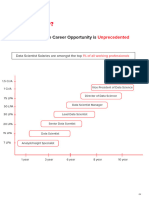
You might also like
- Machine Learning with Python: A Comprehensive Guide with a Practical ExampleFrom EverandMachine Learning with Python: A Comprehensive Guide with a Practical ExampleNo ratings yet
- Data Scientist: Nanodegree Program SyllabusDocument16 pagesData Scientist: Nanodegree Program Syllabussimha1177No ratings yet
- Data Scientist: Nanodegree Program SyllabusDocument17 pagesData Scientist: Nanodegree Program SyllabusBenjamin DublinNo ratings yet
- Data Scientist Nanodegree Syllabus: Before You StartDocument5 pagesData Scientist Nanodegree Syllabus: Before You StartAditya the RetroNo ratings yet
- Data Scientist Nanodegree Program SyllabusDocument17 pagesData Scientist Nanodegree Program SyllabusHariyo YandiNo ratings yet
- Python Data Science CertificateDocument3 pagesPython Data Science CertificatechiahaoguangNo ratings yet
- Metis Bootcamp Curriculum 2020Document19 pagesMetis Bootcamp Curriculum 2020Haidar ANo ratings yet
- Guest LectureDocument4 pagesGuest LectureavanigangNo ratings yet
- Lesson - 1 Course Introduction Data Science FoundationDocument26 pagesLesson - 1 Course Introduction Data Science Foundationisarita100% (1)
- Data Science Bootcamp: CurriculumDocument19 pagesData Science Bootcamp: CurriculumOlumide OlayinkaNo ratings yet
- ML DevOps Engineer Nanodegree ProgramDocument16 pagesML DevOps Engineer Nanodegree ProgramCylubNo ratings yet
- Intermediate Python Nanodegree Program SyllabusDocument10 pagesIntermediate Python Nanodegree Program SyllabusCylubNo ratings yet
- Data Analytics Boot Camp: Curriculum OverviewDocument12 pagesData Analytics Boot Camp: Curriculum OverviewAbuelo Escobar100% (1)
- Module Report PresentationDocument7 pagesModule Report Presentationas0160No ratings yet
- Nanodegree Program SyllabusDocument29 pagesNanodegree Program SyllabusCarlos Iván Mejía SoriaNo ratings yet
- Data Architect Nanodegree Program SyllabusDocument12 pagesData Architect Nanodegree Program SyllabusibrahimnoohNo ratings yet
- Antwak Providence Proposal v3Document14 pagesAntwak Providence Proposal v3comalob706No ratings yet
- Brochure MIT XPRO - Professional Certificate in Data Engineering - V44Document15 pagesBrochure MIT XPRO - Professional Certificate in Data Engineering - V44Henry JaimesNo ratings yet
- Comp Sci ChecklistDocument24 pagesComp Sci ChecklistHạo BùiNo ratings yet
- Exploringcomputerscience 1Document6 pagesExploringcomputerscience 1api-441383155No ratings yet
- Introduction To Data Analytics-BCA216Document190 pagesIntroduction To Data Analytics-BCA216Ashish AntopazhunkaranNo ratings yet
- Udacity Enterprise Syllabus Data Analyst nd002Document16 pagesUdacity Enterprise Syllabus Data Analyst nd002IaksksksNo ratings yet
- Senior Architect 9443373799 / 7358773175: ProfileDocument3 pagesSenior Architect 9443373799 / 7358773175: ProfileShantha GopaalNo ratings yet
- 0901ec221090 RishavmudgalDocument11 pages0901ec221090 RishavmudgalSuryanshNo ratings yet
- Geetha Polaboina - Data Analyst - CVDocument4 pagesGeetha Polaboina - Data Analyst - CVKrishna Keerthi100% (1)
- L01 - IntroductionDocument51 pagesL01 - IntroductionBigu Marius AlinNo ratings yet
- Moizkhan DataanalystDocument2 pagesMoizkhan DataanalystSana AliNo ratings yet
