You might also like
- The Spectral Theory of Toeplitz Operators. (AM-99), Volume 99From EverandThe Spectral Theory of Toeplitz Operators. (AM-99), Volume 99No ratings yet
- Asimilasi 2Document1 pageAsimilasi 2Nur AqilahNo ratings yet
- DS535 Note 4 (With Marks)Document18 pagesDS535 Note 4 (With Marks)nuthan manideepNo ratings yet
- You Your A The: Took Royong in LetterDocument4 pagesYou Your A The: Took Royong in LetterSyamimi ZolkepliNo ratings yet
- Scanned - 0002Document1 pageScanned - 0002Nirban sahaNo ratings yet
- Img 20221229 0001Document1 pageImg 20221229 0001fredyNo ratings yet
- Simulation Activity 4.1 CE21S11Document3 pagesSimulation Activity 4.1 CE21S11JOHN DENVER LUGTUNo ratings yet
- BMS34A00157,156Document5 pagesBMS34A00157,156Rohit Parmar (Computer Operator, Bangalore)No ratings yet
- Compressor Spec+Schem SMDocument4 pagesCompressor Spec+Schem SMjoeeNo ratings yet
- Ffirt: .T - ""!!R+FR - (EiDocument3 pagesFfirt: .T - ""!!R+FR - (EiRohit Parmar (Computer Operator, Bangalore)No ratings yet
- Operator Crane CertificateDocument5 pagesOperator Crane CertificateDedy SulistyoNo ratings yet
- Statistics - Notes1Document1 pageStatistics - Notes1Ali AquinoNo ratings yet
- Audio 1982 02 PDFDocument92 pagesAudio 1982 02 PDFmoises100% (1)
- Sub Soil Investigation Report of Bridge at Ch. 11+066 PDFDocument4 pagesSub Soil Investigation Report of Bridge at Ch. 11+066 PDFMahbubur Rahman RussellNo ratings yet
- K'WV ., W: RN Vo'' +Document22 pagesK'WV ., W: RN Vo'' +Carla CardealNo ratings yet
- PG 3Document1 pagePG 3Khoo Rui JieNo ratings yet
- Kinematics and Inverse Kinematics of A SCARA Robot: TopicsDocument10 pagesKinematics and Inverse Kinematics of A SCARA Robot: TopicsanujagrajNo ratings yet
- Time SeriesDocument5 pagesTime SeriesPrathamNo ratings yet
- Img 20190802 0001Document2 pagesImg 20190802 0001Hon Nguyen VietNo ratings yet
- Unit-4 Cardivascular ApplicationsDocument13 pagesUnit-4 Cardivascular ApplicationsDibyashree BasuNo ratings yet
- Postgraduate-Pg Mba Semester-3 2022 May International-Finance-Pattern-2019Document2 pagesPostgraduate-Pg Mba Semester-3 2022 May International-Finance-Pattern-2019MrugendraNo ratings yet
- BW4B 18-02-2021Document1 pageBW4B 18-02-2021Ferdinand0No ratings yet
- Darc!:, (,'1 "... 1 T),, t:1, Il, /LDocument3 pagesDarc!:, (,'1 "... 1 T),, t:1, Il, /LRohit Parmar (Computer Operator, Bangalore)No ratings yet
- Thompson P4Document13 pagesThompson P4Berkay ŞirinNo ratings yet
- Speed 08Document1 pageSpeed 08docpot2008No ratings yet
- Open Circuit Characteristics of DC Shunt GeneratorDocument6 pagesOpen Circuit Characteristics of DC Shunt GeneratorBalagam RupaNo ratings yet
- D - 1.0 Is The Top 11ne: Lei:gtnDocument1 pageD - 1.0 Is The Top 11ne: Lei:gtnkrismkar2014No ratings yet
- DEC-2018-JAN-2019 - EC-minDocument84 pagesDEC-2018-JAN-2019 - EC-minkvxrw7201No ratings yet
- CAPE Physics 2008 U1 P2 (TT) Mark SchemeDocument16 pagesCAPE Physics 2008 U1 P2 (TT) Mark SchemeMik CharlieNo ratings yet
- INTERNAL ARMED CONFLICTSManuscriptDocument4 pagesINTERNAL ARMED CONFLICTSManuscriptMichael QuidorNo ratings yet
- LLQLS: Il'F, Iigeiieiieii3!I'E'I'Document7 pagesLLQLS: Il'F, Iigeiieiieii3!I'E'I'Sachin MalaviNo ratings yet
- Pelfcd./V Eirfef: City News Water Rattoni Effectil/E ImmediatelyDocument3 pagesPelfcd./V Eirfef: City News Water Rattoni Effectil/E ImmediatelyLarry LeachNo ratings yet
