Revised 2021.06.15)lovelifeNo ratings yet
- SES Software Packages for Engineering Computation and DesignDocument3 pagesSES Software Packages for Engineering Computation and DesignlovelifeNo ratings yet
- Grounding, EMI and Lightning Certification TrainingDocument9 pagesGrounding, EMI and Lightning Certification TraininglovelifeNo ratings yet
- Fulltext01Document129 pagesFulltext01lovelifeNo ratings yet
- Jacobian PDFDocument2 pagesJacobian PDFSyed Zain MehdiNo ratings yet
- Solution of Systems of Linear Delay Differential Equations Via Laplace TransformationDocument6 pagesSolution of Systems of Linear Delay Differential Equations Via Laplace TransformationSanjib RakshitNo ratings yet
- Determinants Chapter SolutionsDocument5 pagesDeterminants Chapter SolutionsOm Prakash SharmaNo ratings yet
- MOdule GRADE 11 Module 5-6Document8 pagesMOdule GRADE 11 Module 5-6Christian Cabadongga100% (1)
- Complex Numbers: Z A+b I A Real PartDocument5 pagesComplex Numbers: Z A+b I A Real PartDennis AndradaNo ratings yet
- CF & SS E-CAPS-14: Key concepts in calculusDocument4 pagesCF & SS E-CAPS-14: Key concepts in calculusKrishnendu SahaNo ratings yet
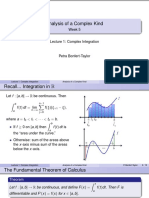
- Complex Integration PDFDocument12 pagesComplex Integration PDFjayroldparcede100% (2)
- Integral Domains: Ab Ac B C. This Leads To The FollowingDocument5 pagesIntegral Domains: Ab Ac B C. This Leads To The FollowingLazdebest LeaderNo ratings yet
- Derivatives of inverse trigonometric functionsDocument2 pagesDerivatives of inverse trigonometric functionsAyush GuptaNo ratings yet
- 222b Lecture NotesDocument98 pages222b Lecture NotesTOM DAVISNo ratings yet
- Multiplying Polynomials 1Document13 pagesMultiplying Polynomials 1Cacait RojanieNo ratings yet
- Discrete Fourier Transform, DFT and FFTDocument37 pagesDiscrete Fourier Transform, DFT and FFTabubakrNo ratings yet
- Ma6351 Unit IV Fourier TransformsDocument30 pagesMa6351 Unit IV Fourier Transformssatheeshsep24No ratings yet
- CuspDocument3 pagesCuspRomeissaaNo ratings yet
- IntegrationDocument123 pagesIntegrationHari KrushnaNo ratings yet
- CCP-MT (1 1e) PDFDocument184 pagesCCP-MT (1 1e) PDFRajat KaliaNo ratings yet
- Review vectors matrices appendicesDocument16 pagesReview vectors matrices appendicesArvind ShuklaNo ratings yet
- Chapter 3 Laplace TransformDocument32 pagesChapter 3 Laplace TransformAie Neutral100% (1)
- Introduction To Abstract Algebra - Math 113 - Paulin PDFDocument78 pagesIntroduction To Abstract Algebra - Math 113 - Paulin PDFPhilip OswaldNo ratings yet
- Mathocrat PYQ 1992-2022 Real AnalysisDocument16 pagesMathocrat PYQ 1992-2022 Real AnalysisAmanNo ratings yet
- Relations and Functions - 11 - Ws - 1 - Question Bank - 22-23Document8 pagesRelations and Functions - 11 - Ws - 1 - Question Bank - 22-23Parshav GoyalNo ratings yet
- Data Analysis by Govind PanduDocument303 pagesData Analysis by Govind Panduprashanth vermaNo ratings yet
- Solving IntegralsDocument4 pagesSolving IntegralsKaran Ravi BhatnagarNo ratings yet
- Permutations with Repetition (Distinguishable PermutationDocument14 pagesPermutations with Repetition (Distinguishable PermutationRhae Diaz DarisanNo ratings yet
- Module 9. Partial DerivativesDocument18 pagesModule 9. Partial DerivativesMark Daniel RamiterreNo ratings yet
- ORF523 Lec2Document13 pagesORF523 Lec2navid babaeiNo ratings yet
- SVD and LSI CombinedDocument11 pagesSVD and LSI CombinedReni AmuNo ratings yet
- DSP-2 (DFS & DFT) (S)Document53 pagesDSP-2 (DFS & DFT) (S)Pratik PatelNo ratings yet
- (Horizons in World Physics 237) A. S. Demidov - Generalized Functions in Mathematical Physics - Main Ideas and Concepts - Nova Science Pub Inc (2001)Document153 pages(Horizons in World Physics 237) A. S. Demidov - Generalized Functions in Mathematical Physics - Main Ideas and Concepts - Nova Science Pub Inc (2001)paku deyNo ratings yet
- 10.4 Exponential Equations PDFDocument5 pages10.4 Exponential Equations PDFPatzAlzateParaguya100% (1)