You might also like
- CC TO BTC Method (Updated April 2021) : Written byDocument5 pagesCC TO BTC Method (Updated April 2021) : Written byJustin Booker75% (4)
- Additional Exercises for Vectors, Matrices, and Least SquaresDocument41 pagesAdditional Exercises for Vectors, Matrices, and Least SquaresAlejandro Patiño RiveraNo ratings yet
- 2.1.1.5 Lab - The World Runs On CircuitsDocument4 pages2.1.1.5 Lab - The World Runs On CircuitsJa'Mia MarineNo ratings yet
- KKT Optimization NotesDocument4 pagesKKT Optimization NotesNicholas ThigpenNo ratings yet
- University of Kerbala College of Engineering Petroleum Engineering Department Subject: Optimization Prof. Dr. Sabah Rasoul Al-JabiriDocument6 pagesUniversity of Kerbala College of Engineering Petroleum Engineering Department Subject: Optimization Prof. Dr. Sabah Rasoul Al-JabiriMohamed ModerNo ratings yet
- Maximum Minimum ProblemsDocument17 pagesMaximum Minimum ProblemsAsdf GhjklNo ratings yet
- Matlab - Introduction SlidesDocument52 pagesMatlab - Introduction SlidesFernanda ModkowskiNo ratings yet
- Quantitative Analysis for Management Decisions Assignment 2Document9 pagesQuantitative Analysis for Management Decisions Assignment 2mkdiNo ratings yet
- Commands in Matlab To Obtain The Solution of Ordinary Differential Equations (Ode) and System of OdesDocument21 pagesCommands in Matlab To Obtain The Solution of Ordinary Differential Equations (Ode) and System of Odesআসিফ রেজাNo ratings yet
- Business Statistics 6th Edition Levine Solutions Manual 1Document36 pagesBusiness Statistics 6th Edition Levine Solutions Manual 1stephaniebuckleynaordybfzq100% (22)
- Homework2 v1.0Document5 pagesHomework2 v1.0royadaneshi2001No ratings yet
- 6.867 Machine Learning: Mid-Term Exam October 13, 2004Document11 pages6.867 Machine Learning: Mid-Term Exam October 13, 2004Dickson SamwelNo ratings yet
- Intoduction To MATLABDocument32 pagesIntoduction To MATLABDania KhattakNo ratings yet
- Business Statistics 6th Edition Levine Solutions Manual 1Document29 pagesBusiness Statistics 6th Edition Levine Solutions Manual 1steven100% (31)
- Numerical Methods exercise solutionsDocument6 pagesNumerical Methods exercise solutionsMustafa GökkayaNo ratings yet
- Chap 5Document35 pagesChap 5Maurice PolitisNo ratings yet
- Lagrange Method of Interpolation - More Examples Industrial EngineeringDocument9 pagesLagrange Method of Interpolation - More Examples Industrial EngineeringAhsanNo ratings yet
- practical-7-regressionDocument5 pagespractical-7-regressionBijya Laxmi ManandharNo ratings yet
- Introduction To MatlabDocument34 pagesIntroduction To MatlabRasheed KibriaNo ratings yet
- NCERT Solutions Class 10 Maths Chapter 3 Pair of Linear Equations in Two VariablesDocument45 pagesNCERT Solutions Class 10 Maths Chapter 3 Pair of Linear Equations in Two VariablesBijendri DeviNo ratings yet
- Qba Lec 7 2023Document12 pagesQba Lec 7 2023ahmedgalalabdalbaath2003No ratings yet
- Ejercicios Matlab 1Document2 pagesEjercicios Matlab 1MissmatNo ratings yet
- Y X Sin y X F y X+:), ( Domain of F Is The Region in Which 1 1Document11 pagesY X Sin y X F y X+:), ( Domain of F Is The Region in Which 1 1Tayyab HusaainNo ratings yet
- Lab 1 Introduction To MATLABDocument35 pagesLab 1 Introduction To MATLABAbdul RehmanNo ratings yet
- Linear Programming Graphical ApproachDocument20 pagesLinear Programming Graphical ApproachVaughn MosesNo ratings yet
- Machine Learning 10-701 Final Exam May 5, 2015: Obvious Exceptions For Pacemakers and Hearing AidsDocument17 pagesMachine Learning 10-701 Final Exam May 5, 2015: Obvious Exceptions For Pacemakers and Hearing AidsNithinNo ratings yet
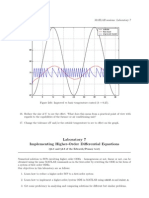
- MATLAB sessions: Laboratory 7 implementing higher-order differential equationsDocument7 pagesMATLAB sessions: Laboratory 7 implementing higher-order differential equationsjlbalbNo ratings yet
