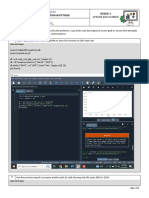
You might also like
- Carreon WS06Document4 pagesCarreon WS06Keneth CarreonNo ratings yet
- Supervised Machine Learning in Python: Worksheet 3.8Document1 pageSupervised Machine Learning in Python: Worksheet 3.8Emely GonzagaNo ratings yet
- Wa0002 PDFDocument39 pagesWa0002 PDFSreenath SreeNo ratings yet
- CSC 108H1 F 2010 Test 1 Duration - 45 Minutes Aids Allowed: NoneDocument8 pagesCSC 108H1 F 2010 Test 1 Duration - 45 Minutes Aids Allowed: NoneexamkillerNo ratings yet
- Statistical Learning Project: Ques 1 - Import The Necessary LibrariesDocument16 pagesStatistical Learning Project: Ques 1 - Import The Necessary LibrariesHarsh SinghNo ratings yet
- CSC 108H1 F 2009 Test 1 Duration - 35 Minutes Aids Allowed: NoneDocument8 pagesCSC 108H1 F 2009 Test 1 Duration - 35 Minutes Aids Allowed: NoneexamkillerNo ratings yet
- Assesment 1Document18 pagesAssesment 1ASHUTOSH RAY 15BME0081No ratings yet
- Sci Cal SynopsisDocument30 pagesSci Cal SynopsisTushar KhannaNo ratings yet
- CS 1 Ans - Introduction To PythonDocument9 pagesCS 1 Ans - Introduction To Pythonasha.py81No ratings yet
- Research in ComputingDocument40 pagesResearch in ComputingGayatri Dilip JuwatkarNo ratings yet
- Gng1106 Sample MidtermDocument22 pagesGng1106 Sample MidtermJon LeNo ratings yet
- Programming For Beginners Java Tutorial#5 - SolutionDocument14 pagesProgramming For Beginners Java Tutorial#5 - SolutionHNo ratings yet
- CSE 3024: Web Mining: Lab Assessment - 3Document13 pagesCSE 3024: Web Mining: Lab Assessment - 3Nikitha ReddyNo ratings yet
- Ai - Phase 3Document9 pagesAi - Phase 3Manikandan NNo ratings yet
- Assignment 1 - LP1Document14 pagesAssignment 1 - LP1bbad070105No ratings yet
- Mlaifile1 3Document27 pagesMlaifile1 3Krishna kumarNo ratings yet
- DS100-1 WS 2.6 Enrico, DMDocument8 pagesDS100-1 WS 2.6 Enrico, DMAnalyn EnricoNo ratings yet
- 2020-21 XIIInfo - Pract.S.E.155Document11 pages2020-21 XIIInfo - Pract.S.E.155Haresh NathaniNo ratings yet
- Advanced DatabaseDocument23 pagesAdvanced DatabaseravikumarrkNo ratings yet
- Takehome 2Document6 pagesTakehome 2Matthew WebbNo ratings yet
- #Create Vector of Numeric Values #Display Class of VectorDocument10 pages#Create Vector of Numeric Values #Display Class of VectorAnooj SrivastavaNo ratings yet
- Python ODC-17032022Document8 pagesPython ODC-17032022Pawan MishraNo ratings yet
- Ip ProjectDocument23 pagesIp ProjectkawsarNo ratings yet
- AIDS - DM Using Python - Lab ProgramsDocument19 pagesAIDS - DM Using Python - Lab ProgramsyelubandirenukavidyadhariNo ratings yet
- MITRES 6 009IAP12 Lab1 PDFDocument9 pagesMITRES 6 009IAP12 Lab1 PDFlp111bjNo ratings yet
- PYTHON AssignmentDocument26 pagesPYTHON Assignmentprincekumar13785No ratings yet
- Chandigarh Group of Colleges College of Engineering Landran, MohaliDocument47 pagesChandigarh Group of Colleges College of Engineering Landran, Mohalitanvi wadhwaNo ratings yet
- FrescoDocument17 pagesFrescovinay100% (2)
- Assignment 7Document3 pagesAssignment 7jitbitan.kgpianNo ratings yet
- Part-A: SI. No Program Page NoDocument38 pagesPart-A: SI. No Program Page NoFasal ShahNo ratings yet
- Final Practical File 2022-23Document87 pagesFinal Practical File 2022-23Kuldeep SinghNo ratings yet
- Worksheet-1 (Python)Document9 pagesWorksheet-1 (Python)rizwana fathimaNo ratings yet
