You might also like
- Template Chaos CircuitDocument14 pagesTemplate Chaos CircuitEnrique PriceNo ratings yet
- PrimaDocument14 pagesPrimaMarvin OlavidesNo ratings yet
- Econ 512 Box Jenkins SlidesDocument31 pagesEcon 512 Box Jenkins SlidesMithilesh KumarNo ratings yet
- Beyond LTI SI: Estimating the Kalman Filter from DataDocument13 pagesBeyond LTI SI: Estimating the Kalman Filter from DataSerkan SezinNo ratings yet
- Canonical Quantization C6, HT 2016: 1.1 From Classical To Quantum TheoryDocument19 pagesCanonical Quantization C6, HT 2016: 1.1 From Classical To Quantum Theorycifarha venantNo ratings yet
- Nonlinear Least Squares Theory - Lecture NotesDocument33 pagesNonlinear Least Squares Theory - Lecture NotesAnonymous tsTtieMHDNo ratings yet
- Randomization of Affine Diffusion ProcessesDocument40 pagesRandomization of Affine Diffusion ProcessesBartosz BieganowskiNo ratings yet
- Quantum Annealing Basics and : Hidetoshi NishimoriDocument35 pagesQuantum Annealing Basics and : Hidetoshi Nishimorifisica_musicaNo ratings yet
- State Space Models and The Kalman FilterDocument49 pagesState Space Models and The Kalman FilterMohammadNo ratings yet
- EM Algorithm TutorialDocument35 pagesEM Algorithm TutorialbprtxrcqilmqsvsdhrNo ratings yet
- Optimization of dynamic vibration absorbers for platesDocument6 pagesOptimization of dynamic vibration absorbers for platessundaramaks saravana muruganNo ratings yet
- CET Vol69Document6 pagesCET Vol69minh leNo ratings yet
- sns_2022_중간Document2 pagessns_2022_중간juyeons0204No ratings yet
- MPC Models PDFDocument13 pagesMPC Models PDFpepe sanchezNo ratings yet
- Time Series Analysis and Applications: Homework Please Return (In PDF File) by May 24, 2020Document2 pagesTime Series Analysis and Applications: Homework Please Return (In PDF File) by May 24, 2020roussisd74944No ratings yet
- RECURSIVE IDENTIFICATION ALGORITHMS LIBRARY by NavratilDocument11 pagesRECURSIVE IDENTIFICATION ALGORITHMS LIBRARY by NavratilAli AlmisbahNo ratings yet
- Chapter 2 - Lecture SlidesDocument74 pagesChapter 2 - Lecture SlidesJoel Tan Yi JieNo ratings yet
- PHYS 381 W23 Assignment 4Document8 pagesPHYS 381 W23 Assignment 4Nathan NgoNo ratings yet
- Cs 229, Autumn 2016 Problem Set #2: Naive Bayes, SVMS, and TheoryDocument20 pagesCs 229, Autumn 2016 Problem Set #2: Naive Bayes, SVMS, and TheoryZeeshan Ali SayyedNo ratings yet
- LTIDocument67 pagesLTIElectron FlowNo ratings yet
- Ps 1Document5 pagesPs 1Emre UysalNo ratings yet
- Worksheet IDocument6 pagesWorksheet IAlemayew AzezewNo ratings yet
- discrete fractional calculus whith the nabla operatorDocument12 pagesdiscrete fractional calculus whith the nabla operatordarwin.mamaniNo ratings yet
- ELEC221 HW04 Winter2023-1Document16 pagesELEC221 HW04 Winter2023-1Isha ShuklaNo ratings yet
- File 1323Document8 pagesFile 1323Migle GirsaiteNo ratings yet
- Convergence of the generalized-α scheme for constrained mechanical systemsDocument18 pagesConvergence of the generalized-α scheme for constrained mechanical systemsCesar HernandezNo ratings yet
- 23 Exam 01 SOLv 231025 ADocument5 pages23 Exam 01 SOLv 231025 A이주영No ratings yet
- Tustin's Method For Final State Approximation of Conservative Dynamical SystemsDocument6 pagesTustin's Method For Final State Approximation of Conservative Dynamical SystemsRedkit ofFootHillNo ratings yet
