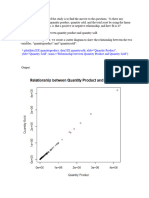
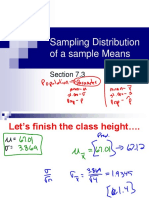
You might also like
- Basics of Hypothesis TestingDocument42 pagesBasics of Hypothesis TestingRandy NatalNo ratings yet
- Hypothesis TestingDocument36 pagesHypothesis Testinggilkirui2000No ratings yet
- Basics of Hypothesis TestingDocument36 pagesBasics of Hypothesis TestingVparikh ParikhNo ratings yet
- Basics of Hypothesis TestingDocument36 pagesBasics of Hypothesis TestingSam ValdezNo ratings yet
- Basics of Hypothesis TestingDocument36 pagesBasics of Hypothesis TestingSomanna M Research ScholarNo ratings yet
- Hypothesis TestingDocument36 pagesHypothesis TestingPallavi ShettigarNo ratings yet
- Basics of Hypothesis Testing: October 19Document36 pagesBasics of Hypothesis Testing: October 19yasit10No ratings yet
- Lecture BDS 8-23-24 PrintDocument11 pagesLecture BDS 8-23-24 PrintVictor Van der WelNo ratings yet
- Multiple Linear Regression: BIOST 515 January 15, 2004Document32 pagesMultiple Linear Regression: BIOST 515 January 15, 2004HazemIbrahimNo ratings yet
- SSC 201Document14 pagesSSC 201Adebayo OmojuwaNo ratings yet
- Hypothesis Tests, Confidence Intervals, and Bootstrapping: Business Statistics 41000Document54 pagesHypothesis Tests, Confidence Intervals, and Bootstrapping: Business Statistics 41000Manab ChetiaNo ratings yet
- Hypothesis TestingDocument41 pagesHypothesis TestingvisitantaiNo ratings yet
- Probability and Statistics Lecture-10Document30 pagesProbability and Statistics Lecture-10Khan ArishaNo ratings yet
- BS 10-11Document51 pagesBS 10-11AnshumanNo ratings yet
- A Detailed Lesson Plan in Mathematics in The Modern WorldDocument11 pagesA Detailed Lesson Plan in Mathematics in The Modern WorldChristian Philip LendioNo ratings yet
- Statistics 221 Summary of MaterialDocument5 pagesStatistics 221 Summary of MaterialJames McQueenNo ratings yet
- Advanced Statistics: Sign Test, Kolmogorov Test and Jarque-Bera TestDocument27 pagesAdvanced Statistics: Sign Test, Kolmogorov Test and Jarque-Bera TestJune SabatinNo ratings yet
- SB K49 Lecture8Document51 pagesSB K49 Lecture831231022978No ratings yet
- ) and Variance, So The Hypothesis, H: andDocument4 pages) and Variance, So The Hypothesis, H: andPi YaNo ratings yet
- COURSE 3 ECONOMETRICS 2009 Hypothesis TestingDocument37 pagesCOURSE 3 ECONOMETRICS 2009 Hypothesis TestingMihai StoicaNo ratings yet
- Hypothesis Testing For MeansDocument26 pagesHypothesis Testing For MeansAllan KomosiNo ratings yet
- Hypothesis+tests+involving+a+sample+mean+or+proportionDocument45 pagesHypothesis+tests+involving+a+sample+mean+or+proportionJerome Badillo100% (1)
- CH 04Document6 pagesCH 04JokoSusiloNo ratings yet
- Chat Openai Com Share 42b24a73 839b 4128 Ade9 7d8eed9e9533Document21 pagesChat Openai Com Share 42b24a73 839b 4128 Ade9 7d8eed9e9533NadhiyaNo ratings yet
- Stat 473-573 NotesDocument139 pagesStat 473-573 NotesArkadiusz Michael BarNo ratings yet
- Hypothesis Testing Complete SlidesDocument54 pagesHypothesis Testing Complete Slidesghabel11No ratings yet
- Statistical Tests Martin G 161131 V15 UPLOADDocument33 pagesStatistical Tests Martin G 161131 V15 UPLOADAnonymous F8kqoYNo ratings yet
- Final Term Biostatistics PDFDocument7 pagesFinal Term Biostatistics PDFSarmad HussainNo ratings yet
