You might also like
- Coronary Heart Disease: A Guide to Diagnosis and TreatmentFrom EverandCoronary Heart Disease: A Guide to Diagnosis and TreatmentRating: 3.5 out of 5 stars3.5/5 (3)
- Cardiovascular DiseaseDocument22 pagesCardiovascular DiseaseSunday JamesNo ratings yet
- Healthy HeartDocument58 pagesHealthy Heartswaroopraj147No ratings yet
- Cardio Vascular SystemDocument22 pagesCardio Vascular SystemdeborahNo ratings yet
- Coronary Artery Disease ExplainedDocument109 pagesCoronary Artery Disease ExplainedPriyaNo ratings yet
- Cardiovascular DiseasesDocument52 pagesCardiovascular DiseasesAMAN KUMAR JHANo ratings yet
- Kurmabekov Ilim: The Heart: Anatomy, Physiology, and Functi OnDocument16 pagesKurmabekov Ilim: The Heart: Anatomy, Physiology, and Functi OnILIM KURMANBEKOVNo ratings yet
- Health ReproductionDocument2 pagesHealth ReproductionLelouch vBritaniaNo ratings yet
- Contant of The ResourcesDocument2 pagesContant of The Resources200838927No ratings yet
- CC CCCCCC C CC CCCCCCC CCC C !C !C!C !C!C!C !C"!C #!C!C!C !C!C!C!C !C#C C$ C C C CC CCC CC C C%$CC÷ ÷÷ CC&CCCC C CCDocument10 pagesCC CCCCCC C CC CCCCCCC CCC C !C !C!C !C!C!C !C"!C #!C!C!C !C!C!C!C !C#C C$ C C C CC CCC CC C C%$CC÷ ÷÷ CC&CCCC C CCHrithik RaiNo ratings yet
- Segundo CorteDocument4 pagesSegundo CorteNicolasNo ratings yet
- Gen Bio (Circulatory System)Document18 pagesGen Bio (Circulatory System)Kit KathNo ratings yet
- Circulatory SystemDocument2 pagesCirculatory SystemEduardo DiazNo ratings yet
- HeartDocument53 pagesHeartmafe1432No ratings yet
- Anatomy Case StudyDocument15 pagesAnatomy Case StudyHazreen HazwanyNo ratings yet
- Cardiovascular SystemDocument5 pagesCardiovascular SystemDrexel DalaygonNo ratings yet
- Cardiac Function Tests ExplainedDocument8 pagesCardiac Function Tests ExplainedJosiah BimabamNo ratings yet
- Assignment # 3: Circulatory SystemDocument5 pagesAssignment # 3: Circulatory SystemJefferNo ratings yet
- Cardiac Control CentreDocument8 pagesCardiac Control CentregeorgeloxdaleNo ratings yet
- Circulatory System FunctionsDocument18 pagesCirculatory System FunctionsEmmanuel VillafuerteNo ratings yet
- CHD Sahil ThesisDocument78 pagesCHD Sahil Thesismanwanim18No ratings yet
- Makalah Bahasa InggrisDocument20 pagesMakalah Bahasa InggrisInas NadaaNo ratings yet
- Draw and Label The Different Organs Related To The Cardiovascular System. HeartDocument10 pagesDraw and Label The Different Organs Related To The Cardiovascular System. HeartShainaChescaEvansNo ratings yet
- Circulatory System AssignmentDocument8 pagesCirculatory System AssignmentMonroe P ZosaNo ratings yet
- Cardio Respiratory Endurance Mam PascoDocument13 pagesCardio Respiratory Endurance Mam PascoDavid GoliathNo ratings yet
- Heart Disease: Symptoms of Heart Disease in Your Blood Vessels (Atherosclerotic Disease)Document22 pagesHeart Disease: Symptoms of Heart Disease in Your Blood Vessels (Atherosclerotic Disease)Kenneth Jay EdnacoNo ratings yet
- Cardio Vascular SystemDocument7 pagesCardio Vascular SystemMomen HagagNo ratings yet
- MYOCARDITIS: THE INFLAMMATION OF THE HEART MUSCLEDocument52 pagesMYOCARDITIS: THE INFLAMMATION OF THE HEART MUSCLE7337man100% (1)
