You might also like
- Examinations PDFDocument2 pagesExaminations PDFAnonymous 3PU3LxbHNo ratings yet
- Mercedes-Benz Greener Manufacturing AiDocument16 pagesMercedes-Benz Greener Manufacturing AiPuji0% (1)
- QLSTMvsLSTMDocument7 pagesQLSTMvsLSTMmohamedaligharbi20No ratings yet
- PyTorch ImageNet Inference Top-k CSVDocument3 pagesPyTorch ImageNet Inference Top-k CSVVenkatesh WNo ratings yet
- Lstm-Load-Forecasting:6 - All - Features - Ipynb at Master Dafrie:lstm-Load-Forecasting GitHubDocument5 pagesLstm-Load-Forecasting:6 - All - Features - Ipynb at Master Dafrie:lstm-Load-Forecasting GitHubMuhammad Hamdani AzmiNo ratings yet
- Machine LearningDocument54 pagesMachine LearningJacobNo ratings yet
- Sota Image Classification Models With Pytorch ApiDocument10 pagesSota Image Classification Models With Pytorch ApiGuy Anthony NAMA NYAMNo ratings yet
- Configuring GCN Model for TSP ProblemDocument1 pageConfiguring GCN Model for TSP ProblemNicolasNo ratings yet
- Assignment 3 DS5620Document11 pagesAssignment 3 DS5620humaragptNo ratings yet
- PyTorch_Crash_Course__1713016363Document15 pagesPyTorch_Crash_Course__1713016363moussakallaabdoulayeNo ratings yet
- vertopal.com_Font_Transfer_2_autoencodersDocument78 pagesvertopal.com_Font_Transfer_2_autoencoderscloud4nrjNo ratings yet
- Train PyDocument4 pagesTrain PyKarim dabbabiNo ratings yet
- Jaycolpdf 1Document5 pagesJaycolpdf 1P Samyutha 22107849101No ratings yet
- Autoencoder - MPL - Basic - Ipynb - Colaboratory PDFDocument21 pagesAutoencoder - MPL - Basic - Ipynb - Colaboratory PDFushasreeNo ratings yet
- Asep Purnama - 140710180027 - Praktik LSTMDocument9 pagesAsep Purnama - 140710180027 - Praktik LSTMAsepNo ratings yet
- Ilovepdf MergedDocument10 pagesIlovepdf MergedPattranit TeerakosonNo ratings yet
- Q 3 X 1Document4 pagesQ 3 X 1言哲凡No ratings yet
- ML LabDocument7 pagesML LabSharan PatilNo ratings yet
- Backprop Training Neural Net Sum OperationDocument6 pagesBackprop Training Neural Net Sum Operationarun_1328No ratings yet
- assDocument5 pagesassTaqwa ElsayedNo ratings yet
- Trainina A NN BackpropagationDocument6 pagesTrainina A NN Backpropagationarun_1328No ratings yet
- Implementation of Time Series ForecastingDocument12 pagesImplementation of Time Series ForecastingSoba CNo ratings yet
- CodeDocument11 pagesCodemushahedNo ratings yet
- Apex For Bres 1Document6 pagesApex For Bres 1Bless CoNo ratings yet
- MachineDocument45 pagesMachineGagan Sharma100% (1)
- DL Lab ManualDocument35 pagesDL Lab Manuallavanya penumudi100% (1)
- Import TorchDocument4 pagesImport Torchnguyenhuyenn161203No ratings yet
- SampleDocument6 pagesSamplewww.santhoshvjd123No ratings yet
- Aiml LabDocument14 pagesAiml Lab1DT19IS146TriveniNo ratings yet
- tree (2)Document7 pagestree (2)indigalakishoreNo ratings yet
- raw_nitexDocument5 pagesraw_nitexneel neelantiNo ratings yet
- Object Detection WebcamDocument3 pagesObject Detection Webcammoh.yanni fikriNo ratings yet
- Data MiningDocument20 pagesData Mining21800768No ratings yet
- PytorchDocument4 pagesPytorchYong-Jun ChamNo ratings yet
- CodeDocument2 pagesCodetiko bossNo ratings yet
- Chap 3.1 Embedding in TensorflowDocument23 pagesChap 3.1 Embedding in TensorflowHRITWIK GHOSHNo ratings yet
- Python CprofileDocument5 pagesPython CprofilekhonelloNo ratings yet
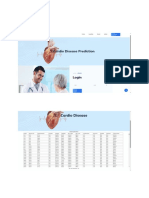
- Cardio Screen RFDocument27 pagesCardio Screen RFThe Mind100% (1)
- Load Libraries Keras CNN URL MaliciousnessDocument10 pagesLoad Libraries Keras CNN URL MaliciousnessSree Ram PavanNo ratings yet
- ML 1-10Document53 pagesML 1-1022128008No ratings yet
- ML - LAB - 7 - Jupyter NotebookDocument7 pagesML - LAB - 7 - Jupyter Notebooksuman100% (1)