- BMS34A149Document3 pagesBMS34A149Rohit Parmar (Computer Operator, Bangalore)No ratings yet
- M53 2010 Le5Document1 pageM53 2010 Le5krystal.bscNo ratings yet
- Aliment at Ore Alinco - DM330MVE - SMDocument14 pagesAliment at Ore Alinco - DM330MVE - SMdaniele_mdgNo ratings yet
- Data Structures I DEC-2019 Sem-I (S.Y.B.Tech IT)Document2 pagesData Structures I DEC-2019 Sem-I (S.Y.B.Tech IT)Kirti GanoreNo ratings yet
- DS535 Note3Document16 pagesDS535 Note3nuthan manideepNo ratings yet
- @ Trui :RR", W: cI-'.:,Darcl 72llg?4Document3 pages@ Trui :RR", W: cI-'.:,Darcl 72llg?4Rohit Parmar (Computer Operator, Bangalore)No ratings yet
- Histološki Crteži - Neda Delić, MFUBDocument36 pagesHistološki Crteži - Neda Delić, MFUBDario BratićNo ratings yet
- Pattern: Relay Lf'gic - , E:lementary Diagram Connectlon Diagram L1 L2Document4 pagesPattern: Relay Lf'gic - , E:lementary Diagram Connectlon Diagram L1 L2Juvenal G. C. GallardoNo ratings yet
- Documents I TL Lines I Practice I - : 1961 SKM FWDocument7 pagesDocuments I TL Lines I Practice I - : 1961 SKM FWManoj AhirwarNo ratings yet
- CHECHLISTDocument1 pageCHECHLISTAmpere MISNo ratings yet
- GON DPHO Monthly-Report FalgunDocument3 pagesGON DPHO Monthly-Report FalgunEnlightened IdeasNo ratings yet
- PChem F2002-E1Document7 pagesPChem F2002-E1api-3707297No ratings yet
- Scema Jun 2019 DJJ30103Document9 pagesScema Jun 2019 DJJ301031054 HAFIZ HIZANINo ratings yet
- CH 3Document25 pagesCH 3Fàrhàt HossainNo ratings yet
- Timeless BenshoofDocument10 pagesTimeless BenshoofJeeson Eun100% (1)
- IMG - 0452 Computer Fundamental Lecture PRCDocument1 pageIMG - 0452 Computer Fundamental Lecture PRCMaster JaguarNo ratings yet
- FH SSDocument7 pagesFH SSMONA KUMARINo ratings yet
- Conflict of Laws Syllabus - Atty. QuibodDocument8 pagesConflict of Laws Syllabus - Atty. QuibodEzer Ivan Ria BacayoNo ratings yet
- BMS34A00206,207Document5 pagesBMS34A00206,207Rohit Parmar (Computer Operator, Bangalore)No ratings yet
- PS Endotoxins and ExotoxinsDocument6 pagesPS Endotoxins and ExotoxinsShalini MNo ratings yet
- BMS34A00191Document3 pagesBMS34A00191Rohit Parmar (Computer Operator, Bangalore)No ratings yet
- CH#5 Elliptic Integral With ExerciseDocument15 pagesCH#5 Elliptic Integral With ExerciseMuhammad UsmanNo ratings yet
- CH#5 Elliptic IntegralsDocument15 pagesCH#5 Elliptic IntegralsTaha ZakaNo ratings yet
- Runway LightingDocument12 pagesRunway LightingBalaji RNo ratings yet
- IMG - 0061 MCQ EE Board Problem 2012 18Document1 pageIMG - 0061 MCQ EE Board Problem 2012 18Master JaguarNo ratings yet
- 1er EXAMEN PARCIAL DE FENOMENOS DE TRANSPORTEDocument3 pages1er EXAMEN PARCIAL DE FENOMENOS DE TRANSPORTEEdicely EVNo ratings yet
- Phy3622 11 Sup 2018Document5 pagesPhy3622 11 Sup 2018Jay KayyNo ratings yet
- DS535 Note3Document16 pagesDS535 Note3nuthan manideepNo ratings yet
- Note 4Document18 pagesNote 4nuthan manideepNo ratings yet
- Note 6Document33 pagesNote 6nuthan manideepNo ratings yet
- DS535 Note2 (Marked)Document27 pagesDS535 Note2 (Marked)nuthan manideepNo ratings yet
- Note 2Document27 pagesNote 2nuthan manideepNo ratings yet
- DS535 Note1Document19 pagesDS535 Note1nuthan manideepNo ratings yet
- Note 5Document24 pagesNote 5nuthan manideepNo ratings yet
- Lesson Plan OoadDocument3 pagesLesson Plan OoadvplvplNo ratings yet