- Cardiovasular SystemDocument5 pagesCardiovasular SystemAsher Eby VargeeseNo ratings yet
- Chapter I - Cardiovascular System: HeartDocument2 pagesChapter I - Cardiovascular System: HeartIndranil SinhaNo ratings yet
- Understanding How Your Heart FunctionsDocument4 pagesUnderstanding How Your Heart FunctionsthenameisvijayNo ratings yet
- Loreto, Bien BMG3FX/MWF/3:00-04:00 Lugo, Mariel Cabigao, JeanDocument4 pagesLoreto, Bien BMG3FX/MWF/3:00-04:00 Lugo, Mariel Cabigao, JeanJean CabigaoNo ratings yet
- Angina PectorisDocument20 pagesAngina PectorisJyoti singhNo ratings yet
- Chapter 1 - The Cardiovascular SystemDocument22 pagesChapter 1 - The Cardiovascular SystemHoa LoNo ratings yet
- How The Heart WorksDocument11 pagesHow The Heart Worksprasanta_bbsrNo ratings yet
- Heart DiseaseDocument38 pagesHeart DiseaseDr.Sunil KumarNo ratings yet
- Heart Health GuideDocument7 pagesHeart Health GuideYAO CESAR KOFFINo ratings yet
- Cad - Coronary Artery Disease & Myocardial InfarctionDocument6 pagesCad - Coronary Artery Disease & Myocardial Infarctionmaulikmd21No ratings yet
- The Heart: Mariam MohammedDocument16 pagesThe Heart: Mariam Mohammedmemomnmnm78No ratings yet
- University of Goce Delcev StipDocument11 pagesUniversity of Goce Delcev StipviktorijatalevskaNo ratings yet
- Cardiovascular SystemDocument2 pagesCardiovascular Systemmitsuki_sylphNo ratings yet
- Anatomy Physiology HeartDocument9 pagesAnatomy Physiology HeartAlvheen JoaquinNo ratings yet
- Project BioDocument18 pagesProject Bioyanshu falduNo ratings yet
- Components of The Cardiovascular SystemDocument5 pagesComponents of The Cardiovascular SystemLorinaNo ratings yet
- Circulatory System and Heart Biology Summarisation.Document5 pagesCirculatory System and Heart Biology Summarisation.Jumana ElkhateebNo ratings yet
- Coronary Artery DiseaseDocument3 pagesCoronary Artery DiseaseAlan Valencia Baya Jr.No ratings yet
- Structure and Function of the HeartDocument5 pagesStructure and Function of the Heartdrowned_clarkeNo ratings yet
- The Human Heart: Location, Size and ShapeDocument9 pagesThe Human Heart: Location, Size and ShapeL I G-Arijit HisabiaNo ratings yet
- Heart Failure In-Depth Report: Causes, Symptoms, and TreatmentDocument11 pagesHeart Failure In-Depth Report: Causes, Symptoms, and Treatmentastro1211No ratings yet
- Unit Seven: Cardiovascular SystemDocument10 pagesUnit Seven: Cardiovascular SystemKath RubioNo ratings yet
- 3.4 - The Circulatory SystemDocument3 pages3.4 - The Circulatory SystemDjejNo ratings yet
- Screenshot 2022-09-01 at 5.39.08 PMDocument1 pageScreenshot 2022-09-01 at 5.39.08 PMTrishia EspejaNo ratings yet
- Final Case Study - CADDocument109 pagesFinal Case Study - CADPatricia Marie Buenafe100% (1)
- Chapter 12Document4 pagesChapter 12Jose Douglas VelasquezNo ratings yet
- Anatomy of Heart - RyanDocument5 pagesAnatomy of Heart - Ryandrowned_clarkeNo ratings yet
- Structure and Function of the HeartDocument5 pagesStructure and Function of the Heartdrowned_clarkeNo ratings yet
- Prevention of Cardiovascular DiseasesDocument27 pagesPrevention of Cardiovascular DiseaseskennfenwNo ratings yet
- Human Heart ScienceDocument7 pagesHuman Heart ScienceJewel Kathryn MorenoNo ratings yet
