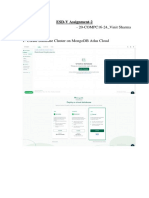
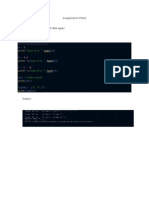
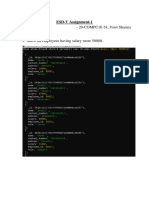
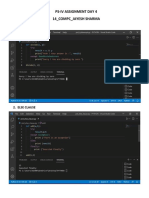
You might also like
- Building Expert System in PrologDocument45 pagesBuilding Expert System in PrologjayasutejaNo ratings yet
- Zero To Mastery In Cybersecurity- Become Zero To Hero In Cybersecurity, This Cybersecurity Book Covers A-Z Cybersecurity Concepts, 2022 Latest EditionFrom EverandZero To Mastery In Cybersecurity- Become Zero To Hero In Cybersecurity, This Cybersecurity Book Covers A-Z Cybersecurity Concepts, 2022 Latest EditionNo ratings yet
- Expert System ArchitectureDocument5 pagesExpert System ArchitectureaadafullNo ratings yet
- Artificial Intelligence and Expert SystemsDocument10 pagesArtificial Intelligence and Expert SystemsManish Kumar KashyapNo ratings yet
- Artificial Intelligence and Expert Systems: Submitted byDocument10 pagesArtificial Intelligence and Expert Systems: Submitted byRoshani KamathNo ratings yet
- AI UNIT 4 Lecture 2Document7 pagesAI UNIT 4 Lecture 2Sunil NagarNo ratings yet
- ES and neural network - AI techniques comparedDocument16 pagesES and neural network - AI techniques comparedBshwas TeamllcenaNo ratings yet
- What Is Expert System ?Document26 pagesWhat Is Expert System ?moharajNo ratings yet
- SB MirzaDocument31 pagesSB MirzaShaher Bano MirzaNo ratings yet
- Unit - 5Document8 pagesUnit - 5skraoNo ratings yet
- AI Expert Systems ChapterDocument18 pagesAI Expert Systems ChapterAnonymous EImkf6RGdQNo ratings yet
- InTech-Intelligent Problem Solvers in Education Design Method and ApplicationsDocument28 pagesInTech-Intelligent Problem Solvers in Education Design Method and ApplicationsLê Nhật NguyênNo ratings yet
- Expert System: Artificial IntelligenceDocument7 pagesExpert System: Artificial IntelligencesweetwaqarNo ratings yet
- Expert System Development in 40 CharactersDocument31 pagesExpert System Development in 40 CharactersKavya MistryNo ratings yet
- Expert SystemDocument65 pagesExpert SystemBharathi ArikerieNo ratings yet
- Class+5+ +Lecture+Note.Document33 pagesClass+5+ +Lecture+Note.harvardcasestudiesNo ratings yet
- MBATech Unit7 ExpertsystemDocument30 pagesMBATech Unit7 ExpertsystemAditya IyerNo ratings yet
- Presentation 1Document8 pagesPresentation 1Tathagata DeyNo ratings yet
- NLP Techniques for Information ExtractionDocument25 pagesNLP Techniques for Information ExtractionTouseef sultanNo ratings yet
- ADS-UNIT-1Document36 pagesADS-UNIT-1mohamudsk007No ratings yet
- AI Mid Sem AssesmentDocument4 pagesAI Mid Sem AssesmentAiman AfiqNo ratings yet
- Chapter 1-Introduction To SADDocument21 pagesChapter 1-Introduction To SADYohans BrhanuNo ratings yet
- Structure of SystemDocument10 pagesStructure of SystemthangdalatNo ratings yet
- AI Unit 3Document85 pagesAI Unit 3barkmeow2069No ratings yet
- Expert SystemDocument47 pagesExpert SystemBin Zhang100% (1)
- AI Mod-4Document5 pagesAI Mod-4Shashank chowdary DaripineniNo ratings yet
- AI Mod-4Document5 pagesAI Mod-4Shashank chowdary DaripineniNo ratings yet
- Intelligent Problem Solvers in Education DesignDocument25 pagesIntelligent Problem Solvers in Education DesignLinh Huỳnh Lê NhậtNo ratings yet
- AI Session 3 SlidesDocument30 pagesAI Session 3 SlidesShame BopeNo ratings yet
- System Analysis and DesignDocument90 pagesSystem Analysis and Designhanima5No ratings yet
- 3.2 Expert SystemsDocument4 pages3.2 Expert SystemsFardeen AzharNo ratings yet
- Intelligent Techniques AssignmentDocument7 pagesIntelligent Techniques AssignmentMano_Bili89No ratings yet
- ReportDocument69 pagesReportAditya Raj SahNo ratings yet
- Expert SystemsDocument35 pagesExpert SystemsRammah YusufNo ratings yet
