You might also like
- 1 Level Date: Student:: Danica Davidman, BCBA, All Rights ReservedDocument1 page1 Level Date: Student:: Danica Davidman, BCBA, All Rights ReservedJelena StojiljkovicNo ratings yet
- A Typographers ChecklistDocument7 pagesA Typographers ChecklistDina Bogdan-AlexandruNo ratings yet
- Perl Training RegexDocument27 pagesPerl Training Regexchandu_bezawadaNo ratings yet
- Traditional Grammar: Grammar - Studying-the-Approach-of-Traditional-Grammarians&id 1765312Document17 pagesTraditional Grammar: Grammar - Studying-the-Approach-of-Traditional-Grammarians&id 1765312arkina_sunshineNo ratings yet
- Perl - Part Iii: Indian Institute of Technology KharagpurDocument24 pagesPerl - Part Iii: Indian Institute of Technology KharagpurAbdul Ghani KhanNo ratings yet
- TOEFL (Reading & Vocab)Document24 pagesTOEFL (Reading & Vocab)Hutama Putra Wibawa100% (1)
- Prime Numbers: The Most Mysterious Figures in MathFrom EverandPrime Numbers: The Most Mysterious Figures in MathRating: 3 out of 5 stars3/5 (11)
- Noise PollutionDocument144 pagesNoise PollutionGAMING FOR LIFENo ratings yet
- Gerund Vs ParticipleDocument6 pagesGerund Vs ParticipleJahirul Quaim100% (1)
- Chapter 3Document51 pagesChapter 3Dip Das100% (1)
- NLP Chapter 5Document70 pagesNLP Chapter 5ai20152023No ratings yet
- Chapter Three Regular Expressions and Finite-State AutomataDocument19 pagesChapter Three Regular Expressions and Finite-State AutomataramuarulmuruganNo ratings yet
- Regular Expressions & AutomataDocument62 pagesRegular Expressions & AutomataNelakurthi SudheerNo ratings yet
- Lecture 03Document13 pagesLecture 03ali khanNo ratings yet
- Oow Getting Regular With Regular ExpressionsDocument62 pagesOow Getting Regular With Regular Expressionsnahid423100% (1)
- Syntax AnalysisDocument87 pagesSyntax AnalysisSaif UllahNo ratings yet
- Python ReDocument101 pagesPython ReMinhaj GhouriNo ratings yet
- Lecture 2: Regular Expressions, Text NormalizationDocument19 pagesLecture 2: Regular Expressions, Text NormalizationManaal AzfarNo ratings yet
- Regular Expressions: SESSION - 14 - 15 - 16Document42 pagesRegular Expressions: SESSION - 14 - 15 - 16Graisy BiswalNo ratings yet
- Regular Expressions and Sed & AwkDocument14 pagesRegular Expressions and Sed & AwkFadli MzrNo ratings yet
- 1st GR Narr Rubric NW 12 2012Document2 pages1st GR Narr Rubric NW 12 2012api-143406529No ratings yet
- Syntax Analysis (Part-I)Document88 pagesSyntax Analysis (Part-I)PRANEETH DUTTA GORUPOTUNo ratings yet
- Theory of Computation: Madhav Institute of Technology and ScienceDocument38 pagesTheory of Computation: Madhav Institute of Technology and Sciencejyash1293No ratings yet
- Regular Expressions - Character Classes & Findall Method - by Zohaib Shahzad - MediumDocument11 pagesRegular Expressions - Character Classes & Findall Method - by Zohaib Shahzad - Mediumnur fuadNo ratings yet
- 04 RegexpDocument26 pages04 RegexpseravanakumarNo ratings yet
- Formal Methods: Finite State Machine - Regular ExpressionsDocument14 pagesFormal Methods: Finite State Machine - Regular ExpressionsStatus LifeNo ratings yet
- Slide14 RegularExpressionDocument45 pagesSlide14 RegularExpressionPro UnipadderNo ratings yet
- 4 - Lecture 08 (Syntax Analysis - Part I)Document67 pages4 - Lecture 08 (Syntax Analysis - Part I)Akarsh KusumanchiNo ratings yet
- 2-Introduction To Language Engineering - Part2Document26 pages2-Introduction To Language Engineering - Part2salma montaserNo ratings yet