- NP Hard and NP Complete ProblemsDocument15 pagesNP Hard and NP Complete ProblemsAngu Vignesh GuruNo ratings yet
- Review Article: A Comprehensive Survey of Abstractive Text Summarization Based On Deep LearningDocument21 pagesReview Article: A Comprehensive Survey of Abstractive Text Summarization Based On Deep LearningFranco CapuanoNo ratings yet
- Variables EmptechDocument15 pagesVariables EmptechGelo VeeNo ratings yet
- LU5: Deep Feedforward Networks: Hidden Units, Architecture DesignDocument15 pagesLU5: Deep Feedforward Networks: Hidden Units, Architecture DesignDEIVAM RNo ratings yet
- NN ExamplesDocument91 pagesNN Examplesnguyenhoangan.13dt2No ratings yet
- Lecture 17. Closure Properties of Recursive and R.E. LanguagesDocument4 pagesLecture 17. Closure Properties of Recursive and R.E. Languageswenqiang0716No ratings yet
- 15A05404 Formal Languages & Automata TheoryDocument2 pages15A05404 Formal Languages & Automata TheoryScribd JdjNo ratings yet
- SE3 CondensedDocument6 pagesSE3 CondensedOwais Qureshi100% (1)
- UntitledDocument6 pagesUntitledSPEEDCELL PremiumNo ratings yet
- Unit 1: Definition and Characteristics of Object-Oriented ProgrammingDocument7 pagesUnit 1: Definition and Characteristics of Object-Oriented ProgrammingMasautso ChiwambaNo ratings yet
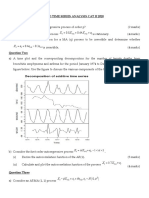
- X X X E: Karatina University Sta 223: Introduction To Time Series Analysis Cat Ii 2020 Question OneDocument2 pagesX X X E: Karatina University Sta 223: Introduction To Time Series Analysis Cat Ii 2020 Question OneKimondo KingNo ratings yet
- 6 Table 10 T TableDocument1 page6 Table 10 T TableHafidz IkhwanNo ratings yet
- Probability PDFDocument116 pagesProbability PDFKoustav MukherjeeNo ratings yet
- Formal Languages and Automata Theory QB PDFDocument5 pagesFormal Languages and Automata Theory QB PDFSatish JadhaoNo ratings yet
- A Survey On Deep Learning For Multimodal Data FusionDocument36 pagesA Survey On Deep Learning For Multimodal Data FusionllNo ratings yet
- 3 1 DFA To Regular ExpressionDocument20 pages3 1 DFA To Regular ExpressionNabilah IsyraqNo ratings yet
- Question BankDocument10 pagesQuestion BankGurjit SinghNo ratings yet
- Formula SheetDocument3 pagesFormula SheetgogogogoNo ratings yet
- Information Bottleneck MethodDocument11 pagesInformation Bottleneck MethodAzamatNo ratings yet
- A Note On The Equivalence of NARX and RNNDocument7 pagesA Note On The Equivalence of NARX and RNNcristian_masterNo ratings yet
- TOC Unit I MCQDocument4 pagesTOC Unit I MCQBum TumNo ratings yet
- Time Series Analysis ARIMA Final RaychellSantosEmbileDocument45 pagesTime Series Analysis ARIMA Final RaychellSantosEmbileRaychell Manuel Santos-EmbileNo ratings yet
- Introduction-To-Ml-Part-3 EditedDocument73 pagesIntroduction-To-Ml-Part-3 EditedHana AlhomraniNo ratings yet
- Implementing A DFA (Deterministic Finite Automata) in C++Document5 pagesImplementing A DFA (Deterministic Finite Automata) in C++Rizul83% (6)
- Coupling and CohesionDocument10 pagesCoupling and CohesionRizz BajwaNo ratings yet
- Asm4 2013345148Document10 pagesAsm4 2013345148K59 Le Gia HanNo ratings yet
- Random Processes Ma1254Document17 pagesRandom Processes Ma1254Surya Kumar MaranNo ratings yet
- Continuous Dist Week 5Document12 pagesContinuous Dist Week 5LibyaFlowerNo ratings yet
- LSTM in RNNDocument90 pagesLSTM in RNNClaudioNo ratings yet