You might also like
- DummiesGuideDocument51 pagesDummiesGuideMilorad SpasicNo ratings yet
- Storytelling With Data - The New Visualization Data Guide To Reaching Your Business Aim in The Fastest WayDocument100 pagesStorytelling With Data - The New Visualization Data Guide To Reaching Your Business Aim in The Fastest Waytim donlot100% (1)
- Big Data Analytics - Quick Guide - TutorialspointDocument50 pagesBig Data Analytics - Quick Guide - TutorialspointAero AcadNo ratings yet
- Credit CardDocument15 pagesCredit CardAnant JainNo ratings yet
- Testing and Quality AssuranceDocument5 pagesTesting and Quality AssuranceBulcha MelakuNo ratings yet
- Project Planning (Project Quality Management)Document22 pagesProject Planning (Project Quality Management)Stephen VisperasNo ratings yet
- Crisp DMDocument30 pagesCrisp DMKautilya Parmar100% (1)
- DATA MiningDocument21 pagesDATA MiningRobi BMNo ratings yet
- Ministry of Finance University of Finance-Marketing International BusinessDocument27 pagesMinistry of Finance University of Finance-Marketing International BusinessKhánh NgọcNo ratings yet
- PAM - CompleteDocument322 pagesPAM - CompleteDaksh RawalNo ratings yet
- FMEA Errata Sheet ENG AIAG VDA FMEA Handbook 202000602 PDFDocument10 pagesFMEA Errata Sheet ENG AIAG VDA FMEA Handbook 202000602 PDFBonny BonitoNo ratings yet
- Crisp DMDocument33 pagesCrisp DMJuanCarlosEstradaNo ratings yet
- Excel Cheat SheetDocument61 pagesExcel Cheat SheetKedai IwaNo ratings yet
- Crisp DM PresentationDocument9 pagesCrisp DM PresentationSwapnil SakpalNo ratings yet
- Crisp DMDocument38 pagesCrisp DMnxjnvkNo ratings yet
- Crisp-DmDocument4 pagesCrisp-Dmshravan kumarNo ratings yet
- Data Mining FrameworkDocument18 pagesData Mining FrameworkHilmy MuhammadNo ratings yet
- Data Mining Implementation ProcessDocument9 pagesData Mining Implementation ProcessRa Mez GmrNo ratings yet
- Machine Learning The Way To Better ThinkingDocument11 pagesMachine Learning The Way To Better ThinkingRick MitraNo ratings yet
- Intro Ds ClassDocument46 pagesIntro Ds ClassAshitha AshiNo ratings yet
- Topic 2 Business in Practice and The GRISP-DM FrameworkDocument22 pagesTopic 2 Business in Practice and The GRISP-DM FrameworkDuy Khanh HuynhNo ratings yet
- Unit2-Data ScienceDocument20 pagesUnit2-Data ScienceDIVYANSH GAUR (RA2011027010090)No ratings yet
- Sesi 2 Data Analitik - FrameworkDocument42 pagesSesi 2 Data Analitik - Frameworkde notoriousNo ratings yet
- 02 CrispdmDocument25 pages02 CrispdmsamiaNo ratings yet
- Predictive Modelling-Week-1Document39 pagesPredictive Modelling-Week-1prepareforexamzNo ratings yet
- 6 - Data Science MethodologyDocument20 pages6 - Data Science MethodologyDivya kumaran SivaretnamNo ratings yet
- CrispslidesDocument20 pagesCrispslidesMiguel pilamungaNo ratings yet
- CRISP Data Mining SIBM PuneDocument24 pagesCRISP Data Mining SIBM PuneAYUSH AGRAWALNo ratings yet
- Chapter 5 - Big Data Implementation Part 1Document62 pagesChapter 5 - Big Data Implementation Part 1Suren DevNo ratings yet
- Bda Bi Jit Chapter-3Document40 pagesBda Bi Jit Chapter-3Araarsoo JaallataaNo ratings yet
- CrispDocument8 pagesCrispJose Rafael CruzNo ratings yet
- Module 5 - Data Science MethodologyDocument17 pagesModule 5 - Data Science MethodologyfathiahNo ratings yet
- Lecture 5 Introduction To Data Mining Business IntelligenceDocument50 pagesLecture 5 Introduction To Data Mining Business Intelligencelasithrandima123No ratings yet