- Ist 214-Statictics Ii: Week 4: Binomial Distribution and Poison Distribution, Expected Values and VarianceDocument18 pagesIst 214-Statictics Ii: Week 4: Binomial Distribution and Poison Distribution, Expected Values and Variancemelekkbass10No ratings yet
- Homework #5: MA 402 Mathematics of Scientific Computing Due: Monday, September 27Document6 pagesHomework #5: MA 402 Mathematics of Scientific Computing Due: Monday, September 27ra100% (1)
- Chapt15 BPSDocument18 pagesChapt15 BPSHamsaveni ArulNo ratings yet
- Statistical Inference IIDocument3 pagesStatistical Inference IIshivam1992No ratings yet
- EC-512EC512 LecNotes Pt2Document29 pagesEC-512EC512 LecNotes Pt2Nagmani KumarNo ratings yet
- Eva Uation Methods 273 A Spring 09Document17 pagesEva Uation Methods 273 A Spring 09Lena MohameedNo ratings yet
- LogregDocument26 pagesLogregroy royNo ratings yet
- Midterm Review: Chapter 1 - Descriptive StatsDocument6 pagesMidterm Review: Chapter 1 - Descriptive StatsDenish ShresthaNo ratings yet
- Business Statistics 41000: Hypothesis TestingDocument34 pagesBusiness Statistics 41000: Hypothesis Testinguday369No ratings yet
- Testing of HypothesisDocument33 pagesTesting of HypothesisMA. PATRICIA MAYJANNA HARONo ratings yet
- Gary Chamberlain Econometric SDocument152 pagesGary Chamberlain Econometric SGabriel RoblesNo ratings yet
- Review of StatisticsDocument36 pagesReview of StatisticsJessica AngelinaNo ratings yet
- Hypothesis TestDocument57 pagesHypothesis TestVirgilio AbellanaNo ratings yet
- Introduction To Hypothesis Testing, Power Analysis and Sample Size CalculationsDocument8 pagesIntroduction To Hypothesis Testing, Power Analysis and Sample Size CalculationsFanny Sylvia C.No ratings yet
- Regression - MultipleDocument11 pagesRegression - Multiplelesta putriNo ratings yet
- Chapter 7: Hypothesis Testing With One SampleDocument6 pagesChapter 7: Hypothesis Testing With One SamplenootiNo ratings yet
- AP ECON 2500 Session 4Document18 pagesAP ECON 2500 Session 4Thuỳ DungNo ratings yet
- CE - 08A - Solutions: Hypothesis Testing: H: Suspect Is Innocent Vs H: Suspect Is Guilty, ThenDocument5 pagesCE - 08A - Solutions: Hypothesis Testing: H: Suspect Is Innocent Vs H: Suspect Is Guilty, ThennhiNo ratings yet
- Gsbiju MA202 3 3Document7 pagesGsbiju MA202 3 3Jivin George ThomasNo ratings yet
- Bootstrap Event Study Tests: Peter Westfall ISQS DeptDocument34 pagesBootstrap Event Study Tests: Peter Westfall ISQS DeptNekutenda PanasheNo ratings yet
- Chapter 3: Probability: ExperimentDocument12 pagesChapter 3: Probability: Experimentnilesh bhojaniNo ratings yet
- MIT18 05S14 Reading18Document8 pagesMIT18 05S14 Reading18ThiruNo ratings yet
- Simple RegressionDocument35 pagesSimple RegressionHimanshu JainNo ratings yet
- Bes Ex5Document13 pagesBes Ex5Nhi Phạm Trần YếnNo ratings yet
- ScribeDocument9 pagesScriberatesNo ratings yet
- 1 DiscreteDistribution2018Document75 pages1 DiscreteDistribution2018Anirudh RaghavNo ratings yet
- Ch10 4pageDocument30 pagesCh10 4pageAshish GuptaNo ratings yet
- Academic Coordinator: MathematicsDocument35 pagesAcademic Coordinator: MathematicsShahroz MemonNo ratings yet
- Solved Examples of Cramer Rao Lower BoundDocument6 pagesSolved Examples of Cramer Rao Lower BoundIk RamNo ratings yet
- A (Very) Brief Review of Statistical Inference: 1 Some PreliminariesDocument9 pagesA (Very) Brief Review of Statistical Inference: 1 Some PreliminarieswhatisnameNo ratings yet
