You might also like
- Basic of Intelligence BusinessDocument5 pagesBasic of Intelligence BusinessDhivena JeonNo ratings yet
- Mis QuestionsDocument2 pagesMis QuestionsAdam MirzaNo ratings yet
- RMK 04: IT Foundation of Business Intelligence: Databases &: Information ManagementDocument5 pagesRMK 04: IT Foundation of Business Intelligence: Databases &: Information ManagementEhsanul FahimNo ratings yet
- Mis Report RawrDocument21 pagesMis Report RawrDane ParochaNo ratings yet
- E-Commerce Note BBA 7th Semester Unit V Business InteligenceDocument5 pagesE-Commerce Note BBA 7th Semester Unit V Business InteligenceSant Kumar YadavNo ratings yet
- Databases and Information ManagementDocument2 pagesDatabases and Information ManagementNadya AlexandraNo ratings yet
- Chapter 6 Management Information SystemDocument6 pagesChapter 6 Management Information SystemyogosaeNo ratings yet
- Chapter 6Document8 pagesChapter 6Coci KhouryNo ratings yet
- CT 3Document8 pagesCT 3Rahat fahimNo ratings yet
- Unit 1Document9 pagesUnit 120ACS45 Jeevan rajNo ratings yet
- Organizing Data and InformationDocument11 pagesOrganizing Data and InformationAditya SinghNo ratings yet
- Foundation of Business Intelligence: Databases and Managing InformationDocument36 pagesFoundation of Business Intelligence: Databases and Managing InformationbiaaminNo ratings yet
- Summary Chapter 6 Foundations of Business Intelligence: Databases and Information ManagementDocument2 pagesSummary Chapter 6 Foundations of Business Intelligence: Databases and Information ManagementNiswatun Chaira50% (2)
- CH 6 - Foundations of Business Intelligence Databases and Information ManagementDocument16 pagesCH 6 - Foundations of Business Intelligence Databases and Information ManagementfabianredhatamaNo ratings yet
- Organizing Data and InformationDocument11 pagesOrganizing Data and InformationAditya Singh100% (1)
- MIS442 Chapter 6 DocumentDocument5 pagesMIS442 Chapter 6 DocumentshantoNo ratings yet
- File Organization Terms and ConceptsDocument3 pagesFile Organization Terms and ConceptsClayton Mark CadampogNo ratings yet
- What Are The Main Motivation For A Proper Organisation of A DatabaseDocument6 pagesWhat Are The Main Motivation For A Proper Organisation of A DatabaseSOMOSCONo ratings yet
- Chapter 5: Data Resource Management: Ææñ, Æ Ææ and Ææthese DatabasesDocument4 pagesChapter 5: Data Resource Management: Ææñ, Æ Ææ and Ææthese DatabasesNaiha AbidNo ratings yet
- Data Warehousing AssignmentDocument9 pagesData Warehousing AssignmentRushil Nagwan100% (2)
- 4a - Database SystemsDocument35 pages4a - Database SystemsPrakriti ShresthaNo ratings yet
- Reporter Group 2 Module6Document5 pagesReporter Group 2 Module6maangela TangcoNo ratings yet
- T R 6 SIM - Rio Ananta TariganDocument2 pagesT R 6 SIM - Rio Ananta TariganNur May SaryNo ratings yet
- Database For Exit ExamDocument69 pagesDatabase For Exit ExamTadesse DakabaNo ratings yet
- Introduction To DatabaseDocument4 pagesIntroduction To Databasevalentinembajiogu2020No ratings yet
- BUS 516 - Chapter 6 - Foundations of Business IntelligenceDocument63 pagesBUS 516 - Chapter 6 - Foundations of Business IntelligenceArju LubnaNo ratings yet
- National Certificate in Software Engineering Software Engineering: IDocument102 pagesNational Certificate in Software Engineering Software Engineering: IMelusi DemademaNo ratings yet
- LecDocument29 pagesLecTanvir ArefinNo ratings yet
- Chapter 1 OdbDocument12 pagesChapter 1 OdbMoti King MotiNo ratings yet
