You might also like
- TRDP 11-2005Document6 pagesTRDP 11-2005api-3733074No ratings yet
- Classic CV-how To DoDocument1 pageClassic CV-how To DoadahNo ratings yet
- Itr-Mw 242Document1 pageItr-Mw 242Ramzi ZoghlamiNo ratings yet
- Itr-Mw 242Document1 pageItr-Mw 242Ramzi ZoghlamiNo ratings yet
- Pile Dynamics, Inc. Cross-Hole AnalyzerDocument14 pagesPile Dynamics, Inc. Cross-Hole AnalyzerMalak NajemNo ratings yet
- Digitalisation On EconomyDocument20 pagesDigitalisation On EconomyMacsim BogdanNo ratings yet
- Classic CVDocument1 pageClassic CVmrdoogeesNo ratings yet
- Casablanca: Youtube Channel: Free Guitar TabsDocument9 pagesCasablanca: Youtube Channel: Free Guitar TabsMinh Tiến100% (1)
- 4cc Testpage HighDocument1 page4cc Testpage HighRumen StoychevNo ratings yet
- Spice PresentationDocument5 pagesSpice Presentationshruti.dhond3251No ratings yet
- ENDO Hermanussen 11.40 Nutrition Effects On Growth - CSDocument58 pagesENDO Hermanussen 11.40 Nutrition Effects On Growth - CSDennyNo ratings yet
- Harvest Home - MandolinDocument1 pageHarvest Home - MandolinTom MazumaNo ratings yet
- HiringDocument7 pagesHiringAvish GumberNo ratings yet
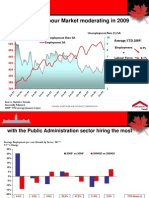
- Consumer Confidence LagsDocument1 pageConsumer Confidence LagsWalter BialasNo ratings yet
- ABB PQ FilterDocument14 pagesABB PQ FilterTrung NguyenNo ratings yet
- TCodesDocument3 pagesTCodesshishaolunNo ratings yet
- Indifference TabDocument10 pagesIndifference TabEfrain AlejandroNo ratings yet
- Indifference Tab PDFDocument10 pagesIndifference Tab PDFgoracvetNo ratings yet
- Misc Happy Birthday Fingerstyle BluesDocument1 pageMisc Happy Birthday Fingerstyle BluesPedro Jose PorteroNo ratings yet
- Kanlungan TabsDocument3 pagesKanlungan TabsAlfredNo ratings yet
- World Economic IndicatorsDocument3 pagesWorld Economic IndicatorsSteveTillNo ratings yet
- Trends: S Upply DemandDocument42 pagesTrends: S Upply DemandThoughts and More ThoughtsNo ratings yet
- CMHC Update June 2009Document16 pagesCMHC Update June 2009jawaid6970No ratings yet
- Israel's Economy March 2011Document38 pagesIsrael's Economy March 2011Economic Mission, Embassy of IsraelNo ratings yet
- Business Forecasting: The Box-Jenkins Method of ForecastingDocument22 pagesBusiness Forecasting: The Box-Jenkins Method of ForecastingNavinNo ratings yet
- N Orthridge Earthquake Dam Age: M AgnitudeDocument1 pageN Orthridge Earthquake Dam Age: M AgnitudeJoão AsseiceiraNo ratings yet
- The Star Spangled BannerDocument2 pagesThe Star Spangled Bannernyanchu4077No ratings yet
- UwU Tabs (Canción)Document3 pagesUwU Tabs (Canción)Majo;;No ratings yet
- Silent Hill Promise Tab PDFDocument1 pageSilent Hill Promise Tab PDFjjjasonNo ratings yet
- Silent Hill Promise Tab PDFDocument1 pageSilent Hill Promise Tab PDFTxomso LamaNo ratings yet
- Silent Hill Promise Tab PDFDocument1 pageSilent Hill Promise Tab PDFBrandon CTNo ratings yet
- Silent Hill Promise Tab PDFDocument1 pageSilent Hill Promise Tab PDFGermanCrewNo ratings yet
- Lack Orse LuesDocument4 pagesLack Orse Luespercy sledgeNo ratings yet
- WWW .Monchingcar Pio: Thyro Alf Aro & Y Umi LacsamanaDocument4 pagesWWW .Monchingcar Pio: Thyro Alf Aro & Y Umi LacsamanaJonathan GocelaNo ratings yet