- # Understanding DM Architecture, KDD & DM ToolsDocument29 pages# Understanding DM Architecture, KDD & DM ToolsDan MasangaNo ratings yet
- BA Data MiningDocument10 pagesBA Data Miningsam2011No ratings yet
- Data Mining Process: Lecturer: Dr. Nguyen Thi Ngoc AnhDocument31 pagesData Mining Process: Lecturer: Dr. Nguyen Thi Ngoc AnhThảo Nguyên TrầnNo ratings yet
- Introduction To Data Mining: A.J.M.M. (Ton) WeijtersDocument24 pagesIntroduction To Data Mining: A.J.M.M. (Ton) WeijterskrishnakumarNo ratings yet
- Lesson 1 Introduction To Data Mining: Jennifer O. Contreras ColomaDocument40 pagesLesson 1 Introduction To Data Mining: Jennifer O. Contreras ColomaOmer HushamNo ratings yet
- QBA - Chapter 1 Introduction To Quantity AnalysisDocument32 pagesQBA - Chapter 1 Introduction To Quantity Analysisahmedgalalabdalbaath2003No ratings yet
- Big Data Analytics Quick GuideDocument53 pagesBig Data Analytics Quick Guidesatheeshbabun100% (1)
- Current TrendsDocument35 pagesCurrent TrendsicecoolbergeNo ratings yet
- Lesson1 2Document25 pagesLesson1 2Jhimar Peredo JuradoNo ratings yet
- Organising ML ProjectsDocument52 pagesOrganising ML Projectsmax bisceneNo ratings yet
- KDD Assignmnt DataDocument7 pagesKDD Assignmnt DataAbiha Akter 201-15-3203No ratings yet
- Ba ReviewerDocument7 pagesBa ReviewerJamielyn Dy DimaanoNo ratings yet
- Introduction To Simulation: MS 5225 Business Process Modeling & SimulationDocument43 pagesIntroduction To Simulation: MS 5225 Business Process Modeling & SimulationMatthew ZNo ratings yet
- CINPD Unit 5Document16 pagesCINPD Unit 5Geetha MenonNo ratings yet
- DM - MOD - 1 Part IIDocument14 pagesDM - MOD - 1 Part IIsandrarajuofficialNo ratings yet
- Lesson 5 - Module 005business Process ModelingDocument12 pagesLesson 5 - Module 005business Process ModelingNoe AgubangNo ratings yet
- Summary Business AnalyticsDocument24 pagesSummary Business AnalyticsLUIGIANo ratings yet
- Unit2 1 Descriptive ModelDocument17 pagesUnit2 1 Descriptive Modelsabharish varshan410No ratings yet
- Unit 1Document43 pagesUnit 1Nihar Ranjan Prusty 92No ratings yet
- Brochure C-DA KLDocument9 pagesBrochure C-DA KLkhesviny.vijayanNo ratings yet
- S2 - Datascience LifecycleDocument19 pagesS2 - Datascience LifecyclemmtharinduNo ratings yet
- Module 1 TutorialDocument35 pagesModule 1 Tutorialgohasap_303011511No ratings yet
- Data Mining Process, Techniques, Tools & ExamplesDocument11 pagesData Mining Process, Techniques, Tools & Examplestofy79No ratings yet
- SE401 - Software Quality Assurance and Testing: Test PlanDocument44 pagesSE401 - Software Quality Assurance and Testing: Test PlanFake fakerNo ratings yet
- Pattern Recognition ApplicationDocument43 pagesPattern Recognition ApplicationKhaled OmarNo ratings yet
- Project Management APU Lec 8Document39 pagesProject Management APU Lec 8Jahid HasanNo ratings yet
- Ads Phase 4Document12 pagesAds Phase 4Sheik Dawood SNo ratings yet
- Q) Drivers For Business AnalyticsDocument5 pagesQ) Drivers For Business AnalyticsMohamed RiyazNo ratings yet
- Maintenance: - Occurs When The System Is in Production - IncludesDocument25 pagesMaintenance: - Occurs When The System Is in Production - IncludesSachin KumarNo ratings yet