- ML Practical FileDocument43 pagesML Practical FilePankaj Singh100% (1)
- ML LAB Mannual - IndexDocument29 pagesML LAB Mannual - IndexNisahd hiteshNo ratings yet
- Analysis ReportDocument8 pagesAnalysis ReportwritersleedNo ratings yet
- Data Structures Assignment: Problem 1Document7 pagesData Structures Assignment: Problem 1api-26041279No ratings yet
- End To End Implementation of Data Science Pipeline in The Linear Regression ModelDocument39 pagesEnd To End Implementation of Data Science Pipeline in The Linear Regression ModelDerek DegbedzuiNo ratings yet
- Record 2022-23Document92 pagesRecord 2022-23kawsarNo ratings yet
- Aayushi Saini 20191102 B.SC (H) Statistics 5 Semester Statistical Computing Using C/C++ ProgrammingDocument45 pagesAayushi Saini 20191102 B.SC (H) Statistics 5 Semester Statistical Computing Using C/C++ Programmingmansi sainiNo ratings yet
- Aiml Lab Copy SauravDocument8 pagesAiml Lab Copy SauravPallabi JaiswalNo ratings yet
- Computer Class X UtDocument4 pagesComputer Class X Uthaimandas9881No ratings yet
- Final - DNN - Hands - On - Jupyter NotebookDocument8 pagesFinal - DNN - Hands - On - Jupyter Notebooktango charlie25% (4)
- Data Flow Diagrams (DFDS)Document7 pagesData Flow Diagrams (DFDS)Vivek PandeyNo ratings yet
- Python Programming Lab ManualDocument14 pagesPython Programming Lab ManualmallelaharinagarajuNo ratings yet
- Big Data File in RDocument23 pagesBig Data File in RPrabhu GoyalNo ratings yet
- Aakash S Project ReportDocument12 pagesAakash S Project ReportVivekNo ratings yet
- Practical File PythonDocument25 pagesPractical File Pythonkaizenpro01No ratings yet
- Python SolutionsDocument21 pagesPython SolutionsDisha GoelNo ratings yet
- DAUR Lab ManualDocument14 pagesDAUR Lab ManualSunhith JainaNo ratings yet
- In This Hands-On You Will Be Performing CNN Operations Using Tensorflow PackageDocument6 pagesIn This Hands-On You Will Be Performing CNN Operations Using Tensorflow PackageJohn SolomonNo ratings yet
- Bcs Higher Education Qualifications BCS Level 4 Certificate in IT April 2011 Examiner'S Report Software DevelopmentDocument22 pagesBcs Higher Education Qualifications BCS Level 4 Certificate in IT April 2011 Examiner'S Report Software DevelopmentJessica TiffanyNo ratings yet
- ML - LAB - FILE AmritDocument13 pagesML - LAB - FILE AmritkhatmalmainNo ratings yet
- ML - LAB - FILE PankajDocument13 pagesML - LAB - FILE PankajkhatmalmainNo ratings yet
- Shiny HandoutDocument14 pagesShiny HandoutAngel SmithNo ratings yet
- Practical Record File XII Physics 22-23 FinalDocument34 pagesPractical Record File XII Physics 22-23 FinalSUVODEEP SARKARNo ratings yet
- DNN ALL Practical 28Document34 pagesDNN ALL Practical 284073Himanshu PatleNo ratings yet
- (Program Should Input Number of Row/columns and Followed by TheDocument3 pages(Program Should Input Number of Row/columns and Followed by TheAnudeep BhattacharyaNo ratings yet
- Practical Numerical C Programming: Finance, Engineering, and Physics ApplicationsFrom EverandPractical Numerical C Programming: Finance, Engineering, and Physics ApplicationsNo ratings yet
- College Invitation Letter - Managedia 2023Document2 pagesCollege Invitation Letter - Managedia 2023Sandeep DeyNo ratings yet
- Architech 06-2016 Room AssignmentDocument4 pagesArchitech 06-2016 Room AssignmentPRC Baguio100% (1)