- S Ghai: Python Developer / Data AnalystDocument5 pagesS Ghai: Python Developer / Data AnalystApurva DhariaNo ratings yet
- Machine Learning Dev Ops Engineer Nanodegree Program SyllabusDocument16 pagesMachine Learning Dev Ops Engineer Nanodegree Program Syllabuskerlos ZakryNo ratings yet
- Udacity+Enterprise+Syllabus+Business+Analytics+nd098Document13 pagesUdacity+Enterprise+Syllabus+Business+Analytics+nd098Ibrahim AdamaNo ratings yet
- Tentative Data Manipulation PythonDocument4 pagesTentative Data Manipulation Pythonimagtion pdrNo ratings yet
- Business Analytics: Nanodegree Program SyllabusDocument13 pagesBusiness Analytics: Nanodegree Program SyllabusLucas Castro AlvesNo ratings yet
- Week-14-15-Data Mining ToolsDocument24 pagesWeek-14-15-Data Mining ToolsMichael ZewdieNo ratings yet
- Lu1 - Lo 1 - 4Document47 pagesLu1 - Lo 1 - 4Queraysha JairajNo ratings yet
- Deep Learning Nanodegree SyllabusDocument15 pagesDeep Learning Nanodegree SyllabusCylubNo ratings yet
- Roadmap To Become A Data Scientist in 2024Document12 pagesRoadmap To Become A Data Scientist in 2024DurgeshNo ratings yet
- DWDM Final Lab SyllabusDocument2 pagesDWDM Final Lab Syllabussaisimba99No ratings yet
- 9618 - Learner - Guide - (For - Examination - From - 2021) - Computer ScienceDocument24 pages9618 - Learner - Guide - (For - Examination - From - 2021) - Computer Sciencelaksh bissoondialNo ratings yet
- Lesson 01 1.01 Course IntroductionDocument28 pagesLesson 01 1.01 Course Introductionjayant khanvilkarNo ratings yet
- Apcsp Foundations SyllabusDocument5 pagesApcsp Foundations Syllabusapi-473692998No ratings yet
- Intro To Machine Learning Nanodegree Program SyllabusDocument13 pagesIntro To Machine Learning Nanodegree Program SyllabusCylubNo ratings yet
- ds module 1Document72 pagesds module 1Prathik SrinivasNo ratings yet
- Resume - Veera Bhadra RaoDocument4 pagesResume - Veera Bhadra Raopandu1287No ratings yet
- Data Science Toolkit OverviewDocument18 pagesData Science Toolkit OverviewVignesh NarasimhanNo ratings yet
- OOSAD Course OutlineDocument3 pagesOOSAD Course OutlineMoti King MotiNo ratings yet
- Internship Training Programs-PythonDocument23 pagesInternship Training Programs-Pythonkundu munduNo ratings yet
- Metis Bootcamp CurriculumDocument18 pagesMetis Bootcamp CurriculumEthvasNo ratings yet
- Land an Exclusive Data Science Interview with upGrad's Comprehensive BootcampDocument21 pagesLand an Exclusive Data Science Interview with upGrad's Comprehensive Bootcampshivam3119No ratings yet
- Zameer Usman - AI ResumeDocument4 pagesZameer Usman - AI Resume45.Nagare AnuragNo ratings yet
- Python Machine Learning - Session 2Document6 pagesPython Machine Learning - Session 2Pace InfotechNo ratings yet
- Syllabus Data Courses AllWomen 2021Document21 pagesSyllabus Data Courses AllWomen 2021Necessary.R.No ratings yet
- Data Analytics Boot Camp OverviewDocument12 pagesData Analytics Boot Camp OverviewPatricia Monroy100% (1)
- Data Science Immersive Syllabus: CourseDocument4 pagesData Science Immersive Syllabus: Coursedel_espacioNo ratings yet
- Twelve-Week Onsite Bootcamp: Flow of The DayDocument15 pagesTwelve-Week Onsite Bootcamp: Flow of The DayAnonymous iri7q9GNo ratings yet
- Java MaterialDocument92 pagesJava Materialsv284444No ratings yet
- Data RoadmapDocument9 pagesData Roadmapadit369yaNo ratings yet