- An Agile Process Model For Developing Diagnostic Knowledge SystemsDocument5 pagesAn Agile Process Model For Developing Diagnostic Knowledge SystemsshanthidhivyaNo ratings yet
- Machine Learning: Dr. R. B. Chadge YCCE, NagpurDocument24 pagesMachine Learning: Dr. R. B. Chadge YCCE, Nagpursuraj meshramNo ratings yet
- PAPER PUBLISH - EditedDocument9 pagesPAPER PUBLISH - EditedKranti SriNo ratings yet
- CSC112 Introduction to Algorithms and Data StructuresDocument29 pagesCSC112 Introduction to Algorithms and Data StructuresNoman AliNo ratings yet
- Super LibraryDocument14 pagesSuper Libraryursa sayeedNo ratings yet
- Big Data AnalyticsDocument12 pagesBig Data Analyticsurooj fatimaNo ratings yet
- Understanding System Development Methodologies in 40 CharactersDocument168 pagesUnderstanding System Development Methodologies in 40 CharactersKamaluddin Azmi100% (1)
- Expert SystemDocument9 pagesExpert SystemVatsal ChangoiwalaNo ratings yet
- Accounting Expert SystemsDocument5 pagesAccounting Expert SystemsCatalin FilipNo ratings yet
- (IJCST-V5I6P21) :babasaheb .S. Satpute, Dr. Raghav YadavDocument4 pages(IJCST-V5I6P21) :babasaheb .S. Satpute, Dr. Raghav YadavEighthSenseGroupNo ratings yet
- AI and ES Nowledge Base SystemsDocument11 pagesAI and ES Nowledge Base Systemsanshulcool1985No ratings yet
- Identifing Software Bugs or Not Using SMLT ModelDocument34 pagesIdentifing Software Bugs or Not Using SMLT ModelSANJAY S (RA2032241010114)No ratings yet
- Online Job PortalDocument126 pagesOnline Job PortalMegha SahuNo ratings yet
- Presentation 1Document8 pagesPresentation 1Tathagata DeyNo ratings yet
- Expert Systems: Representing Domain Knowledge and ReasoningDocument22 pagesExpert Systems: Representing Domain Knowledge and ReasoningAMI CHARADAVANo ratings yet
- Machine LearningDocument11 pagesMachine LearningTonpai DolnapaNo ratings yet
- Lec1 IntroDocument24 pagesLec1 Introrachelortiz510No ratings yet
- Define and Dvvvviscuss On Expert SystemDocument5 pagesDefine and Dvvvviscuss On Expert SystemWaliur RahmanNo ratings yet
- EXPERT SYSTEMS BACHELOR'S THESIS ON COMPONENTS, METHODOLOGY AND APPLICATIONSDocument7 pagesEXPERT SYSTEMS BACHELOR'S THESIS ON COMPONENTS, METHODOLOGY AND APPLICATIONSilanohs atpugNo ratings yet
- HTML Forms Built On User Trait DetectionDocument16 pagesHTML Forms Built On User Trait DetectionsaikiranNo ratings yet
- Intelligent Problem Solvers in Education: Design Method and ApplicationsDocument30 pagesIntelligent Problem Solvers in Education: Design Method and ApplicationsthangdalatNo ratings yet
- Top Data Science Interview Questions and Answers in 2023 PDFDocument14 pagesTop Data Science Interview Questions and Answers in 2023 PDFChristine Cao100% (1)
- Lesson 6 What Is ML, Types of Machine Learning. in Data Science.Document18 pagesLesson 6 What Is ML, Types of Machine Learning. in Data Science.Victor AjraebrillNo ratings yet
- World's Largest Science, Technology & Medicine Open Access Book PublisherDocument32 pagesWorld's Largest Science, Technology & Medicine Open Access Book PublisherRajeshNo ratings yet
- ML - With - Python - TaggedDocument43 pagesML - With - Python - TaggedAnthony Corneau100% (1)
- 14 16 ReportDocument4 pages14 16 ReportXyzNo ratings yet
- Css Ie Report JayeshDocument11 pagesCss Ie Report JayeshXyzNo ratings yet
- Hardik Singh's ResumeDocument11 pagesHardik Singh's ResumeXyzNo ratings yet
- RBL Group C2 Changes Topic to "T&P PortalDocument1 pageRBL Group C2 Changes Topic to "T&P PortalXyzNo ratings yet
- SPCCDocument11 pagesSPCCXyzNo ratings yet
- 5 MarkersDocument17 pages5 MarkersXyzNo ratings yet
- 20-Compc16-24 - Vinit Sharma - Fa-2Document10 pages20-Compc16-24 - Vinit Sharma - Fa-2XyzNo ratings yet