- Random Forests: N 1 N J X A I X A IDocument12 pagesRandom Forests: N 1 N J X A I X A IendaleNo ratings yet
- Linear Regression Model with Gradient DescentDocument52 pagesLinear Regression Model with Gradient DescentshinjoNo ratings yet
- Exercise Set - Week 1: Problem 1Document4 pagesExercise Set - Week 1: Problem 1Mark HelouNo ratings yet
- Week 2 Introduction To Linear Models - Revised - v1Document54 pagesWeek 2 Introduction To Linear Models - Revised - v1Ahmad HammoudehNo ratings yet
- Universidad Nacional Del Altiplano: Capitulo 0Document35 pagesUniversidad Nacional Del Altiplano: Capitulo 0Alexander ChinoNo ratings yet
- LIMITS OF MULTIVARIABLE FUNCTIONSDocument88 pagesLIMITS OF MULTIVARIABLE FUNCTIONSAditya Kumar SinghNo ratings yet
- MATHS INPUT-OUTPUT ANALYSISDocument2 pagesMATHS INPUT-OUTPUT ANALYSISTedNo ratings yet
- CS221 - Artificial Intelligence - Machine Learning - 3 Linear ClassificationDocument28 pagesCS221 - Artificial Intelligence - Machine Learning - 3 Linear ClassificationArdiansyah Mochamad NugrahaNo ratings yet
- Generating Random SignalsDocument56 pagesGenerating Random SignalssamfgNo ratings yet
- Linear Regression Class6Document15 pagesLinear Regression Class6Mohit SitlaniNo ratings yet
- Statistics For Managers Using Microsoft Excel 8th Edition Levine Solutions Manual 1Document36 pagesStatistics For Managers Using Microsoft Excel 8th Edition Levine Solutions Manual 1tylermorrisonaowkftpnzc100% (22)
- On-Line - Tutoriales (1, 2, 3, 4 y 5)Document22 pagesOn-Line - Tutoriales (1, 2, 3, 4 y 5)Antonio LMNo ratings yet
- Setting Up The Initial Tableau: Star All Rows Whose Corresponding Basic Solution Is NegativeDocument16 pagesSetting Up The Initial Tableau: Star All Rows Whose Corresponding Basic Solution Is NegativeManavNo ratings yet
- Lecture 1 Special Matrix OperationDocument13 pagesLecture 1 Special Matrix OperationChristopher Joshua MartinezNo ratings yet
- Perceptron TutorialDocument37 pagesPerceptron TutorialJohn CarterNo ratings yet
- Midterm ESE 500Document8 pagesMidterm ESE 500kaysriNo ratings yet
- Chapter Two Solution of Nonlinear EquationsDocument2 pagesChapter Two Solution of Nonlinear EquationsMohammed al-mashabiNo ratings yet
- Solving Differential Equations With MatlabDocument20 pagesSolving Differential Equations With MatlabYon Jairo MontoyaNo ratings yet
- MH2500 Exam 1516 SolnDocument7 pagesMH2500 Exam 1516 SolnPhoebe Peebee ZhouNo ratings yet
- Solutions Problem Set 1Document7 pagesSolutions Problem Set 1sanketjaiswalNo ratings yet
- Assignment No. 03 Perceptron learning rule_and_Adaline_ error surfaceDocument3 pagesAssignment No. 03 Perceptron learning rule_and_Adaline_ error surfacecheemashuja43No ratings yet
- Reviewing Exercises For Chapter 12Document6 pagesReviewing Exercises For Chapter 12richardbNo ratings yet
- Neural NetworksDocument31 pagesNeural NetworksCHEAT SHEETNo ratings yet
- Introduction To Matlab 2Document34 pagesIntroduction To Matlab 2Deepak Kumar SinghNo ratings yet
- Kernel SVM For Image ClassificationDocument20 pagesKernel SVM For Image ClassificationAriake SwyceNo ratings yet
- hw3 SolDocument14 pageshw3 SolKiyan RoyNo ratings yet
- Examples and SolutionsDocument9 pagesExamples and Solutions2002.pawandeepsinghNo ratings yet
- Reading For Linear ProgrammingDocument20 pagesReading For Linear ProgrammingRajneet ChandNo ratings yet
- Answer Set 1 - Fall 2008Document6 pagesAnswer Set 1 - Fall 2008Linh ChiNo ratings yet
- CHAPTER 1 First-Order Differential Equat PDFDocument13 pagesCHAPTER 1 First-Order Differential Equat PDFcristy_maxspeedNo ratings yet
- Numerical Methods For Engineers - Guide to solving ODEs using numerical techniquesDocument31 pagesNumerical Methods For Engineers - Guide to solving ODEs using numerical techniquesamiruddin sharifNo ratings yet
- CH 1Document7 pagesCH 1kenenisa AbdisaNo ratings yet
- Finite 44Document13 pagesFinite 44JorgeLuisCastilloRangelNo ratings yet