- A Numerical Algorithm Based On Rbfs For Solving An Inverse Source ProblemDocument10 pagesA Numerical Algorithm Based On Rbfs For Solving An Inverse Source ProblemAnibal Coronel PerezNo ratings yet
- Notes On Gans, Energy-Based Models, and Saddle PointsDocument10 pagesNotes On Gans, Energy-Based Models, and Saddle PointsNguyễn ViệtNo ratings yet
- Notes On Gans, Energy-Based Models, and Saddle PointsDocument10 pagesNotes On Gans, Energy-Based Models, and Saddle PointsNguyễn ViệtNo ratings yet
- E9-252 Mathematical methods in signal processing homeworkDocument1 pageE9-252 Mathematical methods in signal processing homeworkChandreshSinghNo ratings yet
- Lecture 8: Bayesian Estimation of Parameters in State Space ModelsDocument33 pagesLecture 8: Bayesian Estimation of Parameters in State Space ModelsTrinh VtnNo ratings yet
- MAST90083 2021 S2 Exam PaperDocument4 pagesMAST90083 2021 S2 Exam Paperxiaotianxue84No ratings yet
- (2019) Piecewise Reproducing Kernel Method For Linear Impulsive Delay Differential Equations With Piecewise Constant ArgumentsDocument10 pages(2019) Piecewise Reproducing Kernel Method For Linear Impulsive Delay Differential Equations With Piecewise Constant ArgumentsAlejandro ChiuNo ratings yet
- Charnes & CooperDocument6 pagesCharnes & CooperBinhNo ratings yet
- The Box-Jenkins MethodDocument14 pagesThe Box-Jenkins MethodAltaf KondakamaralaNo ratings yet
- Advanced Topics in Learning and VisionDocument26 pagesAdvanced Topics in Learning and VisionHemanth MNo ratings yet
- Signals & Systems Questions Set 01Document13 pagesSignals & Systems Questions Set 01Sachin Singh NegiNo ratings yet
- Chapter 2 AgaDocument22 pagesChapter 2 AgaNina AmeduNo ratings yet
- Signals and Systems QuestionsDocument16 pagesSignals and Systems QuestionsVishal KumarNo ratings yet
- CS229 Problem Set #1: Supervised LearningDocument8 pagesCS229 Problem Set #1: Supervised LearningangieNo ratings yet
- MCMC Bayes PDFDocument27 pagesMCMC Bayes PDFMichael TadesseNo ratings yet
- chap5_optimal_controlDocument10 pageschap5_optimal_controlShan Shan BondNo ratings yet
- sns_2021_기말(온라인)Document2 pagessns_2021_기말(온라인)juyeons0204No ratings yet
- 5 On Diagonal Approximations ToDocument14 pages5 On Diagonal Approximations ToAKİF BARBAROS DİKMENNo ratings yet
- MonteCarlo Integration ExtendedDocument52 pagesMonteCarlo Integration ExtendedDaniel CordeiroNo ratings yet
- Методичка Stat. InferenceDocument45 pagesМетодичка Stat. InferenceYehorNo ratings yet
- On Solving Periodic Riccati Equations: A. VargaDocument27 pagesOn Solving Periodic Riccati Equations: A. VargaKarad KaradiasNo ratings yet
- Solving Dynare Eui2014 PDFDocument84 pagesSolving Dynare Eui2014 PDFduc anhNo ratings yet
- Neural Networks for Time Series PredictionDocument42 pagesNeural Networks for Time Series PredictionboynaduaNo ratings yet
- Exam in Automatic Control II Reglerteknik II 5hp: Good Luck!Document10 pagesExam in Automatic Control II Reglerteknik II 5hp: Good Luck!Armando MaloneNo ratings yet
- Ordinary Differential Equations - Initial Value ProblemsDocument20 pagesOrdinary Differential Equations - Initial Value ProblemsAlex DextrNo ratings yet