- Chapter 7odeDocument29 pagesChapter 7odeRoberto NascimentoNo ratings yet
- FO - Course Transition Info - Acknowledgement - SIT50422 - Dip Hospitality Management - V1Document2 pagesFO - Course Transition Info - Acknowledgement - SIT50422 - Dip Hospitality Management - V1nitesh.kc06No ratings yet
- Kitchen Equipment Handling and Maintaining Standard Procedure and PoliciesDocument2 pagesKitchen Equipment Handling and Maintaining Standard Procedure and PoliciesChef Chef75% (4)
- Lesson Plan Defining and Non Relative Clauses XII (I)Document3 pagesLesson Plan Defining and Non Relative Clauses XII (I)mariaalexeli0% (1)
- Haldex Valve Catalog: Quality Parts For Vehicles at Any Life StageDocument108 pagesHaldex Valve Catalog: Quality Parts For Vehicles at Any Life Stagehoussem houssemNo ratings yet
- Corporate Profile of Multimode GroupDocument6 pagesCorporate Profile of Multimode GroupShaheen RahmanNo ratings yet
- Cyrille MATH INVESTIGATION Part2Document18 pagesCyrille MATH INVESTIGATION Part2Jessie jorgeNo ratings yet
- Keira Knightley: Jump To Navigation Jump To SearchDocument12 pagesKeira Knightley: Jump To Navigation Jump To SearchCrina LupuNo ratings yet
- Review of Related Literature and Related StudiesDocument23 pagesReview of Related Literature and Related StudiesReynhard Dale100% (3)
- Presentation 1Document22 pagesPresentation 1AILYN PECASALESNo ratings yet
- Astm D2265-00 PDFDocument5 pagesAstm D2265-00 PDFOGINo ratings yet
- Risk Assessment For ExcavationDocument6 pagesRisk Assessment For ExcavationAhmed GamalNo ratings yet
- Writing Short StoriesDocument10 pagesWriting Short StoriesRodiatun YooNo ratings yet
- Drill Bit Classifier 2004 PDFDocument15 pagesDrill Bit Classifier 2004 PDFgustavoemir0% (2)
- Check List For Design Program of A Parish ChurchDocument11 pagesCheck List For Design Program of A Parish ChurchQuinn HarloweNo ratings yet
- Calculate Breakeven Point in Units and Revenue Dollars: Intermediate Cost Analysis and ManagementDocument52 pagesCalculate Breakeven Point in Units and Revenue Dollars: Intermediate Cost Analysis and ManagementNavice Kie100% (1)
- BF254 BF255Document3 pagesBF254 BF255rrr2013No ratings yet
- Bill of Quantity: Supply of Pipes and FittingsDocument3 pagesBill of Quantity: Supply of Pipes and FittingssubxaanalahNo ratings yet
- Grange Fencing Garden Products Brochure PDFDocument44 pagesGrange Fencing Garden Products Brochure PDFDan Joleys100% (1)
- CE Laws L8 L15Document470 pagesCE Laws L8 L15Edwin BernatNo ratings yet
- p1632 eDocument4 pagesp1632 ejohn saenzNo ratings yet
- Articles About Social Issues - Whiter SkinDocument9 pagesArticles About Social Issues - Whiter Skinf aNo ratings yet
- H I Ôn Thi Aptis & Vstep - Tài Liệu - Anna MaiDocument4 pagesH I Ôn Thi Aptis & Vstep - Tài Liệu - Anna Maihanh.mt2022No ratings yet
- SM-G900F Esquematico Completo Anibal Garcia IrepairDocument2 pagesSM-G900F Esquematico Completo Anibal Garcia Irepairfix marketNo ratings yet
- Nokia 3g Full Ip CommissioningDocument30 pagesNokia 3g Full Ip CommissioningMehul JoshiNo ratings yet
- VDRL - Press. GaugesDocument9 pagesVDRL - Press. GaugesSourav RayNo ratings yet
- Caterpillar Sis (01.2014) MultilanguageDocument10 pagesCaterpillar Sis (01.2014) MultilanguageTemmy Candra Wijaya100% (1)
- Impeller Velocity TrianglesDocument2 pagesImpeller Velocity TrianglesLorettaMayNo ratings yet