- Manual Approach: Chapter OneDocument10 pagesManual Approach: Chapter OneBlack PandaNo ratings yet
- DB Managment Ch1Document4 pagesDB Managment Ch1Juan Manuel Garcia NoguesNo ratings yet
- Iis 4 WeekDocument48 pagesIis 4 WeekYakupNo ratings yet
- Chapter 1 - Introduction To Databases: 2-What Is A DatabaseDocument13 pagesChapter 1 - Introduction To Databases: 2-What Is A DatabaseAWAHNJI JEANNo ratings yet
- Lecture Week: 3 Chapter 3: Database Concepts: Tutorial: Bap 71 AisDocument7 pagesLecture Week: 3 Chapter 3: Database Concepts: Tutorial: Bap 71 AisOdria ArshianaNo ratings yet
- Database Management SystemsDocument84 pagesDatabase Management SystemsTas MimaNo ratings yet
- TM - TSI - 05 Foundation of BI (Part 1)Document26 pagesTM - TSI - 05 Foundation of BI (Part 1)yuli anaNo ratings yet
- Unit 2 DSDocument12 pagesUnit 2 DSMalik SahabNo ratings yet
- Module 6 AssignmentDocument3 pagesModule 6 AssignmentPATRICIA MAE BELENNo ratings yet
- Presentation DIT ON DATABASEDocument6 pagesPresentation DIT ON DATABASENatasha KaberaNo ratings yet
- Unit Iv: Data AND Knowledge ManagementDocument21 pagesUnit Iv: Data AND Knowledge ManagementRodel Novesteras ClausNo ratings yet
- DBMS Topic 1Document9 pagesDBMS Topic 1Cindy CortezNo ratings yet
- Management Information Systems Managing The Digital Firm Canadian 5th Edition Laudon Solutions ManualDocument36 pagesManagement Information Systems Managing The Digital Firm Canadian 5th Edition Laudon Solutions Manualgregoryfinnzvpvga100% (36)
- Management Information Systems Managing The Digital Firm Canadian 5Th Edition Laudon Solutions Manual Full Chapter PDFDocument57 pagesManagement Information Systems Managing The Digital Firm Canadian 5Th Edition Laudon Solutions Manual Full Chapter PDFelizabethciaraqdcank100% (10)
- Rais12 SM CH04Document41 pagesRais12 SM CH04Anton VitaliNo ratings yet
- 12 01 09 10 32 12 1287 Sindhujam PDFDocument23 pages12 01 09 10 32 12 1287 Sindhujam PDFPrasad DhanikondaNo ratings yet
- SYS210 6 7 9 13 RevisionDocument17 pagesSYS210 6 7 9 13 RevisionRefalz AlkhoNo ratings yet
- Itm Mod 3Document25 pagesItm Mod 3SHARMIKA SINGHNo ratings yet
- Questions From Chapter 6Document4 pagesQuestions From Chapter 6Syeda Wahida SabrinaNo ratings yet
- MIS: Database, Lecture-1Document81 pagesMIS: Database, Lecture-1Sunjida EnamNo ratings yet
- Database SystemsDocument6 pagesDatabase Systemsanishagadkari33No ratings yet
- CMP 214Document66 pagesCMP 214Ezekiel JamesNo ratings yet
- Foundations of Business Intelligence: Databases and Information ManagementDocument43 pagesFoundations of Business Intelligence: Databases and Information ManagementArbab AshrafNo ratings yet
- Imperia+++++++L Leadership School Course OutlinesDocument25 pagesImperia+++++++L Leadership School Course Outlinesmuhammad100% (1)
- HO1. Organizing Data and InformationDocument7 pagesHO1. Organizing Data and InformationJulienne SisonNo ratings yet
- Databases - Lecture 1Document21 pagesDatabases - Lecture 1thelangastamperNo ratings yet
- ManaGING DATA - ASSIGNMENTDocument4 pagesManaGING DATA - ASSIGNMENTJasminNo ratings yet
- AssignmentDocument35 pagesAssignmentnepal pokhara100% (1)
- Exploring the Fundamentals of Database Management Systems: Business strategy books, #2From EverandExploring the Fundamentals of Database Management Systems: Business strategy books, #2No ratings yet
- Big Data for Beginners: Data at Scale. Harnessing the Potential of Big Data AnalyticsFrom EverandBig Data for Beginners: Data at Scale. Harnessing the Potential of Big Data AnalyticsNo ratings yet