- Dep.: Puno, Prov.: San Antonio de Putina, Dist.: Ananea Lat.: 14°40 34.5, Long.: 69°32 01.7, Alt.: 4660Document1 pageDep.: Puno, Prov.: San Antonio de Putina, Dist.: Ananea Lat.: 14°40 34.5, Long.: 69°32 01.7, Alt.: 4660Elvis EspinozaNo ratings yet
- Practitioners' Insights: Investing Under Uncertainties by Kuntal Shah 13 May 2020Document43 pagesPractitioners' Insights: Investing Under Uncertainties by Kuntal Shah 13 May 2020Sanjay JalindhraNo ratings yet
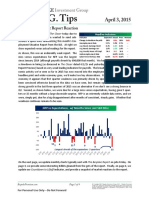
- NFP Vs Expectations, W/ Months Since Last 50K Miss: For Personal Use Only-Do Not ForwardDocument4 pagesNFP Vs Expectations, W/ Months Since Last 50K Miss: For Personal Use Only-Do Not ForwardSpeculation OnlyNo ratings yet
- Sergio's SketchDocument1 pageSergio's SketchBastian HildnerNo ratings yet
- Holden 05Document52 pagesHolden 05Ali Mert InalNo ratings yet
- Retrato - Pedro MartinsDocument2 pagesRetrato - Pedro MartinsMartín Dalmasso MolasNo ratings yet
- Xercise: R Ij 1 Ij 2 IjDocument4 pagesXercise: R Ij 1 Ij 2 IjAlexander Franco CastrillonNo ratings yet
- 04 Hoguas - Credit Risk Procedures - 0 PDFDocument19 pages04 Hoguas - Credit Risk Procedures - 0 PDFMazen AlbsharaNo ratings yet
- AssignmentDocument3 pagesAssignmentSibte HassanNo ratings yet
- Slides Multivariate Calculus Wima 2018Document27 pagesSlides Multivariate Calculus Wima 2018MilanAdzicNo ratings yet
- SC Research Flash Note - May 2021 InflationDocument2 pagesSC Research Flash Note - May 2021 InflationDan HathurusingheNo ratings yet
- Valseana - Sergio AssadDocument3 pagesValseana - Sergio AssadIgor Magalhães Rodrigues100% (4)
- Shuffle BluesDocument1 pageShuffle BluesXianlin SuNo ratings yet
- Esperando NacerDocument2 pagesEsperando NacerLiliana MadonnaNo ratings yet
- Chapter 4Document24 pagesChapter 4Chidananda GuptasNo ratings yet
- Tab InsensatezDocument3 pagesTab InsensatezMichely CardosoNo ratings yet
- Isko Laga Dala Toh Life JhingalalaDocument48 pagesIsko Laga Dala Toh Life JhingalalaSanket DaveNo ratings yet
- Data 1 Histogram Data 2 Histogram: Data 1 Cumulative Distributions Data 2 Cumulative DistributionsDocument2 pagesData 1 Histogram Data 2 Histogram: Data 1 Cumulative Distributions Data 2 Cumulative DistributionsKhalil KhdourNo ratings yet
- Barril B1 CifraDocument2 pagesBarril B1 CifraJose Ramon TalaveraNo ratings yet
- Blues en Mi - 2Document3 pagesBlues en Mi - 2Gerard RousseauNo ratings yet
- As It Was MelodyDocument1 pageAs It Was Melodychristos kriebardisNo ratings yet
- User Guide For The Item Analysis Template © Balajadia 2014: General DirectionsDocument7 pagesUser Guide For The Item Analysis Template © Balajadia 2014: General DirectionsJobert de JesusNo ratings yet
- West Coast TABDocument1 pageWest Coast TABAna FernandesNo ratings yet
- (Free Scores - Com) Powell Baden Retrato Brasileiro 97634Document2 pages(Free Scores - Com) Powell Baden Retrato Brasileiro 97634Antonio UrtiNo ratings yet
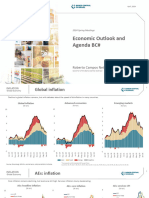
- Economic Outlook and Agenda BC#: Roberto Campos NetoDocument41 pagesEconomic Outlook and Agenda BC#: Roberto Campos Netoandre.torresNo ratings yet
- 1.3.3.the Relationship of Mental Expressions in Terms ofDocument10 pages1.3.3.the Relationship of Mental Expressions in Terms ofDr.j.sakthi Varshini 103No ratings yet
