You might also like
- Intelligent Vehicular Networks and Communications: Fundamentals, Architectures and SolutionsFrom EverandIntelligent Vehicular Networks and Communications: Fundamentals, Architectures and SolutionsRating: 1 out of 5 stars1/5 (1)
- Ge Et Al 2023 Roadside Lidar Sensor Configuration Assessment and Optimization Methods For Vehicle Detection andDocument20 pagesGe Et Al 2023 Roadside Lidar Sensor Configuration Assessment and Optimization Methods For Vehicle Detection andYuna Park (박유나)No ratings yet
- Sensors and Sensor Fusion in Autonomous VehiclesDocument4 pagesSensors and Sensor Fusion in Autonomous VehiclesWIlhelmNo ratings yet
- Object Detection For Automotive Radar Point Clouds - A ComparisonDocument23 pagesObject Detection For Automotive Radar Point Clouds - A ComparisonhassamaliNo ratings yet
- Idt 15 Idt200106Document15 pagesIdt 15 Idt200106ImaneNo ratings yet
- Sensors 20 07283Document21 pagesSensors 20 07283Gopinathrg19 KrishNo ratings yet
- Sensor FusionDocument5 pagesSensor FusionShiva AgrawalNo ratings yet
- A Survey On 3D Object Detection Methods For Autonomous Driving ApplicationsDocument14 pagesA Survey On 3D Object Detection Methods For Autonomous Driving ApplicationsVishal ManwaniNo ratings yet
- Automatic Lane Identification Using The Roadside Lidar SensorsDocument11 pagesAutomatic Lane Identification Using The Roadside Lidar SensorsGhionNo ratings yet
- Lidar Sensor Saadulhassan Syed C2Document8 pagesLidar Sensor Saadulhassan Syed C2tuanlh.todayNo ratings yet
- Complete Panoptic Traffic Recognition System With Ensemble of YOLO Family ModelsDocument9 pagesComplete Panoptic Traffic Recognition System With Ensemble of YOLO Family ModelsInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- A Survey On 3D LiDAR Localization For Autonomous VehiclesDocument6 pagesA Survey On 3D LiDAR Localization For Autonomous VehiclesYifeng CaoNo ratings yet
- Visual-LiDAR Based 3D Object Detection and Tracking For Embedded SystemsDocument14 pagesVisual-LiDAR Based 3D Object Detection and Tracking For Embedded Systems20bec054PRIYANSHU GUPTANo ratings yet
- Autonomous VehiclesDocument15 pagesAutonomous VehiclesAYESHANo ratings yet
- Obstacle Detection Using Stereo VisionDocument56 pagesObstacle Detection Using Stereo Visionsharukj khanNo ratings yet
- Remotesensing 13 00089 v2Document23 pagesRemotesensing 13 00089 v2Varun GoradiaNo ratings yet
- Representing Road Related Laserscanned Data in Curved Regular Grid: A Support To Autonomous VehiclesDocument5 pagesRepresenting Road Related Laserscanned Data in Curved Regular Grid: A Support To Autonomous VehiclesN'GOLO MAMADOU KONENo ratings yet
- Object Detection and Tracking Algorithms For Vehicle Counting: A Comparative AnalysisDocument11 pagesObject Detection and Tracking Algorithms For Vehicle Counting: A Comparative Analysisnaresh tinnaluriNo ratings yet
- Neural-Network-Based Traffic Sign Detection and Recognition in High-Definition Images Using Region Focusing and ParallelizationDocument14 pagesNeural-Network-Based Traffic Sign Detection and Recognition in High-Definition Images Using Region Focusing and ParallelizationVo Hoang Nguyen Vy B1706556No ratings yet
- GPS Based Vehicular Collision Warning System Using IEEE 802.15.4 MAC/PHY StandardDocument6 pagesGPS Based Vehicular Collision Warning System Using IEEE 802.15.4 MAC/PHY StandardEleazar DavidNo ratings yet
- Rodriguez Mva 2011Document16 pagesRodriguez Mva 2011Felipe Taha Sant'AnaNo ratings yet
- Ijet V4i3p31 PDFDocument5 pagesIjet V4i3p31 PDFInternational Journal of Engineering and TechniquesNo ratings yet
