You might also like
- CV RecordDocument48 pagesCV RecordLakshya KarwaNo ratings yet
- CD 601 Lab ManualDocument61 pagesCD 601 Lab ManualSatya Prakash SoniNo ratings yet
- DeepLearningForVisionSystems Ch5 AlexNetDocument32 pagesDeepLearningForVisionSystems Ch5 AlexNetmkkadambiNo ratings yet
- TPCV1+2+3+4.ipynb - ColaboratoryDocument70 pagesTPCV1+2+3+4.ipynb - Colaboratorydouaa khilaNo ratings yet
- Initializing Input and Batch SizesDocument15 pagesInitializing Input and Batch SizesmkkadambiNo ratings yet
- Machine LearningDocument54 pagesMachine LearningJacobNo ratings yet
- Font Transfer 2 AutoencodersDocument78 pagesFont Transfer 2 Autoencoderscloud4nrjNo ratings yet
- Fresco Code Python Application ProgrammingDocument7 pagesFresco Code Python Application ProgrammingTECHer YTNo ratings yet
- AssDocument5 pagesAssTaqwa ElsayedNo ratings yet
- Apex For Bres 1Document6 pagesApex For Bres 1Bless CoNo ratings yet
- Ai LabDocument15 pagesAi Lab4653Anushika PatelNo ratings yet
- DIP Lab AssignmentsDocument33 pagesDIP Lab Assignmentsrr3870044No ratings yet
- CV Lab ExperimentsDocument10 pagesCV Lab ExperimentsIt's MeNo ratings yet
- CNN Numpy 1st HandsonDocument5 pagesCNN Numpy 1st HandsonJohn Solomon100% (1)
- Jaycolpdf 1Document5 pagesJaycolpdf 1P Samyutha 22107849101No ratings yet
- Gulshan - DIP - Lab - Programs (11 To 20)Document37 pagesGulshan - DIP - Lab - Programs (11 To 20)rr3870044No ratings yet
- Assignment 3 DS5620Document11 pagesAssignment 3 DS5620humaragptNo ratings yet
- EE 559 HW2Code PDFDocument7 pagesEE 559 HW2Code PDFAliNo ratings yet
- Ai Games - Round 2Document2 pagesAi Games - Round 2ANURABNo ratings yet
- Example PythonDocument4 pagesExample PythonAsif RazaNo ratings yet
- PredictDocument3 pagesPredictVenkatesh WNo ratings yet
- Exe 1Document13 pagesExe 1jaya pandiNo ratings yet
- 1 - Standard Linear Regression: Numpy NP PandasDocument4 pages1 - Standard Linear Regression: Numpy NP PandasWahib NakhoulNo ratings yet
- IchcgDocument31 pagesIchcgarman khanNo ratings yet
- CS5242 Assignment 2Document12 pagesCS5242 Assignment 2Ajith ShenoyNo ratings yet
- Transfer Learning For Image Classification in PytorchDocument13 pagesTransfer Learning For Image Classification in PytorchMinusha TehaniNo ratings yet
- Pattern Recognition LabDocument24 pagesPattern Recognition LabPrashant KumarNo ratings yet
- V1 Receptive Fields Through Efficient Coding - HW2Document4 pagesV1 Receptive Fields Through Efficient Coding - HW2carolinac1256No ratings yet
- Lab 4-Image Segmentation Using U-NetDocument9 pagesLab 4-Image Segmentation Using U-Netmbjanjua35No ratings yet
- Cats and Dogs Classification Using CNNDocument3 pagesCats and Dogs Classification Using CNNravali. chintamaaniNo ratings yet
- Algoritmo3 2Document6 pagesAlgoritmo3 2hilmehirziNo ratings yet
- MainDocument1 pageMainNicolasNo ratings yet
- Laporan Final Project AcvkDocument5 pagesLaporan Final Project Acvkfrizal adityaNo ratings yet
- CodeDocument4 pagesCodeThinh HoangNo ratings yet
- Prelab GMM 1Document5 pagesPrelab GMM 1lamtayazaissatNo ratings yet
- ComputerGraphicsNotesWeek9 01 0418Document6 pagesComputerGraphicsNotesWeek9 01 0418MD KAMRUZZAMANNo ratings yet
- IVPAss 2Document3 pagesIVPAss 2sidkot27No ratings yet
- Assignment 11-17-15: Michael Petzold November 19, 2015Document4 pagesAssignment 11-17-15: Michael Petzold November 19, 2015mikey pNo ratings yet
- AIML Lab ProgDocument15 pagesAIML Lab ProgGreen MongorNo ratings yet
