Professional Documents
Culture Documents
Lecture Notes Ling2019 1
Uploaded by
Phúc NguyễnOriginal Title
Copyright
Available Formats
Share this document
Did you find this document useful?
Is this content inappropriate?
Report this DocumentCopyright:
Available Formats
Lecture Notes Ling2019 1
Uploaded by
Phúc NguyễnCopyright:
Available Formats
lOMoARcPSD|27553903
49275 Lecture Notes Ling(2019 )-1
Neural Networks and Fuzzy Logic (University of Technology Sydney)
Studocu is not sponsored or endorsed by any college or university
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
Steve Ling
School of Biomedical Engineering
Faculty of Engineering and Information Technology
University of Technology, Sydney
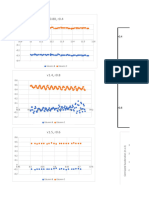
Fuzzy input1: Heart rate
1
Output membership value
0.8
0.6
VL L M H VH
0.4
0.2
0
0.5 1 1.5 2 2.5
Normailized heat rate
Fuzzy input2: Corrected QT interval
1
Output membership value
0.8
0.6
VL L M H VH
0.4
0.2
0
Fuzzy
0.7 0.8 0.9 1 1.1 1.2 1.3 1.4 1.5
Normailized corrected QT interval Logic
UTS
March 2019
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
49275 Neural Networks and Fuzzy Logic
Steve SH Ling
CONTENTS
1. INTRODUCTION TO NEURAL NETWORKS AND FUZZY LOGIC
1.1 Model-Free Systems 1
1.2 Important Milestones 2
1.2.1 Neural Networks 2
1.2.2 Fuzzy Systems 4
1.3 Various Structures 5
1.3.1 Neural Networks 5
1.3.2 Fuzzy Systems 7
1.4 Introduction to Neural Networks 8
1.4.1 Biological Neurons 8
1.4.2 Simple Neuron model 10
1.4.3 Architectures, Output Characteristics and Learning Algorithms 11
1.4.4 Applications of neural network 12
1.5 Introduction to Fuzzy Logic 13
1.5.1 Fuzzy Set Theory 13
1.5.2 Support Set 14
1.5.3 Membership Functions 14
1.5.4 Fuzzy Set Operations 16
1.5.5 Extension Principle 18
1.5.6 Linguistic Hedges 18
References 20
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
2. FUNDAMENTAL CONCEPTS OF NEURAL NETWORKS
2.1 Neuron Modelling for Artificial Neural Systems 23
2.1.1 McCulloch-Pitts Neuron Model 23
2.1.2 Perceptrons 26
2.2 Basic Network Architectures 30
2.2.1 Feedforward Network 30
2.2.2 Recurrent Network 31
2.3 Learning Rules 32
2.3.1 Supervised and Unsupervised Learning 32
2.3.2 The General Learning Rule 32
2.3.3 Hebbian Learning Rule 33
2.3.4 Discrete Perceptron Learning Rule 34
2.3.5 Delta Learning Rule 35
2.3.6 Widrow-Hoff Learning Rule 37
2.3.7 Summary of learning rule and their properties 38
References 38
3. FUNDAMENTAL CONCEPTS OF FUZZY LOGIC AND FUZZY
CONTROLLER
3.1 Fundamental concepts of fuzzy logic 39
3.1.1 Fuzzy Relations 39
3.1.2 Composition of Fuzzy Relations 40
3.2 Fuzzy Logic Control System 42
3.2.1 System Variables 43
3.2.2 Fuzzification 44
3.2.3 Fuzzy Control Rules and Rule Base 45
3.2.4 Reasoning Techniques 49
ii
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
3.2.5 Defuzzification 51
3.3 Closed Loop Fuzzy Logic Control 56
3.4 Self-Organising Fuzzy Logic Controller 66
3.4.1 Structure of a SOFLC 66
3.4.2 Performance Index Table 67
3.4.3 Rule-base Generation and Modification 68
3.4.4 Self-Organising Procedure 68
3.4.5 Remarks 69
References 70
4. SINGLE-LAYER FEEDFORWRD NEURAL NETWORKS AND
RECURRENT NEURAL NETWORK
4.1 Single-Layer Perceptron Classifiers 71
4.1.1 Classification Model 71
4.1.2 Discriminant Functions 73
4.1.3 Linear Classifier 74
4.1.4 Minimum-distance classifier 77
4.1.5 Non-parametric Training Concept 80
4.1.6 Training and Classification using the Discrete Perceptron 83
4.1.7 Single-Layer Continuous Perceptron Networks 85
4.1.8 Multi-Category Single-Layer Perceptron Networks 89
4.2 Single-Layer Feedback (Recurrent) Network 92
References 96
iii
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
5. MULTI-LAYER FEEDFORWRD NEURAL NETWORKS
5.1. Linearly Nonseparable Patterns 97
5.2 Delta Learning Rule for Multi-Perceptron Layer 100
5.3 Generalised Delta Learning Rule (Error Back Propagation Training) 101
5.4 Learning Factors 104
5.4.1 Evaluate the network performance 104
5.4.2 Initial Weights 106
5.4.3 Learning Constant 106
5.4.4 Adaptive Learning rate 107
5.4.5 Momentum Method 107
5.4.6 Network Architecture and Data Representation 109
5.5 Batch Mode Training 113
5.6 Early Stopping Method of Training 114
References 115
6. INTRODUCTION TO CONVOLUTIONAL NEURAL NETWORKS
6.1 Motivation 116
6.2 Architecture of Convolutional Neural Networks 117
6.2.1 Convolutional Layer 117
6.2.1.1 Local Connectivity 118
6.2.1.2 Spatial Arrangement 119
6.2.1.3 Parameter Sharing 121
6.2.2 Pooling Layer 124
6.2.3 Fully-connected Layer 128
6.2.4 Softmax 128
iv
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
6.3 Optimization Algorithms for Training Deep Models 129
6.3.1 Stochastic Gradient Descent 129
6.3.2 Momentum 130
6.3.3 Parameter initialization strategy 132
6.3.4 Algorithms with Adaptive Learning Rates 132
6.3.4.1 AdaGrad 133
6.3.4.2 RMSProp 134
6.3.4.3 Adam 135
6.3.4.4 Choosing the Right Optimization Algorithm 135
6.3.5 Batch Normalization 136
References 137
7. GENETIC ALGORITHMS
7.1 Introduction to Genetic Algorithm 138
7.2 Optimisation of a simple function 139
7.2.1 Representation 140
7.2.2 Initial population 141
7.2.3 Evaluation function 141
7.2.4 Genetic operators 142
7.2.5 Parameters 143
7.2.6 Experimental results 143
7.3 Genetic Algorithms: How do they work? 144
7.4 Real-coded Genetic Algorithms 155
7.4.1 Crossover operations 157
7.4.1.1 Single-point crossover 157
7.4.1.2 Arithmetic crossover 157
7.4.1.3 Blend- crossover 158
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
7.4.2 Mutation operations 158
7.4.2.1 Uniform mutation 158
7.4.2.2 Non-uniform mutation 159
7.5 Training the neural network using Genetic Algorithm 159
References 161
vi
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
CHAPTER ONE
INTRODUCTION TO NEURAL NETWORKS AND FUZZY
LOGIC
_______________________________________________________
Chapter 1.1 Model-Free Systems
In a world of evolving complexity and variety, although events are never the same, there
is some continuity, similarity and predictability which allow us to generalise future
events from past experience. Two techniques, neural networks and fuzzy systems, share
the common ability to work well in this natural environment which is riddled with
difficulty arising from uncertainty, imprecision, and noise.
Neural networks and fuzzy systems estimate functions from sample data. Deterministic and
statistical approaches also estimate functions, however they require mathematical models.
Neural networks and fuzzy systems are model-free estimators as they do not require the
development of system models such as transfer functions and state-space representations.
The operational framework of neural networks and fuzzy systems is symbolic.
Neural networks theory has its structure embedded in the mathematical fields of
dynamical systems, optimal and adaptive control, and statistics. Fuzzy theory
encompasses these fields and others such as probability, mathematical logic, and
nonlinear control. Applications of neural networks include high speed moderns, long
distance telephone calls, airport bomb detectors, medical imaging, biomedical signal
classification systems and handwritten character and speech recognition systems.
Applications of fuzzy systems include subway systems, elevator and traffic light scheduling
systems. Fuzzy systems are also used to auto-focus camcorders, smart home systems,
biomedical instrumentation, and to control smartly household appliances such as air
conditioners, washing machines, vacuum cleaners, and refrigerators.
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
Chapter 1.2 Important Milestones
1.2.1 Neural Networks
McCulloch and Pitts outlined the first formal element of an elementary computing neuron in
1943. The connections between neurons in a network fundamentally determine the dynamics
of the network. For this reason, the field known today as Neural Networks was originally
called Connectionism. Networks of this type seemed appropriate for modelling not only
symbolic logic, but also perception and behaviour.
In 1958, Rosenblatt found models based on McCulloch & Pitts neurons to be
unbiological. They required implausibly precise connections and timing, and they did not take
into account model variations in real neural networks. Rosenblatt then developed a theory of
statistical separability in a class of network models called perceptrons. It became clear later
that the perceptron was incapable of learning to distinguish classes of patterns which were not
linearly separable.
The solution of this problem is back-propagation, a method of training a neural network to
approximate any function, including arbitrary complex functions. It is the only form of neural
network which has produced a significant number of commercial applications.
In 1988, Yann LeCun developed a fundamental convolutional neural network which named
LeNet5. The image features are distributed across the entire image, and convolutions with
learnable parameters are an effective way to extract similar features at multiple location with few
parameters. In 2014, Christian Szegedy from Google begun a quest aimed at reducing the
computational burden of deep neural networks, and devised the GoogLeNet the first Inception
architecture.
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
The important milestones in the development of artificial neural systems may be
summarised in Table 1 . 1.
Table 1 . 1 Milestones in the development of artificial neural systems
1943 McCulloch, Pitts McCulloch & Pitts neuron model
1949 Hebb Hebbian learning rule
1954 Minsky First neurocomputer
1958 Rosenblatt Rosenblatt perceptron
1960 Widrow, Hoff ADALINE (Adaptive Linear Element)
1962 Widrow, Hoff Widrow-Hoff learning rule
1974 Grossberg, Cohen ART (Adaptive Resonance Theory)
1974 Werbos Early exposition of back-propagation
1977 Kohonen Associative memory
1980 Fukushima, Miyaka Neocognitron
1982 Hopfield Recurrent neural networks
1982 Kohonen Self-organising maps
1986 Rumelhart, Hinton, Williams Back-propagation
1988 Broomhead, Lowe Radial basis function
1988 Yann LeCun Convolutional neural network (LeNet5)
1992 MacKay Bayesian neural networks
2014 Christian Szegedy GoogLeNet
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
1.2.2 Fuzzy Systems
During the past several years, fuzzy logic control has emerged as one of the most active and
fruitful areas for research in the application of fuzzy set theory. Motivated by Zadeh's seminal
papers on the linguistic approach and system analysis based on the theory of fuzzy sets,
Mamdani and his colleagues pioneered the use of fuzzy logic control. Recent applications
have shown effective control using fuzzy logic can be designed for complex ill-defined control
systems without the knowledge of their underlying dynamics.
The important milestones in the development of fuzzy logic control may be summarised in
Table 1 . 2.
Table 1 . 2 Milestones in the development of fuzzy logic control
1965 Zadeh Fuzzy sets
1972 Zadeh A rationale for fuzzy logic control
1973 Zadeh Linguistic approach
1974 Mamdani, Assilian Steam engine control
1977 Ostergaard Heat exchanger and cement kiln control
1979 Procyk Self-organising fuzzy logic control
1980 Tong et al. Wastewater treatment process
1980 Fukami, Muzimoto, Tanaka Fuzzy conditional inference
1984 Sugeno, Murakami Parking control of a model car
1985 Kiszka, Gupta Fuzzy system stability
1985 Takagi, Sugeno Takagi-Sugeno (T-S) fuzzy models
1987 Miyamoto, Yasunobu Sendai subway system
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
Chapter 1.3 Various Structures
1.3.1 Neural Networks
Back-propagation provides a way of using a target function to find the coefficients which make a
certain mapping function approximate the target function as closely as possible. The mapping
function in back-propagation is complex. It can be visualised as the computation carried
out by a fully connected three-layer feedforward network. The network consists of three
layers: the input, hidden, and output layers as shown in Figure 1.1.
Input Layer Hidden Layer Output Layer
Figure 1.1 Neural Network
Neural networks used for identification purposes typically have multilayer feedforward
architectures and are trained using the error back-propagation technique. The basic configuration
for forward plant identification is shown in Figure 1.2. The identification of the plant inverse is
another viable alternative for designing control systems. A neural network configuration using
inverse plant identification is shown in Figure 1.3.
Figure 1.2 Forward Plant Identification
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
Figure 1.3 Plant Inverse Identification
Figure 1.4 shows the feedforward controller implemented using a neural network. Neurocontroller
B is an exact copy of neural network A, which undergoes training. Network A is connected so that
it gradually learns to perform as the unknown plant inverse. A closely related control architecture
for control and simultaneous specialised learning of the output domain is shown in Figure 1.5.
Figure 1.4 Neural Network Control with Plant Inverse Learning
Figure 1.5 Neural Network Control
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
1.3.2 Fuzzy Systems
A fuzzy logic controller (FLC) can be typically incorporated in a closed loop control system as
shown in Figure 1.6. The main elements of the FLC are a fuzzification unit, an inference engine
with a knowledge base, and a defuzzification unit.
The Self-Organising Fuzzy Logic Controller (SOFLC) shown in Figure 1.7 which has a control
policy which can change with respect to the process it is controlling and the environment it is
operating in. The particular feature of this controller is that it strives to improve its performance
until it converges to a predetermined quality.
Figure 1.6 Fuzzy logic controller
Figure 1.7 Self-organising fuzzy logic controller
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
Chapter 1.4 Introduction to Neural Networks
Neural Network is an interconnected assembly of simple processing elements, units, or nodes,
whose functionality is loosely based on the animal neuron. The processing ability of the
network is stored in the inter-unit connection, strengths, or weights, obtained by a process of
adaptation to, or learning from, a set of training patterns. One of the simple example of neural
network structure is shown in Figure 1.8. In this Figure, a denotes the input of network, b
denotes the output of network, U denotes the neuron (node), and w denotes the weight between
two neurons. There are three entities that characterize a neural network:
▪ The network topology, or interconnection of neural units (feedforward, recurrent, etc).
▪ The characteristics of individual units or artificial neurons (transfer functions).
▪ The strategy for pattern learning or training (Hebbian learning, delta learning rule, etc)
Figure 1.8 Example of neural network structure
1.4.1 Biological Neurons
The neuron is the fundamental building block of the biological network. Its schematic diagram
is shown in Figure 1.9. A typical cell has three major regions: the cell body (soma), the axon,
and the dendrites. Dendrites form a dendritic tree, which is a very fine bush of fibers around
the neuron's body. Dendrites receive information from neurons through long fibres called axons.
An axon is a long cylindrical connection that carries impulses from the neuron. The axon-
dendrite contact organ is called a synapse. The synapse is where the neuron introduces its signal
to the neighbouring neuron
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
The neuron is able to respond to the total of its inputs aggregated within a short time interval
called the period of latent summation. The neuron's response is generated if the total potential
of its membrane reaches a certain level. Incoming impulses can be excitatory if they cause the
firing of a neuron, or inhibitory if they hinder the firing of a response. A more precise condition
for firing is that the excitation should exceed the inhibition by the amount called the threshold
of the neuron, typically a value of about 40 mV. After carrying a pulse, an axon fibre is in a
state of completely nonexcitability for a certain time called the refractory period. The time
units for modelling biological neurons can be taken to be of the order of a millisecond. However,
the refractory period is not uniform over the cells.
The typical cycle time of neurons is about a million times slower than semiconductor gates.
Nevertheless, the brain can do very fast processing for tasks like vision, motor control, and
decisions even with access to incomplete and noisy data. This is obviously possible only
because billions of neurons operate simultaneously in parallel.
Figure 1.9 Schematic Diagram of a Neuron
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
1.4.2 Simple Neuron model
A basic neuron model is shown in Figure 1.10 (a) and its threshold T characteristic is shown
in Figure 1.10 (b). The firing rule for this model is defined as follows:
1 𝑛𝑒𝑡 ≥ 𝑇
𝑜 = 𝑓(𝑛𝑒𝑡) = { (1.1)
0 𝑛𝑒𝑡 < 𝑇
where 𝑛𝑒𝑡 = ∑𝑛𝑖=1 𝑤𝑖 𝑥𝑖 ,
o denotes the output of neuron,
𝑥𝑖 denotes the input of neuron, i = 1, 2, … n where n is the number of input.
𝑤𝑖 denotes the weight between the output o and input x.
Figure 1.10 Basic neuron model
To consider the conditions necessary for the firing of a neuron. Incoming impulses can be
excitatory if they cause the firing, or inhibitory if the hinder the firing of the response. Notes
that wi = +1 for excitatory synapses and wi = −1 for inhibitory synapses.
10
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
1.4.3 Architectures, Output Characteristics and Learning Algorithms
There are two main types of neural networks and namely Feed-forward networks and
Recurrent/feedback networks. A summary of the architectures of neural networks are shown in
Figure 1.11.
Various feed-forward neural networks have been developed such as single-layer perceptron,
multilayer perceptron and radial basis function nets, etc. Feed-forward type networks receive
external signals and simply propagate these signals through all the layers to obtain the result
(output) of the neural network. There are no feedback connection previous layer.
On the other hand, recurrent/feedback networks such as competitive networks, Kohonen’s
SOM, Hopfield network, etc, have such feedback connections to model the temporal
characteristics of the problem being learned.
Figure 1.11 A summary of the architectures of neural networks
One of the key characteristic of neural network is its learning ability. Learning consists of
adjusting weight and threshold values until a certain criterion (or several criteria) is (are)
satisfied.
There are two main types of learning:
Supervised learning, where the neuron (or neural network) is provided with a data set
consisting of input vectors and a target (desired output) associated with each input vector. This
data set is referred to as the training set. The aim of supervised training is then to adjust the
weight values such that the error between the real output of the neuron and the target output is
11
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
minimized. The learning algorithms of supervised learning are including LVQ, Perceptron,
Back-propagation, ARTMap, etc.
Unsupervised learning, where the aim is to discover patterns or features in the input data with
no assistance from an external source. Many unsupervised learning algorithms basically
perform a clustering of the training patterns. The learning algorithms of unsupervised learning
are including SOM, VQ, PCA, Hebb learning rule, etc.
1.4.4 Applications of neural network
There are six tasks that neural network can perform:
(1) Pattern classification
(2) Clustering
(3) Function approximation
(4) Prediction or forecasting
(5) Optimisation
(6) Retrieval by content
Figure 1.12 Tasks of neural network.