- Programming For Data Science With Python: Nanodegree Program SyllabusDocument13 pagesProgramming For Data Science With Python: Nanodegree Program SyllabusalxaNo ratings yet
- Dbms UPDATED MANUAL EWITDocument75 pagesDbms UPDATED MANUAL EWITMadhukesh .kNo ratings yet
- Zero Lecture: Big Data Analytics Lab BCA04206 From: Megha GargDocument19 pagesZero Lecture: Big Data Analytics Lab BCA04206 From: Megha GargMegha GargNo ratings yet
- India Handloom Brand India Handloom Brand: Manual For Products Manual For ProductsDocument28 pagesIndia Handloom Brand India Handloom Brand: Manual For Products Manual For ProductslavanyaNo ratings yet
- Shapes and Designs: Make A ClapperDocument16 pagesShapes and Designs: Make A ClapperHarish ReddyNo ratings yet
- Channa Mereya Lyrics - Ae Dil Hai Mushkil (2016) 1Document2 pagesChanna Mereya Lyrics - Ae Dil Hai Mushkil (2016) 1lavanyaNo ratings yet
- Ae Dil Hai Mushkil (Anthem) Lyrics - Ae Dil Hai Mushkil (2016) 1Document2 pagesAe Dil Hai Mushkil (Anthem) Lyrics - Ae Dil Hai Mushkil (2016) 1lavanyaNo ratings yet
- Basics of Dental Implantology For The Oral SurgeonDocument21 pagesBasics of Dental Implantology For The Oral SurgeonlavanyaNo ratings yet
- Stumm Lee Chemistry Aqueous IronDocument27 pagesStumm Lee Chemistry Aqueous IronlavanyaNo ratings yet
- BSC 702 Gross Anatomy Lecture Notes: Thorax, Abdomen and PelvisDocument144 pagesBSC 702 Gross Anatomy Lecture Notes: Thorax, Abdomen and PelvislavanyaNo ratings yet
- 2019 Ncov FactsheetDocument1 page2019 Ncov FactsheetlavanyaNo ratings yet
- Characteristics of Ovulation: October 2019Document103 pagesCharacteristics of Ovulation: October 2019lavanyaNo ratings yet
- Progesterone BookDocument84 pagesProgesterone BookKinjal ShahNo ratings yet
- A Study of Fashion Design and Pattern Making of Ladies' Dresses With DraperiesDocument11 pagesA Study of Fashion Design and Pattern Making of Ladies' Dresses With DraperieslavanyaNo ratings yet
- Estrogen: March 2018Document62 pagesEstrogen: March 2018lavanyaNo ratings yet
- Omar F. Hadidi, MD, Tom C. Nguyen, MD: Chapter 10: Step-By-Step Guide: Transfemoral Sapien S3 TAVRDocument12 pagesOmar F. Hadidi, MD, Tom C. Nguyen, MD: Chapter 10: Step-By-Step Guide: Transfemoral Sapien S3 TAVRlavanyaNo ratings yet
- LFT Guide: Interpret Liver Function Test ResultsDocument4 pagesLFT Guide: Interpret Liver Function Test ResultslavanyaNo ratings yet
- Liver Function Test Handout 2016Document3 pagesLiver Function Test Handout 2016kookyinNo ratings yet
- P140031 CDocument30 pagesP140031 ClavanyaNo ratings yet
- Average QuestionsDocument22 pagesAverage QuestionsAruna YadavNo ratings yet
- Liver PresentationDocument45 pagesLiver PresentationVimuvimNo ratings yet
- Circinterventions 115 002408 PDFDocument10 pagesCircinterventions 115 002408 PDFlavanyaNo ratings yet
- Thera BrainDocument7 pagesThera BrainlavanyaNo ratings yet
- P140031c PDFDocument30 pagesP140031c PDFlavanyaNo ratings yet
- 100 Number SeriesDocument24 pages100 Number SerieslavanyaNo ratings yet
- Clinical Heart DiseaseDocument2 pagesClinical Heart DiseaselavanyaNo ratings yet
- Linear Arrangement Questions For SBI Clerk PDFDocument6 pagesLinear Arrangement Questions For SBI Clerk PDFShaina MehtaNo ratings yet
- Mirza YaDocument1 pageMirza YalavanyaNo ratings yet