- Daftar Lampiran Coding Python RecognizeDocument7 pagesDaftar Lampiran Coding Python RecognizeResha Noviane PutriNo ratings yet
- ps2 Macro Bongioanni TXTDocument4 pagesps2 Macro Bongioanni TXTGuido BongioanniNo ratings yet
- Data MiningDocument20 pagesData Mining21800768No ratings yet
- Code ExplainDocument4 pagesCode ExplainThinh HoangNo ratings yet
- Fresco Code Python Application ProgrammingDocument7 pagesFresco Code Python Application ProgrammingRay90% (20)
- SVMDocument2 pagesSVMRUpoe03No ratings yet
- FrescoDocument17 pagesFrescovinay100% (2)
- Aiml LabDocument14 pagesAiml Lab1DT19IS146TriveniNo ratings yet
- PE17 PortezDocument1 pagePE17 PortezAlex PortezNo ratings yet
- ResNet50 Training CodeDocument9 pagesResNet50 Training Codenatashamarie.relampagosNo ratings yet
- PyTorch Crash Course 1713016363Document15 pagesPyTorch Crash Course 1713016363moussakallaabdoulayeNo ratings yet
- Raw NitexDocument5 pagesRaw Nitexneel neelantiNo ratings yet
- Training CodeDocument27 pagesTraining CodeThe MindNo ratings yet
- Code mẫu bài tập 4Document9 pagesCode mẫu bài tập 4Bảo ĐoànNo ratings yet
- Python TCSDocument6 pagesPython TCSJyotirmay Sahu0% (1)
- Back Propogation TrainingDocument6 pagesBack Propogation Trainingarun_1328No ratings yet
- In This Hands-On You Will Be Performing CNN Operations Using Tensorflow PackageDocument6 pagesIn This Hands-On You Will Be Performing CNN Operations Using Tensorflow PackageJohn SolomonNo ratings yet
- Lecture 22Document64 pagesLecture 22Tev WallaceNo ratings yet
- MalenoV Code 5 Layer CNN 65x65x65 VoxelsDocument30 pagesMalenoV Code 5 Layer CNN 65x65x65 VoxelsAlejandro Garza JuárezNo ratings yet
- CTA Full DocumentDocument35 pagesCTA Full DocumentThe MindNo ratings yet
- Student TrackerDocument36 pagesStudent TrackerThe MindNo ratings yet
- Voice Based ATMDocument29 pagesVoice Based ATMThe MindNo ratings yet
- Training CodeDocument27 pagesTraining CodeThe MindNo ratings yet
- Wildlife ScreenDocument4 pagesWildlife ScreenThe MindNo ratings yet
- Animal Repellent - FullDocument58 pagesAnimal Repellent - FullThe Mind100% (1)
- Cardio Screen RFDocument27 pagesCardio Screen RFThe Mind100% (1)
- Chapter 2Document11 pagesChapter 2The MindNo ratings yet
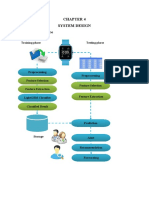
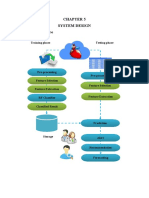
- System Design System Architecture: Training Phase Testing PhaseDocument1 pageSystem Design System Architecture: Training Phase Testing PhaseThe MindNo ratings yet
- Chapter 5Document2 pagesChapter 5The MindNo ratings yet
- Cardio Disease - Full Document - LightGBMDocument29 pagesCardio Disease - Full Document - LightGBMThe MindNo ratings yet
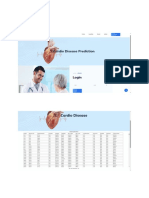
- Cardio-Screenshot OnlyDocument10 pagesCardio-Screenshot OnlyThe MindNo ratings yet
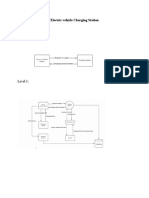
- Level 0:: Electric Vehicle Charging Station Data Flow DiagramDocument2 pagesLevel 0:: Electric Vehicle Charging Station Data Flow DiagramThe MindNo ratings yet
- Face Door Lock System - Full ReportDocument59 pagesFace Door Lock System - Full ReportThe MindNo ratings yet
- Use Case Diagram: LoginDocument5 pagesUse Case Diagram: LoginThe MindNo ratings yet
- Use Case Diagram: LoginDocument5 pagesUse Case Diagram: LoginThe MindNo ratings yet
- Use Case DiagramDocument8 pagesUse Case DiagramThe MindNo ratings yet
- Examination of The Patient - StereopsisDocument10 pagesExamination of The Patient - StereopsisJLoNo ratings yet