12
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
Chapter 1.5 Introduction to Fuzzy Logic
In a traditional set theory, an item is either a member of a set or it is not. This two-valued logic
has proved to be very effective in solving well-defined problems, which are characterised by
precise descriptions of the process being dealt with in quantitative form. However, there is a
class of problems which are typically complex or ill-defined in nature where the concepts are
no longer clearly true or false, but are more or less false or most likely true. Fuzzy set theory
emerged as one effective approach to dealing with these problems. Developed in 1965 by Lotfi
Zadeh, the theory of fuzzy sets was introduced as an extension to traditional set theory, and
the corresponding fuzzy logic was developed to manipulate the fuzzy sets.
1.5.1 Fuzzy Set Theory (Ross 1995)
Fuzzy sets are defined in a universe of discourse. For a given universe of discourse U, a fuzzy
set is determined by a membership function which maps members of U on to a membership
range in the interval [0,1]. Associated with a classical binary or crisp set is a characteristic
function which returns 1 if the element is a member of that set and 0 otherwise.
A fuzzy set F in a universe of discourse U is usually represented as a set of ordered pairs of
elements u and grade of membership value μ F ( u ) :
F={ (u, F(u))|uU } (1.2)
A fuzzy set F can be written as
𝐹 = ∫𝑈 F(u)/𝑢 for continuous U (1.3)
𝐹 = ∑𝑛𝑖=1 F(𝑢𝑖 )/𝑢𝑖 for discrete U (1.4)
13
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
Example 1.1
In the universe of discourse U = {2,3,4,5,6,7} , the fuzzy subset F labelled ‘integer close to
4’ may be defined as
F = 0. 33 / 2 + 0. 66 / 3 + 1. 0 / 4 + 0. 66 / 5 + 0. 33 / 6 + 0. 0 / 7
1.5.2 Support Set
The support set of a fuzzy set F is the crisp set of all points u in U such that μ F ( u ) > 0. A
fuzzy set whose support is a single point in U is referred to as a fuzzy singleton. The support
set is said to be compact if it is a strict subset of the universe of discourse.
1.5.3 Membership Functions
The membership for fuzzy sets can be defined numerically or as a function. A numerical
definition expresses the degree of membership function as a vector of numbers. A
functional definition defines the membership function in an analytic expression which
allows the membership grade for each element in the defined universe of discourse· to be
calculated. The membership functions which are often used include the triangular function,
the trapezoid function and the Gaussian function, as illustrated in Figure 1.13.
The triangular function is defined as follows:
0 𝑓𝑜𝑟 𝑢 < 𝑎
(𝑢 − 𝑎)/(𝑏 − 𝑎) 𝑓𝑜𝑟 𝑎 ≤ 𝑢 ≤ 𝑏
𝜇𝐹 (𝑢) = { (1.5)
(𝑐 − 𝑢)/(𝑐 − 𝑏) 𝑓𝑜𝑟 𝑏 ≤ 𝑢 ≤ 𝑐
0 𝑓𝑜𝑟 𝑢 > 𝑐
14
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
The trapezoid function is defined as follows:
0 𝑓𝑜𝑟 𝑢 < 𝑎
(𝑢 − 𝑎)/(𝑏 − 𝑎) 𝑓𝑜𝑟 𝑎 ≤ 𝑢 ≤ 𝑏
𝜇𝐹 (𝑢 ) = 1 𝑓𝑜𝑟 𝑏 ≤ 𝑢 ≤ 𝑐 (1.6)
(𝑑 − 𝑢)/(𝑑 − 𝑐) 𝑓𝑜𝑟 𝑐 ≤ 𝑢 ≤ 𝑑
{ 0 𝑓𝑜𝑟 𝑢 > 𝑑
The Gaussian function is defined as follows:
(𝑢−𝑐)2
−
𝜇𝐹 (𝑢) = 𝑒 2𝜎2 (1.7)
where the parameters are the centre c and the variance .
Figure 1.13 Some typical membership functions (Triangular, Trapezoid, Gaussian).
15
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
Example 1.2
A fuzzy subset F of U labelled “middle age” may be defined as
F={ (u, F(u))|uU }
Using a triangular membership function, the fuzzy subset F might be defined as
0 𝑓𝑜𝑟 𝑢 < 30
(𝑢 − 30)/15 𝑓𝑜𝑟 30 ≤ 𝑢 ≤ 45
𝜇𝐹 (𝑢) = {
(60 − 𝑢)/15 𝑓𝑜𝑟 45 ≤ 𝑢 ≤ 60
0 𝑓𝑜𝑟 𝑢 > 60
Figure 1.14 Fuzzy subset of “middle age” persons.
1.5.4 Fuzzy Set Operations
Let A and B be two fuzzy sets in U with membership functions A and B respectively. Some
basic fuzzy set operations are summarised as follows:
Equality A(u) = B(u), uU (1.8)
Union A B (u) =max{A(u), B(u)}, uU (1.9)
Intersection A B (u) =min{A(u), B(u)}, uU (1.10)
Complement A’ (u) = 1−A(u), uU (1.11)
Normalisation NORM(A) (u) = A(u)/max(A(u)), uU (1.12)
Concentration CON(A) (u) = (A(u))2, uU (1.13)
Dilation DIL(A) (u) = √(A(u)), uU (1.14)
16
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
Intensification 2(A(u))2 𝑓𝑜𝑟 0 ≤ A(u) ≤ 0.5
INT(A) (u) = { 2 𝑓𝑜𝑟 0.5 ≤ A(u) ≤ 1
1 − 2(1 − A(u)) (1.15)
Algebraic A • B (u) =A(u) • B(u), uU (1.16)
product
Bounded sum A B (u) = min{1,A(u) + B(u)}, uU (1.17)
Bounded A B (u) = max{0,A(u) + B(u)−1}, uU (1.18)
product
A(u) 𝑓𝑜𝑟 B(u) = 1
Drastic product A B (u)= {B(u) 𝑓𝑜𝑟 A(u) = 1 (1.19)
0 for A(u), B(u) < 1
Example 1.3
Let two fuzzy sets A and B be defined as follows:
A=0.1/1 + 0.3/2 + 0.7/3 + 1.0/4 + 0.6/5 + 0.2/6 + 0.1/7
B=0.2/1 + 0.8/2 + 1.0/3 + 0.6/4 + 0.4/5 + 0.3/6 + 0.1/7
Then
A’=0.9/1 + 0.7/2 + 0.3/3 + 0.0/4 + 0.4/5 + 0.8/6 + 0.9/7
A’ A =0.1/1 + 0.3/2 + 0.3/3 + 0.0/4 + 0.4/5 + 0.2/6 + 0.1/7
A’ A =0.9/1 + 0.7/2 + 0.7/3 + 1.0/4 + 0.6/5 + 0.8/6 + 0.9/7
A B =0.1/1 + 0.3/2 + 0.7/3 + 0.6/4 + 0.4/5 + 0.2/6 + 0.1/7
A B =0.2/1 + 0.8/2 + 1.0/3 + 1.0/4 + 0.6/5 + 0.3/6 + 0.1/7
17
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
1.5.5 Extension Principle
It is possible for elements u of one universe of discourse U to be mapped onto elements v of
another universe of discourse v through a function f. An extension principle developed by
Zadeh (1975) and later elaborated by Yager (1986) allows us to extend the domain of a function
on fuzzy sets.
Let f:u→v and define A to be a fuzzy set on the universe of discourse U and
A=1/u1+ 2/u2 +…+ n/un
then f(A)=1/f(u1)+ 2/ f(u2) +…+ n/ f(un) (1.20)
Example 1.4
If v=f(u)=2u−1 and A=0.6/1+1/2+0.8/3
then
f(A)=0.6/1+1/3+0.5/5 or V=0.6/1+1/3+0.5/5
1.5.6 Linguistic Hedges
One powerful aspect of fuzzy sets is the ability to deal with linguistic quantifiers or “hedges”.
Hedges such as very, more or less, not very, plus, etc. correspond to modifications in the
membership function as illustrated in Figure 1.15. Table 1.3 shows some fuzzy set operators
which can be used to represent some standard hedges. Note that the operator definition are not
unique and should be designed into appropriate forms before being used.
18
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
Figure 1.15 Fuzzy set modified by hedges.
Table 1.3 Hedges and corresponding operators
19
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
References
1. Brown, M., Harris, C. 1994, Neuro fuzzy Adaptive Modelling and Control,
Hertfordshire Prentice Hall.
2. Chai, R., Ling, S. H., San, P. P., Naik, G., Nguyen, N. T., Tran, Y., Craig, A., and
Nguyen, N. T. 2017, “Improving EEG-based driver fatigue classification using
sparse-deep belief networks,” Frontiers in Neuroscience, vol.11, Article103.
3. Ghevondian, N., Nguyen, H. T. 1997, ‘Low Power Portable Monitoring System of
Parameters for Hypoglycaemic Patients’, 19th Annual International Conference,
IEEE Engineering in Medicine and Biology Society, 30 October – 2 November 1997,
Chicago, USA, pp. 1029-1031.
4. Ghevondian, N., Nguyen, H. T. 1997, ‘Using Fuzzy Logic Reasoning for Monitoring
Hypoglycaemia in Diabetic Patients’, 19th Annual International Conference, IEEE
Engineering in Medicine and Biology Society, 30 October – 2 November 1997,
Chicago, USA, pp. 1108-1111.
5. Jamshidi, M., Vadiee, N., Ross, T. J. 1993, Fuzzy Logic and Control - Software and
Hardware Applications, Prentice Hall, New Jersey.
6. Joseph, T., Nguyen, H. T. 1998, ‘Neural Network Control of Wheelchairs using
Telemetric Head Movement’, 20th Annual International Conference, IEEE
Engineering in Medicine and Biology Society, 29 October – 1 November 1998, Hong
Kong, pp. 2731-2733.
7. Kosko, B. 1992, Neural Networks and Fuzzy Systems, Prentice Hall, New Jersey.
8. Ling, S. H., Nguyen, H. T. 2012, ‘Natural occurrence of nocturnal hypoglycaemia
detection using hybrid particle swarm optimized fuzzy reasoning model’, Artificial
Intelligence in Medicine, issue 55, pp. 177-184.
20
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
9. Ling, S. H., Leung, F. H. F., Lam, H. K., Tam, P. K. S. 2003, “Short-term electric load
forecasting based on a neural fuzzy network,” IEEE Trans. Industrial Electronics, vol.
50, no. 6, pp.1305–1316.
10. Ling, S. H., Iu, H. H. C., Leung, F. H. F., Chan K. Y. 2008, “Improved hybrid PSO-
based wavelet neural network for modelling the development of fluid dispensing for
electronic packaging,” IEEE Trans. Industrial Electronic, vol. 55, no. 9, pp. 3447–
3460, Sep. 2008.
11. Ling, S. H., Nguyen, H. T. 2011, “Genetic algorithm based multiple regression with
fuzzy inference system for detection of nocturnal hypoglycemic episodes,” IEEE Trans.
on Information Technology in Biomedicine, vol. 15, no. 2, pp. 308–315.
12. Ling, S. H., San, P. P., Chan K. Y., Leung, F. H. F., Liu, Y. 2014, “An intelligent
swarm based-wavelet neural network for affective mobile phone design,”
Neurocomputing, vol. 142, pp. 30-38.
13. Nguyen, H. T., Sands, D. M. 1995, ‘Self-Organising Fuzzy Logic Controller’, Control
95, The Institution of Engineers, Australia, 23-25 October 1995, Melbourne, vol 2, pp.
353-257.
14. Nguyen, H. T., King, L. M., Knight, G. 2004, ‘Real-Time Head Movement System
and Embedded Linux Implementation for the Control of Power Wheelchairs’, 26th
Annual International Conference of the IEEE Engineering in Medicine and Biology
Society, 1-5 September 2004, San Francisco, USA, pp. 4892-4895.
15. Nguyen, H. T., Nguyen, S. T., Taylor, P. B., Middleton J. 2007, ‘Head Direction
Command Classification using an Adaptive Optimal Bayesian Neural Network’,
International Journal of Factory Automation, Robotics and Soft Computing, Issue 3,
July 2007, pp. 98-103.
16. Smith, M. 1993, Neural Networks for Statistical Modelling. Van Nostrand Reinhold,
New York.
21
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
17. Ross T.J. 1995. Fuzzy Logic with Engineering Applications. McGraw-Hill.
18. Yan, J., Ryan, M., Power, J. 1994, Using Fuzzy Logic, Prentice Hall, Hertfordshire.
Zurada, J. M. 1992, Introduction to Artificial Neural Systems. West Publishing
Company, St. Paul.
22
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
CHAPTER TWO
FUNDAMENTAL CONCEPTS OF NEURAL NETWORKS
_______________________________________________________
Chapter 2.1 Neuron Modelling for Artificial Neural Systems
2.1.1 McCulloch-Pitts Neuron Model
The first formal definition of a synthetic neuron model was formulated by McCulloch and
Pitts (1943). The McCulloch-Fitts neuron model is shown in Figure 2.1. The firing rule for
this model is defined as follows
1 𝑖𝑓 ∑𝑛𝑖=1 𝑤𝑖 𝑥𝑖 ≥ 𝑇 1 𝑖𝑓 𝐰 ′ 𝐱 ≥ 𝑇
𝑧={ 𝑂𝑅 𝑧={ (2.1)
0 𝑖𝑓 ∑𝑛𝑖=1 𝑤𝑖 𝑥𝑖 < 𝑇 0 𝑖𝑓 𝐰 ′ 𝐱 < 𝑇
where w is the weight vector and x is the input vector.
𝑤1 𝑥1
𝐰 = [𝑤 𝑥
…2 ] and 𝐱 = [ …2 ]
𝑤𝑛 𝑥𝑛
Note that wi = +1 for excitatory synapses, wi = −1 for inhibitory synapses for this model, and
T is the neuron's threshold value.
Although this neuron model is very simplistic, it has substantial computing potential. It can
perform the basic logic operations NOT, OR, and AND, provided its weights and thresholds
are properly selected.
Figure 2.1 McCulloch-Pitts Neuron Model
23
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
Example 2.1
Example of three-input NOR gates using the McCulloch-Pitts neuron model is shown in
Figure 2.2. Verify the implemented functions by compiling a truth table for this logic gate.
Figure 2.2 NOR Gate
Solution 2.1
v1
y v2
x1 x2 x3 v1=w’x y v2 z
0 0 0 0 0 0 1
0 0 1 1 1 −1 0
0 1 0 1 1 −1 0
0 1 1 2 1 −1 0
1 0 0 1 1 −1 0
1 0 1 2 1 −1 0
1 1 0 2 1 −1 0
1 1 1 3 1 −1 0
24
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
Exercise 2.1
Example of three-input NAND gates using the McCulloch-Pitts neuron model is shown in
Figure 2.3. Verify the implemented functions by compiling a truth table for this logic gate.
Figure 2.3 NAND Gate
25
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
2.1.2 Perceptrons
The McCulloch-Pitts model is based on several simplications. It allows only binary states
(0,1) and operates under a discrete-time assumption with synchronisation of all neurons in a
larger network. Weights and thresholds in a neuron are fixed and no interaction among
network neurons takes place except for signal flow.
A general perceptron consists of a processing element with synaptic input connections and a
single input. Its symbolic representation described in Figure 2.4 shows a set of weights and
the neuron's processing unit (node). The neuron output signal is given by:
𝑣 = ∑𝑛𝑖=1 𝑤𝑖 𝑥𝑖 = 𝐰 ′ 𝐱 (2.2)
𝑧 = 𝑓(𝑣) (2.3)
Figure 2.4 Perceptron
The function z = f(v) is often referred to as an activation function. Note that temporarily,
the threshold value is not explicitly used for convenience. We have assumed that
the modelled neuron has (n-1) actual synaptic connections associated with actual
variable inputs x1 ,x2 ,...,xn-1. We have also assumed that the last synapse is an
inhibitory one with wn = −1.
26
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
Typical activations functions used are
Threshold logic unit (TLU)
+1, 𝑣 > 0
𝑧 = 𝑓0 (𝑣) = sgn(𝑣) = { (2.4)
−1, 𝑣 < 0
Figure 2.5 Threshold logic unit (TLU)
Logistic function
1
𝑓1 (𝑣 ) = (2.5)
1+𝑒 −𝑣
𝑧 = 𝑓1 (v)
( )
= 𝑧(1 − 𝑧)
Figure 2.6 Logistic function
27
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
Bipolar logistic function
2 1−𝑒 −𝑣
𝑓2 (𝑣) = − 1 = 1+𝑒 −𝑣 = 2𝑓1 (𝑣) − 1 (2.6)
1+𝑒 −𝑣
𝑧= 𝟐( )
( 𝟐( ))
= 0.5(1 − 𝑧 2 )
Figure 2.7 Bipolar logistic function
Hyperbolic bipolar logistic function
1−𝑒 −2𝑣
𝑓3 (𝑣) = tanh(𝑣) = 1+𝑒 −2𝑣 = 2𝑓1 (2𝑣) − 1 (2.7)
𝑧= 𝟑( )
( 𝟑( ))
= 1 − tanh2 (z)
Figure 2.8 Hyperbolic bipolar logistic function
The soft-limiting activation functions f1(v), f2(v), f3(v) are often called sigmoidal
characteristics, as opposed to the hard-limiting activation function f0(v). A perceptron with
the activation function f0(v) describes the discrete perceptron shown in Figure 2.9. It was the
first learning machine introduced by Rosenbratt in 1958.
28
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
Figure 2.9 Discrete Perceptron
Example 2.2
Prove that if the logistic function z(v) = f1(v) is used as an activation function, then the
derivative of z(v) is given by:
𝑑𝑧
= 𝑧(1 − 𝑧) (2.8a)
𝑑𝑣
Solution 2.2
1 𝑒𝑣
𝑧(𝑣) = 𝑓1 (𝑣) = =
1 + 𝑒 −𝑣 𝑒 𝑣 + 1
𝑑𝑧 𝑒 𝑣 (𝑒 𝑣 + 1) − 𝑒 𝑣 (𝑒 𝑣 ) 𝑒𝑣 (𝑒 𝑣 )2
= = −
𝑑𝑣 (𝑒 𝑣 + 1)2 𝑒𝑣 + 1 (𝑒 𝑣 + 1)2
2
𝑒𝑣 𝑒𝑣
= 𝑣 −( 𝑣 ) = 𝑧 − 𝑧 2 = 𝑧(1 − 𝑧)
𝑒 +1 𝑒 +1
Example 2.3
If the bipolar logistic function z(v) = f2(v) is used as an activation function, then the
derivative of z(v) is given by:
𝑑𝑧
= 0.5(1 − 𝑧2 ) (2.8b)
𝑑𝑣
Solution 2.3
2 2𝑒 𝑣 𝑒 𝑣 −1
𝑧(𝑣) = 𝑓2 (𝑣) = − 1 = 𝑒 𝑣+1 − 1 =
1+𝑒 −𝑣 𝑒 𝑣 +1
𝑑𝑧 𝑒 𝑣 (𝑒 𝑣 + 1) − (𝑒 𝑣 − 1)𝑒 𝑣 2𝑒 𝑣
= =
𝑑𝑣 (𝑒 𝑣 + 1)2 (𝑒 𝑣 + 1)2
2𝑒 𝑣 1 (1 − 𝑧)
= 𝑣
× 𝑣 = (𝑧 + 1) = 0.5(1 − 𝑧 2 )
𝑒 +1 𝑒 +1 2
29
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
Chapter 2.2 Basic Network Architectures
The neural network can be defined as an interconnection of neurons such that neuron
outputs are connected, through weights, to all other neurons including themselves with
both lag-free and delay connections allowed.
