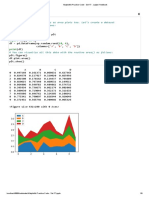
You might also like
- Hasil RendiDocument11 pagesHasil RendiFitria KintaNo ratings yet
- Glass ClassificationDocument3 pagesGlass ClassificationSiddharth Tiwari100% (2)
- Supervised Learning With Scikit-Learn: Preprocessing DataDocument32 pagesSupervised Learning With Scikit-Learn: Preprocessing DataNourheneMbarekNo ratings yet
- Practical-5 - Jupyter NotebookDocument8 pagesPractical-5 - Jupyter NotebookHarsha Gohil100% (1)
- Clustering Bank CustomersDocument50 pagesClustering Bank CustomersP Venkata Krishna Rao100% (19)
- Loading The Dataset: 'Churn - Modelling - CSV'Document6 pagesLoading The Dataset: 'Churn - Modelling - CSV'Divyani ChavanNo ratings yet
- Predicting Diamond Price: 2 Step MethodDocument17 pagesPredicting Diamond Price: 2 Step MethodSarajit Poddar100% (1)
- TP RegressionDocument1 pageTP RegressionMOHAMED EL BACHIR BERRIOUA100% (1)
- Import As Import As Import AsDocument8 pagesImport As Import As Import AsDavid EsparzaArellanoNo ratings yet
- Import As: Numpy NPDocument5 pagesImport As: Numpy NPGilang SaputraNo ratings yet
- DSBDA-4Document4 pagesDSBDA-4Arbaz ShaikhNo ratings yet
- Linear - Regression - Ipynb - ColaboratoryDocument4 pagesLinear - Regression - Ipynb - Colaboratoryavnimote121No ratings yet
- 6 XG Boost - Jupyter NotebookDocument3 pages6 XG Boost - Jupyter Notebookvenkatesh m100% (1)
- Merging - Scaled - 1D - & - Trying - Different - CLassification - ML - Models - .Ipynb - ColaboratoryDocument16 pagesMerging - Scaled - 1D - & - Trying - Different - CLassification - ML - Models - .Ipynb - Colaboratorygirishcherry12100% (1)
- C2M2 - Assignment: 1 Risk Models Using Tree-Based ModelsDocument38 pagesC2M2 - Assignment: 1 Risk Models Using Tree-Based ModelsSarah Mendes100% (1)
- Practica 9Document24 pagesPractica 92marlenehh2003No ratings yet
- Joshua PDFDocument11 pagesJoshua PDFKavi SekarNo ratings yet
- Matplotlib 1652960400Document13 pagesMatplotlib 1652960400Washington AzevedoNo ratings yet
- Fmsa315 - s11 - A.ipynb - Fernández - ConstanzaDocument6 pagesFmsa315 - s11 - A.ipynb - Fernández - ConstanzaScribdTranslationsNo ratings yet
- 1 2 3 4 5 6 7 8 9 10 Sepallength Sepalwidth Petallength Petalwidth SpeciesDocument4 pages1 2 3 4 5 6 7 8 9 10 Sepallength Sepalwidth Petallength Petalwidth SpeciesLINH VU TRANGNo ratings yet
- AML5201 - LabFinal - Suhas - S - Nair - Ipynb - ColaboratoryDocument11 pagesAML5201 - LabFinal - Suhas - S - Nair - Ipynb - Colaboratorykasalasurya16No ratings yet
- Interpolatingfunction : Bla Ndsolve ( (F ''' (T) + F (T) F '' (T) 0, F (0) 0, F ' (0) 0, F ' (100 000) 1), F, T)Document7 pagesInterpolatingfunction : Bla Ndsolve ( (F ''' (T) + F (T) F '' (T) 0, F (0) 0, F ' (0) 0, F ' (100 000) 1), F, T)Alexis CastleNo ratings yet
- ML Lab6.Ipynb - ColaboratoryDocument5 pagesML Lab6.Ipynb - ColaboratoryAvi Srivastava100% (1)
- Fertilidad: Numpy NP Pandas PD Matplotlib - Pyplot PLT IpywidgetsDocument8 pagesFertilidad: Numpy NP Pandas PD Matplotlib - Pyplot PLT IpywidgetsKevin Fernando Ochoa Martinez100% (1)
- Generative AI Binary ClassificationDocument7 pagesGenerative AI Binary ClassificationCyborg UltraNo ratings yet
- PandasDocument21 pagesPandasShubham dattatray koteNo ratings yet
- Data Mining PortfolioDocument19 pagesData Mining PortfolioJohnMaynardNo ratings yet
- PembelajaranMesin - Ipynb - ColaboratoryDocument6 pagesPembelajaranMesin - Ipynb - ColaboratoryKhaerul RijalNo ratings yet
- Cl-Vii Ass4 4301063Document7 pagesCl-Vii Ass4 4301063ATHARVA SHINDENo ratings yet
- Clustering analysis reveals optimum number of clusters for airlines and crime dataDocument9 pagesClustering analysis reveals optimum number of clusters for airlines and crime datanehal gundrapally100% (1)