- 2 TextProc Mar 25 2021Document71 pages2 TextProc Mar 25 2021Krisostomus Nova RahmantoNo ratings yet
- Lecture 13 - String - ProcessingDocument22 pagesLecture 13 - String - ProcessingHoang Nhat MinhNo ratings yet
- CS 105 Perl: Introduction To Regular Expressions: Curtis DunhamDocument32 pagesCS 105 Perl: Introduction To Regular Expressions: Curtis DunhamBrokolino MućakNo ratings yet
- 2 - Python StringsDocument23 pages2 - Python Stringspavan KumarNo ratings yet
- Perlre Perl Regular ExpressionsDocument16 pagesPerlre Perl Regular Expressionsfippifuppi78No ratings yet
- REGULAR EXPRESSIONS WorkbookDocument8 pagesREGULAR EXPRESSIONS WorkbooksfaisalaliuitNo ratings yet
- 1st GR Informative Rubric nw12 2012 1Document2 pages1st GR Informative Rubric nw12 2012 1api-143406529No ratings yet
- RegexDocument24 pagesRegexsaif MokarromNo ratings yet
- CC 2Document65 pagesCC 2KamiNo ratings yet
- Dakshina Ranjan Kisku Department of Computer Science and Engineering National Institute of Technology DurgapurDocument19 pagesDakshina Ranjan Kisku Department of Computer Science and Engineering National Institute of Technology DurgapurAgrawal DarpanNo ratings yet
- Source Serif ProDocument4 pagesSource Serif ProGilson OlegarioNo ratings yet
- RegularExpressionsDocument16 pagesRegularExpressionssaisuraj1510No ratings yet
- CPSC 388 - Compiler Design and Construction: Scanners - Regular ExpressionsDocument20 pagesCPSC 388 - Compiler Design and Construction: Scanners - Regular ExpressionsKashif RaffatNo ratings yet
- Erica Gamets GREP Cheat Sheet PDFDocument4 pagesErica Gamets GREP Cheat Sheet PDFLorena Cano VergaraNo ratings yet
- Erica Gamets GREP Cheat SheetDocument4 pagesErica Gamets GREP Cheat SheetNimi WineNo ratings yet
- Regular ExpressionDocument10 pagesRegular ExpressionFairooz RashedNo ratings yet
- ': Q UickDocument4 pages': Q UickBilly KidsNo ratings yet
- NLP Unit1ContentDocument106 pagesNLP Unit1ContentarunNo ratings yet
- Filter 4Document11 pagesFilter 4Sagar ChingaliNo ratings yet
- Web Tehcnology Lecture-5 - 6Document20 pagesWeb Tehcnology Lecture-5 - 6Santa clausNo ratings yet
- Regular Expressions: Item 15: Know The Precedence of Regular Expression OperatorsDocument36 pagesRegular Expressions: Item 15: Know The Precedence of Regular Expression OperatorsPinky NaharNo ratings yet
- Metacharacters: Any Character, Except A Newline. For Example, The RegexpDocument2 pagesMetacharacters: Any Character, Except A Newline. For Example, The Regexppankajsharma2k3No ratings yet
- Module 2Document78 pagesModule 2MANAS DUTTANo ratings yet
- Javascript Regular Expressions and Exception Handling: Prof - N. Nalini Ap (SR) Scope Vit VelloreDocument30 pagesJavascript Regular Expressions and Exception Handling: Prof - N. Nalini Ap (SR) Scope Vit VelloreHansraj RouniyarNo ratings yet
- Chapter 2 - Regular ExpressionDocument25 pagesChapter 2 - Regular ExpressionHoney Myint KyawNo ratings yet
- Regular Expressions in PerlDocument13 pagesRegular Expressions in PerlGirish ManwaniNo ratings yet
- Computational Linguistics: Dr. Dina KhattabDocument7 pagesComputational Linguistics: Dr. Dina KhattabDalia AhmedNo ratings yet
- CHEM337 Research 3Document3 pagesCHEM337 Research 3Dzul FahmiNo ratings yet
- ACT CH2 Regular Expressions and LanguagesDocument59 pagesACT CH2 Regular Expressions and LanguageskenbonhundaraNo ratings yet
- CS 491 Natural Language Processing Module 2: Basic Text ProcessingDocument24 pagesCS 491 Natural Language Processing Module 2: Basic Text ProcessingSakshi NijhawanNo ratings yet