2.2.1 Feedforward Network
An elementary feedforward architecture of m neurons receiving n inputs is shown in Figure
2.10.
Figure 2.10 Single-layer feedforward network: (a) interconnection scheme
and (b) block diagram.
The mapping of the input vector x to the output vector z can be represented by
v = Wx
(2.9)
z = (v)
where W is the weight matrix (connection matrix) and
𝑥1 𝑣1 𝑧1
𝐱 = [ 𝑥…2 ] , 𝐯 = [ 𝑣…2 ] , 𝒛 = [ 𝑧…2 ]
𝑥𝑛 𝑣𝑚 𝑧𝑚
𝑤11 ⋯ 𝑤1𝑛 𝑣1
𝐖=[ ⋮ ⋱ ⋮ ], (v) = [𝑣…2 ] where () is an activation function.
𝑤𝑚1 ⋯ 𝑤𝑚𝑛 𝑣 𝑛
30
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
2.2.2 Recurrent Network
A recurrent network can be obtained from the feedforward network by connecting the
outputs of the neurons to their inputs as shown in Figure 2.11.
Figure 2.11 Single-layer discrete-time recurrent network: (a) interconnection scheme
and (b) block diagram.
In the above recurrent network, the time elapsed between t and t + . is introduced by
the delay elements in the feedback loop. This time delay is analogous to the refractory
period of an elementary biological neuron model.
The mapping of the input vector x to the output vector z can be represented by
𝐯(𝑡 + Δ) = 𝐖𝐱(𝑡)
𝐳(𝑡 + Δ) = 𝐯(𝑡 + Δ) (2.10)
For a discrete-time artificial neural system
𝐯(𝑘 + 1) = 𝐖𝐱(𝑘)
𝐳(𝑡 + 1) = 𝐯(𝑡 + 1) (2.11)
Recurrent networks typically operate with a discrete representation of data. They often
use neurons with a hard-limiting activation function. A system with discrete-time inputs
and a discrete data representation is called an automaton.
31
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
Chapter 2.3 Learning Rules
2.3.1 Supervised and Unsupervised Learning
There are two different types of learning: supervised learning and unsupervised learning. In
supervised learning, the desired response d is provided by the trainer. The distance
[d,z]between the actual and the desired response serves as an error measure and is used to
correct the network parameters. The error can be used to modify weights so that the error
decreases. For this learning mode, a set of input and output patterns (training set) is required.
In unsupervised learning, the desired response d is not known. Since no information is
available regarding to the correctness of responses, learning must be based on
observations of responses to inputs that we have some knowledge about. In this mode of
learning, the network must discover by itself any possible patterns, regularities, and
separating properties. While discovering these, the network updates its parameters using a
self-organising process.
2.3.2 The General Learning Rule
The general learning rule for neural network studies is: The weight Wi increases in
proportion to the product of input x and learning signal ri . The learning signal ri is in
general a function of Wi , x , and sometimes of the training signal d.
ri = ri(wi, x, d) (2.12)
The increment of the weight vector according to the general learning rule is
wi (k+1)=wi (k)+wi (k) (2.13)
where
wi (k) = c ri(k) x(k) (2.14)
c>0 is called learning constant (learning rate)
ri is the learning signal and
ri(k) = ri( wi (k), x(k), d(k)) (2.15)
The illustration for general weight learning rules is given in Figure 2.12.
32
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
Figure 2.12 Illustration for weight learning rule.
2.3.3 Hebbian Learning Rule
The Hebbian learning rule (1949) represents a purely feedforward, unsupervised learning.
The learning signal r is equal simply to the output of the neuron.
ri(k) = zi(k) = f (wi’ (k) x(k)) (2.16)
wi (k+1) = wi (k)+wi (k)
where wi (k) = cri(k)xi (k)
This learning rule requires the weight initialisation at small random values around wi = 0
prior to learning.
33
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
Exercise 2.2
Assume that the network shown in Figure 2.9 with the initial weight vector w(1) needs to be
trained using the set of three input vectors x(1), x(2), x(3) as below
1 1 0 1
−2
𝐱(1) = [ ], 𝐱(2) = [ −0.5 1 −1
] , 𝐱(3) = [ ] , and 𝐰(1) = [ ]
1.5 −2 −1 0
0 −1.5 1.5 0.5
If the activation function of this perceptron is the logistic function f1(v), the learning
constant is c = 1, and the Hebbian learning rule is used, show that the weight vectors after
subsequent training steps are:
1.9526 2.4021 2.4021
w(2)= [ −2.9052 ], w(3)= [ −3.1299 ], w(4)= [ −3.1105 ]
1.4289 0.5298 0.5104
0.5 −0.1743 −0.1452
2.3.4 Discrete Perceptron Learning Rule
The discrete perceptron learning rule (1958) is of supervised type as shown in Figure 2.13. The
learning signal r is the error between the desired and actual response of the neuron.
ri(k) = ei(k) = di(k) − zi(k) = di(k) − f( wi’ (k) x(k)) (2.17)
wi (k+1)=wi (k)+cri(k)xi (k)
The weight adjustment is inherent zero when the desired and actual responses agree. The
weights are initialised at any values.
Figure 2.13 Discrete perceptron learning rule.
34
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
Exercise 2.3
Assume that the network shown in Figure 2.9 with the initial weight vector w(1) needs to be
trained using the set of three input vectors x(1), x(2), x(3) as below
1 0 −1 1
𝐱(1) = [−2], 𝐱(2) = [ 1.5 ] , 𝐱(3) = [ 1 ] , and 𝐰(1) = [−1]
0 −0.5 0.5 0
−1 −1 −1 0.5
The trainer’s desired responses for x(1), x(2), x(3) are d(1)=−1, d(2)= −1, d(3)=1 respectively.
If the learning constant is c=0.1, and the discrete perceptron learning rule is used, show that
the weight vectors after subsequent training steps are:
0.8 0.8 0.6
w (2) = [ −0.6], w (3) = [ −0.6 −0.4
], w (4) = [ 0.1 ]
0 0
0.7 0.7 0.5
2.3.5 Delta Learning Rule
The delta learning rule is only valid for continuous activation function and in the supervised
learning mode. This learning rule can be readily derived from the condition of least squared
error between the output and the desired response.
vi = wi’ x
1 1 1 2
𝐸 = 𝑒𝑖 2 = (𝑑𝑖 − 𝑧𝑖 )2 = (𝑑𝑖 − 𝑓(𝑣𝑖 )) (2.18)
2 2 2
The error gradient vector is
𝜕𝐸 𝜕𝐸 𝜕𝑧𝑖 𝜕𝑓 𝜕𝑓 𝑣𝑖
𝛻𝐸 = = = −(𝑑𝑖 − 𝑧𝑖 ) = −(𝑑𝑖 − 𝑧𝑖 ) (2.19)
𝜕𝑤𝑖 𝜕𝑧𝑖 𝜕𝑤𝑖 𝜕𝑤𝑖 𝜕𝑣𝑖 𝜕𝑤𝑖
𝜕𝑓
𝛻𝐸 = −(𝑑𝑖 − 𝑧𝑖 ) 𝐱
𝜕𝑣𝑖
35
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
Since the minimisation of the error requires the weight changes to be in the negative gradient
direction, we take
∆𝐰𝑖 = − 𝛻𝐸 (2.20)
where is a positive constant (learning rate).
Using the general learning rule (2.14), it can be seen that the learning constant c and the
learning rate are equivalent. The weights are initialised at any values and the learning
signal r can be found from
𝜕𝑓(𝑣(𝑘))
𝑟𝑖 (𝑘) = 𝑒𝑖 (𝑘) = 𝑒𝑖 (𝑘)𝑓 ′ (𝑣(𝑘)) = (𝑑𝑖 (𝑘) − 𝑧𝑖 (𝑘))𝑓 ′ (𝑣(𝑘)) (2.21)
𝜕𝑣(𝑘)
wi (k+1)=wi (k)+cri(k)xi (k)
Exercise 2.4
Again, assume that the network shown in Figure 2.9 with the initial weight vector w(1)
needs to be trained using the set of three input vectors x(1), x(2), x(3) as below
1 0 −1 1
−2
𝐱(1) = [ ], 𝐱(2) = [ 1.5 1 −1
] , 𝐱(3) = [ ] , 𝑎𝑛𝑑 𝐰(1) = [ ]
0 −0.5 0.5 0
−1 −1 −1 0.5
The trainer’s desired responses for x(1), x(2), x(3) are d(1) = −1, d(2)= −1, d(3)=1
respectively. If the activation function of this perception is the bipolar logistic function f2 (v),
the learning constant is c = 0.1, and the delta learning rule is used, show that the weight
vectors after subsequent training steps are:
0.974 0.974 0.947
𝐰(2) = [ −0.948 ], 𝐰(3) = [ −0.956 ], 𝐰(4) = [ −0.929 ]
0 0.002 0.016
0.526 0.531 0.504
36
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
2.3.6 Widrow-Hoff Learning Rule
The Widrow-Hoff learning rule (1962) is applicable for the supervised training of neural
networks. It is independent of the activation function of neurons. The learning signal r is the
error between the desired output value d and the activation value of the neuron v.
𝑟𝑖 (𝑘) = 𝑑𝑖 (𝑘) − 𝑣𝑖 (𝑘) = 𝑑𝑖 (𝑘) − 𝐰 ′ (𝑘)𝐱(𝑘) (2.22)
wi (k+1)=wi (k)+cri(k)xi (k)
This rule can be considered as a special case of the delta rule. Assuming that
𝑣𝑖 = 𝐰 ′ (𝑘)𝐱(𝑘), 𝑓(𝑣𝑖 ) = 𝑣𝑖 , 𝑓 ′ (𝑣𝑖 ) = 1. This rule is sometimes called the LMS (least mean
square) learning rule. The weights are initialised at any value.
Exercise 2.5
Again, assume that the network shown in Figure 2.9 with the initial weight vector w(1)
needs to be trained using the set of three input vectors x(1), x(2), x(3) as below
1 0 −1 1
𝐱(1) = [−2], 𝐱(2) = [ 1.5 ] , 𝐱(3) = [ 1 ] , 𝑎𝑛𝑑 𝐰(1) = [−1]
0 −0.5 0.5 0
−1 −1 −1 0.5
The trainer’s desired responses for x(1), x(2), x(3) are d(1) = −1, d(2)= −1, d(3)=1
respectively. If the activation function of this perception is the bipolar logistic function f2 (v),
the learning constant is c = 0.1, and the Widrow-Hoff learning rule is used, show that the
weight vectors after subsequent training steps are:
0.65 0.65 0.3767
𝐰(2) = [−0.30], 𝐰(3) = [−0.255] , 𝐰(4) = [0.0183]
0 −0.015 0.1216
0.85 0.82 0.5468
37
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
2.3.7 Summary of learning rule and their properties
References
Brown, M., Harris C. 1994. Neurofuzzy Adaptive Modelling and Control.
Hertfordshire: Prentice Hall.
Kosko B. 1992. Neural Networks and Fuzzy Systems. New Jersey: Prentice Hall.
Hertz J., Krogh A., Palmer R. G. 1991. Introduction to the Theoary of Neural
Computing.Redwood City, California: Addison-Wesley.
Smith M. 1993. Neural Networks for Statistical Modelling. New York: Van Nostrand
Reinhold
Zurada, J.M. 1992. Introduction to Artificial Neural Systems. St. Paul: West
Publishing Company.
38
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
CHAPTER THREE
FUNDAMENTAL CONCEPTS OF FUZZY LOGIC AND
FUZZY CONTROLLER
_______________________________________________________
Chapter 3.1 Fundamental concepts of fuzzy logic
3.1.1 Fuzzy Relations
A fuzzy relation maps elements of one universe to one of another universe through the
Cartesian product of the two universes. The strength of the relation between ordered pairs of
the two universes is measured with the membership function expressing various degrees of
strength of the relation on the unit interval [0,1].
Fuzzy Cartesian Product
If A1, A2, …An are fuzzy sets in U1, U2, … Un respectively, the Cartesian product of A1,
A2,…, An is a fuzzy set F in the product space U1U2 … Un with the membership function:
F(u1, u2, …, un)=min[A1(u1), A2(u2), …An(un)] (3.1)
where F= A1 A2 … An
Fuzzy Relation
An n-ary fuzzy relation is a fuzzy set in U1U2 … Un and expressed as:
RU ={((u1, u2, …, un), R(u1, u2, …, un))|(u1, u2, …, un)U} (3.2)
where U1U2 … Un
39
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
Example 3.1
Let A be a fuzzy set defined on a universe of three discrete temperatures, T={t1, t2, t3}, and B
be a fuzzy set defined on a universe of two discrete pressure P={p1, p2}. Fuzzy set A
represents the “ambient” temperature and fuzzy set B represents the “near optimum” pressure
for a certain heat exchanger, and the Cartesian product might represent the conditions
(temperature-pressure pairs) of the exchanger that are associated with “efficient” operations.
Let
T=0.1/t1 + 0.6/t2 + 1/t3
P=0.4/p1 + 0.8/p2
If R is the fuzzy relation in T P
0.1 0.1
R=TP = [0.4 0.6]
0.4 0.8
3.1.2 Composition of Fuzzy Relations
If P and Q are fuzzy relations in UV and V W respectively.
By using max-min composition, P and Q is a fuzzy relation denoted by:
P ∘ Q={|(u,w), max[min[P(u, v), Q(v, w)]] | (uU, vV, wW} (3.3)
By using max-product composition, P and Q is a fuzzy relation denoted by:
P ∘ Q={|(u,w), max[P(u, v) • Q(v, w)] | (uU, vV, wW} (3.4)
40
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
Example 3.2
In the armature control of a DC motor, suppose that the membership functions for both
armature resistance Ra (ohms), armature Ia (A), and motor speed N (rpm) are given in their
per unit values:
0.3 0.7 1.0 0.2
𝑅𝑎 = { + + + }
30 60 100 120
0.2 0.4 0.6 0.8 1.0 0.1
𝐼𝑎 = { + + + + + }
20 40 60 80 100 120
0.33 0.67 1.0 0.15
𝑁={ + + + }
500 1000 1500 1800
The fuzzy relation between armature resistance and armature current P= Ra Ia, and the fuzzy
relation between armature current and motor speed Q= Ia N can be calculated
0.2 0.2 0.2 0.15
0.2 0.3 0.3 0.3 0.3 0.1 0.33 0.4 0.4 0.15
0.33 0.6 0.6 0.15
𝐏 = [0.2 0.4 0.6 0.7 0.7 0.1 ] 𝐐=
0.2 0.4 0.6 0.8 1.0 0.1 0.33 0.67 0.8 0.15
0.2 0.2 0.2 0.2 0.2 0.1 0.33 0.67 1.0 0.15
[ 0.1 0.1 0.1 0.1 ]
Using the max-min compositional operations, a relation P ∘ Q can be calculated to related
armature resistance to motor speed
0.3 0.3 0.3 0.15
𝐓 = 𝐏 ∘ 𝐐 = [0.33 0.67 0.7 0.15 ]
0.33 0.67 1.0 0.15
0.2 0.2 0.2 0.15
41
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
Chapter 3.2 Fuzzy Logic Control System
In control system design, a PID controller is effective for a fixed control environment. In
order to cope with varying control environment or system non-linearity, an adaptive controller,
a self-tuning PID controller, a H ∞ controller or a sliding mode controller may be used. The
design of these controllers needs a mathematical model of the process in order to formulate
the input-output relation. Such models can be very difficult or very time consuming to be
identified.
In the fuzzy-logic-based approach, the inputs, outputs and control response are specified in
terms similar to those that might be used by an expert. Complex mathematical models of the
system under control are not required. Essentially, complicated knowledge based on the
experience of an expert can be incorporated in the fuzzy system in a relatively simple
way. Usually, this knowledge is expressed in the forms of rules.
Fuzzy logic and its applications in control engineering can be considered as the most important
area in fuzzy set theory and its applications. Since the invention of the first fuzzy controller by
Mamdani in 1974, fuzzy logic controllers (FLCs) have been successfully applied in numerous
industrial applications such as cement-kiln process control, automatic train operation,
camcorder autofocussing, crane control, etc
A fuzzy logic controller (FLC) can be typically incorporated in a closed loop control system as
shown in Figure 3.1. The main elements of the FLC are a fuzzification unit, an inference engine
with a knowledge base, and a defuzzification unit.
Figure 3.1 A fuzzy logic control system
42
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
3.2.1 System Variables
When a FLC is designed to replace a conventional PD controller, the input variables of the
FLC are error (e) and change of error (ce). The output variable of the FLC is a control signal
u.
The fuzzy set for each system variable are defined in typical linguistic terms such as
PVB Positive Very Big
PB Positive Big
PM Positive Medium
PS Positive Small ZE
Zero
NS Negative Small
NM Negative Medium
NB Negative Big
NVB Negative Very Big
There are two ways to define the membership for a fuzzy set: numerical or functional. A
numerical definition expresses the degree of membership function of a fuzzy set as a vector
of numbers whose dimension depends on the level of discretisation in the universe of discourse.
A functional definition denotes the membership function of a fuzzy set in a functional form
such as the triangular function or a Gaussian function.
Figure 3.2 show typical fuzzy sets and membership functions of system variables error
e ,change of error ce, and controller output (plant input) u in numerical form. A functional
form membership for a fuzz set is shown in Figure 3.3.
Figure 3.2 Membership functions in numerical form
43
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
Triangular membership functions Gaussian membership functions
Figure 3.3 Membership functions in functional form
3.2.2 Fuzzification
Fuzzification is the process of mapping from observed inputs to fuzzy sets in the various input
universes of discourse. In process control, the observed data is usually crisp, and fuzzification
is required to map the observed range of crisp inputs to corresponding fuzzy values for the
system input variables. The mapped data are further converted into suitable linguistic terms
as labels of the fuzzy sets defined for system input variables. This process can be expressed
by:
X = fuzzifier (x) (3.5)
44
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
Example 3.3
Assume that the range of “error” is [-5V, 5V] and the fuzzy set “error” has 9 members [NVB,
NB, NM, NS, ZE, PS, PM. PB, PVB] with triangular membership functions shown in Figure
3.4.
Figure 3.4 Fuzzification
Show that if
e = 2.25V
then
E = {0.75/ PM +0.25/ PB}
3.2.3 Fuzzy Control Rules and Rule Base
In a FLC, knowledge of the application domain and the control objectives is formulated
subjectively in most applications, based on an expert's experience. However, an
“objective” knowledge base may be constructed in a learning/self-organising environment by
using fuzzy modelling techniques.