- An Introduction To Statistical InferenceDocument33 pagesAn Introduction To Statistical InferenceWathz NawarathnaNo ratings yet
- Unit 3 Part 4Document8 pagesUnit 3 Part 4Girraj DohareNo ratings yet
- Python BasicsDocument15 pagesPython BasicsGirraj DohareNo ratings yet
- Frozen ch02Document42 pagesFrozen ch02Shashank AgarwalNo ratings yet
- 3pandas IpynbDocument26 pages3pandas IpynbGirraj DohareNo ratings yet
- Unit 1 Part 1Document18 pagesUnit 1 Part 1Girraj DohareNo ratings yet
- Unit 4 Part 1Document62 pagesUnit 4 Part 1Girraj DohareNo ratings yet
- Unit - V: Statistical Technique & DistributionDocument20 pagesUnit - V: Statistical Technique & DistributionGirraj DohareNo ratings yet
- Transmission Media CablesDocument32 pagesTransmission Media CablesharikshNo ratings yet
- Madhav Institute of Technology & Science, Gwalior Department of CSE & ITDocument16 pagesMadhav Institute of Technology & Science, Gwalior Department of CSE & ITGirraj DohareNo ratings yet
- Unit - 3 Digital Electronics - AllDocument121 pagesUnit - 3 Digital Electronics - AllGirraj DohareNo ratings yet
- Network Layer: The Control Plane: Computer Networking: A Top Down ApproachDocument102 pagesNetwork Layer: The Control Plane: Computer Networking: A Top Down ApproachGirraj DohareNo ratings yet
- Unit 2 Digital ElectronicsDocument37 pagesUnit 2 Digital ElectronicsGirraj DohareNo ratings yet
- ch1 v1Document22 pagesch1 v1gunaNo ratings yet
- Unit 1 Part 2Document85 pagesUnit 1 Part 2Girraj DohareNo ratings yet
- Unit 5 - Operating System - WWW - Rgpvnotes.inDocument27 pagesUnit 5 - Operating System - WWW - Rgpvnotes.inGirraj DohareNo ratings yet
- UNIT - 2 - MaterialDocument252 pagesUNIT - 2 - MaterialGirraj DohareNo ratings yet
- Introduction Of: Operating SystemDocument14 pagesIntroduction Of: Operating SystemGirraj DohareNo ratings yet
- Unit-I p3Document19 pagesUnit-I p3Girraj DohareNo ratings yet
- Unit 5 - Operating System - WWW - Rgpvnotes.inDocument27 pagesUnit 5 - Operating System - WWW - Rgpvnotes.inGirraj DohareNo ratings yet
- Digital Logic Design 230201 (Dc-1) : PPTS: Unit - 1Document50 pagesDigital Logic Design 230201 (Dc-1) : PPTS: Unit - 1Girraj DohareNo ratings yet
- CSO (160311) - Unit 1Document134 pagesCSO (160311) - Unit 1Girraj DohareNo ratings yet
- Unit 4 - Operating System - WWW - Rgpvnotes.inDocument23 pagesUnit 4 - Operating System - WWW - Rgpvnotes.inGirraj DohareNo ratings yet
- Unit 3 - Operating System - WWW - Rgpvnotes.inDocument38 pagesUnit 3 - Operating System - WWW - Rgpvnotes.inGirraj DohareNo ratings yet
- Unit 3 - Operating System - WWW - Rgpvnotes.inDocument38 pagesUnit 3 - Operating System - WWW - Rgpvnotes.inGirraj DohareNo ratings yet
- Unit 2 - Operating System - WWW - Rgpvnotes.inDocument15 pagesUnit 2 - Operating System - WWW - Rgpvnotes.inPRABHAMAN JYOT SINGHNo ratings yet
- Unit 4 - Operating System - WWW - Rgpvnotes.inDocument23 pagesUnit 4 - Operating System - WWW - Rgpvnotes.inGirraj DohareNo ratings yet
- Unit 1 - Operating System - WWW - Rgpvnotes.inDocument15 pagesUnit 1 - Operating System - WWW - Rgpvnotes.inSHIVAM KUMARNo ratings yet
- Unit 2 - Operating System - WWW - Rgpvnotes.inDocument15 pagesUnit 2 - Operating System - WWW - Rgpvnotes.inPRABHAMAN JYOT SINGHNo ratings yet