- Unit3 TocDocument97 pagesUnit3 TocSparsh VermaNo ratings yet
- Syllabication TipsDocument3 pagesSyllabication TipsVimal NairNo ratings yet
- BMED136 Problem 1Document5 pagesBMED136 Problem 1Eym MeNo ratings yet
- Booking ConfirmationDocument3 pagesBooking ConfirmationDip DasNo ratings yet
- Client Coveted Interview PhrasesDocument2 pagesClient Coveted Interview PhrasesDip DasNo ratings yet
- BMS Invoice 3902383498Document1 pageBMS Invoice 3902383498Dip DasNo ratings yet
- Statistical Constituency Pars-Ing: 14.1 Probabilistic Context-Free GrammarsDocument29 pagesStatistical Constituency Pars-Ing: 14.1 Probabilistic Context-Free GrammarsDip DasNo ratings yet
- HW 2Document1 pageHW 2Dip DasNo ratings yet
- IELTSDocument2 pagesIELTSDip DasNo ratings yet
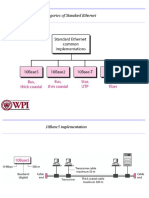
- EthernetDocument42 pagesEthernetDip DasNo ratings yet
- Dip Das AssignmentDocument3 pagesDip Das AssignmentDip DasNo ratings yet
- Networking and Internetworking DevicesDocument21 pagesNetworking and Internetworking DevicesDip DasNo ratings yet
- Problem Set 3 and 4Document3 pagesProblem Set 3 and 4Dip DasNo ratings yet
- Do It Yourself - Actividad 3Document3 pagesDo It Yourself - Actividad 3Dayana palominoNo ratings yet
- Kvs 2018 PRT Questions Hindi 57 PDFDocument16 pagesKvs 2018 PRT Questions Hindi 57 PDFMridula KumariNo ratings yet
- Figurative Language That ComparesDocument11 pagesFigurative Language That ComparesMishaNo ratings yet
- Prefijos y SufijosDocument5 pagesPrefijos y SufijosKatyana SilvaNo ratings yet
- Unit 11 - There - S No ComparisonDocument2 pagesUnit 11 - There - S No ComparisonSolís TannyNo ratings yet
- Linguistic DiscussionDocument13 pagesLinguistic DiscussionqieraNo ratings yet
- Lesson 2 PoetryDocument16 pagesLesson 2 PoetryCyra ArquezNo ratings yet
- Common Noun and Proper NounDocument14 pagesCommon Noun and Proper NounRoann BalezaNo ratings yet
- English 4&5 - PT - MsJustineDocument2 pagesEnglish 4&5 - PT - MsJustine賈斯汀No ratings yet
- 52 Grammar Topics in English PDFDocument1 page52 Grammar Topics in English PDFLouie SerranoNo ratings yet
- Template RPH 2023 NewDocument33 pagesTemplate RPH 2023 NewNur Assyura Abdul RahimNo ratings yet
- ES1103 Tutorial 17Document17 pagesES1103 Tutorial 17Sourabh RajNo ratings yet
- Localizationxlsx PDF FreeDocument168 pagesLocalizationxlsx PDF Freeاسراء الداعورNo ratings yet
- Determine Meaning From Word PartDocument10 pagesDetermine Meaning From Word PartzulfaaakfiiNo ratings yet
- English Grammar NewDocument173 pagesEnglish Grammar Newshubham bobde100% (1)
- Purposive Communication Report July 2Document38 pagesPurposive Communication Report July 2Jericho MarianoNo ratings yet
- Sample Lesson Exemplar in English VIDocument7 pagesSample Lesson Exemplar in English VIdranoelmasky50% (8)
- Sociolinguistics (Social Dialect)Document6 pagesSociolinguistics (Social Dialect)Sella Safitri100% (1)
- The Silent Way - OdtDocument9 pagesThe Silent Way - OdtDani SilvaNo ratings yet
- Table of SpecificationsDocument6 pagesTable of SpecificationsJose Jade GonzalesNo ratings yet
- Instruction of Assignment RoleplayDocument2 pagesInstruction of Assignment RoleplayMuhammad AnuarNo ratings yet
- New Images CB-6 Ch1-3 With TOCDocument28 pagesNew Images CB-6 Ch1-3 With TOCBobby NoharaNo ratings yet
- Modality and RepresentationDocument43 pagesModality and RepresentationMariam SinghiNo ratings yet
- SemiDocument2 pagesSemiCristia Faye Lumawag LaoNo ratings yet
- Tomas PinpinDocument2 pagesTomas PinpinZyrene CabaldoNo ratings yet