The knowledge base consists of a data base and a rule base. The data base provides the
necessary definitions of the fuzzy parameters as fuzzy sets with membership functions defined
on the universe of discourse for each variable. The rule base consists of fuzzy control rules
intended to achieve the control objectives.
45
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
Fuzzy Inference Rules
A fuzzy rule, often expressed in the form
IF (antecedent) THEN (consequent) (3.6)
e.g. If (x is A) AND (y is B) THEN (z is C)
is essentially a fuzzy relation or a fuzzy implication.
There are two main types of fuzzy inference rules in fuzzy logic reasoning: generalised modus
ponens (GMP) and generalised modus tollens (GMT). GMP is widely used in fuzzy logic
control applications and GMT is commonly used in expert systems, especially medical
diagnosis applications.
Generalised Modus Ponens (GMP) - Direct Reasoning
Premise 1 (Knowledge) : IF x is A then y is B
Premise 2 (Fact) : x is A’
Consequence (Conclusion) : y is B’
Generalised Modus Tollens (GMTP) - Indirect Reasoning
Premise 1 (Knowledge) : IF x is A then y is B
Premise 2 (Fact) : y is B’
Consequence (Conclusion) : x is A’
Fuzzy Knowledge Base
A fuzzy knowledge base consists of a number of fuzzy rules. In most engineering
control applications, the fuzzy rules are expressed as
IF (x is A) AND (y is B) THEN (z is C) (3.7)
46
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
There are several sentence connectives such as AND, OR, and ALSO. The connectives AND
and OR are often used in the antecedent part, while connective ALSO is usually used in the
consequent part of fuzzy rules.
A fuzzy control algorithm should always be able to infer a proper control action for any input
in the universe of discourse. This property is referred to as 'completeness'. If the number of
fuzzy sets, or 'predicates', for each input variable is denoted by m and the number of system
input variables by n , then mn different rules are required for a completeness in the
conventional expert system approach. For example, if the number of fuzzy sets per system
input variable m is 7 and the number of input variables n is 3, then 73 = 343 rules are required.
In contrast with a conventional expert system, a FLC rule base typically only uses a small
number of rules to attain completeness in its behaviour. It has been found that the number of
control rules in a FLC can be remarkably reduced primarily due to the overlap of the fuzzy
sets and the soft matching approach used in fuzzy inference.
47
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
Example 3.4
Fuzzy logic is used to control a two-axis mirror gimbal for aligning a laser beam using a
quadrant detector. Electronics sense the error in the position of the beam relative to the centre
of the detector and produces two signals representing the x and y direction errors. The
controller processes the error information using fuzzy logic and provides appropriate control
voltages to run the motors which reposition the beam.
To represent the error input to the controller, a set of linguistic variables is chosen to represent
5 degrees of error, 3 degrees of change of error, and 5 degrees of armature voltage.
Membership functions are constructed to represent the input and output values' grades of
membership as shown in Figure 3.5.
Figure 3.5 Membership functions of a laser beam alignment system
Two sets of rules are chosen. These "Fuzzy Associative Memories" or FAMs, are a shorthand
matrix notation for presenting the rule set. A linguistic armature voltage rule is fired for each
pair of linguistic error variables and linguistic change in error variables.
A set of "pruned" rules is also used to investigate the effect of reducing the processed
information on the behaviour of the controller. When pruned, the FAM is slightly modified
to incorporate all the rules. The effect on the system response by modifying the FAM bank is
more dramatic than modifying the membership functions. Changing the FAM "coarsely" tunes
the response while adjusting the membership functions "finely" tunes the response. The FAMs
48
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
are shown in Table 3.1. Table 3.l (a) shows the full set of 15 fuzzy rules and Table 3.l (b)
shows the rule base fuzzy set after pruning.
Table 3.1 Fuzzy Associative Memories
(a) (b)
3.2.4 Reasoning Techniques
There are various ways in which the observed input values can be used to identify which
rules should be used and to infer an appropriate fuzzy control action. Among the various
fuzzy inference methods, the following are the most commonly used in industrial FLCs.
1. The point-valued MAX-MIN fuzzy inference method
2. The point-valued MAX-PRODUCT (or MAX-DOT) fuzzy inference method
Due to the nature of industrial process control, it is often the case that the input data are crisp.
Fuzzification typically involves treating these as fuzzy singletons, which are then used with a
fuzzy inference method. Assume that the fuzzy control rule base has only two rules:
Rule 1: IF x is A1 and y is B1 THEN z is C1
Rule2: IF x is A2 and y is B2 THEN z is C2
Let the fire strength of the ith rule be denoted by i;. For inputs x0 and y0 , the fire strength
1 and 2 can be calculated from
1=A1(x0) B1(y0)
2=A2(x0) B2(y0) (3.7)
49
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
MAX-MIN Fuzzy Reasoning
In MAX-MIN fuzzy reasoning, Mamdani's minimum operation rule Rc is used for fuzzy
implication. The membership of the inferred consequence C is point-wise given by
𝜇𝑐 (𝑧) = ⋁𝑛𝑖=1 (𝛼𝑖 ∧ 𝜇𝑐1 (𝑦)) (3.8)
Figure 3.6 shows the MAX-MIN inference process for the crisp input values x0 and y0 which
have been regarded as fuzzy singletons.
Figure 3.6 MAX-MIN inference
MAX-PRODUCT Fuzzy Reasoning
In MAX-PRODUCT fuzzy reasoning, Larsen's product operation rule RP is used for
fuzzy implication. The membership of the inferred consequence C is point-wise given by
𝜇𝑐 (𝑧) = ⋁𝑛𝑖=1 (𝛼𝑖 ⋅ 𝜇𝑐1 (𝑦)) (3.9)
Figure 3.7 shows the MAX- PRODUCT inference process for the crisp input values x0 and
y0.
Figure 3.7 MAX-PRODUCT fuzzy inference
50
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
3.2.5 Defuzzification
Defuzzification is the process of mapping from a space of inferred fuzzy control actions to a
space of non-fuzzy (crisp) control actions. A defuzzification strategy is aimed at producing
a non-fuzzy control action that best represents the possibility distribution of the inferred
fuzzy control action. This can be expressed by:
u = defuzzifter(U) (3.10)
In real-time implementation of fuzzy logic control, the commonly used defuzzification
strategies are the mean of maximum (MOM) and the centre of area (COA).
Mean of Maximum (MOM) Method
The MOM strategy (height defuzzification) generates a control action which represents the
mean value of all local control actions whose membership functions reach the maximum.
Let the number of rules be denoted by n, the maximum height of the membership function of
the fuzzy set defined for the output control (consequent) of the i-th rule by the crisp value Hi,
the corresponding crisp control value along the output universe of discourse by Ui and the fire
strength from the i-th rule by i. Then the crisp control value u* defuzzified using the MOM
method is given by:
∑𝑛
𝑖=1 𝛼𝑖 𝐻𝑖 𝑈𝑖
𝑢∗ = ∑𝑛
(3.11)
𝑖=1 𝛼𝑖 𝐻𝑖
The crisp value Ui is a support value at which the membership function reaches
maximum Hi (most often Hi = 1). In addition, although the fire strength from the i-th rule i
is normally calculated as described in Equation 3.7, a more effective method for calculating
the fire strength in a MOM method is
i = Ai(xi)• Bi(yi). (3.12)
Assuming Hi = 1,
∑𝑛
𝑖=1 𝛼𝑖 𝑈𝑖
𝑢∗ = ∑𝑛
(3.13)
𝑖=1 𝛼𝑖
51
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
Centre of Area (COA) Method
The COA strategy generates the centre of gravity of the possibility distribution of a control
action.
Let the number of rules be denoted by n, the amount of control output of the i-th rule ui, and
its corresponding membership value in the output fuzzy set C 𝜇𝐶 (𝑢𝑖 ). Then the crisp control
value u* defuzzified using the COA method is given by:
∑𝑛
𝑖=1 𝜇𝐶 (𝑢𝑖 )𝑢𝑖
𝑢∗ = ∑𝑛
(3.14)
𝑖=1 𝜇𝐶 (𝑢𝑖 )
If the universe of discourse is continuous, then the COA strategy generates an output control
action of
∫ 𝜇𝐶 (𝑢)𝑢𝑑𝑢
𝑢∗ = (3.15)
∫ 𝜇𝐶 (𝑢)𝑑𝑢
52
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
Example 3.5
In a control system, the membership functions of system variables error e , change of error
ce, and controller output (plant input) u are shown Figure 3.8.
Assume that the fuzzy rules are represented by a FAM Table (Table 3.2), and the current
values of error e and change of error ce are {e = 1.5, ce = −0.05}. Assume also that the ranges
of error, change of error, and controller output are [−3,3], [−1,1], and [−6,6] respectively.
error e
change of error ce
Controller output u
Figure 3.8 Membership functions of a control system
Table 3.2 FAM Table
Change of Error (CE)
N ZE P
N N N ZE
Error (E)
ZE N ZE P
P ZE P P
53
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
Solution 3.5
Step 1: Fuzzification
The current values of error e and change of error ce are {e = 1.5, ce = −0.05}
In fuzzy notation:
E1.5=0.25/ZE+0.75/P
CE-0.05=0.1/N+0.9/ZE
Step 2: Reasoning
E CE U (MOM) U(COA)
Rule 1 0.25/ZE 0.1/N 0.025/N 0.1/N
Rule 2 0.25/ZE 0.9/ZE 0.225/ZE 0.25/ZE
Rule 3 0.75/P 0.1/N 0.075/ZE 0.1/ZE
Rule 4 0.75/P 0.9/ZE 0.675/P 0.75/P
Step 3: Defuzzification
According to the MOM method, the output 𝑢∗ can be found using
∑𝑛𝑖=1 𝛼𝑖 𝑈𝑖 0.025(−4) + 0.225(0) + 0.075(0) + 0.675(4)
𝑢∗ = = = 2.6
∑𝑛𝑖=1 𝛼𝑖 0.025 + 0.225 + 0.075 + 0.675
According to the COA method, the output u* can be found using the max-min inference
process as shown in below
∫ 𝜇𝐶 (𝑢)𝑢𝑑𝑢
𝑢∗ =
∫ 𝜇𝐶 (𝑢)𝑑𝑢
−3.6 −3 1 3 6
∫−6 0.1𝑢𝑑𝑢 + ∫−3.6(0.25𝑢 + 1)𝑢𝑑𝑢 + ∫−3 0.25𝑢𝑑𝑢 + ∫1 (0.25𝑢)𝑢𝑑𝑢 + ∫3 0.75𝑢𝑑𝑢
= 6 −3.6 1 3 6
∫−3.6 0.1𝑑𝑢 ∫−3 (0.25𝑢 + 1)𝑑𝑢 + ∫−3 0.25𝑑𝑢 + ∫1 (0.25𝑢) 𝑑𝑢 + ∫3 0.75𝑑𝑢
54
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
−3.6 −3 1 3 6
𝑢2 𝑢3 𝑢2 𝑢2 𝑢3 𝑢2
(0.1 2 ) + (0.25 3 + 2 ) + (0.25 2 ) + (0.25 3 ) + (0.75 2 )
−6 −3.6 −3 1 3
= −3 3
𝑢2 𝑢2
(0.1𝑢)−3.6
−6 + (0.25 + 𝑢) + (0.25𝑢)1−3 + (0.25 ) + (0.75𝑢)63
2 −3.6
2 1
−1.152 − 0.342 − 1 + 2.1667 + 10.125 9.7977
= = = 2.1323
0.24 + 0.105 + 1 + 1 + 2.25 4.595
Figure 3.9 Max-Min Inference Process
55
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
Chapter 3.3 Closed Loop Fuzzy Logic Control
A control system for a physical system is an arrangement of hardware components designed
to alter, to regulate, or to command, through a control action, another physical system so that
it exhibits certain desired characteristics or behavior. Physical control systems are typically of
two types: open-loop control systems, in which the control action is independent of the physical
system output, and closed-loop control systems (also known as feedback control systems), in
which the control action depends on the physical system output. Examples of open-loop control
systems are a toaster, in which the amount of heat is set by a human, and an automatic washing
machine, in which the controls for water temperature, spin-cycle time, and so on are preset by
a human. In both these cases, the control actions are not a function of the output of the toaster
or the washing machine. Examples of feedback control are a room temperature thermostat,
which senses room temperature and activates a heating or cooling unit when a certain threshold
temperature is reached, and an autopilot mechanism, which makes automatic course
corrections to an aircraft when heading or altitude deviations from certain preset values are
sensed by the instruments in the plane’s cockpit.
To control any physical variable, we must first measure it. The system for measurement of the
controlled signal is called a sensor. The physical system under control is called a plant. In a
closed-loop control system, certain forcing signals of the system (the inputs) are determined
by the responses of the system (the outputs). To obtain satisfactory responses and
characteristics for the closed-loop control system, it is necessary to connect an additional
system, known as a compensator, or a controller, to the loop. The general form of a closed-
loop control system is illustrated in Figure 3.10. The control problem is stated as follows. The
output, or response, of the physical system under control (i.e., the plant) is adjusted as required
by the error signal. The error signal is the difference between the actual response of the plant,
as measured by the sensor system, and the desired response, as specified by a reference input.
56
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
Figure 3.10 A closed-loop control system
First-generation (nonadaptive) simple fuzzy controllers can generally be depicted by a block
diagram such as that shown in Figure 3.11.
Figure 3.11 A simple fuzzy logic control system block diagram
The knowledge-base module in Figure 3.11 contains knowledge about all the input and output
fuzzy partitions. It will include the term set and the corresponding membership functions
defining the input variables to the fuzzy rule-base system and the output variables, or control
actions, to the plant under control.
The steps in designing a simple fuzzy control system are as follows:
1. Identify the variables (inputs, states, and outputs) of the plant.
2. Partition the universe of discourse or the interval spanned by each variable into a
number of fuzzy subsets, assigning each a linguistic label (subsets include all the
elements in the universe).
3. Assign or determine a membership function for each fuzzy subset.
4. Assign the fuzzy relationships between the inputs’ or states’ fuzzy subsets on the one
hand and the outputs’ fuzzy subsets on the other hand, thus forming the rule-base.
57
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
5. Choose appropriate scaling factors for the input and output variables to normalize the
variables to the [0, 1] or the [−1, 1] interval.
6. Fuzzify the inputs to the controller.
7. Use fuzzy approximate reasoning to infer the output contributed from each rule.
8. Aggregate the fuzzy outputs recommended by each rule.
9. Apply defuzzification to form a crisp output.
Aircraft Landing Control Problem
The following example shows the flexibility and reasonable accuracy of a typical application
in fuzzy control.
Example 3.6
We will conduct a simulation of the final descent and landing approach of an aircraft. The
desired profile is shown in Figure 3.12. The desired downward velocity is proportional to the
square of the height. Thus, at higher altitudes, a large downward velocity is desired. As the
height (altitude) diminishes, the desired downward velocity gets smaller and smaller. In the
limit, as the height becomes vanishingly small, the downward velocity also goes to zero. In
this way, the aircraft will descend from altitude promptly but will touch down very
gently to avoid damage.
Figure 3.12 The desired profile of downward velocity versus altitude
The two state variables for this simulation will be the height above ground, h, and the vertical
velocity of the aircraft, v (Figure 3.13). The control output will be a force that, when applied
to the aircraft, will alter its height, h, and velocity, v. The differential control equations are
loosely derived as follows. See Figure 3.14. Mass, m, moving with velocity, v, has momentum,
58
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
p = mv. If no external forces are applied, the mass will continue in the same direction at the
same velocity. If a force, f, is applied over a time interval Δt, a change in velocity of Δv = fΔt/m
will result. If we let Δt = 1.0 (s) and m = 1.0 (Ib s2 ft−1), we obtain Δv = f (lb), or the change in
velocity is proportional to the applied force.
Figure 3.13 Aircraft landing control problem
Figure 3.14 Simple momentum model for aircraft landing
In difference notation, we get
vi+1 = vi + fi,
hi+1 = hi + vi Δt,
where vi+1 is the new velocity, vi is the old velocity, hi+1 is the new height, and hi is the old
height. These two “control equations” define the new value of the state variables v and h in
response to control input and the previous state variable values. Next, we construct
membership functions for the height, h, the vertical velocity, v, and the control force, f:
Step 1. Define membership functions for state variables as shown in Tables 3.3 and 3.4 and
Figures 3.15 and 3.16.
59
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
Table 3.3 Membership values for height
Table 3.4 Membership values for velocity
Figure 3.15 Height, h, partitioned
Figure 3.16 Velocity, v ,partitioned
60
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
Step 2. Define a membership function for the control output, as shown in Table 3.5 and
Figure 3.17.
Table 3.5 Membership values for control force
Figure 3.17 Control force, f ,partitioned
Step 3. Define the rules and summarize them in an FAM table (Table 3.6). The values in the
FAM table, of course, are the control outputs.
Table 3.6 FAM table
Step 4: Define the initial conditions and conduct a simulation for four cycles. Because the
task at hand is to control the aircraft’s vertical descent during approach and landing, we will
61
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
start with the aircraft at an altitude of 1000 feet, with a downward velocity of −20 ft s−1. We
will use the following equations to update the state variables for each cycle:
vi+1 = vi + fi,
hi+1 = hi + vi.
Initial height, h0 : 1000 ft
Initial velocity, v0 : −20 fts−1
Control f0 to be computed
Height h fires L at 1.0 and M at 0.6 (h1000 = 0.6/M+1.0/L)
Velocity v fires only DL at 1.0 (v-20 = 1.0/DL)
Reasoning the output force f0:
height velocity Force (COA)
Rule 1 M(0.6) DL (1.0) US (0.6)
Rule 2 L (1.0) DL (1.0) Z (1.0)
WE defuzzify using COA and get f0=5.8lb. This is the output force computed from initial
conditions. The results for cycle 1 appear in Figure 3.18.
Figure 3.18 Truncated consequents and union of fuzzy consequent for cycle 1
62
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
Now, we compute new values of the state variables and the output for the next cycle:
h1 = h0 + v0 = 1000 +(−20) = 980ft,
v1 = v0 + f0 = −20 + 5.8= −14.2fts−1.
Height h1 = 980 ft fires L at 0.96 and M at 0.64 (h980= 0.64/M+0.96/L)
Velocity v1 = −14.2fts−1 fires DS at 0.58 and DL at 0.42 (v-14.0 = 0.42/DL+0.58/DS)
Reasoning the output force f1:
height velocity Force (COA)
Rule 1 M (0.64) DL (0.42) US (0.42)
Rule 2 M (0.64) DS (0.58) Z (0.58)
Rule 3 L (0.96) DL (0.42) Z (0.42)
Rule 4 L (0.96) DS (0.58) DS (0.58)
We defuzzify using COA and get f1= − 0.5lb. Results are shown in Figure 3.19.
f1= −0.5
Figure 3.19 Union of fuzzy consequent for cycle 1
Now, we compute new values of the state variables and the output for the next cycle.
h2 = h1 + v1 = 980 + (−14.2) = 965.8ft,
v2 = v1 + f1 = −14 2+ (−0 5) = −14.7fts−1.
h2 = 965.8 ft fires L at 0.93 and M at 0.67 (H965.8= 0.67/M+0.93/L),
v2 = −14 7fts−1 fires DL at 0.43 and DS at 0.57 (v-14.7 = 0.43/DL+0.57/DS).