- Circulation NotesDocument2 pagesCirculation NotesBhkti MittalNo ratings yet
- Animal Monitoring Screen CodeDocument17 pagesAnimal Monitoring Screen CodeThe MindNo ratings yet
- Student TrackerDocument36 pagesStudent TrackerThe MindNo ratings yet
- Voice Based ATMDocument29 pagesVoice Based ATMThe MindNo ratings yet
- CTA Full DocumentDocument35 pagesCTA Full DocumentThe MindNo ratings yet
- Animal Repellent - FullDocument58 pagesAnimal Repellent - FullThe Mind100% (1)
- Cardio Screen RFDocument27 pagesCardio Screen RFThe Mind100% (1)
- Training CodeDocument27 pagesTraining CodeThe MindNo ratings yet
- Flask Forest Ranger Registration & LoginDocument4 pagesFlask Forest Ranger Registration & LoginThe MindNo ratings yet
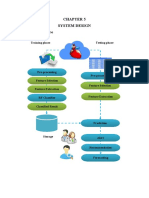
- System Design System Architecture: Training Phase Testing PhaseDocument1 pageSystem Design System Architecture: Training Phase Testing PhaseThe MindNo ratings yet
- Face Door Lock System - Full ReportDocument59 pagesFace Door Lock System - Full ReportThe MindNo ratings yet
- Cardio-Screenshot OnlyDocument10 pagesCardio-Screenshot OnlyThe MindNo ratings yet
- Chapter 5Document2 pagesChapter 5The MindNo ratings yet
- Chapter 2Document11 pagesChapter 2The MindNo ratings yet
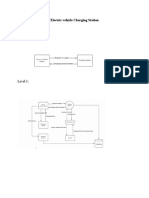
- EV Charging Station Data Flow DiagramDocument2 pagesEV Charging Station Data Flow DiagramThe MindNo ratings yet
- Fake Review - AbstractDocument2 pagesFake Review - AbstractThe MindNo ratings yet
- Use case diagram for depression detection web appDocument5 pagesUse case diagram for depression detection web appThe MindNo ratings yet
- Use Case Diagram: LoginDocument5 pagesUse Case Diagram: LoginThe MindNo ratings yet
- Use Case DiagramDocument8 pagesUse Case DiagramThe MindNo ratings yet
- A BERT Encoding With Recurrent Neural Network and Long-Short Term Memory For Breast Cancer Image Classification - 1-s2.0-S2772662223000176-MainDocument15 pagesA BERT Encoding With Recurrent Neural Network and Long-Short Term Memory For Breast Cancer Image Classification - 1-s2.0-S2772662223000176-MainSrinitish SrinivasanNo ratings yet
- Accuracy MeasuresDocument61 pagesAccuracy MeasuresSanoop MallisseryNo ratings yet
- Machine Learning EvaluationDocument3 pagesMachine Learning EvaluationKhalida MuntasherNo ratings yet
- Loading The Dataset: 'Diabetes - CSV'Document4 pagesLoading The Dataset: 'Diabetes - CSV'Divyani ChavanNo ratings yet
- PEMODELAN PREDIKSI KESEHATAN MENTAL MAHASISWA DI LINGKUNGAN MULTIKULTURAL MENGGUNAKAN ALGORITMA DECISION TREE J48 EngDocument7 pagesPEMODELAN PREDIKSI KESEHATAN MENTAL MAHASISWA DI LINGKUNGAN MULTIKULTURAL MENGGUNAKAN ALGORITMA DECISION TREE J48 EngHaidir AhmadNo ratings yet
- FPGA Implementation of A Face Recognition SystemDocument5 pagesFPGA Implementation of A Face Recognition SystemANKUSH MISHRA 17110019No ratings yet
- 17 Ensemble Techniques Problem StatementDocument28 pages17 Ensemble Techniques Problem StatementJadhav A.SNo ratings yet
- Student Campus Placement Prediction Analysis Using ChiSquared Test On Machine Learning Algorithms-IJRASETDocument10 pagesStudent Campus Placement Prediction Analysis Using ChiSquared Test On Machine Learning Algorithms-IJRASETIJRASETPublicationsNo ratings yet