- Sensors: Radar Transformer: An Object Classification Network Based On 4D MMW Imaging RadarDocument16 pagesSensors: Radar Transformer: An Object Classification Network Based On 4D MMW Imaging RadarfakeNo ratings yet
- Feasibility Analysis of Driverless Car Using Vanets: 1.2 Google Driver Less CarDocument3 pagesFeasibility Analysis of Driverless Car Using Vanets: 1.2 Google Driver Less CarhrishikeshNo ratings yet
- Leveraging Mobile Net and Yolo Algorithm For Enhanced Perception in Autonomous DrivingDocument5 pagesLeveraging Mobile Net and Yolo Algorithm For Enhanced Perception in Autonomous DrivingInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- SZALAY Et Al-ICTINROADVEHICLESOBDvsCANDocument8 pagesSZALAY Et Al-ICTINROADVEHICLESOBDvsCANKunal AhiwaleNo ratings yet
- Data Collection Through Vehicular Sensor Networks by Using TCDGPDocument7 pagesData Collection Through Vehicular Sensor Networks by Using TCDGPRadhe KrishnNo ratings yet
- Sensors 18 00177 v2Document14 pagesSensors 18 00177 v2Hậu PhạmNo ratings yet
- Car Following Logic (Wiedemann 1974)Document22 pagesCar Following Logic (Wiedemann 1974)pritshNo ratings yet
- Collision Identification Using Radar: Oakland University School of Engineering and Computer ScienceDocument33 pagesCollision Identification Using Radar: Oakland University School of Engineering and Computer ScienceSujith JanardananNo ratings yet
- Vehicle ViewDocument7 pagesVehicle ViewGautam DemattiNo ratings yet
- Traffic-Net: 3D Traffic Monitoring Using A Single Camera: Mahdi Rezaei, Mohsen Azarmi, Farzam Mohammad Pour MirDocument21 pagesTraffic-Net: 3D Traffic Monitoring Using A Single Camera: Mahdi Rezaei, Mohsen Azarmi, Farzam Mohammad Pour MirRezaei MNo ratings yet
- A Vehicle Recognition Method Based On Radar and Camera Fusion in AnDocument10 pagesA Vehicle Recognition Method Based On Radar and Camera Fusion in AnАкжаркын ИзбасароваNo ratings yet
- Traffic Light Detection and Recognition For Self Driving Cars Using Deep Learning SurveyDocument4 pagesTraffic Light Detection and Recognition For Self Driving Cars Using Deep Learning SurveyEditor IJTSRDNo ratings yet
- Sensors: Benchmarking of Various Lidar Sensors For Use in Self-Driving Vehicles in Real-World EnvironmentsDocument20 pagesSensors: Benchmarking of Various Lidar Sensors For Use in Self-Driving Vehicles in Real-World EnvironmentsKarriChiranjeeviNo ratings yet
- PreprintTraffic Sign Detection NeurocomputingDocument26 pagesPreprintTraffic Sign Detection Neurocomputingami videogameNo ratings yet
- Intelligent Traffic-Monitoring System Based On YOLO and Convolutional Fuzzy Neural NetworksDocument14 pagesIntelligent Traffic-Monitoring System Based On YOLO and Convolutional Fuzzy Neural Networksahammedijas2209118No ratings yet
- SDN Based ITSDocument13 pagesSDN Based ITSSuresh ChavhanNo ratings yet
- Changle Li 2021Document15 pagesChangle Li 2021Dung NguyễnNo ratings yet
- Sensors 21 03485Document24 pagesSensors 21 03485wayne.nguyenNo ratings yet
- Calculating The Speed of Vehicles Using Wireless Sensor NetworksDocument5 pagesCalculating The Speed of Vehicles Using Wireless Sensor NetworksHayderNo ratings yet
- LIDAR Based Object DetectionDocument3 pagesLIDAR Based Object DetectionSarthak BatraNo ratings yet
- MAJORDocument24 pagesMAJORC RAHUL RAO.571No ratings yet
- Ahmad, 2021Document15 pagesAhmad, 2021Faisal AliNo ratings yet
- Dokania IDD-3D Indian Driving Dataset For 3D Unstructured Road Scenes WACV 2023 PaperDocument10 pagesDokania IDD-3D Indian Driving Dataset For 3D Unstructured Road Scenes WACV 2023 PaperSharan RaoNo ratings yet
