You might also like
- Parallel Computational Fluid Dynamics '99: Towards Teraflops, Optimization and Novel FormulationsFrom EverandParallel Computational Fluid Dynamics '99: Towards Teraflops, Optimization and Novel FormulationsNo ratings yet
- Numerical Methods for Simulation and Optimization of Piecewise Deterministic Markov Processes: Application to ReliabilityFrom EverandNumerical Methods for Simulation and Optimization of Piecewise Deterministic Markov Processes: Application to ReliabilityNo ratings yet
- Design and Analysis of Closed Loop Capacity Control For A Multi 2005 CIRP AnDocument4 pagesDesign and Analysis of Closed Loop Capacity Control For A Multi 2005 CIRP AnMaría Paula SánchezNo ratings yet
- Improves Multiplier Effcieny in HardwareDocument9 pagesImproves Multiplier Effcieny in HardwareMushahid HussainNo ratings yet
- A FPGA Implementation of Model Predictive Control : K.V. Ling, S.P. Yue and J.M. MaciejowskiDocument6 pagesA FPGA Implementation of Model Predictive Control : K.V. Ling, S.P. Yue and J.M. MaciejowskinarendraNo ratings yet
- Aggregation of Malmquist Productivity IndexesDocument11 pagesAggregation of Malmquist Productivity IndexesjanaNo ratings yet
- Production Nad CostsDocument12 pagesProduction Nad Costsnyasha gundaniNo ratings yet
- Multiobjective Optimal Design of Superconducting Generator Using Genetic AlgorithmDocument5 pagesMultiobjective Optimal Design of Superconducting Generator Using Genetic AlgorithmDeepak GuptaNo ratings yet
- Multitask Trajectory Planning Based On Predictive ControlDocument8 pagesMultitask Trajectory Planning Based On Predictive ControlMarcello AlmeidaNo ratings yet
- A COMSOL Interface To Cape-Open Compliant Physical and Thermodynamic Property PackagesDocument13 pagesA COMSOL Interface To Cape-Open Compliant Physical and Thermodynamic Property PackagesGiu Ali Mamani PacoNo ratings yet
- The Temporal Knapsack Problem and Its SolutionDocument15 pagesThe Temporal Knapsack Problem and Its SolutionDanish GhauriNo ratings yet
- Economic Lot Scheduling: JS, Ffs and ElsDocument17 pagesEconomic Lot Scheduling: JS, Ffs and ElsSatyam DuttNo ratings yet
- On Mixed Integer Programming Formulations For The Unit Commitment ProblemDocument92 pagesOn Mixed Integer Programming Formulations For The Unit Commitment ProblemEduards Moises Triviño VildósolaNo ratings yet
- Optimization Algorithms Deep PDFDocument9 pagesOptimization Algorithms Deep PDFsaadNo ratings yet
- Liñan-5-12Document8 pagesLiñan-5-12Angel Santiago Cabezas LópezNo ratings yet
- LQG/LTR Flight Controller Optimal Design Based On Differential Evolution AlgorithmDocument4 pagesLQG/LTR Flight Controller Optimal Design Based On Differential Evolution AlgorithmLuis CarvalhoNo ratings yet
- Pa Project Report FinalDocument4 pagesPa Project Report FinalSajeda ShboolNo ratings yet
- Jt9D Individual Engine Performance Modelling: Sakhr Abu Darag and Tomas GronstedtDocument7 pagesJt9D Individual Engine Performance Modelling: Sakhr Abu Darag and Tomas GronstedtdausNo ratings yet
- Draft: Proceedings of WTC2005 World Tribology Congress III September 12-16, 2005, Washington, D.C., USADocument2 pagesDraft: Proceedings of WTC2005 World Tribology Congress III September 12-16, 2005, Washington, D.C., USARajib DuttaNo ratings yet