- Deep-Learning-Based Stair Detection Using 3D Point Cloud Data For Preventing Walking Accidents of The Visually ImpairedDocument7 pagesDeep-Learning-Based Stair Detection Using 3D Point Cloud Data For Preventing Walking Accidents of The Visually ImpairedSleeplover RuhiNo ratings yet
- AI and ML Lab Manual 2022Document37 pagesAI and ML Lab Manual 2022Lakshmi G NNo ratings yet
- 10 Ai Evaluation tp01Document5 pages10 Ai Evaluation tp01tanjirouchihams12No ratings yet
- KR&AI-ML-DM Practical Journal ANSDocument64 pagesKR&AI-ML-DM Practical Journal ANSmst aheNo ratings yet
- COMP1801 - Copy 1Document18 pagesCOMP1801 - Copy 1SujiKrishnanNo ratings yet
- Forward Feature Selection For Toxic Speech Classification Using Support Vector Machine and Random ForestDocument10 pagesForward Feature Selection For Toxic Speech Classification Using Support Vector Machine and Random ForestIAES IJAINo ratings yet
- 5 Random Forest - Jupyter NotebookDocument2 pages5 Random Forest - Jupyter Notebookvenkatesh mNo ratings yet
- A Hyperparameter Optimization For Galaxy ClassificationDocument14 pagesA Hyperparameter Optimization For Galaxy Classification胡浩No ratings yet
- Confusion Matrix Definitions and ExamplesDocument12 pagesConfusion Matrix Definitions and ExamplesJohnvianney ManuelNo ratings yet
- ML Business Report InsightsDocument43 pagesML Business Report InsightsROHINI ROKDENo ratings yet
- (Internet of Everything (IoE) ) Rashmi Agrawal (Editor) Marcin Paprzycki (Editor) Neha Gupta (Editor) - Big Data IoT and MachDocument339 pages(Internet of Everything (IoE) ) Rashmi Agrawal (Editor) Marcin Paprzycki (Editor) Neha Gupta (Editor) - Big Data IoT and MachBassem SamirNo ratings yet
- Part A Assignment - No - 5 PDFDocument8 pagesPart A Assignment - No - 5 PDFsakshi kumavatNo ratings yet
- Malignant Comments Classifier ProjectDocument30 pagesMalignant Comments Classifier ProjectSaranya MNo ratings yet
- Decision TreeDocument3 pagesDecision TreeG SuriyanaraynanNo ratings yet
- Application of Machine Learning in Medical DiagnosisDocument19 pagesApplication of Machine Learning in Medical Diagnosisavinash100909No ratings yet
- MG1016 Coursework Brief 2020.21 PDFDocument5 pagesMG1016 Coursework Brief 2020.21 PDFShruthi SathyanarayananNo ratings yet
- KNIME Book From Modeling Model EvaluationDocument74 pagesKNIME Book From Modeling Model EvaluationPierpaolo VergatiNo ratings yet
- Artificial Neural Networks: Supriya A JadhavDocument40 pagesArtificial Neural Networks: Supriya A JadhavJadhav A.SNo ratings yet
- Complex Engineering Problem Drug Classification Using Fuzzy C MeansDocument31 pagesComplex Engineering Problem Drug Classification Using Fuzzy C MeansSameer YounasNo ratings yet
- 20dit073 Jay Prajapati MLDocument68 pages20dit073 Jay Prajapati MLJay PrajapatiNo ratings yet
- Confusion Matrix: For Evaluating The KNN ModelDocument17 pagesConfusion Matrix: For Evaluating The KNN ModelSUHRIT BISWASNo ratings yet
- K-Nearest Neighbors in MATLAB & Classification Learner App - Machine Learning - @MATLABHelperDocument6 pagesK-Nearest Neighbors in MATLAB & Classification Learner App - Machine Learning - @MATLABHelperManoa Fetra Niaina RAJAONARIVELONo ratings yet