- Dr Shikongo's I3611IM Lecture NotesDocument116 pagesDr Shikongo's I3611IM Lecture NotesJonas XoxaeNo ratings yet
- Analytical Solution For The Time-Fractional Telegraph EquationDocument14 pagesAnalytical Solution For The Time-Fractional Telegraph EquationhabibNo ratings yet
- 1 s2.0 S0898122109005598 Main PDFDocument12 pages1 s2.0 S0898122109005598 Main PDFWahid wardakNo ratings yet
- Random Functions and Functional Data ClusteringDocument9 pagesRandom Functions and Functional Data ClusteringmimiNo ratings yet
- MD Calculations Notes on Classical SimulationsDocument89 pagesMD Calculations Notes on Classical SimulationsSaga AbdallaNo ratings yet
- Fabricação e Controle de Um Levitador Pneumático Duplo Reverso AcopladoDocument7 pagesFabricação e Controle de Um Levitador Pneumático Duplo Reverso AcopladoclaudyaneNo ratings yet
- ReinforcementDocument6 pagesReinforcementclaudyaneNo ratings yet
- Defining block diagonal and LMI terms for optimization problems in MATLABDocument1 pageDefining block diagonal and LMI terms for optimization problems in MATLABclaudyaneNo ratings yet
- P 5Document1 pageP 5claudyaneNo ratings yet
- P 5Document1 pageP 5claudyaneNo ratings yet
- Hicss 2016Document10 pagesHicss 2016claudyaneNo ratings yet
- Madelein24, 4655Document10 pagesMadelein24, 4655claudyaneNo ratings yet
- Predictive Analysis of Fluid-Hammer Effect On LNG Regasification System Pipeline NetworkDocument6 pagesPredictive Analysis of Fluid-Hammer Effect On LNG Regasification System Pipeline NetworkclaudyaneNo ratings yet
- P 2Document1 pageP 2claudyaneNo ratings yet
- P 45Document1 pageP 45claudyaneNo ratings yet
- P 3Document1 pageP 3claudyaneNo ratings yet
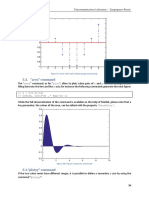
- 5.3. "Area" Command: Telecommunications Laboratory - Zampognaro RosetiDocument1 page5.3. "Area" Command: Telecommunications Laboratory - Zampognaro RoseticlaudyaneNo ratings yet
- Defining block diagonal and LMI terms for optimization problems in MATLABDocument1 pageDefining block diagonal and LMI terms for optimization problems in MATLABclaudyaneNo ratings yet
- Background On Signals and Matlab Operations: Telecommunications Laboratory - Zampognaro RosetiDocument1 pageBackground On Signals and Matlab Operations: Telecommunications Laboratory - Zampognaro RoseticlaudyaneNo ratings yet
- Sampling and Representation of Discrete-Time SignalsDocument1 pageSampling and Representation of Discrete-Time SignalsclaudyaneNo ratings yet
- p39 PDFDocument1 pagep39 PDFclaudyaneNo ratings yet
- 2.6.6 Packages: Python Scientific Lecture Notes, Release 2012.3 (Euroscipy 2012)Document1 page2.6.6 Packages: Python Scientific Lecture Notes, Release 2012.3 (Euroscipy 2012)claudyaneNo ratings yet
- 2.6.5 Scripts or Modules? How To Organize Your Code: Python Scientific Lecture Notes, Release 2012.3 (Euroscipy 2012)Document1 page2.6.5 Scripts or Modules? How To Organize Your Code: Python Scientific Lecture Notes, Release 2012.3 (Euroscipy 2012)claudyaneNo ratings yet
- 2.6.1 Scripts: Python Scientific Lecture Notes, Release 2012.3 (Euroscipy 2012)Document1 page2.6.1 Scripts: Python Scientific Lecture Notes, Release 2012.3 (Euroscipy 2012)claudyaneNo ratings yet