- Unit 1 - Operating System - WWW - Rgpvnotes.inDocument15 pagesUnit 1 - Operating System - WWW - Rgpvnotes.inSHIVAM KUMARNo ratings yet
- AREPENTIDODocument14 pagesAREPENTIDOPeachyNo ratings yet
- Kleinbaum Applied Regression Analysis and Other Multivariable Methods 3 Ed PDFDocument9 pagesKleinbaum Applied Regression Analysis and Other Multivariable Methods 3 Ed PDFGise Quintero0% (6)
- Biostat Lec MidtermsDocument9 pagesBiostat Lec MidtermsMerra VenzuelaNo ratings yet
- Lec2 PDFDocument8 pagesLec2 PDFJoy AJNo ratings yet
- Probability and Statistics For Engineers SyllabusDocument2 pagesProbability and Statistics For Engineers Syllabushakanshah0% (1)
- Chapter 1: Introduction To Statistics Sher Muhammad CHDocument4 pagesChapter 1: Introduction To Statistics Sher Muhammad CHKashif AsgharNo ratings yet
- INLADocument200 pagesINLAAnonymous MGG7vMINo ratings yet
- Aaoc ZC111Document13 pagesAaoc ZC111SatheeskumarNo ratings yet
- Worksheet 1 Refresher ANSWERSDocument8 pagesWorksheet 1 Refresher ANSWERSAndrea De JesusNo ratings yet
- Blocking FactorsDocument56 pagesBlocking Factorsdwiyuliani59100% (1)
- Lesson 2 - Central Limit TheoremDocument18 pagesLesson 2 - Central Limit TheoremJoke JokeNo ratings yet
- Lectures Stat 530Document59 pagesLectures Stat 530madhavNo ratings yet
- Solution Manual For Statistics For The Behavioral Sciences 10th EditionDocument37 pagesSolution Manual For Statistics For The Behavioral Sciences 10th Editionzedlenimenthy6kr100% (23)
- Types of Statistical DistributionsDocument34 pagesTypes of Statistical DistributionsGerónimo Maldonado-MartínezNo ratings yet
- BSA 2-4 Management Science Group Number 4 Chapter 11: Probability and Statistics Question Number 1Document3 pagesBSA 2-4 Management Science Group Number 4 Chapter 11: Probability and Statistics Question Number 1RoseanneNo ratings yet
- Jaw Aban Exercise Bab 2Document32 pagesJaw Aban Exercise Bab 2Camelia ApriaNo ratings yet
- Psychometric TraditionDocument11 pagesPsychometric TraditionBambang RubyNo ratings yet
- Probability and Statistical Tools: Basic Probability & Statistics Practice Questions. Session No. 4Document47 pagesProbability and Statistical Tools: Basic Probability & Statistics Practice Questions. Session No. 4Oscar ZAmoraNo ratings yet
- Research Methodology Marathi VersionDocument138 pagesResearch Methodology Marathi VersionHarsh Sangani71% (7)
- Student's T TestDocument12 pagesStudent's T TestZvonko TNo ratings yet
- T Test Chi-Square TestDocument26 pagesT Test Chi-Square TestAprajita SinghNo ratings yet
- Assignment 2Document6 pagesAssignment 2Ahmed HadadNo ratings yet
- Walpole 2012 Textpages For Topic4Document14 pagesWalpole 2012 Textpages For Topic4MULINDWA IBRANo ratings yet
- Bus 273-274 Chapter 6Document104 pagesBus 273-274 Chapter 6Onur A. KocabıyıkNo ratings yet
- Reading 6 Hypothesis TestingDocument32 pagesReading 6 Hypothesis TestingARPIT ARYANo ratings yet
- CHAPTER 6 Fundamentals of ProbabilityDocument78 pagesCHAPTER 6 Fundamentals of ProbabilityAyushi JangpangiNo ratings yet
- Convert KG-M To N-M - Conversion of Measurement UnitsDocument1 pageConvert KG-M To N-M - Conversion of Measurement Unitsnt48hnwkjjNo ratings yet
- 324 FinalDocument8 pages324 Finalkevin araujoNo ratings yet
- Navidi ch5Document34 pagesNavidi ch5binoNo ratings yet