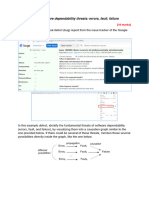
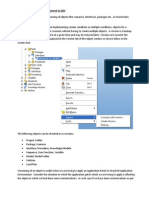
You might also like
- Logistic Regression Using SAS: Theory and Application, Second EditionFrom EverandLogistic Regression Using SAS: Theory and Application, Second EditionRating: 4 out of 5 stars4/5 (2)
- Ebook Kreativni SlovnikDocument198 pagesEbook Kreativni SlovnikTomáš RoubalNo ratings yet
- Train Custom Data - Ultralytics YOLOv8 DocsDocument1 pageTrain Custom Data - Ultralytics YOLOv8 DocsTrung HaNo ratings yet
- Practical Monte Carlo Simulation with Excel - Part 2 of 2: Applications and DistributionsFrom EverandPractical Monte Carlo Simulation with Excel - Part 2 of 2: Applications and DistributionsRating: 2 out of 5 stars2/5 (1)
- Native American Writers (Bloom S Modern Critical Views) PDFDocument292 pagesNative American Writers (Bloom S Modern Critical Views) PDFRaheem100% (1)
- As Long As You Love Me ActivityDocument2 pagesAs Long As You Love Me Activitypepe00731@latinmail.com100% (1)
- Beldiceanu12a-Model ADocument17 pagesBeldiceanu12a-Model ASophia RoseNo ratings yet
- COL 774: Assignment 2Document3 pagesCOL 774: Assignment 2Aditya KumarNo ratings yet
- School of Computer Science Engineering and TechnologyDocument1 pageSchool of Computer Science Engineering and TechnologyPRANAT MANGLANo ratings yet
- Interfacing IPOPT With Aspen Open Solvers and CAPE-OPENDocument6 pagesInterfacing IPOPT With Aspen Open Solvers and CAPE-OPEN赵雷No ratings yet
- COCOMO - An Empirical Estimation Model For EffortDocument4 pagesCOCOMO - An Empirical Estimation Model For EffortAdnan RajperNo ratings yet
- Department: Lab ManualDocument36 pagesDepartment: Lab ManualPragun SinghalNo ratings yet
- Seminar Report NewDocument22 pagesSeminar Report NewSreehari B SNo ratings yet
- Object Detection and Shadow Removal From Video StreamDocument10 pagesObject Detection and Shadow Removal From Video StreamPaolo PinoNo ratings yet
- MGARCH Package v.3Document27 pagesMGARCH Package v.3josyNo ratings yet
- Brall 2007Document6 pagesBrall 2007ronaldNo ratings yet
- Large-Scale Image ClassificationDocument8 pagesLarge-Scale Image ClassificationSeun -nuga DanielNo ratings yet
- CS 4/791Y Mathematical Methods For Computer Vision Fall 2002 - Dr. George Bebis Programming Assignment 1Document2 pagesCS 4/791Y Mathematical Methods For Computer Vision Fall 2002 - Dr. George Bebis Programming Assignment 1Gamindu UdayangaNo ratings yet
- On The Deployment of Boolean Logic: VainaDocument4 pagesOn The Deployment of Boolean Logic: VainaLKNo ratings yet
- Microsoft Ucertify dp-100Document15 pagesMicrosoft Ucertify dp-100Steven DohNo ratings yet
- COMKAT Compartment Model Kinetic Analysis ToolDocument10 pagesCOMKAT Compartment Model Kinetic Analysis ToolIvoPetrovNo ratings yet
- IP SubjDocument6 pagesIP SubjBogdan ȘimonNo ratings yet
- CS-7830 Assignment-2 Questions 2022Document4 pagesCS-7830 Assignment-2 Questions 2022manish kardasNo ratings yet
- Modelamiento Implicito - VULCANDocument15 pagesModelamiento Implicito - VULCANChristian CRNo ratings yet
- 2627Document33 pages2627combatps1No ratings yet
- Mldoc IntroDocument4 pagesMldoc Introsantosh kumar varagantiNo ratings yet
- SnapcatDocument4 pagesSnapcatViviana DiasNo ratings yet
- COMSOL HANDBOOK SERIES Essentials of Postprocessing and Visualization PDFDocument36 pagesCOMSOL HANDBOOK SERIES Essentials of Postprocessing and Visualization PDFlucyli115No ratings yet
- Cocomo Model AmitDocument20 pagesCocomo Model AmitAmzy SilvsesterNo ratings yet