- Figure 8: Stem Command ExampleDocument1 pageFigure 8: Stem Command ExampleclaudyaneNo ratings yet
- 5.2. Plot Post-Processing: Telecommunications Laboratory - Zampognaro RosetiDocument1 page5.2. Plot Post-Processing: Telecommunications Laboratory - Zampognaro RoseticlaudyaneNo ratings yet
- 4.3. Script / Function Control FlowDocument1 page4.3. Script / Function Control FlowclaudyaneNo ratings yet
- Importing Objects From Modules Into The Main Namespace: Python Scientific Lecture Notes, Release 2012.3 (Euroscipy 2012)Document1 pageImporting Objects From Modules Into The Main Namespace: Python Scientific Lecture Notes, Release 2012.3 (Euroscipy 2012)claudyaneNo ratings yet
- 2.5.8 Functions Are Objects: 2.6 Reusing Code: Scripts and ModulesDocument1 page2.5.8 Functions Are Objects: 2.6 Reusing Code: Scripts and ModulesclaudyaneNo ratings yet
- Python Scientific lecture notes, Release 2012.3 (EuroScipy 2012Document1 pagePython Scientific lecture notes, Release 2012.3 (EuroScipy 2012claudyaneNo ratings yet
- Python Scientific Lecture Notes, Release 2012.3 (Euroscipy 2012)Document1 pagePython Scientific Lecture Notes, Release 2012.3 (Euroscipy 2012)claudyaneNo ratings yet
- Python Scientific Lecture Notes, Release 2012.3 (Euroscipy 2012)Document1 pagePython Scientific Lecture Notes, Release 2012.3 (Euroscipy 2012)claudyaneNo ratings yet
- Python Scientific Lecture Notes, Release 2012.3 (Euroscipy 2012)Document1 pagePython Scientific Lecture Notes, Release 2012.3 (Euroscipy 2012)claudyaneNo ratings yet
- 2.5.4 Passed by Value: Python Scientific Lecture Notes, Release 2012.3 (Euroscipy 2012)Document1 page2.5.4 Passed by Value: Python Scientific Lecture Notes, Release 2012.3 (Euroscipy 2012)claudyaneNo ratings yet
- 2001 AMC 10 SolutionsDocument8 pages2001 AMC 10 SolutionsjabagaweeNo ratings yet
- Full Download Introduction To Measure Theoretic Probability 2nd Edition Roussas Solutions ManualDocument6 pagesFull Download Introduction To Measure Theoretic Probability 2nd Edition Roussas Solutions Manualirisybarrous100% (33)
- Hanging ChainDocument5 pagesHanging ChainŞener KılıçNo ratings yet
- Division of Cagayan de Oro City: Concept NotesDocument2 pagesDivision of Cagayan de Oro City: Concept NotesVanessa Jane PanhayNo ratings yet
- Bmat201 PDFDocument5 pagesBmat201 PDFThaanya sNo ratings yet
- Trigonometry Worksheet - 1Document3 pagesTrigonometry Worksheet - 1soina.esNo ratings yet
- 9709 s10 Ms 31Document6 pages9709 s10 Ms 31Hubbak KhanNo ratings yet
- Projective Modules 3. Hairy Ball Theorem 4. Hochster's Example 5. Historical Context ReferencesDocument17 pagesProjective Modules 3. Hairy Ball Theorem 4. Hochster's Example 5. Historical Context ReferencesHiba MansoorNo ratings yet
- Control Systems BasicsDocument17 pagesControl Systems BasicsKaushal FaujdarNo ratings yet
- Vector Bundles and Homogeneous SpacesDocument27 pagesVector Bundles and Homogeneous SpacesCaleb JiNo ratings yet
- Fixed point theorem overviewDocument4 pagesFixed point theorem overviewAsim AmitavNo ratings yet
- Transformations, Shape & Space Revision Notes From GCSE Maths TutorDocument5 pagesTransformations, Shape & Space Revision Notes From GCSE Maths Tutorgcsemathstutor100% (2)