- Data Management and The CMM/CMMI: Translating Capability Maturity Models To Organizational FunctionsDocument18 pagesData Management and The CMM/CMMI: Translating Capability Maturity Models To Organizational FunctionsFernando Martínez LópezNo ratings yet
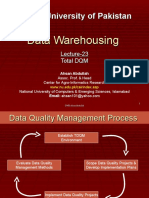
- Virtual University of PakistanDocument12 pagesVirtual University of PakistanAhmed MaherNo ratings yet
- Chapter - 2Document32 pagesChapter - 2Anduamlak WalelignNo ratings yet
- Presentation 1Document28 pagesPresentation 1Nisar MohammadNo ratings yet
- LPM 208 Information Tech.Document91 pagesLPM 208 Information Tech.agukos augustusNo ratings yet
- Imdrf Avis 62304 PDFDocument3 pagesImdrf Avis 62304 PDFK163974 Sohail ZiaNo ratings yet
- Frederick S. Hillier Gerald J. LiebermanDocument14 pagesFrederick S. Hillier Gerald J. LiebermanmuniraNo ratings yet
- Chatbot Research and DesignDocument217 pagesChatbot Research and DesignJosé Carlos Gamero LeónNo ratings yet
- HRD Best Practices in Amazon CompanyDocument11 pagesHRD Best Practices in Amazon Companysoosh 565No ratings yet
- White Paper - Microsoft Teams Call Quality Troubleshooting - Tactics and Solution OverviewDocument14 pagesWhite Paper - Microsoft Teams Call Quality Troubleshooting - Tactics and Solution OverviewSmart ShrinkNo ratings yet
- 985 0708 01 16 - Rev A - ReleaseNotesDocument15 pages985 0708 01 16 - Rev A - ReleaseNotesAndrew MacDonaldNo ratings yet
- Faa Form 8060 12 PDFDocument2 pagesFaa Form 8060 12 PDFRebeccaNo ratings yet
- Analysis Expert LIMS Users ManualDocument19 pagesAnalysis Expert LIMS Users ManualSainath Amuda100% (1)
- From Zero to Super Affiliate RuLit Me 673010.Ru.enDocument99 pagesFrom Zero to Super Affiliate RuLit Me 673010.Ru.enomar slaouiNo ratings yet
- Practical 3Document3 pagesPractical 3Naimish SorathiyaNo ratings yet
- Factory Outlet StoreDocument6 pagesFactory Outlet StoreNeerajNo ratings yet
- FP 700Document36 pagesFP 700BarracudaNo ratings yet
- Software Quality AssuranceDocument39 pagesSoftware Quality AssuranceH1124Manaswi MoreNo ratings yet
- Name - Deepika Mishra Roll No-01 Department-Soet Divison - L Subject - Ai & MLDocument9 pagesName - Deepika Mishra Roll No-01 Department-Soet Divison - L Subject - Ai & MLPranjal KashaudhaNo ratings yet
- Creddle ResumeDocument6 pagesCreddle Resumef0samekymeb3100% (1)
- HK222. CH - 04 - Material Requirement PlanningDocument35 pagesHK222. CH - 04 - Material Requirement PlanningHOÀNG PHẠM HUYNo ratings yet
- Nawc2011 PDFDocument36 pagesNawc2011 PDFHongsung ChoiNo ratings yet
- 3.2 Dalia Adib - 2020-10-14 ITU DLT Why Aren't Telecoms Use Cases Moving Beyond The LabDocument16 pages3.2 Dalia Adib - 2020-10-14 ITU DLT Why Aren't Telecoms Use Cases Moving Beyond The Labali aghajaniNo ratings yet
- The Elements of UML Style (Ambler 2002-11-18) (25AE192E)Document162 pagesThe Elements of UML Style (Ambler 2002-11-18) (25AE192E)husicicNo ratings yet
- Oracle GRC Controls Suite Fundamentals TRAINING Sysllabus Oracle University Online CourseDocument6 pagesOracle GRC Controls Suite Fundamentals TRAINING Sysllabus Oracle University Online CourseVenkatesam BarigedaNo ratings yet
- Material Requirements Planning (MRP) and ERPDocument90 pagesMaterial Requirements Planning (MRP) and ERPDesryadi Ilyas MohammadNo ratings yet
- 10 Advantages and 10 Disadvantages of The Inventory Management System (Pre-Final Exam)Document6 pages10 Advantages and 10 Disadvantages of The Inventory Management System (Pre-Final Exam)Anne Rhos MagbanuaNo ratings yet