63
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
Reasoning the output force f2:
height velocity Force (COA)
Rule 1 M (0.67) DL (0.43) US (0.43)
Rule 2 M (0.67) DS (0.57) Z (0.57)
Rule 3 L (0.93) DL (0.43) Z (0.43)
Rule 4 L (0.93) DS (0.57) DS (0.57)
We defuzzify using COA and get f2= − 0.4lb. Results are shown in Figure 3.20.
f2= −0.4
Figure 3.20 Union of fuzzy consequent for cycle 2
Again, we compute new values of state variables and output:
h3 = h2 + v2 = 965.8+ (−14.7) = 951.1 ft,
v3 = v2 + f2 = −14.7+ (−0.4) = −15.1 ft s−1
and for one more cycle we get
h3 = 951.1ft fires L at 0.9 and M at 0.7 (h951.1= 0.7/M+0.9/L),
v3 = −15.1fts−1 fires DS at 0.49 and DL at 0.51 (v-15.1 = 0.51/DL+0.49/DS).
64
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
Reasoning the output force f3:
height velocity Force (COA)
Rule 1 M (0.7) DL (0.51) US (0.51)
Rule 2 M (0.7) DS (0.49) Z (0.49)
Rule 3 L (0.9) DL (0.51) Z (0.51)
Rule 4 L (0.9) DS (0.49) DS (0.49)
We defuzzify using COA and get f3= 0.3lb. Results are shown in Figure 3.21.
f3= 0.3lb
Figure 3.21 Union of fuzzy consequent for cycle 3
Now, we compute the final values for the state variables to finish the simulation:
h4 = h3 + v3 = 951.1 −15.1 = 936.0ft,
v4 = v3 + f3 = −15.1+0.3= −14.8fts−1.
The summary of the four-cycle simulation results is presented in Table 3.7. If we look at the
downward velocity versus altitude (height) in Table 3.7, we get a descent profile that appears
to be a reasonable start at the desired parabolic curve shown in Figure 3.12 at the beginning of
the example.
Table 3.7 Summary of four-cycle simulation results
65
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
Chapter 3.4 Self-Organising Fuzzy Logic Controller
The Self-Organising Fuzzy Logic Controller (SOFLC) has a control policy which can
change with respect to the process it is controlling and the environment it is operating in.
The particular feature of this controller is that it strives to improve its performance until it
converges to a predetermined quality.
The SOFLC has to perform two tasks simultaneously: to observe the environment while
issuing the appropriate control actions and to use the results of these control actions to
improve them further. In other words, the function of the SOFLC is one of combined system
identification and control.
The ability of the SOFLC to carry out system identification makes it unnecessary to have a
detailed understanding of the environment. The advantage of this technique lies in the fact
that only a minimal amount of information about the environment is required. It is also
useful when the system under control is subject to time-varying parameter changes and
unknown disturbances.
3.4.1 Structure of a SOFLC
A SOFLC is a two-level, hierarchical, rule-base type of controller in which the fuzzy
control rule base of the FLC is created and modified by a learning module with the self-
organising algorithm while executing the control task. As shown in Figure 3.22, a SOFLC
consists of an ordinary fuzzy logic controller (FLC) at the low level and a learning
module at the top level.
The learning module, which contains a performance index table (learning rule base table)
and a rule generation and modification algorithm, is responsible for creating new rules or
modifying existing ones.
In a SOFLC, the control state of a process is monitored by the learning module. When an
undesirable output of the process is detected, the fuzzy control rules are created or
modified based on the corrections given by the performance index table.
66
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
Figure 3.22 Structure of Self-Organising Fuzzy Logic Controller
3.4.2 Performance Index Table
The performance index table relates the state of the process to the deviation from its
desired behaviour, and defines the corrections required for the FLC to bring the system to the
desired states. Depending on the structure of a FLC, a performance index table can be defined
linguistically or expressed quantitatively using such performance indices such as error,
mean square error, maximum absolute error, and averaged error of the system variables.
Typically, the performance index table is derived from a general set of linguistic rules
which express the desired control trajectories in the state-space of the system. Table 3.8
gives an example of a performance index table.
Table 3.8 Performance index table (Inputs e and ce; output: P)
67
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
3.4.3 Rule-base Generation and Modification
Consider a FLC with the following variables:
et : Error input at instant t
cet : Change of error input at instant t
ut : Control output of the FLC at instant t
Furthermore, if the delay-in-reward parameter is denoted by d, and the performance index
output at instant t be denoted by P(et ,cet ). Assume that an undesirable output is detected
at instant t and a control action ut-d taken d instant before, is responsible for the current
response. The system state at that instant is denoted by
(et-d , cet-d , ut-d) (3.16)
To bring the system back to the desired state, the control output of the FLC will have to be
changed into: (et-d , cet-d , ut-d + P(et ,cet ))
Based on this group of system states, a new fuzzy control rule can be formulated. The
algorithm for rule base generation/modification will check if a fuzzy control rule exists
under this system state. If not, a new rule will be added to the rule base. Otherwise, the
existing rule will be modified into a newly formulated rule. If P(et ,cet ) = 0, the system
performance is satisfactory. No rule generation or modification should take place in the
current system state.
3.4.4 Self-Organising Procedure
Let the i-th basic control rule in a SOFLC be denoted by:
IF et is Ai AND cet is Bi THEN ut is Ci
Let j-th modification rule in the performance modification module be denoted by:
IF et is Aj AND cet is Bj THEN pt is Pj
68
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
For a SOFLC with N basic control rules and M performance modification rules, the rule
modifications are often carried out in the following procedures
1. Calculate the fire strength i for each control rule
2. Perform the fuzzy reasoning ui for each control rule
3. Calculate the performance modification P
4. Find the dominant rule which contributes most to the control action
5. If no rule is found, create a new rule in the control rule base
6. If the k-th rule is found, modify rule k using a new control output.
3.4.5 Remarks
In a SOFLC, the fuzzy control rules depend strongly on the performance index table. The
performance index table is often designed heuristically based on intuitive understanding of
the process. However, it is not trivial to design a performance index table which can
represent a desired output response exactly. That may be one of the reasons that several
other approaches have been proposed and implemented including the following:
• Model-based self-organising schemes which accomplish the learning without
using the performance index table.
• Neural network based self-learning.
69
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
References
Brown M., Harris C. 1994. Neurofuzzy Adaptive Modelling and Control.
Hertfordshire: Prentice Hall.
Jamshidi, M., Vadiee, N., Ross, T.J. 1993, Fuzzy Logic and Control, Prentice Hall, New
Jersey.
Kosko B. 1992. Neural Networks and Fuzzy Systems. New Jersey: Prentice Hall. Jamshidi
Ross T.J. 2017. Fuzzy Logic with Engineering Applications (4th edition). McGraw-Hill.
Wang, L. X. 1994, Adaptive Fuzzy Systems and Control, Prentice Hall, New Jersey.
Yager, R.R., Filev, D.P. 1994, Essentials of Fuzzy Modelling and Control, John Wiley,
New York.
Yan, J., Ryan, M., Power, J. 1994, Using Fuzzy Logic, Prentice Hall, Hertfordshire.
70
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
CHAPTER FOUR
SINGLE-LAYER FEEDFORWRD NEURAL NETWORKS
AND RECURRENT NEURAL NETWORK
_______________________________________________________
Chapter 4.1 Single-Layer Perceptron Classifiers
4.1.1 Classification Model
One of the most useful tasks which can be performed by networks of interconnected nonlinear
elements is pattern classification. A pattern is the quantitative description of an object, event,
or phenomenon. The classification may involve spatial and temporal patterns. Examples of
spatial patterns are pictures, weather maps, fingerprints, and characters. Examples of
temporal patterns include speech signals, electrocardiograms, and seismograms. Temporal
patterns usually involve ordered sequences of data appearing in time.
The goal of pattern classification is to assign a physical object, event, or phenomenon to one
of the pre-specified classes (or categories). Typical classification tasks required from a
human being have been classification of the environment into groups such as living species,
plants, weather conditions, minerals, tools, human faces, voices, etc. The interpretation of
data has been learned gradually as a result of repetitive inspecting and classifying of examples.
A classifying system consists of an input transducer providing the input pattern data to the
feature extractor as shown in Figure 4.1. Typically, inputs to the feature extractor are sets of
data vectors which belong to a certain category. Usually, the converted data at the output of
the transducer can be compressed without loss of essential information. The compressed data
are called features.
71
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
Figure 4.1 Classification system
Two simple ways to generate the pattern vector for cases of spatial and temporal objects are
shown in Figure 4.2. In Figure 4.2(a), each component xi of the vector 𝐱 =
[𝑥1 𝑥2 ⋯ 𝑥𝑛 ]′ is assigned the value 1 if the i-th cell contains a portion of a spatial object,
otherwise the value 0 is assigned. In the case of a temporal object being a continuous function
of time t as in Figure 3.2(b), the pattern vector may be formed by letting xi = f (ti), i = 1,
2, …, n.
(a) Spatial (b) Temporal object
Figure 4.2 Pattern coding
72
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
4.1.2 Discriminant Functions
Assume that a set of n-dimensional patterns x1,x2 , ··· ,xP and the desired classification for
each pattern (R categories) are known. In the classification step, the membership in a category
needs to be determined by a classifier based on the comparison of R discriminant functions
g1(x), g2(x),...,gr(x).
The pattern x belongs to the i-th category if and only if
gi(x)>gj(x); i,j=1, 2, …R; ij (4.1)
Within the region Hi, the i-th discriminant function gi(x) will have the largest value.
Example 4.1
Six patterns in 2-dim pattern space shown in Figure 4.3 need to be classified according to
their membership in sets as follows
[0,0],[-0.5,-1],[-1,-2] : Class 1
[2,0],[1.5,-1],[1,-2] : Class 2
Inspection of the patterns indicates that the equation for the decision surface can be arbitrarily
chosen
g(x) = −2x1+x2+2 (4.2)
It is obvious that g(x) > 0 and g(x) < 0 in each of the half-planes containing patterns of Class
1 and Class 2 respectively, and g(x) = 0 for all points on the line.
The two discriminant functions can be defined as
g1(x)=−x1+0.5x2+2 (4.3)
g2(x)=x1 − 0.5x2 (4.4)
Note also that the decision surface equation g(x) can be derived from
g(x)=g1(x) − g2(x) (4.5)
73
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
Figure 4.3 Decision surface
4.1.3 Linear Classifier
A basic pattern classifier is shown in Figure 4.4. For a given pattern, the i-th discriminator
computes the value of the function gi(x). The maximum selector implements condition (4.1)
and selects the largest of all inputs, thus yielding the response equal to the category number
io.
Figure 4.4 Pattern classifier
74
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
A special case of classifiers is the dichotomiser where there are only categories (R = 2). A
single threshold logic unit (TLU) can be used to build such a simple dichotomiser as shown
in Figure 4.5.
Figure 4.5 Dichotomiser
In general, the efficient classifier must be described by nonlinear discriminant functions as
shown in Figure 4.6. It can be shown that the use of nonlinear discriminant functions can be
avoided by changing the feedforward structure of the classifier to the multilayer form.
Figure 4.6 Nonlinear decision surface
75
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
In the linear classification case as shown in Figure 4.7, there are two clusters of patterns with
each cluster belongs to one known category. The central points (prototype points) P1 and P2
of Class 1 and Class 2 clusters are vectors x1 and x2 respectively. These points can be
interpreted as centres of gravity for each cluster. The decision hyperplane should contain the
midpoint of the line segment connecting the two central points, and should be normal to the
vector (x1−x2), which is directed toward P1.
Figure 4.7 Linear discriminant function
The decision hyperplane equation can be written in the following form:
1
𝑔(𝑥) = (𝐱1 − 𝐱 2 )𝑇 𝐱 + (‖𝑥2 ‖2 − ‖𝑥1 ‖2 ) = 0 (4.6)
2
Note that g(x) constitutes a hyperplane described by the equation
𝑔(𝑥) = 𝐰 𝑇 𝐱 + 𝑤𝑛+1 = 0 (4.7)
𝑔(𝑥) = 𝑤1 𝑥1 + 𝑤2 𝑥2 + ⋯ + 𝑤𝑛 𝑥𝑛 +𝑤𝑛+1 = 0
The weighting coefficients of the dichotomiser can be obtained easily from Eqs. (4.6) − (4.7)
as follows:
𝐰 = 𝐱1 − 𝐱 2 (4.8)
1
𝑤𝑛+1 = (‖𝑥2 ‖2 − ‖𝑥1 ‖2 )
2
76
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
4.1.4 Minimum-distance classifier
Assume that a minimum distance classification is required to classify patterns into one of the
R categories. Each of the R classes is represented by the central points P1, P2, ,…PR which
correspond to vectors x1, x2,···,xR respectively. The Euclidean distance between the input
pattern x and the prototype pattern vector xi is
‖𝐱 − 𝐱 𝑖 ‖ = √(𝐱 − 𝐱𝑖 )𝑇 (𝐱 − 𝐱𝑖 ) (4.9)
A minimum-distance classifier calculates the distance from pattern x of unknown
classification to each prototype. The category number of the prototype which yields the
smallest distance is assigned to the unknown pattern.
‖𝐱 − 𝐱 𝑖 ‖𝟐 = 𝐱 𝐓 𝐱 − 𝟐𝐱𝑖 𝑻 𝐱 + 𝐱𝑖 𝑻 𝐱𝑖 (4.10)
Note that choosing the largest of the term (𝐱𝑖 𝑇 𝐱 − 0.5𝐱𝑖 𝑇 𝐱 𝒊 ) is equivalent to choosing the
smallest of the distance ‖𝐱 − 𝐱𝒊 ‖ as the term 𝐱 𝐓 𝐱 is independent of i and shows up in each
of the R distances. Therefore, for a minimum-distance classifier, a discriminant function
gi(x) can be found
𝑔𝒊 (𝐱) = 𝐱 𝑖 𝑇 𝐱 − 0.5𝐱𝑖 𝑇 𝐱 𝑖 = 𝒘𝑖 𝑇 𝐱 + 𝑤𝑖,𝑛+1 , i=1, 2, …R (4.11)
The weighting coefficients for a minimum-distance classifier are:
𝒘𝑖 = 𝐱 𝑖 (4.12)
𝑤𝑖,𝑛+1 = −0.5𝐱𝑖 𝑇 𝐱𝑖 (4.13)
The minimum-distance classifiers can be considered as linear classifiers, sometimes called
linear machines. Since minimum-distance classifiers assign category membership based on
the closest match between each prototype and the current input pattern, the approach is also
called correlation classification. The block diagram of a linear classifier is shown in Figure
4.8.
The decision surface Sij for the contiguous decision regions Hi, Hj is a hyperplane given by
the equation
gi(x) − gj(x) = 0 (4.14)
77
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
Figure 4.8 A linear classifier
Example 4.2
Assume that the prototype points are as shown in Figure 4.9 and their coordinates are 𝑃1 =
10 2 −5
[ ] , 𝑃2 = [ ] , 𝑃3 = [ ] and then design a linear (minimum-distance) classifier.
2 −5 5
For R=3, the weight vectors can be obtained as
10 2 −5
𝐰1 = [ 2 ], 𝐰2 = [ −5 ] , 𝒘3 = [ 5 ]
−52 −14.5 −25
The corresponding linear discriminant functions are
g1(x) = 10x1 +2x2−52
g2(x) = 2x1 −5x2−14.5
g3(x) = −5x1 +5x2−25
78
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
The decision lines can be calculated as:
S12(x)= g1(x) − g2(x) = 8x1 +7x2−37.5 = 0
S23(x)= g2(x) − g3(x) = 7x1 − 10x2+10.5 = 0
S31(x)= g3(x) − g1(x) = − 15x1 +3x2+27 = 0
Figure 4.9 Decision lines
79
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
4.1.5 Non-parametric Training Concept
It is possible for neural network classifiers to derive their weights during the learning cycle.
The sample pattern vectors x1,x2 , ···, xp, called the training sequence, are presented to a
classifier along with the correct response. The classifier modifies its parameters by means of
iterative, supervised learning. The network learns from experience by comparing the targeted
correct response with the actual response.
A supervised training procedure for the dichotomiser as shown in Figure 4.10 can be
developed as follows. The dichotomiser consists of (n+1) weights and the TLU (threshold
logic unit). It is identical to the binary bipolar perceptron.
Figure 4.10 Linear dichotomiser using hard-limiting threshold element
The decision surface equation in n-dimensional pattern space is
𝐰 T 𝐱 + 𝑤𝑛+1 = 0 (4.15)
or in the augmented weight space
𝐰T𝐲 = 0 (4.16)
where
𝑤1 𝑥1
𝑤2 𝑥2
𝐰= ⋮ ,𝐲= ⋮
𝑤𝑛 𝑥𝑛
[𝑤𝑛+1 ] [1]
This is a normal vector-point equation which describes a decision hyperplane in augmented
weight space. In contrast to the decision hyperplane of Equation (4.15), this hyperplane always
intersects the origin. Its normal vector, which is perpendicular to the plane, is the pattern y.
80
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
The normal vector will always point toward the side of the space for which 𝐰 T 𝐲 > 𝟎. This
side is called the positive side, or positive semispace, of the hyperplane.
Figure 4.11 shows a decision surface for the training pattern y1 in the augmented weight space
of the discrete perceptron (Figure 4.10).
Figure 4.11 Steepest descent weight adjustment
Assume that the initial weights are wl and that pattern y1 of Class 1 is now input (Case A).
Obviously, the pattern is misclassified due to g1(y) = (wl)Ty1< 0. To increase the discriminant
function g1(y1), the weight vector should be adjusted in the direction of steepest increase,
which is that of a gradient.
81
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
w(g(y)) = w (wTy) = y (4.17)
The adjusted weights should become
𝐰 2 = 𝐰1 + 𝑐𝐲1 (4.18)
where constant c > 0 is called the correction increment.
Case B illustrates a similar misclassification with the initial weight and pattern y1 of Class 2
being input. Obviously, the pattern is misclassified due to g1(y) = (wl)Ty1> 0. To decrease the
discriminant function g1(y1), the weight vector should be adjusted in the direction of steepest
decrease.
The adjusted weights should become
𝐰 2 = 𝐰1 − 𝑐𝐲1 (4.19)
The supervised training procedure can be summarised using the following expression for the
augmented weight vector:
𝐰 ∗ = 𝐰 ± 𝑐𝐲 (4.20)
where the positive sign applies for undetected pattern of Class 1, and the negative sign for
undetected pattern of Class 2. If a correct classification takes place, no adjustment of weights
is made.