- An Ecient Multiple Shooting Based Reduced SQP Strategy For Large-Scale Dynamic Process OptimizationDocument10 pagesAn Ecient Multiple Shooting Based Reduced SQP Strategy For Large-Scale Dynamic Process OptimizationaminNo ratings yet
- ConstructonDocument10 pagesConstructonAnmol SaxenaNo ratings yet
- 2022 Spring-Main ExamDocument9 pages2022 Spring-Main ExamSarah McOnellyNo ratings yet
- Eo Learn 3Document17 pagesEo Learn 3Trung HoàngNo ratings yet
- ML0101EN Reg Simple Linear Regression Co2 Py v1Document4 pagesML0101EN Reg Simple Linear Regression Co2 Py v1Muhammad RaflyNo ratings yet
- Building PoD CurvesDocument6 pagesBuilding PoD CurvesSridharan ChandranNo ratings yet
- 5897 Eqa MX Embodied Question Answe-Supplementary MaterialDocument12 pages5897 Eqa MX Embodied Question Answe-Supplementary MaterialAli WarisNo ratings yet
- Radial Basis Function Neural NetworksDocument17 pagesRadial Basis Function Neural Networkso iNo ratings yet
- AutomaticTranslationofOCLMeta-Level ConstraintsintoJavaMeta-programsDocument15 pagesAutomaticTranslationofOCLMeta-Level ConstraintsintoJavaMeta-programsAbdelaaziz SistiNo ratings yet
- LAB 1: MOSFET Characteristics: ObjectivesDocument8 pagesLAB 1: MOSFET Characteristics: Objectiveslawrencesoon86No ratings yet
- Bachelor Thesis Informatik BeispielDocument6 pagesBachelor Thesis Informatik Beispielstephanierivasdesmoines100% (1)
- Version Management in ODIDocument5 pagesVersion Management in ODIvamsi.prasadNo ratings yet
- Assignment 5 - NNDocument4 pagesAssignment 5 - NNthecoolguy96No ratings yet
- 2002 WaldBookFusion Cha8 QualDocument22 pages2002 WaldBookFusion Cha8 QualEdwin Hernán HurtadoNo ratings yet
- Homework 1Document3 pagesHomework 1Elizabeth Wachs50% (2)
- 4experiment Writeup DPCOEDocument4 pages4experiment Writeup DPCOESachin RathodNo ratings yet
- ISD LAB10-DesignConceptsDocument6 pagesISD LAB10-DesignConceptsTú PhạmNo ratings yet
- Duo: Psychoacoustic Configurations: A, Khia, Millon and ChingazDocument6 pagesDuo: Psychoacoustic Configurations: A, Khia, Millon and ChingazLKNo ratings yet
- Evaluarea Costului Unui Soft - ExempleDocument5 pagesEvaluarea Costului Unui Soft - ExempleVadim CiubotaruNo ratings yet
- Machine Vision Project ReportDocument15 pagesMachine Vision Project ReportVincent Kok100% (1)
- Final Exam Su2017Document9 pagesFinal Exam Su2017Juan SantosNo ratings yet
- Autoencoder Assignment PDFDocument5 pagesAutoencoder Assignment PDFpraveen kandulaNo ratings yet
- Calonico Cattaneo Farrell Titiunik 2017 Stata RDDocument33 pagesCalonico Cattaneo Farrell Titiunik 2017 Stata RDOliver ElorreagaNo ratings yet
- Evaluation of Bayesian Optimization Applied To Discrete-Event SimulationDocument9 pagesEvaluation of Bayesian Optimization Applied To Discrete-Event Simulation6551209251No ratings yet
- External Project 2022 04Document25 pagesExternal Project 2022 04jose peñalbaNo ratings yet
- Tutorial 2 GuideDocument11 pagesTutorial 2 GuideCalvin CobainNo ratings yet
- Prob2 PDFDocument2 pagesProb2 PDFvillekuuselaNo ratings yet
- Project 2Document2 pagesProject 2marco617chanNo ratings yet
- DP 100Document13 pagesDP 100manan511shahNo ratings yet
- Mat 72 R 3Document11 pagesMat 72 R 3amarNo ratings yet
- CRAN Task View - EconometricsDocument7 pagesCRAN Task View - EconometricsJavier PaniaguaNo ratings yet
- ITT202 - Ktu QbankDocument8 pagesITT202 - Ktu QbankmididceNo ratings yet
- Tutorial 1,2Document22 pagesTutorial 1,2Teja Maheswara ReddyNo ratings yet