- Exe 1Document13 pagesExe 1jaya pandiNo ratings yet
- 22MCA1008 - Varun ML LAB ASSIGNMENTSDocument41 pages22MCA1008 - Varun ML LAB ASSIGNMENTSS Varun (RA1931241020133)100% (1)
- LAB 2 Transfer LearningDocument10 pagesLAB 2 Transfer Learningmbjanjua35No ratings yet
- Machine LearninDocument23 pagesMachine LearninManoj Kumar 1183100% (1)
- PyTorch RRDB Image Super-ResolutionDocument1 pagePyTorch RRDB Image Super-Resolutiondxb ydtNo ratings yet
- codeDocument6 pagescodeKeerti GulatiNo ratings yet
- ML Lab Manual PDFDocument9 pagesML Lab Manual PDFAnonymous KvIcYFNo ratings yet
- ModelsDocument2 pagesModelsMinh SơnNo ratings yet
- J AGS Tutor IalDocument4 pagesJ AGS Tutor IalDemis AndradeNo ratings yet
- Tarea - Predecir Dígitos Manuscritos Con SVM RadialDocument5 pagesTarea - Predecir Dígitos Manuscritos Con SVM RadialNuñez Velez MelisaNo ratings yet
- Prototype 13Document1 pagePrototype 13Yemi TowobolaNo ratings yet
- Assignment10 3Document4 pagesAssignment10 3dashNo ratings yet
- Convolutional Neural Net seismic facies classificationDocument30 pagesConvolutional Neural Net seismic facies classificationAlejandro Garza JuárezNo ratings yet
- 20MIS1025 - DecisionTree - Ipynb - ColaboratoryDocument4 pages20MIS1025 - DecisionTree - Ipynb - ColaboratorySandip DasNo ratings yet
- C121 Exp1Document32 pagesC121 Exp1Devanshu MaheshwariNo ratings yet
- Ai LabDocument15 pagesAi Lab4653Anushika PatelNo ratings yet
- siamese-network-assignmentDocument3 pagessiamese-network-assignmentheat massNo ratings yet
- Bearing Failure Detection Using Autoencoder Neural Network (AE NNDocument16 pagesBearing Failure Detection Using Autoencoder Neural Network (AE NNAhmedNo ratings yet
- Python Lab File ExampleDocument20 pagesPython Lab File Example50 Mohit SharmaNo ratings yet
- CTA Full DocumentDocument35 pagesCTA Full DocumentThe MindNo ratings yet
- Student TrackerDocument36 pagesStudent TrackerThe MindNo ratings yet
- Voice Based ATMDocument29 pagesVoice Based ATMThe MindNo ratings yet
- Flask Forest Ranger Registration & LoginDocument4 pagesFlask Forest Ranger Registration & LoginThe MindNo ratings yet
- Animal Repellent - FullDocument58 pagesAnimal Repellent - FullThe Mind100% (1)
- Cardio-Screenshot OnlyDocument10 pagesCardio-Screenshot OnlyThe MindNo ratings yet
- Cardio Screen RFDocument27 pagesCardio Screen RFThe Mind100% (1)
- Animal Monitoring Screen CodeDocument17 pagesAnimal Monitoring Screen CodeThe MindNo ratings yet
- Chapter 2Document11 pagesChapter 2The MindNo ratings yet
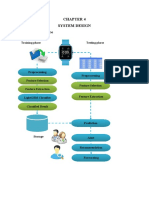
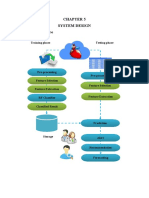
- System Design System Architecture: Training Phase Testing PhaseDocument1 pageSystem Design System Architecture: Training Phase Testing PhaseThe MindNo ratings yet
- Cardio Disease - Full Document - LightGBMDocument29 pagesCardio Disease - Full Document - LightGBMThe MindNo ratings yet
- Use case diagram for depression detection web appDocument5 pagesUse case diagram for depression detection web appThe MindNo ratings yet
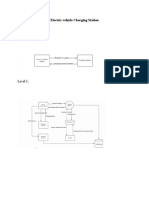
- EV Charging Station Data Flow DiagramDocument2 pagesEV Charging Station Data Flow DiagramThe MindNo ratings yet
- Chapter 5Document2 pagesChapter 5The MindNo ratings yet
- Face Door Lock System - Full ReportDocument59 pagesFace Door Lock System - Full ReportThe MindNo ratings yet
- Fake Review - AbstractDocument2 pagesFake Review - AbstractThe MindNo ratings yet
- Use Case Diagram: LoginDocument5 pagesUse Case Diagram: LoginThe MindNo ratings yet
- Use Case DiagramDocument8 pagesUse Case DiagramThe MindNo ratings yet