- Finite element method approximationDocument5 pagesFinite element method approximationEstela EstelaNo ratings yet
- Data Scientist resume highlighting AI and CV experienceDocument2 pagesData Scientist resume highlighting AI and CV experiencesourab jainNo ratings yet
- ConcentFormMentor CombinedDocument3 pagesConcentFormMentor Combinedsourab jainNo ratings yet
- ISM Makeup SolutionDocument8 pagesISM Makeup Solutionsourab jainNo ratings yet
- IDS Sec-1 CS1-CS8 Merged SlidesDocument419 pagesIDS Sec-1 CS1-CS8 Merged Slidessourab jainNo ratings yet
- Amit Kumar ResumeDocument2 pagesAmit Kumar Resumesourab jainNo ratings yet
- Secure Coding Practices For: White PaperDocument15 pagesSecure Coding Practices For: White Papererica jayasunderaNo ratings yet
- ITDL International Product CatalogoDocument8 pagesITDL International Product CatalogoUlises GarcíaNo ratings yet
- Huawei WCDMA Primary Scrambling Code PlanningDocument22 pagesHuawei WCDMA Primary Scrambling Code PlanningFahrudin Fajar0% (1)
- Safety Manual Sec B1 BBSMDocument2 pagesSafety Manual Sec B1 BBSMTanko RichardsNo ratings yet
- Bresenhams Line Algorithm and Circle Generating MethodsDocument21 pagesBresenhams Line Algorithm and Circle Generating MethodsSOWMYANo ratings yet
- Question Bank FinalDocument44 pagesQuestion Bank Finalswadeshsxc100% (1)
- ASCE702W Wind Analysis Program for ASCE 7-02 CodeDocument15 pagesASCE702W Wind Analysis Program for ASCE 7-02 CodeHgagselim SelimNo ratings yet
- John Michael Lugtu Cloud Computing Reflection PaperDocument2 pagesJohn Michael Lugtu Cloud Computing Reflection PaperGlobe HomeNo ratings yet
- 06 1 Priority Queues 2 HeapsDocument152 pages06 1 Priority Queues 2 Heapskunal lahotiNo ratings yet
- 1 MarksDocument33 pages1 MarksSri RamNo ratings yet
- Grade 08 ICT Lesson 03Document10 pagesGrade 08 ICT Lesson 03Suhada JayamanneNo ratings yet
- Transmision PDFDocument26 pagesTransmision PDFAirton Ahyrton Macazana HuaringaNo ratings yet
- 20 G 1 Anc 140 Aa 0 NNNNNDocument12 pages20 G 1 Anc 140 Aa 0 NNNNNWriterNo ratings yet
- 2015 - 2016 Questions (New Syllabus) Describe The Characteristics and Uses of Different Types of DVDDocument2 pages2015 - 2016 Questions (New Syllabus) Describe The Characteristics and Uses of Different Types of DVDYashodhaNo ratings yet
- Addition Five Minute Frenzy 0110 001 PDFDocument2 pagesAddition Five Minute Frenzy 0110 001 PDFSimone CarvalhoNo ratings yet
- DO-C10072-CT Premet X (Issue 3)Document2 pagesDO-C10072-CT Premet X (Issue 3)Wisnu PrambudiNo ratings yet
- FMC Microflow CalculationsDocument24 pagesFMC Microflow Calculationsstefano375No ratings yet
- Comment Response Sheet SVDN CPP M 0002 D01 0003 (r01)Document2 pagesComment Response Sheet SVDN CPP M 0002 D01 0003 (r01)Tuấn Vũ0% (1)
- House of Sweden Apartments The Top Two Oors ofDocument2 pagesHouse of Sweden Apartments The Top Two Oors ofapi-1750834No ratings yet
- z6 Amplitude ModulationDocument10 pagesz6 Amplitude ModulationtsegayNo ratings yet
- StatisticsDocument26 pagesStatisticscherryNo ratings yet
- NCR HistoryDocument2 pagesNCR HistoryAgam SehgalNo ratings yet
- Mobile Computing Course PlanDocument7 pagesMobile Computing Course PlanPragya ChakshooNo ratings yet
- Q&A With Heather Gold, President, FTTH Council North AmericaDocument2 pagesQ&A With Heather Gold, President, FTTH Council North AmericaanadiguptaNo ratings yet
- Chapter 04 - Batch Input MethodsDocument21 pagesChapter 04 - Batch Input MethodsnivasNo ratings yet
- User login and student registration formDocument10 pagesUser login and student registration formAcep RamdanNo ratings yet
- El Rey Motel 954533465 454 E Foothill BLVD Rialto, CA 92376 (909) 875-0134 Marvin Lal (909) 875-0134Document20 pagesEl Rey Motel 954533465 454 E Foothill BLVD Rialto, CA 92376 (909) 875-0134 Marvin Lal (909) 875-0134Patel ArvindNo ratings yet
- Guidelines for Application FormDocument12 pagesGuidelines for Application FormAmarNo ratings yet