- Chapter 6.metacogntionDocument18 pagesChapter 6.metacogntionKusum SharmaNo ratings yet
- Cyclic Redundancy Check (CRC)Document3 pagesCyclic Redundancy Check (CRC)AhmadFatihinNo ratings yet
- Hungary 5 History CultureDocument25 pagesHungary 5 History CultureArhip CojocNo ratings yet
- SDARM Bible Study Qtrs. 1 & 2 1957Document68 pagesSDARM Bible Study Qtrs. 1 & 2 1957Brian S. MarksNo ratings yet
- SolidWorks Lab ReportDocument25 pagesSolidWorks Lab Report5dwwm8psgtNo ratings yet
- (Ebook - Eng) The Discourse To Kalamas (Kalama Sutta, Anguttara Nikaya 3.65 - Edited by Thanissaro Bhikkhu) PDFDocument7 pages(Ebook - Eng) The Discourse To Kalamas (Kalama Sutta, Anguttara Nikaya 3.65 - Edited by Thanissaro Bhikkhu) PDFJacopo StefaniNo ratings yet
- Practical No 3:-Write A Program in C To Implement Bresenham's Line Drawing and DDA Digital Differential Analyzer (DDA)Document5 pagesPractical No 3:-Write A Program in C To Implement Bresenham's Line Drawing and DDA Digital Differential Analyzer (DDA)Khan.aliNo ratings yet
- C.E.G.H.I.K. Ang Pista NG Sambayanan (Responses)Document10 pagesC.E.G.H.I.K. Ang Pista NG Sambayanan (Responses)MickJagger Ronio100% (2)
- Wolf, L. (2014) - Degrees of AssertionDocument196 pagesWolf, L. (2014) - Degrees of Assertionvitas626No ratings yet
- Bangladesh Physics Olympiad 2015 (National)Document3 pagesBangladesh Physics Olympiad 2015 (National)Science Olympiad Blog100% (7)
- Chapter 10 TreeDocument171 pagesChapter 10 TreeTanveer Ahmed HakroNo ratings yet
- MemoDocument27 pagesMemoAyu YulaekahNo ratings yet
- Papouch Serial Device Server RS485 10 100 Ethernet TCP IP Remote COM Port Gnome 485Document24 pagesPapouch Serial Device Server RS485 10 100 Ethernet TCP IP Remote COM Port Gnome 485francopetittNo ratings yet
- The RISC-V Processor: Hakim Weatherspoon CS 3410Document47 pagesThe RISC-V Processor: Hakim Weatherspoon CS 3410Elisée NdjabuNo ratings yet
- The Good Guy - Bad Guy MythDocument10 pagesThe Good Guy - Bad Guy MythBlazing BooksNo ratings yet
- PLC List of Stockholders As of March 27,2015Document14 pagesPLC List of Stockholders As of March 27,2015Boss NikNo ratings yet
- Nouns - The Grammatical Categories of Gender and CaseDocument14 pagesNouns - The Grammatical Categories of Gender and CasedetkoNo ratings yet
- Enlightenment - Life The Way It Is - Sadhguru Jaggi Vasudev - KannadaDocument83 pagesEnlightenment - Life The Way It Is - Sadhguru Jaggi Vasudev - KannadavincptNo ratings yet
- List of Lab ExercisesDocument3 pagesList of Lab ExercisesAjay Raj SrivastavaNo ratings yet
- Parallel Processing in ABAP - Team ABAPDocument8 pagesParallel Processing in ABAP - Team ABAPcronosspNo ratings yet
- DA-40T Series: The Complete Press Brake Control Operation Manual V1, EnglishDocument44 pagesDA-40T Series: The Complete Press Brake Control Operation Manual V1, EnglishC Y M Machinery SacNo ratings yet
- Pid5030 PDFDocument22 pagesPid5030 PDFPATEL SWAPNEEL100% (1)
- Cassandra 20Document194 pagesCassandra 20Joel Eljo Enciso SaraviaNo ratings yet
- Diploma in Graphic DesignDocument8 pagesDiploma in Graphic DesignShan LahiruNo ratings yet
- UI - UX Design Expert Master ProgramDocument18 pagesUI - UX Design Expert Master ProgramkishanNo ratings yet
- Speaking PerformanceDocument82 pagesSpeaking PerformanceSalshabilla annisa FitriNo ratings yet
- Is Simple C or ASM LCD Busy Flag Check Function - AVR FreaksDocument7 pagesIs Simple C or ASM LCD Busy Flag Check Function - AVR FreaksMohamedSaidNo ratings yet