- Radar Target Simulation For Vehicle-in-the-Loop TestingDocument15 pagesRadar Target Simulation For Vehicle-in-the-Loop TestingmakkieNo ratings yet
- Traffic Flow Analysis With Multiple Adaptive Vehicle Detectors and Velocity Estimation With Landmark-Based ScanlinesDocument8 pagesTraffic Flow Analysis With Multiple Adaptive Vehicle Detectors and Velocity Estimation With Landmark-Based Scanlineskoushik reddyNo ratings yet
- Sensors 21 07744 v2Document18 pagesSensors 21 07744 v2SamNo ratings yet
- White Paper - Map Data For Safer ADAS To HAD Solutions - VSI LabsDocument12 pagesWhite Paper - Map Data For Safer ADAS To HAD Solutions - VSI LabsRachana MedehalNo ratings yet
- Sensors 21 02477 v2Document12 pagesSensors 21 02477 v2sayondeepNo ratings yet
- V2Vnet: Vehicle-To-Vehicle Communication For Joint Perception and PredictionDocument17 pagesV2Vnet: Vehicle-To-Vehicle Communication For Joint Perception and Predictionaleposada7No ratings yet
- Vehicle Tracking and Classification in Challenging Scenarios Via Slice SamplingDocument17 pagesVehicle Tracking and Classification in Challenging Scenarios Via Slice SamplingYaste YastawiqalNo ratings yet
- New Trajectory ApproxDocument18 pagesNew Trajectory Approxgodidet305No ratings yet
- Vacant Parking Slot Detection in The Around ViewDocument22 pagesVacant Parking Slot Detection in The Around ViewZiadelkNo ratings yet
- PHD Research Proposal of Waqar Baig PDFDocument11 pagesPHD Research Proposal of Waqar Baig PDFSajid GhanghroNo ratings yet
- Object Detection Using YOLODocument9 pagesObject Detection Using YOLOIJRASETPublicationsNo ratings yet
- Roadroid Smartphone ApplicationDocument5 pagesRoadroid Smartphone ApplicationDoly ManurungNo ratings yet
- Autonomous Driving in The ICity-HD Maps As A Key CDocument4 pagesAutonomous Driving in The ICity-HD Maps As A Key CGopesh SinghNo ratings yet
- Lane Detection Project ReportDocument15 pagesLane Detection Project ReportDuong DangNo ratings yet
- A Comprehensive Survey of LIDAR-based 3D Object Detection MethodsDocument29 pagesA Comprehensive Survey of LIDAR-based 3D Object Detection MethodsWilliam SantosNo ratings yet
- From Pseudo Code To Program CodeDocument24 pagesFrom Pseudo Code To Program Codeمحمد يسر سواسNo ratings yet
- Nfsv4 Co-Existence With Cifs in A Multi-Protocol EnvironmentDocument19 pagesNfsv4 Co-Existence With Cifs in A Multi-Protocol EnvironmentFrez17No ratings yet
- From Digital Greenfields To Brownfield IoT SuccessDocument9 pagesFrom Digital Greenfields To Brownfield IoT SuccessALEJANDRO HERNANDEZNo ratings yet
- Mobile Computing Professor Pushpendra Singh Indraprastha Institute of Information Technology Delhi Android Studio SetupDocument10 pagesMobile Computing Professor Pushpendra Singh Indraprastha Institute of Information Technology Delhi Android Studio Setupmrd9991No ratings yet
- Term Project Advance Computer Architecture Spring 2017: SubmissionDocument3 pagesTerm Project Advance Computer Architecture Spring 2017: SubmissionTofeeq Ur Rehman FASTNUNo ratings yet
- XJXJXJXDocument30 pagesXJXJXJXaz channelNo ratings yet
- PP UNIT 4 (Object Oriented Programming)Document67 pagesPP UNIT 4 (Object Oriented Programming)naman jaiswalNo ratings yet
- Test Number Section 1: Sat Practice Answer SheetDocument2 pagesTest Number Section 1: Sat Practice Answer Sheetهخه •No ratings yet
- Rules For Web Content WritingDocument4 pagesRules For Web Content WritingAbhishek RawatNo ratings yet
- Password ManagementDocument16 pagesPassword ManagementjimNo ratings yet