- IRIS Recognition Technique Through Douglas MethodDocument27 pagesIRIS Recognition Technique Through Douglas MethodVidya MoolyaNo ratings yet
- ALP TerminologyDocument5 pagesALP TerminologyBhavin KothariNo ratings yet
- Evaluating Existing China Military Camouflage Designs Using Camouflage Similarity Index (CSI)Document5 pagesEvaluating Existing China Military Camouflage Designs Using Camouflage Similarity Index (CSI)peter.naglicNo ratings yet
- Nikkor Z Lenses Comparison ChartDocument2 pagesNikkor Z Lenses Comparison ChartNikonRumors50% (2)
- Arts Appreciation WEEK 5Document5 pagesArts Appreciation WEEK 5Andrea Nicole De LeonNo ratings yet
- Nikon 50mm F - 1Document49 pagesNikon 50mm F - 1Abar ZuhaitzNo ratings yet
- Week 18 - SDL Preview QuestionsDocument3 pagesWeek 18 - SDL Preview QuestionsAAMNA HAROONNo ratings yet
- An Investigation in Satellite Images Based On Image Enhancement TechniquesDocument10 pagesAn Investigation in Satellite Images Based On Image Enhancement TechniquessreeshpsNo ratings yet
- Kursus Adobe PhotoshopDocument2 pagesKursus Adobe PhotoshopAzlan AzmiNo ratings yet
- CatalogxtsDocument215 pagesCatalogxtsAimee chaconNo ratings yet
- Folk ArtDocument6 pagesFolk ArtjenilenNo ratings yet
- Direct and Indirect FinalDocument31 pagesDirect and Indirect Finalmeenali karnNo ratings yet
- Tabela de Cores em HTMLDocument16 pagesTabela de Cores em HTMLCarlos Eduardo ObaraNo ratings yet
- The Focimeter - Measuring Eyeglass Lenses: Including This Notice. Brief Excerpts May Be Reproduced With CreditDocument34 pagesThe Focimeter - Measuring Eyeglass Lenses: Including This Notice. Brief Excerpts May Be Reproduced With CreditEugen Dumitrescu100% (1)
- Escalus SlidesCarnivalDocument48 pagesEscalus SlidesCarnivalbagusNo ratings yet
- Feldmans MethodDocument23 pagesFeldmans Methodjennifer_e_smit8701100% (1)
- Understanding The EOS M50 PreviewDocument21 pagesUnderstanding The EOS M50 PreviewVenkatesan SundaramNo ratings yet
- Achieving Excellence in Cataract Surgery - Chapter 12Document14 pagesAchieving Excellence in Cataract Surgery - Chapter 12Arif MohammadNo ratings yet
- Canon EF 50mm F 1 8 STM Eng PRDocument4 pagesCanon EF 50mm F 1 8 STM Eng PRermald1No ratings yet
- A Comparison of Tests For Quantifying Sensory Eye DominanceDocument10 pagesA Comparison of Tests For Quantifying Sensory Eye DominanceBONNo ratings yet
- Free Abstract Ink PPT Templates: Insert The Subtitle of Your PresentationDocument48 pagesFree Abstract Ink PPT Templates: Insert The Subtitle of Your PresentationWindha Sari TawilNo ratings yet
- PHOTOGRAPHYDocument21 pagesPHOTOGRAPHYCristine Joy GabiazonNo ratings yet
- Adobe Lightroom 3Document18 pagesAdobe Lightroom 3Lynn Daniel-GloverNo ratings yet
- Magic Lantern User GuideDocument56 pagesMagic Lantern User Guidetommy900No ratings yet
- Listado de Filamentos Vendidos Por SunluDocument2 pagesListado de Filamentos Vendidos Por SunluUriel MendozaNo ratings yet
- PEDRO Men ESSDocument38 pagesPEDRO Men ESSMuhammad Rizky ulumNo ratings yet
- Simplified-Phacoemulsification - 2013 PDFDocument247 pagesSimplified-Phacoemulsification - 2013 PDFRaulLopezJaime100% (3)
- Consent FormsDocument111 pagesConsent Formsbug1lovebug2-1100% (1)
- Berikut Tabel Lengkap Mengenai List Kode Warna Hexadecimal:: Gray39Document8 pagesBerikut Tabel Lengkap Mengenai List Kode Warna Hexadecimal:: Gray39Junk KissNo ratings yet