You might also like
- Hypothesis TestingDocument58 pagesHypothesis TestingkartikharishNo ratings yet
- Time Series Analysis by State Space MethodsDocument369 pagesTime Series Analysis by State Space Methodsumarsabo100% (6)
- Statistical EstimationDocument37 pagesStatistical EstimationAmanuel MaruNo ratings yet
- Test of HypothesisDocument85 pagesTest of HypothesisJyoti Prasad Sahu64% (11)
- Intro of Hypothesis TestingDocument66 pagesIntro of Hypothesis TestingDharyl BallartaNo ratings yet
- Elements of Econometrics by Jan Kmenta ZDocument808 pagesElements of Econometrics by Jan Kmenta ZJeetu Sharma0% (1)
- The Most Important Probability Distribution in StatisticsDocument57 pagesThe Most Important Probability Distribution in StatisticsMissy CabangalNo ratings yet
- Parametric Vs Non Parametric StatisticsDocument12 pagesParametric Vs Non Parametric StatisticsiampuneiteNo ratings yet
- JAMOVI AND Basic StatisticsDocument28 pagesJAMOVI AND Basic StatisticsKyle RonquilloNo ratings yet
- Analyzing and Interpreting Quantitative DataDocument19 pagesAnalyzing and Interpreting Quantitative DataBrillian Zainun FaizNo ratings yet
- Fernando, Logit Tobit Probit March 2011Document19 pagesFernando, Logit Tobit Probit March 2011Trieu Giang BuiNo ratings yet
- Modern Marketing Research Concepts Methods and Cases 2nd Edition Feinberg Solutions ManualDocument38 pagesModern Marketing Research Concepts Methods and Cases 2nd Edition Feinberg Solutions Manualjclarku7100% (12)
- Lecture Notes ON Parametric & Non-Parametric Tests FOR Social Scientists/ Participants OF Research Metodology Workshop Bbau, LucknowDocument19 pagesLecture Notes ON Parametric & Non-Parametric Tests FOR Social Scientists/ Participants OF Research Metodology Workshop Bbau, LucknowDiwakar RajputNo ratings yet
- 3 - Test of Hypothesis (Part - 1) PDFDocument45 pages3 - Test of Hypothesis (Part - 1) PDFhijab100% (1)
- SM 38Document19 pagesSM 38ayushNo ratings yet
- 6 Inferential Statistics VI - May 12 2014Document40 pages6 Inferential Statistics VI - May 12 2014Bijay ThapaNo ratings yet
- Advanced Educational Statistics - Edu 901CDocument12 pagesAdvanced Educational Statistics - Edu 901CSolomon kiplimoNo ratings yet
- AEB03 - Inferential Statitsitics (FE)Document54 pagesAEB03 - Inferential Statitsitics (FE)arman kNo ratings yet
- MKTG 4110 Class 4Document10 pagesMKTG 4110 Class 4JSNo ratings yet
- A Brief (Very Brief) Overview of Biostatistics: Jody Kreiman, PHD Bureau of Glottal AffairsDocument56 pagesA Brief (Very Brief) Overview of Biostatistics: Jody Kreiman, PHD Bureau of Glottal AffairsjamesteryNo ratings yet
- Hypothesis TestingDocument45 pagesHypothesis TestingHerman R. SuwarmanNo ratings yet
- B.Tech, Cse-B, V Sem, Iiird Year Cs-503: Data Analytics Introduction To Inferential StatisticsDocument15 pagesB.Tech, Cse-B, V Sem, Iiird Year Cs-503: Data Analytics Introduction To Inferential StatisticsHarry PotterNo ratings yet
- Combine PDFDocument52 pagesCombine PDFcojeneNo ratings yet
- Hypothesis TestingDocument86 pagesHypothesis TestingMohammed AdusNo ratings yet
- Hypothesis Testing 1Document118 pagesHypothesis Testing 1sheelajeevakumar100% (1)
- IB372 FA10 Lab01 Intro Statistics PresentationDocument75 pagesIB372 FA10 Lab01 Intro Statistics Presentationsarfaraz100% (1)
- Inferential Statistics PART 1 PresentationDocument28 pagesInferential Statistics PART 1 PresentationwqlqqNo ratings yet
- Hypothesis Testing: Applied Statistics - Lesson 8Document6 pagesHypothesis Testing: Applied Statistics - Lesson 8PHO AntNo ratings yet
- Hypothesis Testing For One Population Parameter - SamplesDocument68 pagesHypothesis Testing For One Population Parameter - SamplesMary Grace Caguioa AgasNo ratings yet