- CMake Tutorial 8feb2012Document148 pagesCMake Tutorial 8feb2012kaosadNo ratings yet
- Lab 10Document5 pagesLab 10Abdolkarim PahlianiNo ratings yet
- Script Writing and Radio Broadcasting E.D. BibalDocument22 pagesScript Writing and Radio Broadcasting E.D. Biballovelymae.madaliNo ratings yet
- Answers Are Marked in BoldDocument31 pagesAnswers Are Marked in BoldpankajNo ratings yet
- CH - 2 Applications and Methodologies Class 11 NotesDocument13 pagesCH - 2 Applications and Methodologies Class 11 NotesMeet RakholiyaNo ratings yet
- Test Automation FundamentalsDocument49 pagesTest Automation Fundamentalsvbdfg5100% (1)
- Texnomic Tradex Bot: Announcement #3Document1 pageTexnomic Tradex Bot: Announcement #3lawNo ratings yet
- VRPPTDocument22 pagesVRPPTavinash kumarNo ratings yet
- Drought: FEMA National Risk Index Drought Processing Methodology DocumentDocument15 pagesDrought: FEMA National Risk Index Drought Processing Methodology Documentriksa nugraha utamaNo ratings yet
- GoogleDocument5 pagesGoogleRikky MayantoNo ratings yet
- ariesoGEO Data Collection Setup - Huawei UMTS PDFDocument10 pagesariesoGEO Data Collection Setup - Huawei UMTS PDFWidagdho WidyoNo ratings yet
- 5325 Mmsys18 Dataset Paper Darijo Accepted VersionDocument8 pages5325 Mmsys18 Dataset Paper Darijo Accepted VersionRafiq MagdyNo ratings yet
- Flashing - Guides Real Me 3 ProDocument12 pagesFlashing - Guides Real Me 3 Proswebee23No ratings yet
- D800010X062Document605 pagesD800010X062Zakaria Ahmed KhanNo ratings yet
- Hyundai Care APP Registration Login ProcessDocument4 pagesHyundai Care APP Registration Login ProcessDhashana MoorthyNo ratings yet
- FTS MainboardD3441D3445D3446Shortdescription 032016 1157474Document26 pagesFTS MainboardD3441D3445D3446Shortdescription 032016 1157474IGNFONo ratings yet
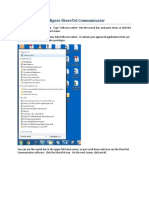
- To Install and Configure ShoreTel Communicator-Revised Software CTRDocument10 pagesTo Install and Configure ShoreTel Communicator-Revised Software CTRBladimilPujOlsChalasNo ratings yet
- Important Tips For HCCDA - 50840Document4 pagesImportant Tips For HCCDA - 50840raabubakar490No ratings yet
- IBM Spectrum Protect SnapshotDocument224 pagesIBM Spectrum Protect Snapshotgoosie66No ratings yet
- Services in t24Document27 pagesServices in t24lyes ٌRivest0% (1)
- CATIA V5-6R2015 Basics - Part I : Getting Started and Sketcher WorkbenchFrom EverandCATIA V5-6R2015 Basics - Part I : Getting Started and Sketcher WorkbenchRating: 4 out of 5 stars4/5 (10)
- Certified Solidworks Professional Advanced Weldments Exam PreparationFrom EverandCertified Solidworks Professional Advanced Weldments Exam PreparationRating: 5 out of 5 stars5/5 (1)
- Beginning AutoCAD® 2020 Exercise WorkbookFrom EverandBeginning AutoCAD® 2020 Exercise WorkbookRating: 2.5 out of 5 stars2.5/5 (3)
- FreeCAD | Step by Step: Learn how to easily create 3D objects, assemblies, and technical drawingsFrom EverandFreeCAD | Step by Step: Learn how to easily create 3D objects, assemblies, and technical drawingsRating: 5 out of 5 stars5/5 (1)
- SketchUp Success for Woodworkers: Four Simple Rules to Create 3D Drawings Quickly and AccuratelyFrom EverandSketchUp Success for Woodworkers: Four Simple Rules to Create 3D Drawings Quickly and AccuratelyRating: 1.5 out of 5 stars1.5/5 (2)
- Contactless Vital Signs MonitoringFrom EverandContactless Vital Signs MonitoringWenjin WangNo ratings yet
- Design Research Through Practice: From the Lab, Field, and ShowroomFrom EverandDesign Research Through Practice: From the Lab, Field, and ShowroomRating: 3 out of 5 stars3/5 (7)