82
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
4.1.6 Training and Classification using the Discrete Perceptron
The distance of p of a point w from the decision plane wTy = 0 in (n+1)-dimensional
Euclidean space can be calculated from
𝐰𝑻𝐲
𝑝 = ‖𝒚‖ (4.21)
Since p is always a non-negative scalar, Equation (4.21) can be rewritten as
|𝐰 𝑻 𝐲|
𝑝= ‖𝒚‖
(4.22)
Note that if the correction constant c is selected such that the corrected weight vector w* is
placed on the decision hyperplane wTy = 0.This implies that
(w*)Ty = 0 or (w𝑐𝐲)Ty = 0 (4.23)
The corresponding correction increment can be calculated as
𝐰𝑻𝐲
𝑐= (4.24)
𝐲𝑻𝐲
or more conveniently
|𝐰 𝑻 𝐲|
𝑐= (4.25)
𝐲𝑻𝐲
The length of the weight adjustment vector cy can be expressed as
|𝐰 𝑻 𝐲|
‖𝑐𝐲‖ = ‖𝐲‖ (4.26)
𝐲𝑻𝐲
Note that the distance p from the point w to the decision plane is identical to the length of
the weight incremental vector. Using this technique, the correction increment cis not constant
and depends on the current training pattern.
For the fixed correction rule
𝐰 ∗ = 𝐰 + 0.5𝑐[𝑑 − sgn(𝒘𝑇 𝐲)]𝐲 (4.27)
Using the variable correction rule
|𝐰 𝑻 𝐲|
𝐰 ∗ = 𝐰 + 0.5 [𝑑 − sgn(𝒘𝑇 𝐲)]𝐲 (4.28)
𝐲𝑻𝐲
where the coefficient is the ratio of the distance between the old weight vector w and the
new weight vector 𝐰 ∗ , to the distance from w to the hyperplane in the weight space. Note
that 0 < <1 for fractional correction rule and 1< < 2 for absolute correction rule.
83
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
Example 4.3
A dichotomiser as shown in Figure has to be trained to recognise the following classification
of four patterns x with known class membership d.
𝐱1 = [1], 𝐱2 = [−0.5], 𝐱 3 = [3], 𝐱 4 = [−2]
𝑑1 = [1], 𝑑2 = [−1], 𝑑3 = [1], 𝑑4 = [−1]
Figure 4.12 Discrete perceptron classifier training (network diagram)
The augmented input vectors are
1 −0.5 3 −2
𝐲1 = [ ], 𝐲2 = [ ] , 𝐲3 = [ ] , 𝐲4 = [ ]
1 1 1 1
Using the fixed correction rule in eq. (4.27), an arbitrary selection of c =1, and the initial
weight chosen arbitrary as
−2.5
𝐰1 = [ ]
1.75
show that
−1.5 −1 2.0
𝐰2 = [ ] , 𝐰3 = [ ] , 𝐰4 = [ ]
2.75 1.75 2.75
Since we have no evidence of correct classification for weights 𝐰 5 , the training set consisting
of an ordered sequence of patterns 𝐲1 , 𝐲2 , 𝐲3 , 𝐲4 needs to be recycled. Therefore, we have
𝐲5 = 𝐲1 , 𝐲6 = 𝐲2 ,𝐲7 = 𝐲3 ,𝐲8 = 𝐲4 , etc.
3
Show that the final weights of the weight vector is 𝐰11 = [ ]
0.75
and that this weight vector provides correct classification of the entire training set.
84
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
Figure 4.13 Discrete perceptron classifier training (fix correction rule training)
4.1.7 Single-Layer Continuous Perceptron Networks
In this section, the continuous perceptron as shown in Figure 4.14 is considered. The
introduction of the continuous perceptron is to gain finer control over the training procedure
and to facilitate working with differentiable characteristics of the threshold element, thus
enabling computation of the error gradient.
Figure 4.14 Continuous perceptron training
85
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
The training is based on the steepest descent technique. Starting from an arbitrary chosen
weight vector w, the gradient E(w) of the current vector is calculated. The adjusted weight
vector w* is obtained by moving in the direction of the negative gradient along the multi-
dimensional error surface. An example of an error surface is shown in Figure 4.15.
Figure 4.15 Error surface
The steepest descent algorithm can be summarised as:
w* = w −E(w) (4.29)
where > 0 is the learning constant.
Define the error Ek in the k-th training step as
1
𝐸𝑘 = (𝑑𝑘 − 𝑧𝑘 )2 (4.30)
2
with
vk = (wk)Tyk, zk = f(vk)
The error minimisation algorithm can be calculated using the chain rule as follows:
𝜕𝐸𝑘 𝜕𝐸𝑘 𝜕𝑧 𝑘 𝜕𝑣 𝑘
∇𝐸𝑘 (𝐰 𝑘 ) = = (4.31)
𝜕𝐰 𝑘 𝜕𝑧 𝑘 𝜕𝑣 𝑘 𝜕𝐰 𝑘
Equation 4.30 becomes
𝜕𝑧 𝑘
∇𝐸𝑘 (𝐰 𝑘 ) = −(𝑑𝑘 − 𝑧𝑘 ) 𝐲 (4.32)
𝜕𝑣 𝑘 𝑘
86
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
Combining Equations (4.29) and (4.32), we have
𝜕𝑧
w* = w +(d−z) 𝐲 (4.33)
𝜕𝑣
It can be seen that this rule is equivalent to the delta training rule (2.21). The calculation
of adjusted weights requires an arbitrary choice of and the specification for the activation
function z = f (v) used.
A significant difference between the discrete and continuous perceptron training is that the
discrete perceptron training algorithm always leads to a solution for linear separable
problems. In contrast, the negative gradient-based continuous perceptron training does not
guarantee solutions for linearly separable patterns.
Example 4.4
1−𝑒 −𝑣
A continuous perceptron with a bipolar activation function as 𝑓2 (𝑣) = shown in
1+𝑒 −𝑣
Figure 4.16 has to be trained to recognise the following classification of four patterns x with
known class membership d.
𝐱1 = [1], 𝐱2 = [−0.5], 𝐱 3 = [3], 𝐱 4 = [−2]
𝑑1 = [1], 𝑑2 = [−1], 𝑑3 = [1], 𝑑4 = [−1]
Figure 4.16 Continuous perceptron classifier training (network diagram)
The augmented input vectors are
1 −0.5 3 −2
𝐲1 = [ ], 𝐲2 = [ ] , 𝐲3 = [ ] , 𝐲4 = [ ]
1 1 1 1
87
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
𝜕𝑧 𝜕𝑓2 (𝑣)
Note that for bipolar activation function = = 0.5(1 − 𝑧 2 ). Using the delta
𝜕𝑣 𝜕𝑣
training rule in Equation (4.33), an arbitrary selection of = 0.5, and the initial
weights chosen arbitrary as
−2.5
𝐰1 = [ ]
1.75
show that
−2.204 −2.1034
𝐰2 = [ ] , . . . , 𝐰4 = [ ]
2.046 1.9912
Since we have no evidence of correct classification for weights 𝐰 4 , the training set consisting
of an ordered sequence of patterns 𝐲1 , 𝐲2 , 𝐲3 , 𝐲4 needs to be recycled. Therefore, we have
𝐲5 = 𝐲1 , 𝐲6 = 𝐲2 ,𝐲7 = 𝐲3 ,𝐲8 = 𝐲4 , etc.
3.1514
Show that the weights vector after 40 cycles (160 steps) is 𝐰16 = [ ]
−0.6233
and that this weight vector provides correct classification of the entire training set.
Figure 4.17 Continuous perceptron classifier training (delta training rule)
88
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
4.1.8 Multi-Category Single-Layer Perceptron Networks
To apply the error-correcting algorithm to the task of multi-category classification, the linear
classifier in Figure 4.8 can be modified to include discrete perceptrons as shown in Figure
4.18. The assumption needed is that classes are linearly separable. Direct supervised training
of this network can be performed in a similar manner as in Section 4.1.6.
For example, using the fixed correction rule, the weight adjustment for this network is
𝐰𝑖∗ = 𝐰𝑖 + 0.5𝑐(𝑑𝑖 − 𝑧𝑖 )𝒚, where 𝑖 = 1,2, … . , 𝑅 (4.34)
where di and zi are the desired and actual responses of the i-th discrete perceptron
respectively.
Note that we have been using yn+l = 1. It is important to note that from the training viewpoint,
any constant value of yn+l is also appropriate. However when yn+l = −1, the wn+l value becomes
equal to the actual firing threshold of the neuron with input being the original pattern x.
Therefore, it may be more convenient to denote the augmented pattern as
𝐱
𝐲=[ ] with wn+l = T
−1
For R-category classifiers with local representation, the desired response or the training
pattern of the i-th category is
𝑑𝑖 = 1, 𝑑𝑗 = −1, where 𝑗 = 1,2, … . , 𝑅, 𝑗 ≠ 𝑖
For R-category classifiers with distributed representation, the desired response or the training
pattern of the i-th category is not required, as more than a single neuron is allowed to
respond +1 in this mode.
89
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
Figure 4.18 A linear classifier using R discrete perceptrons
Example 4.5
10
Similar to Example 4.2, assume that coordinates of the prototype points are 𝐱1 = [ ] , 𝐱2 =
2
2 −5
[ ] , 𝐱3 = [ ], design a Linear classifier using 3 discrete perceptron.
−5 5
The augmented input vectors are
10 2 −5
𝐲1 = [ 2 ], 𝐲2 = [−5], 𝐲3 = [ 5 ]
−1 −1 −1
The class membership vectors d are
1 −1 −1
𝑑1 = [−1], 𝑑2 = [ 1 ], 𝑑3 = [−1]
−1 −1 1
Also, the training set consisting of an ordered sequence of patterns y1, y2, y3 can be recycled if
necessary. Therefore, we have y4 = y1, y5 = y2, y6 = y3 , etc.
Using the fixed correction rule, an arbitrary selection of c = 1, and the initial weights chosen
arbitrary for each discrete perceptron as
1 0 1
𝐰11 1 1
= [−2], 𝐰2 = [−1] , 𝒘3 = [ 3 ]
0 2 −1
show that the final weight vectors are:
5 0 −9
𝐰19 = [3], 𝐰21 = [−1] , 𝒘23 = [ 1 ]
5 2 0
90
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
The three perceptron network obtained as a result of the training is shown in Figure 4.19. It
performs the following classification:
z1=sgn(5x1+3x2−5)
z2=sgn(− x2−2)
z3=sgn(− 9x1+x2)
The resulting surfaces are shown in Figure 4.20. Note that in constrast to the minimum-
distance classifier, this method has produced several indecision regions where no class
membership of an input pattern can be uniquely determined.
Figure 4.19 Continuous perceptron classifier training
Figure 4.20 Decision regions
91
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
Chapter 4.2 Single-Layer Feedback (Recurrent) Network
Hopfield's seminal papers in 1982 and 1984 (Hopfield 1982, 1984) were responsible for many
important applications in neural networks, especially in associative memory and optimisation
problems. His proposed Hopfield networks promoted construction of the first analogue VLSI
neural chip (Howard et al.1988).
Figure 4.21 Single-layer feedback neural network
The single-layer feedback network (Hopfield network) is shown in Figure 4.21. It consists of
n neurons having threshold values T. The updated output z* of the network can be found from
v=Wz+x−T (4.35)
𝒛∗ = 𝑓(𝒗) (4.36)
where z, x, T are the output vector, external input vector, and threshold vector respectively,
f(·) is the activation function, and W is the weight matrix (connectivity matrix)
92
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
𝑧1 𝑣1 𝑥1 𝑇1
𝑧 𝑣 𝑥 𝑇
𝐳 = [ … ], 𝐯 = [ … ] , 𝐱 = [ … ], 𝐓 = [ …2 ]
2 2 2 (4.37)
𝑧𝑛 𝑣𝑛 𝑥𝑛 𝑇𝑛
𝑓(𝑣1 )
𝐳 = 𝑓(𝐯) = [ 𝑓(𝑣 )
…2 ] (4.38)
𝑓(𝑣𝐾 )
0 𝑤12 ⋯𝑤1𝑛
𝑤21 0 ⋯𝑤2𝑛
𝐖=[ ] = [𝐰1 𝐰2 ⋯ 𝐰𝑛 ] (4.39)
⋮ ⋮ 0 ⋮
𝑤𝑛1 𝑤𝑛2 ⋯ 0
The weight matrix W is symmetrical and with zero diagonal entries (i.e. 𝑤𝑖𝑗 = 𝑤𝑗𝑖 , 𝑤𝑖𝑖 = 0)
Assuming that discrete perceptrons are used, for a discrete-time recurrent network, the
following update rules can be used.
Asynchronous stochastic recursion of the Hopfield model network
𝑧𝑖𝑘+1 = 𝑓(𝑣𝑖𝑘 ) = sgn (𝑤𝑖𝑇 𝑧 𝑘 + 𝑥𝑖 − 𝑇𝑖 ), for i=1, 2, …, n. (4.40)
For this update rule, the recursion starts at 𝐳 0 , which is the output vector corresponding to the
initial pattern submitted. The first iteration for k=1 results in 𝑧𝑖1 , where the neuron number i
is random. The other updates are also for random node number j where j i until all elements
of the vector 𝐳1 are updated.
Synchronous (parallel) update algorithm
𝑧𝑖𝑘+1 = 𝑓(𝑣 𝑘 ) = sgn (𝐖𝑧 𝑘 + 𝐱 − 𝐓) (4.41)
Under this update mode, all n neurons of the layer are allowed to change their output
simultaneously.
93
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
Example 4.6
Consider a two-node discrete Hopfield network with
0 −1 0 0
𝐖=[ ], 𝐱 = [ ], and 𝐓 = [ ]
−1 0 0 0
−1
Set the initial output vector as 𝑧 0 = [ ]
−1
Asynchronous update rule
According to the asynchronous update rule, only one node is considered at a time. Assume
that the first node is chosen for update and the second node is considered next
1 1 1
𝑧1 = [ ], 𝑧 2 = [ ], 𝑧 3 = [ ] , …
−1 −1 −1
1
The state 𝒛 = [ ] is an equilibrium state of the network. Using different initial outputs, the
−1
1 −1
vectors 𝒛 = [ ] and 𝒛 = [ ] are the two equilibria of the system.
−1 1
Synchronous update rule
For the case of synchronous update
1 −1 1
𝑧1 = [ ] , 𝑧 2 = [ ], 𝑧 3 = [ ] , …
1 −1 1
The synchronous update produces a cycle of two states rather than a single equilibrium state.
94
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
Example 4.7
The convergence of a 10 x 12 pixels representing a corrupted digit 4 is shown in Figure 4.22.
Consecutive responses are shown in Figure 4.22 (a)-(f). It can be seen that no changes are
produced at the network output for k5 since the system reached one of its stable states.
Figure 4.22 Recursive asynchronous update of a corrupted digit 4:
(a) k = 0, (b) k = 1, (c) k = 2, (d) k = 3, (e) k = 4, (f) k = 5.
95
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
References
Bishop, C. M. 2000, Neural Networks for Pattern Recognition, Oxford University
Press, New York.
Brown, M., Harris C. 1994, Neurofuzzy Adaptive Modelling and Control, Prentice
Hall, Hertfordshire.
Hertz, J., Krogh, A., Palmer, R.G. 1991, Introduction to the Theoary of Neural
Computing, Addison-Wesley, Redwood City, California.
Kosko, B. 1992, Neural Networks and Fuzzy Systems, Prentice Hall, New Jersey.
Smith, M. 1993, Neural Networks for Statistical Modelling, Van Nostrand Reinhold, New
York.
Zurada, J.M. 1992, Introduction to Artificial Neural Systems, West Publishing
Company, St. Paul.
96
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
CHAPTER FIVE
MULTI-LAYER FEEDFORWRD NEURAL NETWORKS
_______________________________________________________
For training patterns which are linearly nonseparable, multi-layer networks (layered
networks) can be used. They can implement arbitrary complex input/output mappings or
decision surfaces separating pattern classes. The most important attribute of a multi-
layered feedforward network is that it can learn a mapping of any complexity using
repeated presentations of the training samples. The trained network often produces
surprising results and generalisations in applications where explicit derivation of
mappings and discovery of relationships is almost impossible.
Chapter 5.1 Linearly Nonseparable Patterns
Assume that two training sets Y1 and Y2 of augmented patterns are available for training.
If no weight vectors w exists such that
wTy >0, y Y1
(5.1)
w y <0, y Y2
T
then the pattern sets Y1 and Y2 are linearly nonseparable.
However, it is possible to map the original pattern space into an image space so that a two-
layer network can eventually classify the patterns which are linearly nonseparable in the
original pattern space.
97
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
Example 5.1
The layered classifier shown in Figure 5.1 is designed to implement the following linearly
nonseparable patterns of XOR function
0 0 1 1
𝐱1 = [ ] , 𝐱 2 = [ ] , 𝐱 3 = [ ] , 𝐱 4 = [ ]
0 1 1 0
𝑑1 = [−1], 𝑑2 = [1], 𝑑3 = [−1], 𝑑4 = [1]
Figure 5.1 Classifier diagram
The arbitrary selected partitioning is provided by the two decision lines in Figure 5.2
having equations
−2𝑥1 + 𝑥2 − 0.5 = 0
𝑥1 − 𝑥2 − 0.5 = 0
The mapping and classification summary table is shown below
The first layer provides an appropriate mapping of patterns into images in the image
space. The second layer implements the classification of the images rather than of the
original patterns. Note that both input patterns A and D collapse in the image space into
a single image (−1, −1).
An arbitrary decision line providing the desired classification and separating A, D and
B, C in the image space as shown in Figure 5.3 has been selected as
98
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
z1+z2+1=0
Figure 5.2 Decision lines in pattern space
Figure 5.3 Decision lines in image space
99
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
Chapter 5.2 Delta Learning Rule for Multi-Perceptron Layer
Error back-propagation training algorithm, an efficient and systematic learning
algorithm for layered linear machines employing perceptrons, has only been developed
recently (Werbos 1974, McClelland and Rumelhart 1986). This algorithm has
reawakened the scientific and engineering community to the modelling of many quantitative
phenomena using neural networks.
To formulate the learning algorithm, the continuous perceptron network involving K
neurons as shown in Figure 5.4 is considered.