- Assignment2-PS (IV) : If Else: Print "Hello World" If Is Greater ThanDocument10 pagesAssignment2-PS (IV) : If Else: Print "Hello World" If Is Greater ThanXyzNo ratings yet
- 68 - Comp - C - Day 3 AssignmentDocument4 pages68 - Comp - C - Day 3 AssignmentXyzNo ratings yet
- Assignment1-PS(IV)-DataTypesOperatorsArraysStringsDocument5 pagesAssignment1-PS(IV)-DataTypesOperatorsArraysStringsXyzNo ratings yet
- 20 Compc16 24 Vinit Sharma Fa 1Document2 pages20 Compc16 24 Vinit Sharma Fa 1XyzNo ratings yet
- Rigveda Finder.Document481 pagesRigveda Finder.Marco PassavantiNo ratings yet
- NPTEL Courses - Final Course List (Jan - April 2022)Document15 pagesNPTEL Courses - Final Course List (Jan - April 2022)XyzNo ratings yet
- Ps-Iv Assignment Day 4 14 - Compc - Jayesh Sharma: 1. Try and ExceptDocument3 pagesPs-Iv Assignment Day 4 14 - Compc - Jayesh Sharma: 1. Try and ExceptXyzNo ratings yet
- 101 Zhang 2015a Defense Mechanisms and Thinking StylesDocument19 pages101 Zhang 2015a Defense Mechanisms and Thinking StylesJasar KhanNo ratings yet
- JHS English Composition: What's in This Class?Document3 pagesJHS English Composition: What's in This Class?Charles AbelNo ratings yet
- RRLDocument2 pagesRRLIan FelizardoNo ratings yet
- Iep Case StudyDocument31 pagesIep Case Studyapi-273265436No ratings yet
- References: Prepared By: Sherry Lene S. GonzagaDocument3 pagesReferences: Prepared By: Sherry Lene S. GonzagaSherry GonzagaNo ratings yet
- Lesson Plan English Year 3Document2 pagesLesson Plan English Year 3Zahirah Dzanimi100% (1)
- DISS Week 3 MarforiGarciaDocument13 pagesDISS Week 3 MarforiGarciarhodora d. tamayoNo ratings yet
- An Analysis On Students' Difficulties in SpeakingDocument6 pagesAn Analysis On Students' Difficulties in SpeakingLưu Hoàng QuốcNo ratings yet
- Department of Education: Epublic of The PhilippineDocument2 pagesDepartment of Education: Epublic of The PhilippineChriztine Marie AsinjoNo ratings yet
- Const ManagementDocument13 pagesConst ManagementAbuBakerNo ratings yet
- 0838 Primary Global Perspectives Curriculum Framework PDFDocument37 pages0838 Primary Global Perspectives Curriculum Framework PDFMritheya Rao100% (5)
- Rmip 21rmi56 Module 2Document25 pagesRmip 21rmi56 Module 2Aimi SubliminalsNo ratings yet
- Evaluating SourcesDocument30 pagesEvaluating SourcesAliya MojicaNo ratings yet
- Grade 8 DLL PE Quarter 1Document3 pagesGrade 8 DLL PE Quarter 1Gil Anne Marie TamayoNo ratings yet
- Samantha Craft's Unofficial Checklist - Females and Autism - Aspergers - The Art of AutismDocument11 pagesSamantha Craft's Unofficial Checklist - Females and Autism - Aspergers - The Art of Autismmiagiles07No ratings yet
- Workshop 1 Supervisory Roles in Facility Work ManagementDocument76 pagesWorkshop 1 Supervisory Roles in Facility Work ManagementAlejandro UrbinaNo ratings yet
- Student Satisfaction On The Art Club of SSSNHS Group 4Document46 pagesStudent Satisfaction On The Art Club of SSSNHS Group 4spacekattNo ratings yet
- Analyzing Patterns of Development in WritingDocument3 pagesAnalyzing Patterns of Development in WritingRobert FrioNo ratings yet
- Week 7 - Module 7.1 LeadershipDocument18 pagesWeek 7 - Module 7.1 LeadershipMichel BanvoNo ratings yet
- Assessment To The Proficiency of Freshmen Bsit Students in Oral and Written Skills in English at City of Malabon UniversityDocument22 pagesAssessment To The Proficiency of Freshmen Bsit Students in Oral and Written Skills in English at City of Malabon Universitymichael.chavez.1851No ratings yet
- Communicative Language TeachingDocument4 pagesCommunicative Language TeachingRuri Rohmatin AnanissaNo ratings yet
- Assignment 3b Detailed Assessment Plan1Document2 pagesAssignment 3b Detailed Assessment Plan1api-272547134No ratings yet
- Advertising ResearchDocument26 pagesAdvertising ResearchAfnas K HassanNo ratings yet