- Sequencing Offshore Oil and Gas Fields Under UncertaintyDocument11 pagesSequencing Offshore Oil and Gas Fields Under UncertaintyAlbeiro Sierra PachecoNo ratings yet
- HD 2Document1 pageHD 2sdxfcgvbhinjmkNo ratings yet
- Dynamic Programming MatlabDocument6 pagesDynamic Programming MatlabRitesh SinghNo ratings yet
- Global Solution of Economic Dispatch With Valve Point Effects and Transmission ConstraintsDocument8 pagesGlobal Solution of Economic Dispatch With Valve Point Effects and Transmission ConstraintsM8ow6fNo ratings yet
- Thermal Unit Commitment Solution Using An Improved Lagrangian RelaxationDocument8 pagesThermal Unit Commitment Solution Using An Improved Lagrangian RelaxationWisnuPrayogoNo ratings yet
- Production FunctionDocument7 pagesProduction FunctionKennara pradipta IdnNo ratings yet
- Number Theory Cryptography 2022 HW2Document2 pagesNumber Theory Cryptography 2022 HW2gaspard TomasNo ratings yet
- Economic Load Dispatch Problem With Ant Lion Optimization Using Practical Constraints (#421816) - 725471Document19 pagesEconomic Load Dispatch Problem With Ant Lion Optimization Using Practical Constraints (#421816) - 725471Mehmet YILMAZNo ratings yet
- PCT 301T ModelingDocument21 pagesPCT 301T ModelingPortia ShilengeNo ratings yet
- Hectorguillermo 2018Document6 pagesHectorguillermo 2018vishal BhoknalNo ratings yet
- Optimisation of Three - Phase Separators: A Mathematical Model DesignDocument9 pagesOptimisation of Three - Phase Separators: A Mathematical Model DesignAbubakarNo ratings yet
- Weighted Partitioning For Fast MultiplierlessDocument5 pagesWeighted Partitioning For Fast MultiplierlessDr. Ruqaiya KhanamNo ratings yet
- Jeppesen Faster Multi-Object Segmentation Using Parallel Quadratic Pseudo-Boolean Optimization ICCV 2021 PaperDocument10 pagesJeppesen Faster Multi-Object Segmentation Using Parallel Quadratic Pseudo-Boolean Optimization ICCV 2021 PaperNan ZhangNo ratings yet
- Tutorial 3Document4 pagesTutorial 3haiqalNo ratings yet
- 2fecow2fget2fpublicatio2f1997public2fhicss98 MurilloDocument9 pages2fecow2fget2fpublicatio2f1997public2fhicss98 MurilloIzudin SoftićNo ratings yet
- Tuning PI Controllers For Integrator/Dead Time ProcessesDocument4 pagesTuning PI Controllers For Integrator/Dead Time ProcessesRaadBassamNo ratings yet
- Paper Okmf Carla2015Document14 pagesPaper Okmf Carla2015Raul RamosNo ratings yet
- Design and Implementation of Approximate Operator Splitting Algorithms On FPGADocument1 pageDesign and Implementation of Approximate Operator Splitting Algorithms On FPGAsamactrangNo ratings yet
- Computers & Industrial EngineeringDocument12 pagesComputers & Industrial EngineeringHelc LarcasNo ratings yet
- Petroleum Reservoir Control Optimization With TheDocument20 pagesPetroleum Reservoir Control Optimization With TheEng SaeedNo ratings yet
- Enhancement of A Semi-Batch Chemical Reactor Efficiency Through Its Dimensions OptimizationDocument10 pagesEnhancement of A Semi-Batch Chemical Reactor Efficiency Through Its Dimensions Optimizationbkpadhi815No ratings yet