- Protect Women From Abuse and Assure Immediate SafetyDocument6 pagesProtect Women From Abuse and Assure Immediate SafetyDinesh KrishnanNo ratings yet
- Data Storage MediaDocument13 pagesData Storage MediaArindam DasNo ratings yet
- How-TO Add Custom SIP Account in Nimbuzz (Tutorial) - TruVoIPBuzz PDFDocument9 pagesHow-TO Add Custom SIP Account in Nimbuzz (Tutorial) - TruVoIPBuzz PDFmuthuswamy77No ratings yet
- IR Remote Control Decoder Using Arduino - IR Remote DecoderDocument15 pagesIR Remote Control Decoder Using Arduino - IR Remote Decoderحارث اكرمNo ratings yet
- Huawei AP5030DN AP5130DN BrochureDocument9 pagesHuawei AP5030DN AP5130DN BrochureUdayanga Sanjeewa WickramasingheNo ratings yet
- Cloud Log - PreviousDocument277 pagesCloud Log - PreviousB AuNo ratings yet
- ANIMATED INITIALDocument10 pagesANIMATED INITIALAhmed KhalidNo ratings yet
- RDC6334G Biref EnglishDocument4 pagesRDC6334G Biref EnglishJuanjo AcvdoNo ratings yet
- CompTIA Network+ Certification Practice Test 1 (Exam N10-006)Document10 pagesCompTIA Network+ Certification Practice Test 1 (Exam N10-006)LostbyondthevoidNo ratings yet
- Face Recognition TechnologyDocument9 pagesFace Recognition TechnologySireesha TekuruNo ratings yet
- Release 12 Focus On Supply Chain Management: Goetz Schmitz Chuck Kennedy May, 2008Document51 pagesRelease 12 Focus On Supply Chain Management: Goetz Schmitz Chuck Kennedy May, 2008Wijana NugrahaNo ratings yet
- Hanumantha Rao Resume-1 (4391)Document4 pagesHanumantha Rao Resume-1 (4391)Aarish AcharyaNo ratings yet
- Computer Architecture SyllabusDocument2 pagesComputer Architecture SyllabusreneNo ratings yet
- Robobrain: Large-Scale Knowledge Engine For RobotsDocument10 pagesRobobrain: Large-Scale Knowledge Engine For RobotsGabriela IvanNo ratings yet
- Aas-28 1 11 0-RNDocument56 pagesAas-28 1 11 0-RNGeorge JR BagsaoNo ratings yet
- Big Data Workshop ContentsDocument2 pagesBig Data Workshop ContentsSunil PatilNo ratings yet
- CIS Oracle Linux 7 Benchmark v1.0.0Document171 pagesCIS Oracle Linux 7 Benchmark v1.0.0Johan Louwers100% (1)
- AWT and Event Handling in JavaDocument60 pagesAWT and Event Handling in JavaAsmatullah KhanNo ratings yet
- Foxboro Control Software Scripting With Direct Access User's GuideDocument294 pagesFoxboro Control Software Scripting With Direct Access User's GuideDaniel100% (1)
- Compare Bex Queries in Different Client System PDFDocument9 pagesCompare Bex Queries in Different Client System PDFnithesh nithuNo ratings yet
- App Arch Guide 2.0 OverviewDocument38 pagesApp Arch Guide 2.0 OverviewkharpohNo ratings yet
- VFACE TOUCH AND BASIC QUICK INSTALLATION GUIDEDocument2 pagesVFACE TOUCH AND BASIC QUICK INSTALLATION GUIDEPunith RajNo ratings yet
- PX 208 Product Brochure Print File (PX208 - PB - 04NOV10revC - PF)Document4 pagesPX 208 Product Brochure Print File (PX208 - PB - 04NOV10revC - PF)Charles LiNo ratings yet
- 2.1 Elements of Computational ThinkingDocument25 pages2.1 Elements of Computational ThinkingHamdi QasimNo ratings yet
- Paperback Fundamentals of Aerodynamics 210423090748Document9 pagesPaperback Fundamentals of Aerodynamics 210423090748riyaz ahmedNo ratings yet
- Data Driven Governance Competency Guide: Resource PersonDocument42 pagesData Driven Governance Competency Guide: Resource PersonJayson VelascoNo ratings yet
- Lines Trunks and Routing GuideDocument342 pagesLines Trunks and Routing GuideViswanath100% (1)
- Spring @Value annotation guideDocument94 pagesSpring @Value annotation guideFake EmailNo ratings yet
- 3 Steps To Find The Standard Cost For A Configurable ProductDocument2 pages3 Steps To Find The Standard Cost For A Configurable ProductRhico100% (5)