- Touchless Touchscreen TechnologyDocument16 pagesTouchless Touchscreen TechnologyBlesson thomasNo ratings yet
- Major EPC System VendorsDocument2 pagesMajor EPC System VendorsAvnish ShrivastavaNo ratings yet
- Project Write UpDocument42 pagesProject Write UpMikel KingNo ratings yet
- Web ReactiveDocument175 pagesWeb Reactivemani kanta swamyNo ratings yet
- Main Js EndpointsDocument7 pagesMain Js Endpointspip3lee101No ratings yet
- HLTE321E.11 User ManualV0.1 DOCjmDocument45 pagesHLTE321E.11 User ManualV0.1 DOCjmGajic NevenNo ratings yet
- Network InfoDocument36 pagesNetwork InfoJuanNo ratings yet
- How To Fix Bad Sectors Using HDAT2 Utility On Bootable USB Flash - HDAT2 TutorialDocument11 pagesHow To Fix Bad Sectors Using HDAT2 Utility On Bootable USB Flash - HDAT2 TutorialNelson Marcelo Zanabria RiosNo ratings yet
- Pallab Kumar Biswas: Career ObjectiveDocument4 pagesPallab Kumar Biswas: Career ObjectiveRajesh RoyNo ratings yet
- BBCRM 30Document90 pagesBBCRM 30Zain BabaNo ratings yet
- 515 Manual SPRINT OP 601255.pdf 2Document47 pages515 Manual SPRINT OP 601255.pdf 2Albaz BiomedNo ratings yet
- Know The Escalation Matrix To ReportDocument1 pageKnow The Escalation Matrix To ReportHemal GandhiNo ratings yet
- Axonius Whitepaper - Why Does Asset Management Matter For Cybersecurity - FinalDocument9 pagesAxonius Whitepaper - Why Does Asset Management Matter For Cybersecurity - FinalPradeep PanigrahiNo ratings yet
- Importing Total Station DataDocument12 pagesImporting Total Station DataJose ValverdeNo ratings yet
- SnapLogic Enterprise Automation For DummiesDocument66 pagesSnapLogic Enterprise Automation For DummiesAngel Calero100% (1)
- El 10gexDocument1 pageEl 10gexDhiraj patelNo ratings yet
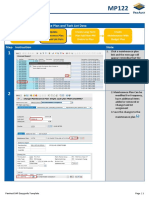
- MP122 - Fcast Maint Plan and Task List DataDocument4 pagesMP122 - Fcast Maint Plan and Task List DataMadhie JokleNo ratings yet
- El Silencio de Galileo ResumenDocument4 pagesEl Silencio de Galileo Resumenc2kzzhdk100% (1)
- Cs101 Solved Mcqs Final Term by JunaidDocument25 pagesCs101 Solved Mcqs Final Term by JunaidWajiha AttiqueNo ratings yet
- Aircraft It Mro v8.4 FinalDocument56 pagesAircraft It Mro v8.4 Finalhero111983No ratings yet
- USB Intelligent Electronic Load Tester: . IntroductionDocument13 pagesUSB Intelligent Electronic Load Tester: . IntroductionRakan HijazeenNo ratings yet
- Archer C80 ( (EU&US) 1.0 - DatasheetDocument8 pagesArcher C80 ( (EU&US) 1.0 - DatasheetRicky1183No ratings yet
- 7.the Marketing Research ProcessDocument3 pages7.the Marketing Research ProcessInshadRT NomanNo ratings yet
- Session Initiation Protocol (SIP) : Dr. Eng. Amr T. Abdel-HamidDocument32 pagesSession Initiation Protocol (SIP) : Dr. Eng. Amr T. Abdel-HamidQuang Man ChiemNo ratings yet
- CryptographyDocument3 pagesCryptographyMinal RayNo ratings yet
- Software Requirement Engineering: Project ProposalDocument2 pagesSoftware Requirement Engineering: Project ProposalMaryam ZaheerNo ratings yet
- Sample MCQ For LinuxDocument15 pagesSample MCQ For Linuxy.alNo ratings yet
- How To Load EIBs - JobAidDocument6 pagesHow To Load EIBs - JobAidYaowenNo ratings yet
- Myanmar Technical Manual Updated June1Document153 pagesMyanmar Technical Manual Updated June1suraj tiwariNo ratings yet
- Supercomputing 2016 Tutorial: Large Scale Visualization With ParaviewDocument234 pagesSupercomputing 2016 Tutorial: Large Scale Visualization With ParaviewHenry PazNo ratings yet