- K-Means Clustering Analysis of Mall Customer DataDocument5 pagesK-Means Clustering Analysis of Mall Customer Dataada sajaNo ratings yet
- Python Course Cheat SheetDocument30 pagesPython Course Cheat SheetVinayNo ratings yet
- 7-8 Feature Engineering 101-NormalizationDocument8 pages7-8 Feature Engineering 101-NormalizationKhan RafiNo ratings yet
- Saurabh Verma 9919102005Document11 pagesSaurabh Verma 9919102005Yogendra pratap Singh100% (1)
- WS#3 Python Data Science Toolbox - NitroDocument6 pagesWS#3 Python Data Science Toolbox - NitroEliezer NitroNo ratings yet
- 10 minutes to pandasDocument19 pages10 minutes to pandasPraveen KandhalaNo ratings yet
- Decision TreeDocument12 pagesDecision TreeKagade AjinkyaNo ratings yet
- Chapter4 PDFDocument34 pagesChapter4 PDFHana BananaNo ratings yet
- Data Analysis and Modeling for Financial Fraud DetectionDocument1 pageData Analysis and Modeling for Financial Fraud Detectionakshay.c c100% (1)
- K Means ClusteringDocument10 pagesK Means ClusteringWalid Sassi100% (1)
- 7 Questions To Ask Before EDADocument2 pages7 Questions To Ask Before EDAYajur Agarwal100% (1)
- 2 and 3Document6 pages2 and 3Radhika KhandelwalNo ratings yet
- Machine Learning Predicts Breast CancerDocument21 pagesMachine Learning Predicts Breast CancerJEFFREY WILLIAMS P M 20221013No ratings yet
- FDS Solved SlipsDocument63 pagesFDS Solved Slipsyashm4071100% (1)
- Visualizing Gravitational-wave Skymap DataDocument9 pagesVisualizing Gravitational-wave Skymap DataASHINI MODINo ratings yet
- Knn1 MinMaxScalarDocument13 pagesKnn1 MinMaxScalarJoe1No ratings yet
- Applied Numerical Methods Wmatlab For Engineers and Scientists 3rd Edition Chapra Solutions ManualDocument25 pagesApplied Numerical Methods Wmatlab For Engineers and Scientists 3rd Edition Chapra Solutions ManualJosephCraiggmax100% (50)
- Logistic Regression in RDocument7 pagesLogistic Regression in RPratik GugliyaNo ratings yet
- MatplotlibDocument8 pagesMatplotlibMahevish FatimaNo ratings yet
- ML0101EN Clas K Nearest Neighbors CustCat Py v1Document9 pagesML0101EN Clas K Nearest Neighbors CustCat Py v1Rajat SolankiNo ratings yet
- Statisitics Project 6Document48 pagesStatisitics Project 6AMAN PRAKASH100% (2)
- Covid-19 Prediction - Jupyter NotebookDocument6 pagesCovid-19 Prediction - Jupyter NotebookTEEGALAMEHERRITHWIK 122010320035No ratings yet
- Tutorial 2 - ClusteringDocument6 pagesTutorial 2 - ClusteringGupta Akshay100% (2)
- Linear Regression Mca Lab - Jupyter NotebookDocument2 pagesLinear Regression Mca Lab - Jupyter NotebookSmriti SharmaNo ratings yet
- Predictive Modelling Alternative Firm Level PDFDocument26 pagesPredictive Modelling Alternative Firm Level PDFAnkita Mishra100% (3)
- SciServerLab Session2 2023-24 StudentDocument20 pagesSciServerLab Session2 2023-24 StudentwilliamgmurquhartNo ratings yet
- Pyt Manual 1Document85 pagesPyt Manual 1Hrithik KumarNo ratings yet
- Jupyter Notebook Yardlenis Sánchez Act2Document1 pageJupyter Notebook Yardlenis Sánchez Act2NASLYNo ratings yet
- Assignment 1 Pa66Document5 pagesAssignment 1 Pa66Pratik ManeNo ratings yet
- PA66 ML Assignment 3Document10 pagesPA66 ML Assignment 3Pratik ManeNo ratings yet
- River Cleaning Robot Project ReportDocument36 pagesRiver Cleaning Robot Project ReportPratik ManeNo ratings yet
- Face Detection Using CNNDocument10 pagesFace Detection Using CNNPratik ManeNo ratings yet
- Introduction To ARENA SimulationDocument25 pagesIntroduction To ARENA SimulationSam yousefNo ratings yet
- Qualitative Research Ethics in EducationDocument15 pagesQualitative Research Ethics in EducationNURUL AINI BT MUSA MoeNo ratings yet
- Geography and HistoryDocument25 pagesGeography and HistorySritamaNo ratings yet
- Functions of Code Switching in ELT ClassroomsDocument19 pagesFunctions of Code Switching in ELT Classroomsnero daunaxilNo ratings yet