- 2016 Siegler ContinuityDocument6 pages2016 Siegler ContinuityFrancis Thomas Pantaleta LimNo ratings yet
- Helen Longino, InterviewDocument8 pagesHelen Longino, Interviewakansrl100% (1)
- AIML UNit-1Document42 pagesAIML UNit-1harish9No ratings yet
- Lev Vygotsky's Social Development TheoryDocument24 pagesLev Vygotsky's Social Development TheoryNazlınur GöktürkNo ratings yet
- PerceptionDocument2 pagesPerceptionVenkatesh TeluNo ratings yet
- History and Philosophy in Science TeachingDocument392 pagesHistory and Philosophy in Science TeachingCitra OktasariNo ratings yet
- Module 3 CT AssignmentDocument3 pagesModule 3 CT Assignmentapi-446537912No ratings yet
- Set A: Murcia National High SchoolDocument3 pagesSet A: Murcia National High SchoolRazel S. MarañonNo ratings yet
- Chemistry 201 Phase Change Role PlayDocument6 pagesChemistry 201 Phase Change Role Playapi-295429241No ratings yet
- Language Acquisition Mind MapDocument1 pageLanguage Acquisition Mind MaphamizahNo ratings yet
- Final Project Allison LybargerDocument9 pagesFinal Project Allison Lybargerapi-252180806No ratings yet
- Learners With Difficulty in Basic Learning and Applying Knowledge Grade 6 and SHSDocument74 pagesLearners With Difficulty in Basic Learning and Applying Knowledge Grade 6 and SHSChristian AguirreNo ratings yet
- DLL Week 7Document4 pagesDLL Week 7Maye S. AranetaNo ratings yet
- SKVT1213 - A1.3 - Due Week 7Document3 pagesSKVT1213 - A1.3 - Due Week 7Uyun AhmadNo ratings yet
- What Is Psychological First Aid?Document4 pagesWhat Is Psychological First Aid?Jianica SalesNo ratings yet
- Giao An Thi Diem 7 HK IDocument330 pagesGiao An Thi Diem 7 HK Itae kimNo ratings yet
- Delft Design GuideDocument10 pagesDelft Design GuideMostafa Abd el-azizNo ratings yet
- Does The Competition Can Give Negative Impact For The Children MentalDocument2 pagesDoes The Competition Can Give Negative Impact For The Children MentalnanaNo ratings yet
- Aveva PID Diagram Process Design Ensuring Consistency Between A Piping Instrumentation Diagram 3D Model Throiugh Aveva PID Diagram PDFDocument136 pagesAveva PID Diagram Process Design Ensuring Consistency Between A Piping Instrumentation Diagram 3D Model Throiugh Aveva PID Diagram PDFbalajivangaruNo ratings yet
- Authentic LearningDocument52 pagesAuthentic Learningsmvuksie100% (1)
- How Does Nature Nurture Creativity?Document20 pagesHow Does Nature Nurture Creativity?Anonymous vWJ2rNvPNo ratings yet
- Kindergarten Lesson Plans 1Document5 pagesKindergarten Lesson Plans 1api-357731269No ratings yet
- Qualitative & Quantitative ResearchDocument4 pagesQualitative & Quantitative Researchsajid bhattiNo ratings yet
- 10th 2nd Lang Eng 1Document31 pages10th 2nd Lang Eng 1Pubg KeliyeNo ratings yet
- Subject Verb AgreementDocument1 pageSubject Verb Agreementstellar.eduNo ratings yet
- ITIL V3 Mock Exam Day 2Document6 pagesITIL V3 Mock Exam Day 2Kiel Edz77% (13)
- Case StudyDocument1 pageCase StudyKhyati MehtaNo ratings yet
- Individual Assignment #4 (Case Study)Document2 pagesIndividual Assignment #4 (Case Study)John ParrasNo ratings yet
- A Detailed Lesson Plan InMath 7Document7 pagesA Detailed Lesson Plan InMath 7Ellen Catle100% (2)