- Analysis of Quantitative Data - 1Document12 pagesAnalysis of Quantitative Data - 1Eid IbrahimNo ratings yet
- L7 Hypothesis TestingDocument59 pagesL7 Hypothesis Testingمصطفى سامي شهيد لفتهNo ratings yet
- 8.hypo Testing....Document44 pages8.hypo Testing....ephremtigabie7No ratings yet
- Biostatistics FinalDocument7 pagesBiostatistics Finalmohammad nomanNo ratings yet
- Master of Business Administration - MBA Semester 3 MB0050 Research Methodology Assignment Set-1Document9 pagesMaster of Business Administration - MBA Semester 3 MB0050 Research Methodology Assignment Set-1Abhishek JainNo ratings yet
- A - Statistical Versus Practical SignificanceDocument12 pagesA - Statistical Versus Practical SignificanceAbhijeet VirdheNo ratings yet
- Testing of Hypothesis: Business Mathematics and Statistics MBA (FT) IDocument18 pagesTesting of Hypothesis: Business Mathematics and Statistics MBA (FT) IAashish Kumar PrajapatiNo ratings yet
- Chapter 6Document16 pagesChapter 6Serenity ManaloNo ratings yet
- Introduction To Hypothesis and Its Concepts 87Document5 pagesIntroduction To Hypothesis and Its Concepts 87ttvignesuwarNo ratings yet
- Cheat Sheet Stats For Exam Cheat Sheet Stats For ExamDocument3 pagesCheat Sheet Stats For Exam Cheat Sheet Stats For ExamUrbi Roy BarmanNo ratings yet
- Testing of HypothesisDocument18 pagesTesting of HypothesisPavan DeshpandeNo ratings yet
- 6.2 Hypothesis Testing v1Document34 pages6.2 Hypothesis Testing v1Quỳnh Anh NguyễnNo ratings yet
- Module 4 Mathematics As A ToolDocument6 pagesModule 4 Mathematics As A ToolAron Lei Rait100% (1)
- Inferential Statistics: Basic ConceptsDocument45 pagesInferential Statistics: Basic ConceptsRhizhailNo ratings yet
- Week 1 - Hypothesis Testing - Part 1Document77 pagesWeek 1 - Hypothesis Testing - Part 1Desryadi Ilyas MohammadNo ratings yet
- Hypothesis Testing Theory-MunuDocument6 pagesHypothesis Testing Theory-MunukarishmabhayaNo ratings yet
- Master of Business Administration - MBA Semester 3 MB0034 Research Methodology - 3 Credits BKID: B0800 Assignment Set-1Document17 pagesMaster of Business Administration - MBA Semester 3 MB0034 Research Methodology - 3 Credits BKID: B0800 Assignment Set-1Vishal HandaragalNo ratings yet
- NOTES On UNIT 3 HypothesisDocument3 pagesNOTES On UNIT 3 HypothesispriyankashrivatavaNo ratings yet
- RM Study Material - Unit 4Document66 pagesRM Study Material - Unit 4Nidhip ShahNo ratings yet
- Sample Size Calculation & SoftwareDocument26 pagesSample Size Calculation & SoftwarechelseapasiahNo ratings yet
- Module 3a - Hypothesis Testing - Docx 1Document4 pagesModule 3a - Hypothesis Testing - Docx 1Sam Rae LimNo ratings yet
- Testing of Hypothesis: BY ArvindDocument20 pagesTesting of Hypothesis: BY ArvindAmar P BilungNo ratings yet
- Basic StatDocument35 pagesBasic StatTaddese GashawNo ratings yet
- WEEK15Document30 pagesWEEK15lieca Joy UayanNo ratings yet
- Topic 9 Hypothesis TestingDocument12 pagesTopic 9 Hypothesis TestingMariam HishamNo ratings yet
- 3.1 Hypothesis Testing and Sample Problems On Parametric TestsDocument35 pages3.1 Hypothesis Testing and Sample Problems On Parametric TestsCharlene FiguracionNo ratings yet
- محاضرة اولى احصاءDocument16 pagesمحاضرة اولى احصاءniiishaan97No ratings yet
- ESTADISTICA APLICADA - Elementos BásicosDocument30 pagesESTADISTICA APLICADA - Elementos BásicosMartha HuamanNo ratings yet
- 1.3 Type I Error Type II Error and Power PDFDocument11 pages1.3 Type I Error Type II Error and Power PDFSatish Kumar RawalNo ratings yet
- BRM 3 - 4-5Document9 pagesBRM 3 - 4-5harsh hariharnoNo ratings yet
- Formulatinghypotheses 110911135920 Phpapp02Document53 pagesFormulatinghypotheses 110911135920 Phpapp02میاں حسنین عالم گجرNo ratings yet