- Malik - Historical and Pedagogical Aspects of The Definition of Function (1980) PDFDocument5 pagesMalik - Historical and Pedagogical Aspects of The Definition of Function (1980) PDFArtemis TrabakoulasNo ratings yet
- CJC 2010 Prelim Math p1Document5 pagesCJC 2010 Prelim Math p1Kenrick KiletNo ratings yet
- Line and Surface Integrals ExplainedDocument1 pageLine and Surface Integrals ExplainedDaniel OrhanNo ratings yet
- Questions & Answers On Maxwell EquationsDocument20 pagesQuestions & Answers On Maxwell Equationskibrom atsbha50% (2)
- Numerical DifferentiationandintegrationDocument79 pagesNumerical DifferentiationandintegrationTaimoor AbbasNo ratings yet
- Ideal Handbook of MathDocument19 pagesIdeal Handbook of MathDurgaNo ratings yet
- Sample Question Paper MathematicsDocument2 pagesSample Question Paper Mathematicsashwani_scribdNo ratings yet
- Stable Adaptive Controller Design for Unknown Linear Time-Invariant PlantsDocument14 pagesStable Adaptive Controller Design for Unknown Linear Time-Invariant Plantsbrunda vishishta iNo ratings yet
- Advance Mechanics of Machines For M.techDocument37 pagesAdvance Mechanics of Machines For M.techMohammedRafeeq91% (11)
- Dsa & CP Roadmap - Resources by Hclub7Document8 pagesDsa & CP Roadmap - Resources by Hclub7AKASH VISHWAKARMANo ratings yet
- Matlab ManualDocument90 pagesMatlab ManualSri Harsha57% (7)
- Measures of Central TendencyDocument40 pagesMeasures of Central TendencyAnagha AnuNo ratings yet
- Bellman FordDocument4 pagesBellman Fordacharya_s2005100% (1)
- Compilation of Maths (9 Nov) - 31 PAGESDocument31 pagesCompilation of Maths (9 Nov) - 31 PAGESMr Ling Tuition CentreNo ratings yet
- Mardesic - Thirty Years of Shape TheoryDocument12 pagesMardesic - Thirty Years of Shape TheoryΧάρης ΦραντζικινάκηςNo ratings yet
- 6 Transportation Problem PDFDocument30 pages6 Transportation Problem PDFchandel08No ratings yet
- Optimal Pairs Trading - A Stochastic Control ApproachDocument5 pagesOptimal Pairs Trading - A Stochastic Control Approachalexa_sherpyNo ratings yet
- ChatGPT Money Machine 2024 - The Ultimate Chatbot Cheat Sheet to Go From Clueless Noob to Prompt Prodigy Fast! Complete AI Beginner’s Course to Catch the GPT Gold Rush Before It Leaves You BehindFrom EverandChatGPT Money Machine 2024 - The Ultimate Chatbot Cheat Sheet to Go From Clueless Noob to Prompt Prodigy Fast! Complete AI Beginner’s Course to Catch the GPT Gold Rush Before It Leaves You BehindNo ratings yet
- Artificial Intelligence: The Insights You Need from Harvard Business ReviewFrom EverandArtificial Intelligence: The Insights You Need from Harvard Business ReviewRating: 4.5 out of 5 stars4.5/5 (104)
- The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our WorldFrom EverandThe Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our WorldRating: 4.5 out of 5 stars4.5/5 (107)
- ChatGPT Millionaire 2024 - Bot-Driven Side Hustles, Prompt Engineering Shortcut Secrets, and Automated Income Streams that Print Money While You Sleep. The Ultimate Beginner’s Guide for AI BusinessFrom EverandChatGPT Millionaire 2024 - Bot-Driven Side Hustles, Prompt Engineering Shortcut Secrets, and Automated Income Streams that Print Money While You Sleep. The Ultimate Beginner’s Guide for AI BusinessNo ratings yet