- Initial Improvement of The Hybrid Accelerated Gradient Descent ProcessDocument8 pagesInitial Improvement of The Hybrid Accelerated Gradient Descent ProcessСтефан ПанићNo ratings yet
- An Evolution of GPT Cryptosystem: 2.1 Rank Metric and Gabidulin CodesDocument6 pagesAn Evolution of GPT Cryptosystem: 2.1 Rank Metric and Gabidulin CodesPeter KidoudouNo ratings yet
- Fast Bit AllocationDocument4 pagesFast Bit AllocationDogancanNo ratings yet
- Conjucted & Optimal DetailsDocument25 pagesConjucted & Optimal DetailsFathima sarjunaNo ratings yet
- Multi-Swarm Pso Algorithm For The Quadratic Assignment Problem: A Massive Parallel Implementation On The Opencl PlatformDocument21 pagesMulti-Swarm Pso Algorithm For The Quadratic Assignment Problem: A Massive Parallel Implementation On The Opencl PlatformJustin WalkerNo ratings yet
- Interpretability of Hinging HyperplanesDocument25 pagesInterpretability of Hinging HyperplanesFabricio CostaNo ratings yet
- Modified Section 07Document10 pagesModified Section 07Eric ShiNo ratings yet
- Easy Multiple Kernel Learning: January 2014Document7 pagesEasy Multiple Kernel Learning: January 2014David GiraldoNo ratings yet
- Geophysical ProblemsDocument1 pageGeophysical ProblemstfakkkNo ratings yet
- Benchmarking: of FFT AlgorithmsDocument3 pagesBenchmarking: of FFT AlgorithmsSubbuNaiduNo ratings yet
- Propellant Rocket MotorsDocument6 pagesPropellant Rocket MotorsTomorrow SwamyNo ratings yet
- Fuel Constrained Economic Emission Load Dispatch Using Hopfield Neural NetworksDocument7 pagesFuel Constrained Economic Emission Load Dispatch Using Hopfield Neural NetworksSujoy DasNo ratings yet
- cadCAD Specification DocumentDocument5 pagescadCAD Specification DocumentDaltonist OggyNo ratings yet
- Journal Pre-Proofs: International Journal of Electronics and Commu-NicationsDocument27 pagesJournal Pre-Proofs: International Journal of Electronics and Commu-NicationspetruskaraNo ratings yet
- Managerial Economics (Pertemuan-5)Document14 pagesManagerial Economics (Pertemuan-5)Daniel LembongNo ratings yet
- ME 6154: Design and Optimization of Energy SystemsDocument2 pagesME 6154: Design and Optimization of Energy SystemsPutumbaka Karthikeya me20b140No ratings yet
- 11 Ijaest Volume No 2 Issue No 2 A Modified Nonlinear Conjugate Gradient Method For Solving Nonlinear Regression Problems 181 186Document6 pages11 Ijaest Volume No 2 Issue No 2 A Modified Nonlinear Conjugate Gradient Method For Solving Nonlinear Regression Problems 181 186iserpNo ratings yet
- Final Exam Paper Design Optimization of SystemsDocument4 pagesFinal Exam Paper Design Optimization of SystemsUday JoshiNo ratings yet
- Optimization Module 2019-1Document64 pagesOptimization Module 2019-1faser04No ratings yet
- Factorisation MemoireDocument21 pagesFactorisation MemoireivanarcilaNo ratings yet
- Medina-Herrera-2-4Document3 pagesMedina-Herrera-2-4Angel Santiago Cabezas LópezNo ratings yet
- Kamesh-2-10Document9 pagesKamesh-2-10Angel Santiago Cabezas LópezNo ratings yet
- Yi Liu-3-8Document6 pagesYi Liu-3-8Angel Santiago Cabezas LópezNo ratings yet
- Liñan-5-12Document8 pagesLiñan-5-12Angel Santiago Cabezas LópezNo ratings yet
- RequirementsDocument14 pagesRequirementsJeannezelle Anne Mariz GazaNo ratings yet
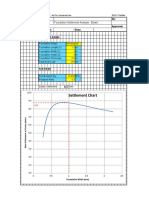