Figure 5.4 Single-layer network with continuous perceptrons
The input and output values of the network are denoted y and z respectively. Using the vector
notation, the forward pass in the network can be expressed as follows
z = (v), where v=Wy (5.2)
where the input vector y, desired output vector d, output vector z, and the weight matrix W
are respectively
𝑦1 𝑑1 𝑧1 𝑤11 ⋯ 𝑤1𝐽
𝑦2 𝑧
𝐲 = [ … ], 𝐝 = [ 𝑑…2 ], 𝐳 = [ …2 ], 𝐖 = [ ⋮ ⋱ ⋮ ] (5.3)
𝑦𝐽 𝑑𝐾 𝑧𝐾 𝑤𝐾1 ⋯ 𝑤𝐾𝐽
and the non-linear operator (v) is
𝑓(𝑣1 )
(v) = [ 𝑓(𝑣 )
…2 ] (5.4)
𝑓(𝑣𝐾 )
100
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
The error expression can be found from
1
𝐸 = ∑𝐾
𝑘=1(𝑑𝑘 − 𝑧𝑘 )
2
(5.5)
2
Assume that the gradient descent search is performed to reduce the error E adjustment
of weights. The weight adjustment can be expressed as follows:
𝜕𝐸 𝜕𝐸 𝜕𝑣𝑘 𝜕𝐸
∆𝑤𝑘𝑗 = −𝜂 = −𝜂 = −𝜂 𝑦
𝜕𝑣𝑘 𝑗
= 𝜂𝑘 𝑦𝑗 (5.6)
𝜕𝑤𝑘𝑗 𝜕𝑣𝑘 𝜕𝑤𝑘𝑗
The error signal term is defined for this layer as
𝜕𝐸 𝜕𝐸 𝜕𝑧𝑘
𝑘 = − =− = (𝑑𝑘 − 𝑧𝑘 )𝑓′(𝑣𝑘 ) (5.7)
𝜕𝑣𝑘 𝜕𝑧𝑘 𝜕𝑣𝑘
The updated weights under the delta training rule can be found from
𝜕𝐸
𝐖 ∗= 𝐖 − 𝜂
𝜕𝐖
= 𝐖 + 𝜂y 𝑇 (5.8)
where
1
= [ 2]
…
𝐾
Chapter 5.3 Generalised Delta Learning Rule (Error Back Propagation Training)
Consider a two-layer network (or three-node layer network) as shown in Figure 5.5.
Layers with neurons whose outputs are not directly accessible are called hidden layers.
Figure 5.5 Layered feedforward neural network
101
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
The negative gradient descent for the hidden layer now can be found from
𝜕𝐸 𝜕𝐸 𝜕𝑣̅𝑗 𝜕𝐸
̅𝑗𝑖 = −𝜂 𝜕𝑤̅ = −𝜂 𝜕𝑣̅
∆𝑤 = 𝜂 𝑥𝑖 (5.9)
𝑗𝑖 𝑗 𝜕𝑤
̅ 𝑗𝑖 𝜕𝑣̅𝑗
The error signal term is defined for this hidden layer as
𝜕𝐸 𝜕𝐸 𝜕𝑦𝑗
̅𝑗 = − 𝜕𝑣̅ = − 𝜕𝑦 𝜕𝑣̅𝑗
(5.10)
𝑗 𝑗
Note that
𝜕𝐸 𝜕 1 𝜕𝐸𝑘 𝜕𝑧𝑘 𝜕𝑣𝑘
𝜕𝑦𝑗
= [ ∑𝐾 2 𝐾
𝑘=1(𝑑𝑘 −𝑧𝑘 ) ] = − ∑𝑘=1 (5.11)
𝜕𝑦𝑗 2 𝜕𝑧𝑘 𝜕𝑣𝑘 𝜕𝑦𝑗
𝜕𝐸 𝜕𝑧𝑘
𝜕𝑦𝑗
= − ∑𝐾
𝑘=1(𝑑𝑘 −𝑧𝑘 ) 𝑤𝑘𝑗 = − ∑𝐾
𝑘=1 𝑘 𝑤𝑘𝑗 (5.12)
𝜕𝑣𝑘
The modified weights of the hidden layer can be expressed as
𝜕𝑦𝑗
̅𝑗𝑖 + 𝜕𝑣̅ 𝑥𝑖 ∑𝐾
̅𝑗𝑖 ∗= 𝑤
𝑤 𝑘=1 𝑘 𝑤𝑘𝑗 (5.13)
𝑗
or
̅1
𝜕𝑦𝑗
̅𝑗 = ∑𝐾
𝜕𝑣̅𝑗 𝑘=1 𝑘
𝑤𝑘𝑗 = (∑𝐾
𝑘=1 𝑘 𝑤𝑘𝑗 )𝑓′(𝑣̅𝑗 ) where ̅ = [ ⋮ ]
̅𝐽−1
𝐖 ̅ − 𝜕𝐸 = 𝐖
̅ ∗= 𝐖 ̅ −̅𝐱 𝑇 where dim(𝐖
̅ )=(J−1, 1) (5.14)
𝜕𝐖
102
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
Example 5.2
The layered classifier shown in Figure 5.6 is trained to solve the following linearly
nonseparable patterns of XOR function.
0 0 1 1
𝐱1 = [ ] , 𝐱 2 = [ ] , 𝐱 3 = [ ] , 𝐱 4 = [ ]
0 1 1 0
𝑑1 = [−1], 𝑑2 = [1], 𝑑3 = [−1], 𝑑4 = [1]
Figure 5.6 Network diagram
The complete training cycle involves all patterns in the training set. Assume that the
initial weights are generated randomly, the cumulative cycle error is calculated for the
complete training cycle. It is then compared with the maximum error allowed. The
training cycles repeat until the cycle error drops below the specified maximum error
value. If the network has failed to learn the training set successfully, the training should be
restarted with different initial weights
All continuous perceptrons use the bipolar activation functions. Assume that = 0.1, a set
of initial random weights was found to provide correct solutions. The initial weight matrices
̅ 1 and the resulting weight matrices W𝑓 , W
W1 , W ̅ 𝑓 obtained after 250 cycles (1000 steps) are:
𝑊 1 = [−0.8568 0.3998 − 1.0702], 𝑊 2 = [−0.8217 0.4508 − 1.0164]
𝐖𝑓 = [−2.7662 3.0731 − 2.3080]
̅ 1 = [−6.9938
𝑊
6.6736 1.5555 ̅ 2
], 𝑊 = [
−6.9938 6.6736 1.5422
]
−4.2812 3.9127 3.6233 −4.2812 3.9127 3.6244
̅ 𝑓 = [−6.1974
𝐖
7.4970 −1.3308
]
−4.7861 5.2825 3.0159
103
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
Figure 5.7 shows the cycle error at each cycle.
Figure 5.7 Cycle error (Convergence rate)
Using the final weight matrices, input all the pattern x1 to x4, then the actual outputs 𝐳 =
[−0.7784 0.7678 −0.8743 0.7498]. Replacing the continuous output perceptron
with discrete output perceptron , e.g. TLU, the actual outputs 𝐳 = [−1 1 −1 1].
Since the network from Figure 5.6 is required to function as a classifier with binary
outputs, the continuous perceptrons should be replaced with discrete perceptrons.
Chapter 5.4 Learning Factors
5.4.1 Evaluate the network performance
The output error E in a network with K output can be calculated as:
1
𝐸 = ∑𝐾
𝑘=1(𝑑𝑘 − 𝑧𝑘 )
2
(5.15)
2
The accumulative error (cycle error) Ec can be calculated over the error back-propagation
training cycle of a network with P training patterns and K output neurons as:
1 2
𝐸𝑐 = ∑𝑃𝑝=1 ∑𝐾 𝑃
𝑘=1(𝑑𝑝𝑘 − 𝑧𝑝𝑘 ) = ∑𝑝=1 𝐸𝑝 (5.16)
2
The root-means-square normalised error Erms, which is more descriptive when
comparing the outcome of the training of different neural networks, can be defined as
104
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
1 2 1
𝐸𝑟𝑚𝑠 = √∑𝑃𝑝=1 ∑𝐾
𝑘=1(𝑑𝑝𝑘 − 𝑧𝑝𝑘 ) = √2𝐸𝑐 (5.17)
𝑃𝐾 𝑃𝐾
The back-propagation learning algorithm in which synaptic strengths are systematically
modified so that the response of the network increasingly approximate the desired
response can be interpreted as an optimisation problem. The generic criterion function
optimisation algorithm is simply negative gradient descent with a fixed step size. The
learning algorithm modifies the weight matrices so that the error value decreases.
The essence of the error back-propagation algorithm is the evaluation of the contribution of
each particular weight to the output error. This is often referred to as the problem of credit
assignment. One of the problems in the implementation of the algorithm is that it may produce
only a local minimum of the error function as illustrated in Figure 5.8. For a local minimum
to exist, all the weights must simultaneously be at a value from which a change in either
direction will increase the error. Although the negative gradient descent technique can
become stuck in local minima of the error function, in general these minima are not very deep,
it is usually sufficient to get out of local minima by inserting some form of randomness to the
training.
Figure 5.8 Minimisation of Erms as a function of single weights.
105
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
5.4.2 Initial Weights
The weights of the network to be trained are typically initialised at small random values.
The initialisation strongly affects the ultimate solution. The network may fail to learn the
training set with the error stabilising or even increasing as the learning continues. The
network learning should then be restarted with other random weights. In Figure 5.8, there
are 3 starting points (initial weights), only point 1 can meet the training goal (reach to
Erms,min). Points 2 and 3 are tapped into local minima.
5.4.3 Learning Constant
The effectiveness and convergence of the error back-propagation learning algorithm
depends heavily on the value of the learning constant . In general, there is no single
learning constant value suitable for different training cases. While gradient descent can be
an efficient method for obtaining the weight values which minimise an error, error surfaces
frequently possess properties that make the procedure slow to converge. A large value of
will result in a more rapid convergence, however with more risk of overshooting the
solution. Note that only small learning constant guarantee a true gradient descent. Typical
values for are ranging from 0.001 to 10.
Using the same Example 5.2, the learning rate of this example is set at 0.1 (=0.1),
compare the learning performance with different learning rates ( =0.01, 0.8, 5). A good
learning rate was found to be =0.8. The cycle errors for different learning rate is shown
in Figure 5.9.
Figure 5.9 The cycle errors for different learning rate ( =0.01, 0.1, 0.8, 5)
106
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
5.4.4 Adaptive Learning rate
The method of adaptive learning rates is much faster than steepest descent and is also very
dependable. Let there be a different learning rate for each weight in the network.
If the direction in which the error decreases at this weight change is the same as the
direction in which it has been decreasing recently, make larger.
If the direction in which the error currently decreases is the opposite of the recent direction,
make smaller.
[Reference:] Robert A. Jacobs, “Increased rates of convergence through learning rate
adaption,” Neural Networks, vol. 1, no. 4, pp. 295-307, 1998.
5.4.5 Momentum Method
The momentum method may be used to accelerate the convergence of the error back
propagation learning algorithm. The method involves supplementing the current weight
adjustments with a fraction of the most recent weight adjustment. The back-propagation
(steepest descent) algorithm with momentum term is:
𝐰 𝑘+1 = 𝐰 𝑘 + 𝐰 𝑘 + (𝐰 𝑘 − 𝐰 𝑘−1 ) or
(5.18)
𝐰 𝑘+1
= 𝐰 + y + (𝐰 − 𝐰
𝑘 𝑘 𝑘−1
)
Typically, is chosen between 0.1 and 0.9. The momentum term typically helps to speed
up convergence, and to achieve an efficient and more reliable profile. Note that 𝐰 0 =
𝐰1 .
107
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
Example 5.3
Using the set of initial random weights as in Example 5.2, a learning rate of = 0.8, a good
momentum constant was found to be ̅ 1 and the
= 0.4 . The initial weight matrices W1 , W
̅ 𝑓 obtained after 250 cycles (1000 steps) are:
resulting weight matrices W𝑓 , W
𝑊 1 = [−0.8568 0.3998 − 1.0702], 𝑊 2 = [−0.5763 0.8081 − 0.6395]
𝐖𝑓 = [−3.4800 3.7021 − 3.0417]
̅ 1 = [−6.9938 6.6736 1.5555 ̅ 2 −6.9938 6.6736 1.4493
𝑊 ], 𝑊 = [ ]
−4.2812 3.9127 3.6233 −4.2812 3.9127 3.6320
̅ 𝑓 = [−6.3004
𝐖
7.4248 −1.8632
]
−5.1667 5.7364 3.1251
back-propagation
without momentum
back-propagation
with momentum
Figure 5.10 The Cycle Error for back-propagation learning with momentum
Using the same example, different momentum constant values ( = 0.1, 0.4, 0.9) are chosen,
a good momentum constant was found to be = 0.4.
Figure 5.11 The Cycle Error for back-propagation learning with momentum with different
momentum constant values ( = 0.1, 0.4, 0.9)
108
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
5.4.6 Network Architecture and Data Representation
Consider a network with I input nodes, a single hidden layer of J neurons, and an output layer
consisting of K neurons as shown in Figure 5.12. The number of input nodes is simply
determined by the dimension of the input vector to be classified which is usually corresponds
to the number of distinct features of the input pattern.
Figure 5.12 A layered neural network
In the case of planar images, the size of the input vector is usually equal to the number of pixels
in the evaluated image. For example, the characters C, I, T can be represented on a 3 x 3 grid as
shown in Figure 5.13.
Figure 5.13 Representation of C, I and T
109
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
Necessary Number of Input Neurons
Assume that the size of the input vector is 9, three training vectors are required:
x1=[1 1 1 1 −1 −1 1 1 1]T :Class C
x2 =[−1 1 −1 −1 1 −1 −1 1 −1 ]T :Class I
x3=[1 1 1 −1 1 −1 −1 1 −1]T :Class T
Necessary Number of Output Neurons
For networks functioning as a classifier, the number of output neurons K can be made equal
to the number of classes. In such cases (local representation), the network would also perform
as a class decoder. Thus, number of output is K.
The number of output neurons K can sometimes be lowered if no class decoding is
required. Binary-coded or other encoded class numbers can be used (distributed
representation). For example, a 4-class classifier can be trained using only 2 output
neurons (00,01,10,11). Similarly, alphabet character classifiers would at least 5 output
neurons to classify 26 characters. Thus, number of output is log2K. (E.g. K=26, number of
output = log2(26) = 4.7 =5.
Necessary Number of Hidden Neurons
The size of hidden layer is one of the most important considerations when solving actual
problems using multi-layer feed-forward networks. Assume that the n-dimensional non-
augmented input space is linearly separable into M disjoint regions with boundaries being
parts of hyperplanes. Each of the M regions can be labelled as belonging to one of the R
classes, where RM .
Figure 5.14 Separable regions
110
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
Figure 5.14 shows an example separation for n=9, R=3 and M=7. Intuitively, the number of
separation regions M should be the lower bound on the size P of the training set ( P M ) .
There exists a relationship between M, J* and n. The maximum number of regions linearly
separable using J* hidden neurons in n-dimensional input space is given by:
(5.19)
(5.20)
For large size input vectors compared to the number of hidden nodes J*, or n J*, the number
of hidden nodes can be calculate from
M=2J* where J*=J−1 (5.21)
Given K output neurons, the maximum number of separated regions M partitioned by
K hyperplanes are
(5.22)
Example 5.4
Design and implement the classification of three printed characters C, I, and T as shown in
Figure using a single hidden layer network. The three input vectors and the target vectors
in the training set are chosen as:
x1=[1 1 1 1 −1 −1 1 1 1]T :Class C
x2 =[−1 1 −1 −1 1 −1 −1 1 −1 ]T :Class I
x3=[1 1 1 −1 1 −1 −1 1 −1]T :Class T
1 −1 −1
𝐝𝟏 = [−1] , 𝐝𝟐 = [ 1 ] , 𝐝𝟑 = [−1]
−1 −1 1
As shown in Figure 5.13, there are 3 classes (R=3) and then number of output neurons is 3
(K=3), the number of separation regions is 7 (M=7). The number of hidden nodes can be
calculated from equation M=2J* , 𝐽∗ = ⌈√7⌉, then J*= 3. Note that due to the necessary
augmentation of inputs and of the hidden layer by one fixed input, the trained network should
111
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
have 10 input nodes (I=10), 4 hidden nodes (J=4), 3 output nodes (K=3). Therefore
̅ )=(J−1,I )=(3,10)
dim(W)=(K,J)=(3,4) and dim(𝐖
In this example, all continuous perceptrons use the bipolar activation function. Using a set of
̅1
initial random weights and a learning constant of =0.8, The initial weight matrices 𝑊 1 , 𝑊
̅ 𝑓 obtained after 60 steps are:
and the final weight matrices 𝑊 𝑓 , 𝑊
Figure 5.15 Cycle Error for Example 5.4
112
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
Chapter 5.5 Batch Mode Training
In pattern mode training, the output weight matrix W and hidden weight matrix W are
updated after each pattern is presented. In batch mode training, increments are accumulated
and updating takes place at the end of each cycle (epoch) after all patterns have been
presented. Essentially, pattern mode training performs stochastic gradient or incremental
gradient search whereas batch mode training performs average gradient descent in the
weight space.
Examples 5.5:
The layered classifier shown in Figure 5.6 is trained in batch mode to solve the following
linearly nonseparable patterns of XOR function
0 0 1 1
𝐱1 = [ ] , 𝐱 2 = [ ] , 𝐱 3 = [ ] , 𝐱 4 = [ ]
0 1 1 0
𝑑1 = [−1], 𝑑2 = [1], 𝑑3 = [−1], 𝑑4 = [1]
Using the set of initial random weights as in Example 5.2, a good learning constant was
foundto be =0.8. The initial weight matrices are same as Example 5.2, and the resulting
̅ 𝑓 obtained after 50 cycles (200 steps) are:
(final) matrics 𝐖𝑓 and 𝐖
𝐖𝑓 = [−3.1856 3.4354 − 2.7244]
̅ 𝑓 = [−6.1454
𝐖
7.5729 −1.6690
]
−4.8755 5.4606 2.9841
Figure 5.16 shows the cycle error for Example 5.5.
Figure 5.16 Cycle error for Example 5.5
113
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
Chapter 5.6 Early Stopping Method of Training
In a typical situation, the mean-square error decreases with an increasing number of cycles
(or epochs) during training. With good generalisation as the goal, it is difficult to determine
when it is best to stop training if we only look at the learning curve. It is possible for the
network to end up overfitting the training data if the training session is not stopped at the right
point.
We may identify the onset of overfitting through the use of cross-validation in which the
training data are split into an estimation subset and a validation subset. The estimation subsets
is used to train the network in the usual way, except that the training session is stopped
periodically (every so many cycles), and the network is tested on the validation subset after
each period of training.
Figure 5.16 Early Stopping Method of Training
114
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
References
Bishop, C. M. 2000, Neural Networks for Pattern Recognition, Oxford University
Press, New York.
Brown, M., Harris C. 1994, Neurofuzzy Adaptive Modelling and Control, Prentice
Hall, Hertfordshire.
Hertz, J., Krogh, A., Palmer, R.G. 1991, Introduction to the Theoary of Neural
Computing, Addison-Wesley, Redwood City, California.
Kosko, B. 1992, Neural Networks and Fuzzy Systems, Prentice Hall, New Jersey.
Smith, M. 1993, Neural Networks for Statistical Modelling, Van Nostrand Reinhold, New
York.
Trieu, H.T., Nguyen, H.T., Willey, K. 2008, ‘Advanced Obstacle Avoidance for a Laser-
based Wheelchair using Optimised Bayesian Neural Networks’, 30th Annual International
Conference of the IEEE Engineering in Medicine and Biology Society,
20-24 August 2008, Vancouver, Canada, pp. 3463-3466.
Zurada, J.M. 1992, Introduction to Artificial Neural Systems, West Publishing
Company, St. Paul.