- Unit-4 Hypothesis - TestingDocument17 pagesUnit-4 Hypothesis - TestingA2 MotivationNo ratings yet
- Lesson 3 Hypothesis TestingDocument23 pagesLesson 3 Hypothesis TestingAmar Nath BabarNo ratings yet
- Recap of Basic StatisticsDocument12 pagesRecap of Basic StatisticsHarun RasheedNo ratings yet
- GSEMModellingusingStata PDFDocument97 pagesGSEMModellingusingStata PDFmarikum74No ratings yet
- Simple Linear RegressionDocument52 pagesSimple Linear RegressionTheGimhan123No ratings yet
- Analisa Data Analisa Univariat: StatisticsDocument11 pagesAnalisa Data Analisa Univariat: StatisticsyudikNo ratings yet
- 1bootstrap Control Charts in Monitoring Value at Risk in InsuranceDocument11 pages1bootstrap Control Charts in Monitoring Value at Risk in InsuranceRadia AbbasNo ratings yet
- Hypothesis Testing PSDocument2 pagesHypothesis Testing PSKristy Dela Peña0% (4)
- CS1B April 2019 ExamPaperDocument5 pagesCS1B April 2019 ExamPaperBRUME JAGBORONo ratings yet
- Amazon SageMakerDocument1,055 pagesAmazon SageMakerJim ShangNo ratings yet
- Judul: Hubungan Kadar HB Pada Donor Darah Yang Diperiksa Secara Langsung Dan Disimpan 2 Hari Uji Yang Digunakan: Uji T-DependentDocument18 pagesJudul: Hubungan Kadar HB Pada Donor Darah Yang Diperiksa Secara Langsung Dan Disimpan 2 Hari Uji Yang Digunakan: Uji T-DependentIlham PrasetyoNo ratings yet
- Ass1 mth513Document3 pagesAss1 mth513Muhammad Idrees0% (1)
- The Wilcoxon Rank-Sum Test: Example 1Document10 pagesThe Wilcoxon Rank-Sum Test: Example 1McNemarNo ratings yet
- Ashwin Russel Nadar MBA (IB) ADocument20 pagesAshwin Russel Nadar MBA (IB) AShubham BhutadaNo ratings yet
- wk06 IVDocument34 pageswk06 IVyingdong liuNo ratings yet
- Mann KendallDocument4 pagesMann KendallOm Prakash SahuNo ratings yet
- Prediction of Airline Ticket Price: Motivation Models DiagnosticsDocument1 pagePrediction of Airline Ticket Price: Motivation Models DiagnosticsQa SimNo ratings yet
- Lilliefors Van Soest's Test of NormalityDocument10 pagesLilliefors Van Soest's Test of Normalitydimitri_deliyianniNo ratings yet
- Silabus AACSB-S1 - Analitik Bisnis - Gasal 18-19Document5 pagesSilabus AACSB-S1 - Analitik Bisnis - Gasal 18-19Hadila Franciska StevanyNo ratings yet
- QTA InterpretationDocument17 pagesQTA InterpretationMuhammad HarisNo ratings yet
- Tugas Two-Way AnovaDocument7 pagesTugas Two-Way AnovaPurwita SariNo ratings yet
- Application of Econometrics in EconomicsDocument160 pagesApplication of Econometrics in EconomicsMayank ChaturvediNo ratings yet
- Adversity Quotient® As Mediating Variable To Depersonalization and Job Performance of Public Elementary School TeachersDocument22 pagesAdversity Quotient® As Mediating Variable To Depersonalization and Job Performance of Public Elementary School TeachersPsychology and Education: A Multidisciplinary JournalNo ratings yet
- Class 10 Individual Assignment (Solutions) : General InstructionsDocument10 pagesClass 10 Individual Assignment (Solutions) : General Instructionsnew rhondaldNo ratings yet
- Research MethodologyDocument58 pagesResearch MethodologyRab Nawaz100% (2)
- Copia de LD50 LC50 Probit AnalysisDocument15 pagesCopia de LD50 LC50 Probit AnalysisCarlos VelásquezNo ratings yet
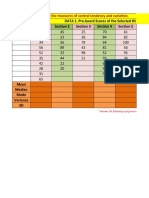
- DATA 1. Pre-Board Scores of The Selected BS Education Students (Per Section) Section 1 Section 2 Section 3 Section 4 Section 5Document10 pagesDATA 1. Pre-Board Scores of The Selected BS Education Students (Per Section) Section 1 Section 2 Section 3 Section 4 Section 5ariane galeno100% (1)
- Types of Significance TestsDocument3 pagesTypes of Significance TestsCyrell RelatorNo ratings yet
- 0801 HypothesisTestsDocument4 pages0801 HypothesisTestsshweta3547No ratings yet