- ChatGPT Side Hustles 2024 - Unlock the Digital Goldmine and Get AI Working for You Fast with More Than 85 Side Hustle Ideas to Boost Passive Income, Create New Cash Flow, and Get Ahead of the CurveFrom EverandChatGPT Side Hustles 2024 - Unlock the Digital Goldmine and Get AI Working for You Fast with More Than 85 Side Hustle Ideas to Boost Passive Income, Create New Cash Flow, and Get Ahead of the CurveNo ratings yet
- Scary Smart: The Future of Artificial Intelligence and How You Can Save Our WorldFrom EverandScary Smart: The Future of Artificial Intelligence and How You Can Save Our WorldRating: 4.5 out of 5 stars4.5/5 (55)
- Generative AI: The Insights You Need from Harvard Business ReviewFrom EverandGenerative AI: The Insights You Need from Harvard Business ReviewRating: 4.5 out of 5 stars4.5/5 (2)
- AI and Machine Learning for Coders: A Programmer's Guide to Artificial IntelligenceFrom EverandAI and Machine Learning for Coders: A Programmer's Guide to Artificial IntelligenceRating: 4 out of 5 stars4/5 (2)
- The AI Advantage: How to Put the Artificial Intelligence Revolution to WorkFrom EverandThe AI Advantage: How to Put the Artificial Intelligence Revolution to WorkRating: 4 out of 5 stars4/5 (7)
- Machine Learning: The Ultimate Beginner's Guide to Learn Machine Learning, Artificial Intelligence & Neural Networks Step by StepFrom EverandMachine Learning: The Ultimate Beginner's Guide to Learn Machine Learning, Artificial Intelligence & Neural Networks Step by StepRating: 4.5 out of 5 stars4.5/5 (19)
- Your AI Survival Guide: Scraped Knees, Bruised Elbows, and Lessons Learned from Real-World AI DeploymentsFrom EverandYour AI Survival Guide: Scraped Knees, Bruised Elbows, and Lessons Learned from Real-World AI DeploymentsNo ratings yet
- Midjourney Mastery - The Ultimate Handbook of PromptsFrom EverandMidjourney Mastery - The Ultimate Handbook of PromptsRating: 4.5 out of 5 stars4.5/5 (2)
- HBR's 10 Must Reads on AI, Analytics, and the New Machine AgeFrom EverandHBR's 10 Must Reads on AI, Analytics, and the New Machine AgeRating: 4.5 out of 5 stars4.5/5 (69)
- Who's Afraid of AI?: Fear and Promise in the Age of Thinking MachinesFrom EverandWho's Afraid of AI?: Fear and Promise in the Age of Thinking MachinesRating: 4.5 out of 5 stars4.5/5 (13)
- Demystifying Prompt Engineering: AI Prompts at Your Fingertips (A Step-By-Step Guide)From EverandDemystifying Prompt Engineering: AI Prompts at Your Fingertips (A Step-By-Step Guide)Rating: 4 out of 5 stars4/5 (1)
- Artificial Intelligence: A Guide for Thinking HumansFrom EverandArtificial Intelligence: A Guide for Thinking HumansRating: 4.5 out of 5 stars4.5/5 (30)
- 2084: Artificial Intelligence and the Future of HumanityFrom Everand2084: Artificial Intelligence and the Future of HumanityRating: 4 out of 5 stars4/5 (81)
- Mastering Large Language Models: Advanced techniques, applications, cutting-edge methods, and top LLMs (English Edition)From EverandMastering Large Language Models: Advanced techniques, applications, cutting-edge methods, and top LLMs (English Edition)No ratings yet
- Artificial Intelligence: The Complete Beginner’s Guide to the Future of A.I.From EverandArtificial Intelligence: The Complete Beginner’s Guide to the Future of A.I.Rating: 4 out of 5 stars4/5 (15)