- 2015.16 2 EN ProblemsDocument4 pages2015.16 2 EN ProblemschampionNo ratings yet
- TrendsDocument35 pagesTrendsMary Audie D. CariagaNo ratings yet
- The importance of effective communication in business managementDocument19 pagesThe importance of effective communication in business managementPrincessqueenNo ratings yet
- ADE 4 Social Work Theories and Practice ModelsDocument4 pagesADE 4 Social Work Theories and Practice ModelsOkeke IsaacNo ratings yet
- Trust - The Foundation Value in RelationshipDocument8 pagesTrust - The Foundation Value in Relationshipanmol6237No ratings yet
- Lesson 1 - HookDocument2 pagesLesson 1 - Hookapi-253272001No ratings yet
- Preschool Physical Development Photo EssayDocument3 pagesPreschool Physical Development Photo EssaycheskaNo ratings yet
- A Mathematician's Lament: How School Cheats Us Out of Our Most Fascinating and Imaginative Art FormFrom EverandA Mathematician's Lament: How School Cheats Us Out of Our Most Fascinating and Imaginative Art FormRating: 5 out of 5 stars5/5 (5)
- Build a Mathematical Mind - Even If You Think You Can't Have One: Become a Pattern Detective. Boost Your Critical and Logical Thinking Skills.From EverandBuild a Mathematical Mind - Even If You Think You Can't Have One: Become a Pattern Detective. Boost Your Critical and Logical Thinking Skills.Rating: 5 out of 5 stars5/5 (1)
- Mathematical Mindsets: Unleashing Students' Potential through Creative Math, Inspiring Messages and Innovative TeachingFrom EverandMathematical Mindsets: Unleashing Students' Potential through Creative Math, Inspiring Messages and Innovative TeachingRating: 4.5 out of 5 stars4.5/5 (21)
- Quantum Physics: A Beginners Guide to How Quantum Physics Affects Everything around UsFrom EverandQuantum Physics: A Beginners Guide to How Quantum Physics Affects Everything around UsRating: 4.5 out of 5 stars4.5/5 (3)
- Mental Math Secrets - How To Be a Human CalculatorFrom EverandMental Math Secrets - How To Be a Human CalculatorRating: 5 out of 5 stars5/5 (3)
- A Mathematician's Lament: How School Cheats Us Out of Our Most Fascinating and Imaginative Art FormFrom EverandA Mathematician's Lament: How School Cheats Us Out of Our Most Fascinating and Imaginative Art FormRating: 4.5 out of 5 stars4.5/5 (20)
- Making and Tinkering With STEM: Solving Design Challenges With Young ChildrenFrom EverandMaking and Tinkering With STEM: Solving Design Challenges With Young ChildrenNo ratings yet
- Basic Math & Pre-Algebra Workbook For Dummies with Online PracticeFrom EverandBasic Math & Pre-Algebra Workbook For Dummies with Online PracticeRating: 4 out of 5 stars4/5 (2)
- Strategies for Problem Solving: Equip Kids to Solve Math Problems With ConfidenceFrom EverandStrategies for Problem Solving: Equip Kids to Solve Math Problems With ConfidenceNo ratings yet
- A-level Maths Revision: Cheeky Revision ShortcutsFrom EverandA-level Maths Revision: Cheeky Revision ShortcutsRating: 3.5 out of 5 stars3.5/5 (8)
- Fluent in 3 Months: How Anyone at Any Age Can Learn to Speak Any Language from Anywhere in the WorldFrom EverandFluent in 3 Months: How Anyone at Any Age Can Learn to Speak Any Language from Anywhere in the WorldRating: 3 out of 5 stars3/5 (79)
- Calculus Workbook For Dummies with Online PracticeFrom EverandCalculus Workbook For Dummies with Online PracticeRating: 3.5 out of 5 stars3.5/5 (8)
- Limitless Mind: Learn, Lead, and Live Without BarriersFrom EverandLimitless Mind: Learn, Lead, and Live Without BarriersRating: 4 out of 5 stars4/5 (6)
- How Math Explains the World: A Guide to the Power of Numbers, from Car Repair to Modern PhysicsFrom EverandHow Math Explains the World: A Guide to the Power of Numbers, from Car Repair to Modern PhysicsRating: 3.5 out of 5 stars3.5/5 (9)