- Tyba SyllabusDocument15 pagesTyba SyllabusVaibhav MajgaonkarNo ratings yet
- Building Social Literacy Skills in EducationDocument11 pagesBuilding Social Literacy Skills in EducationKim ArdaisNo ratings yet
- Mendiskusikan Hasil Pengujian Hipotesis Penelitian Dalam Penyusunan Disertasi: Sebuah Kajian TeoritisDocument9 pagesMendiskusikan Hasil Pengujian Hipotesis Penelitian Dalam Penyusunan Disertasi: Sebuah Kajian Teoritisujang septianNo ratings yet
- Synopsis Format (BASR)Document7 pagesSynopsis Format (BASR)Muhammad Tanzeel Qaisar DogarNo ratings yet
- Lawrence M Jaricha Practical AssignmentDocument5 pagesLawrence M Jaricha Practical Assignmentlawrence munya jarichaNo ratings yet
- Muhammad Saiful Rafif - 5013201096 - Resume Week 7Document3 pagesMuhammad Saiful Rafif - 5013201096 - Resume Week 7Zaprz RaffNo ratings yet
- Challenges of The Teachers in The New Normal EnvironmentDocument26 pagesChallenges of The Teachers in The New Normal EnvironmentAlexia Peligro SupapoNo ratings yet
- STAT 221 Mid Term (2) MidtermDocument4 pagesSTAT 221 Mid Term (2) MidtermDiane BangtuanNo ratings yet
- PCED102 The Teacher and The School CurriculumDocument12 pagesPCED102 The Teacher and The School CurriculumKim ArdaisNo ratings yet
- Nurse Education Today: SciencedirectDocument6 pagesNurse Education Today: Sciencedirectdwirabiatul adwiyahaliNo ratings yet
- Agent-Based Model - WikipediaDocument19 pagesAgent-Based Model - WikipediaJameson TheisenNo ratings yet
- A Study On The Relationship Between VideDocument6 pagesA Study On The Relationship Between VideMuhammad RizwanNo ratings yet
- DLL Wellness WK 5Document5 pagesDLL Wellness WK 5Lorna CelarioNo ratings yet
- Performance and Enabling ObjectivesDocument2 pagesPerformance and Enabling ObjectivesTravon CharlesNo ratings yet
- UNIT VI Client EducationDocument27 pagesUNIT VI Client Educationtaekook is real100% (1)
- Esp For Tourism and Hospitality in Algeria: Prospects For Curriculum DesignDocument119 pagesEsp For Tourism and Hospitality in Algeria: Prospects For Curriculum DesignDoha SalimNo ratings yet
- Feedback For Unit 2 Assignment Dropbox - CE340 Introduction To Autism Spectrum Disorder in Young Children - Purdue University GlobalDocument4 pagesFeedback For Unit 2 Assignment Dropbox - CE340 Introduction To Autism Spectrum Disorder in Young Children - Purdue University GlobalyaiteNo ratings yet
- Hierarchies of Loss: A Critique of Disenfranchised Grief: Patricia Robson, B.E ., M.ADocument23 pagesHierarchies of Loss: A Critique of Disenfranchised Grief: Patricia Robson, B.E ., M.AWinny AisyahNo ratings yet
- Examinations Final Time Table May-Aug 2022Document14 pagesExaminations Final Time Table May-Aug 2022Clinton otienoNo ratings yet
- Students Preferability Towards The Type of Music They Listen To While StudyingDocument9 pagesStudents Preferability Towards The Type of Music They Listen To While StudyingFaith Lanie LumayagNo ratings yet
- BookDocument166 pagesBookBalcha bulaNo ratings yet
- Employees' Job Satisfaction and Their Work Per-Formance As Elements Influencing Work SafetyDocument8 pagesEmployees' Job Satisfaction and Their Work Per-Formance As Elements Influencing Work SafetyVivekNo ratings yet
- Research Design and Methodology Chapter of Nursing ThesisDocument28 pagesResearch Design and Methodology Chapter of Nursing ThesisJEMABEL SIDAYENNo ratings yet
- 7045SSL CW2-BriefDocument11 pages7045SSL CW2-BriefJahidul AhasanNo ratings yet
- Effect of study habits on academic performanceDocument18 pagesEffect of study habits on academic performanceGrace Saagundo Dubduban100% (1)
- Foundation and Conception of CurriculumDocument2 pagesFoundation and Conception of CurriculumElijah Shem YapeNo ratings yet