- Settlement Chart: Foundation Settlement Analysis - ElasticDocument2 pagesSettlement Chart: Foundation Settlement Analysis - ElasticCSEC Uganda Ltd.No ratings yet
- Annexure 5.14 BC Mix DesignDocument10 pagesAnnexure 5.14 BC Mix Designmiesty50% (2)
- ITC Johnston Complete Family Pack Font ListDocument2 pagesITC Johnston Complete Family Pack Font ListSenthuTu0% (1)
- Dynamic Strategies For Small BusinessDocument11 pagesDynamic Strategies For Small BusinessBusiness Expert Press0% (1)
- Imanager U2000 ME Release Notes 01 PDFDocument180 pagesImanager U2000 ME Release Notes 01 PDFCamilo Andres OrozcoNo ratings yet
- Jawaban Materi 3Document7 pagesJawaban Materi 3Aminatus MahmudahNo ratings yet
- Cs2252 - MPMC 16 M With Answers Upto 2Document40 pagesCs2252 - MPMC 16 M With Answers Upto 2archumeenabaluNo ratings yet
- Marketing Plan Rental LaptopDocument15 pagesMarketing Plan Rental LaptopDany AkbarNo ratings yet
- Syllabus ChemDocument5 pagesSyllabus ChemDGA GAMINGNo ratings yet
- SynopsisDocument20 pagesSynopsisMohd ShahidNo ratings yet
- DS - 20190709 - E2 - E2 198S-264S Datasheet - V10 - ENDocument13 pagesDS - 20190709 - E2 - E2 198S-264S Datasheet - V10 - ENCristina CorfaNo ratings yet
- Adult Neurological QuestionnaireDocument1 pageAdult Neurological QuestionnaireIqbal BaryarNo ratings yet
- Resume ManikandanDocument3 pagesResume ManikandanPMANIKANDANSVNNo ratings yet
- 29102015000000B - Boehler DCMS-IG - SWDocument1 page29102015000000B - Boehler DCMS-IG - SWErdinc BayatNo ratings yet
- Healthcare SCM in Malaysia - Case StudyDocument10 pagesHealthcare SCM in Malaysia - Case StudyHussain Alam100% (1)
- Whirlpool Refrigerator Ice Water Filter 1 Edr1rxd1 W10295370aDocument1 pageWhirlpool Refrigerator Ice Water Filter 1 Edr1rxd1 W10295370aGreg JohnsonNo ratings yet
- Exercise 7 - Stability Analysis - SolutionsDocument20 pagesExercise 7 - Stability Analysis - SolutionsSuperbVoiceNo ratings yet
- Perfect Email FormulaDocument4 pagesPerfect Email FormulaBallpoitAryanNo ratings yet
- Connector GuideDocument20 pagesConnector GuideBastian VarelaNo ratings yet
- Worksheet BURNSDocument6 pagesWorksheet BURNSRiza Angela BarazanNo ratings yet
- Knowledge RepresentationDocument14 pagesKnowledge RepresentationGonibala LandyNo ratings yet
- Unit 8 Standard Test Test (Z Widoczną Punktacją)Document6 pagesUnit 8 Standard Test Test (Z Widoczną Punktacją)lucjakrzywa2804No ratings yet
- HSE Manager JDDocument2 pagesHSE Manager JDRukun SinagaNo ratings yet
- Assignment On I.T & Pharma IndustryDocument11 pagesAssignment On I.T & Pharma IndustryGolu SinghNo ratings yet
- MT Rating Sheet COTDocument3 pagesMT Rating Sheet COTAilah Mae Dela CruzNo ratings yet
- RoyalBritishBank V TurquanDocument3 pagesRoyalBritishBank V TurquanAlbukhari AliasNo ratings yet
- Endodontic and Restorative Management of A Lower Molar With A Calcified Pulp Chamber.Document7 pagesEndodontic and Restorative Management of A Lower Molar With A Calcified Pulp Chamber.Nicolas SantanderNo ratings yet
- Ejercicios Verbal GREDocument23 pagesEjercicios Verbal GREElena LostaunauNo ratings yet
- Civil Engineering Paper 02Document35 pagesCivil Engineering Paper 02anubhavNo ratings yet