115
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
CHAPTER SIX
INTRODUCTION TO CONVOLUTIONAL NEURAL
NETWORKS
_______________________________________________________
Chapter 6.1 Motivation
As shown in the previous chapter, neural networks receive an input (a single vector), and
transform it through a series of hidden layers. Each hidden layer is made up of a set of
neurons, where each neuron is fully connected to all neurons in the previous layer, and where
neurons in a single layer function completely independently and do not share any
connections. The last fully-connected layer is called the “output layer” and in classification
settings it represents the class scores.
While regular neural networks do not scale well to full images. For example, for images are
only of size 32×32×3 (32 wide, 32 high, 3 color channels), a single fully-connected neuron
in a first hidden layer of a regular neural network would have 32*32*3 = 3072 weights. This
amount still seems manageable, but clearly this fully-connected structure does not scale to
larger images. For example, an image of more respectable size, e.g. 200×200×3, would lead
to neurons that have 200*200*3 = 120,000 weights. Moreover, we would almost certainly
want to have several such neurons, so the parameters would add up quickly! Clearly, this
full connectivity is wasteful, and the huge number of parameters would quickly lead to
overfitting. On the other hand, the spatial and structural correlations of the image pixels are
broken if flattening an image to a single vector as input. Therefore, the convolutional neural
networks (CNNs) are proposed.
Convolutional neural networks or CNNs, are a specialized kind of neural network for
processing data that has a known, grid-like topology. Convolutional Neural Networks are
very similar to ordinary neural networks from the previous chapter: they are made up of
neurons that have learnable weights and biases. Each neuron receives some inputs, performs
a dot product and optionally follows it with a non-linearity. The whole network still
expresses a single differentiable score function: from the raw image pixels on one end to
class scores at the other. And they still have a loss function (e.g. Softmax) on the last (fully-
116
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
connected) layer and all the tips/tricks we developed for learning regular neural networks
still apply.
CNN architectures make the explicit assumption that the inputs are images, which allows us
to encode certain properties into the architecture. These then make the forward function
more efficient to implement and vastly reduce the amount of parameters in the network.
Convolutional networks have been tremendously successful in practical applications.
Chapter 6.2 Architecture of Convolutional Neural Networks
The typical CNNs consist of three main layers: convolutional layer, pooling layer and fully-
connected layer. As shown in Figure 6.1, it is a classical CNN model, LeNet5. In this Figure,
C1, C3 and C5 are three convolution layers which compute the output of neurons that are
connected to local regions. S2 and S4 present the pooling/subsampling layers. F6 is a fully-
connected layer to compute the class scores. As last, the output can be obtained by the
classifier. In this chapter, we mainly introduce the Softmax classifier. We now describe the
individual layers and the details of their hyperparameters and their connectivities.
Figure 6.1 An example of CNN structure – LeNet5.
6.2.1 Convolutional Layer
The convolutional layer is the core building block of a convolutional network that does most
of the computational heavy lifting. It has three main characteristics, local connectivity,
spatial arrangement and parameter sharing.
117
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
6.2.1.1 Local Connectivity
When dealing with high-dimensional inputs such as images, it is impractical to connect
neurons to all neurons in the previous volume. Instead, we will connect each neuron to only
a local region of the input volume. The spatial extent of this connectivity is a hyperparameter
called the receptive field of the neuron (equivalently this is the filter size). The extent of the
connectivity along the depth axis is always equal to the depth of the input volume. It is
important to emphasize again this asymmetry in how we treat the spatial dimensions (width
and height) and the depth dimension: The connections are local in space (along width and
height), but always full along the entire depth of the input volume. For example, as shown
in Figure 6.2(a), suppose that the input volume has size [32×32×3]. If the receptive field (or
the filter size) is 5×5, then each neuron in the convolutional layer will have weights to a
[5×5×3] region in the input volume, for a total of 5*5*3 = 75 weights (and +1 bias parameter).
Notice that the extent of the connectivity along the depth axis must be 3, since this is the
depth of the input volume.
(a) (b)
Figure 6.2 Local Connectivity
As shown in the Figure 6.2 (b), the neurons from the neural network chapter remain
unchanged: They still compute a dot product of their weights with the input followed by a
non-linearity, but their connectivity is now restricted to be local spatially.
118
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
6.2.1.2 Spatial Arrangement
We have explained the connectivity of each neuron in the convolutional layer to the input
volume, but we haven’t yet discussed how many neurons there are in the output volume or
how they are arranged. Three hyperparameters control the size of the output volume: the
depth, stride and zero-padding. We discuss these next:
Depth: the depth of the output volume is a hyperparameter: it corresponds to the number of
filters we would like to use, each learning to look for something different in the input. For
example, if the first convolutional layer takes as input the raw image, then different neurons
along the depth dimension may activate in presence of various oriented edges, or blobs of
colour. We will refer to a set of neurons that are all looking at the same region of the input
as a depth column (some people also prefer the term fibre).
Stride: we must specify the stride with which we slide the filter. When the stride is 1 then
we move the filters one pixel at a time. When the stride is 2 (or uncommonly 3 or more,
though this is rare in practice) then the filters jump 2 pixels at a time as we slide them around.
This will produce smaller output volumes spatially.
Zero-padding: As we will soon see, sometimes it will be convenient to pad the input volume
with zeros around the border. The size of this zero-padding is a hyperparameter. The nice
feature of zero padding is that it will allow us to control the spatial size of the output volumes
(most commonly as we’ll see soon we will use it to exactly preserve the spatial size of the
input volume so the input and output width and height are the same).
We can compute the spatial size of the output volume as a function of the input volume size
(W), the receptive field size of the convolution layer neurons (F), the stride with which they
are applied (S), and the amount of zero padding used (P) on the border. You can convince
yourself that the correct formula for calculating the size of output volume Nout is given by:
(𝑊−𝐹+2𝑃)
𝑁𝑜𝑢𝑡 = +1 (6.1)
𝑆
119
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
For example, for a 7×7 input and a 3×3 filter with stride S=1 and zero padding P=0, we
would get a 5×5 output. With stride S=2 we would get a 3×3 output. The process is shown
in Figure 6.3.
(a) (b) (c)
Figure 6.3 Illustration of spatial arrangement.
In this example there is only one spatial dimension (x-axis), one neuron with a receptive field
size of F = 3, the input size is W = 5, and there is zero padding of P = 1. In Figure 6.3(a): The
neuron strides across the input in stride of S = 1, giving output of size (5 - 3 + 2)/1+1 = 5. In
Figure 6.3(b): The neuron uses stride of S = 2, giving output of size (5 - 3 + 2)/2+1 = 3.
Notice that stride S = 3 could not be used since it wouldn't fit neatly across the volume. In
terms of the equation (6.1), this can be determined since (5 - 3 + 2) = 4 is not divisible by 3.
The neuron weights are in this example [1, 0, −1] (shown in Fig. 6.3(c)), and its bias is zero.
These weights are shared across all yellow neurons (topper layer) in Figure 6.3.
Use of zero-padding: In the example of Figure 6.2(a), the input dimension was 5 and the
output dimension was equal (also 5). This worked out so because our receptive fields were 3
and we used zero padding of 1. If there was no zero-padding used, then the output volume
would have had spatial dimension of only 3, because that it is how many neurons would have
“fit” across the original input. In general, setting zero padding to be P=(F−1)/2 when the stride
is S=1 ensures that the input volume and output volume will have the same size spatially.
Constraints on strides: Note again that the spatial arrangement hyperparameters have mutual
constraints. For example, when the input has size W=10, no zero-padding is used P=0, and
the filter size is F=3, then it would be impossible to use stride S=2, since
(W−F+2P)/S+1=(10−3+0)/2+1=4.5, i.e. not an integer, indicating that the neurons don’t “fit”
120
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
neatly and symmetrically across the input. Therefore, this setting of the hyperparameters is
considered to be invalid, and a CNN library could throw an exception or zero pad the rest to
make it fit, or crop the input to make it fit, or something. Sizing the CNN appropriately so
that all the dimensions “work out” can be a real headache, which the use of zero-padding and
some design guidelines will significantly alleviate.
6.2.1.3 Parameter Sharing
Parameter sharing refers to using the same parameter for more than one function in a model.
In a traditional neural net, each element of the weight matrix is used exactly once when
computing the output of a layer. It is multiplied by one element of the input and then never
revisited. As a synonym for parameter sharing, one can say that a network has tied weights,
because the value of the weight applied to one input is tied to the value of a weight applied
elsewhere. In a convolutional neural net, each member of the kernel is used at every position
of the input (except perhaps some of the boundary pixels, depending on the design decisions
regarding the boundary). The parameter sharing used by the convolution operation means
that rather than learning a separate set of parameters for every location, we learn only one
set.
Parameter sharing scheme is used in Convolutional Layers to control the number of
parameters. Using the real-world example above, we see that there are 55*55*96 = 290400
neurons in the first Conv Layer, and each has 11*11*3 = 363 weights and 1 bias. Together,
this adds up to 290400*364 = 105,705,600 parameters on the first layer of the CNN alone.
Clearly, this number is very high.
It turns out that we can dramatically reduce the number of parameters by making one
reasonable assumption: That if one feature is useful to compute at some spatial position (x, y),
then it should also be useful to compute at a different position (x2, y2). In other words, denoting
a single 2-dimensional slice of depth as a depth slice (e.g. a volume of size [55×55×96] has
96 depth slices, each of size [55×55]), we are going to constrain the neurons in each depth
slice to use the same weights and bias. With this parameter sharing scheme, the first
convolutional layer in our example would now have only 96 unique set of weights (one for
each depth slice), for a total of 96*11*11*3 = 34,848 unique weights, or 34,944 parameters
121
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
(+96 biases). Alternatively, all 55*55 neurons in each depth slice will now be using the same
parameters. In practice during backpropagation, every neuron in the volume will compute the
gradient for its weights, but these gradients will be added up across each depth slice and only
update a single set of weights per slice.
Notice that if all neurons in a single depth slice are using the same weight vector, then the
forward pass of the conv layer can in each depth slice be computed as a convolution of the
neuron’s weights with the input volume (Hence the name: Convolutional Layer). This is why
it is common to refer to the sets of weights as a filter (or a kernel), that is convolved with the
input.
Note that sometimes the parameter sharing assumption may not make sense. This is especially
the case when the input images to a CNN have some specific centred structure, where we
should expect, for example, that completely different features should be learned on one side
of the image than another. One practical example is when the input are faces that have been
centred in the image. You might expect that different eye-specific or hair-specific features
could (and should) be learned in different spatial locations. In that case it is common to relax
the parameter sharing scheme, and instead simply call the layer a Locally-Connected Layer.
Summary. To summarize, the Conv Layer:
❖ Accepts a volume of size W1×H1×D1
❖ Requires four hyperparameters:
▪ Number of filters K,
▪ their spatial extent F,
▪ the stride S,
▪ the amount of zero padding P.
❖ Produces a volume of size W2×H2×D2 where:
▪ W2=(W1−F+2P)/S+1
▪ H2=(H1−F+2P)/S+1 (i.e. width and height are computed equally by
symmetry)
▪ D2=K
❖ With parameter sharing, it introduces F×F×D1 weights per filter, for a total
of (F×F×D1)⋅K weights and K biases.
122
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
❖ In the output volume, the d-th depth slice (of size W2×H2) is the result of performing
a valid convolution of the d-th filter over the input volume with a stride of S, and
then offset by d-th bias.
A common setting of the hyperparameters is F=3, S=1, P=1. However, there are common
conventions and rules of thumb that motivate these hyperparameters.
Example 6.1
This example shows how to get the value in the feature map based on the receptive field in
the input and the weights (convolution filter). We can see that the destination pixel =
∑9𝑖=1 𝑤𝑖 𝑥𝑖 =((−1×3)+ (0×0)+ (1×1)+ (−2×2)+ (0×6)+ (2×2)+ (−1×2)+ (0×4)+ (1×1))= −3.
Example 6.2
For an input image with size 5×5×3 (3 colour channels), since 3D volumes are hard to
visualize, all the volumes are visualized with each depth slice stacked in rows. The input
volume is of size W1=5, H1=5, D1=3, and the convolutional layer parameters are K=2, F=3,
S=2, P=1. That is, we have 2 filters of size 3×3 with a stride of 2. Therefore, the output volume
size has spatial size (5 − 3 + 2)/2 + 1 = 3. Moreover, notice that a padding of P=1 is applied
to the input volume, making the outer border of the input volume zero. The visualization
123
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
below iterates over the output activations, and shows that each element is computed by
elementwise multiplying the highlighted input with the filter, summing it up, and then
offsetting the result by the bias. Now, the size of input volume with zero-padding (P=1) is
7×7×3 and the three input images (with pad 1) are:
Given that the filter 0, W0 and bias b0 are:
and filter 1, W1 and bias b1 are:
Show that the output volume (3×3×2) is
6.2.2 Pooling Layer
A typical layer of a convolutional network consists of three stages. In the first stage, the layer
performs several convolutions in parallel to produce a set of linear activations. In the second
stage, each linear activation is run through a nonlinear activation function, such as the rectified
linear activation function. This stage is sometimes called the detector stage. In the third stage,
we use a pooling function to modify the output of the layer further.
124
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
A pooling function replaces the output of the net at a certain location with a summary statistic
of the nearby outputs. For example, the max pooling operation reports the maximum output
within a rectangular neighbourhood. Other popular pooling functions include the average of
a rectangular neighbourhood, the L2 norm of a rectangular neighbourhood, or a weighted
average based on the distance from the central pixel. The Figure 6.4 shows an example of the
process of max pooling. Pooling layer downsamples the volume spatially, independently in
each depth slice of the input volume. In Figure 6.4(a), the input volume of size [224×224×
64] is pooled with filter size 2, stride 2 into output volume of size [112×112×64]. Notice that
the volume depth is preserved. In Figure 6.4(b), the most common downsampling operation
is max, giving rise to max pooling, here shown with a stride of 2. That is, each max is taken
over 4 numbers (little 2×2 square).
(a) (b)
Figure 6.4 Illustration of max pooling.
In all cases, pooling helps to make the representation become approximately invariant to small
translations of the input. Invariance to translation means that if we translate the input by a
small amount, the values of most of the pooled outputs do not change. See Figure 6.5 for an
example of how this works. Figure 6.5(a) shows a view of the middle of the output of a
convolutional layer. The bottom row shows outputs of the nonlinearity. The top row shows
the outputs of max pooling, with a stride of one pixel between pooling regions and a pooling
region width of three pixels. Figure 6.5(b) shows a view of the same network, after the input
has been shifted to the right by one pixel. Every value in the bottom row has changed, but
125
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
only half of the values in the top row have changed, because the max pooling units are only
sensitive to the maximum value in the neighbourhood, not its exact location.
Invariance to local translation can be a very useful property if we care more about whether
some feature is present than exactly where it is. For example, when determining whether an
image contains a face, we need not know the location of the eyes with pixel-perfect accuracy,
we just need to know that there is an eye on the left side of the face and an eye on the right
side of the face. In other contexts, it is more important to preserve the location of a feature.
For example, if we want to find a corner defined by two edges meeting at a specific orientation,
we need to preserve the location of the edges well enough to test whether they meet.
(a)
(b)
Figure 6.5 Max pooling introduces invariance.
The use of pooling can be viewed as adding an infinitely strong prior that the function the
layer learns must be invariant to small translations. When this assumption is correct, it can
greatly improve the statistical efficiency of the network.
Pooling over spatial regions produces invariance to translation, but if we pool over the outputs
of separately parametrized convolutions, the features can learn which transformations to
become invariant to (see Figure. 6.6). A pooling unit that pools over multiple features that are
learned with separate parameters can learn to be invariant to transformations of the input.
Here we show how a set of three learned filters and a max pooling unit can learn to become
126
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
invariant to rotation. All three filters are intended to detect a hand-written “5”. Each filter
attempts to match a slightly different orientation of the “5”. When a “5” appears in the input,
the corresponding filter will match it and cause a large activation in a detector unit. The max
pooling unit then has a large activation regardless of which pooling unit was activated. We
show here how the network processes two different inputs, resulting in two different detector
units being activated. The effect on the pooling unit is roughly the same either way.
Figure 6.6 Example of learned invariances
Because pooling summarizes the responses over a whole neighbourhood, it is possible to use
fewer pooling units than detector units, by reporting summary statistics for pooling regions
spaced k pixels apart rather than 1 pixel apart. This improves the computational efficiency of
the network because the next layer has roughly k times fewer inputs to process. When the
number of parameters in the next layer is a function of its input size (such as when the next
layer is fully connected and based on matrix multiplication) this reduction in the input size
can also result in improved statistical efficiency and reduced memory requirements for storing
the parameters. For many tasks, pooling is essential for handling inputs of varying size. For
example, if we want to classify images of variable size, the input to the classification layer
must have a fixed size. This is usually accomplished by varying the size of an offset between
pooling regions so that the classification layer always receives the same number of summary
statistics regardless of the input size. For example, the final pooling layer of the network may
be defined to output four sets of summary statistics, one for each quadrant of an image,
regardless of the image size.
127
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
6.2.3 Fully-connected Layer
Neurons in a fully connected layer have full connections to all activations in the previous
layer, as seen in traditional neural networks (See Chapters 4-5). It can view as the final
learning phase, which maps extracted visual features to desired outputs. The output of fully-
connected layer is a vector, which is then passed through softmax to represent confidence of
classification.
6.2.4 Softmax
Softmax is a special kind of activation layer, usually at the end of fully-connected layer
outputs. It can be viewed as a fancy normalizer (a.k.a. Normalized exponential function).
It produces a discrete probability distribution vector and is very convenient when
combined with cross-entropy loss.
Given sample vector input x and weight vectors {wj}, the predicted probability of y = j
can be calculated by:
𝐰 𝑇𝐱
𝑒 𝑗
𝑃(𝑦 = 𝑗 | 𝐱) = 𝐰𝑘 𝑇 𝐱
(6.2)
∑𝐾
𝑘=1 𝑒
Figure 6.7 shows an example of the process of Softmax classifier, after calculating and
comparing the probability of each colour, the green colour has a highest probability value
compared with the other colours, and thus the final output of the classifier is green.
Figure 6.7 Illustration of the process of Softmax
128
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
Chapter 6.3 Optimization Algorithms for Training Deep Models
6.3.1 Stochastic Gradient Descent
We have previously introduced the gradient descent algorithm that follows the gradient of an
entire training set downhill. This may be accelerated considerably by using stochastic gradient
descent to follow the gradient of randomly selected minibatches downhill when the data size
is large.
Stochastic gradient descent (SGD) and its variants are probably the most used optimization
algorithms for machine learning in general and for deep learning in particular. It is possible
to obtain an unbiased estimate of the gradient by taking the average gradient on a minibatch
of m examples. Algorithm 6.1 shows how to follow this estimate of the gradient downhill.
Algorithm 6.1 Stochastic gradient descent (SGD) update at training iteration k
Require: Learning rate ϵk.
Require: Initial parameter θ.
while stopping criterion not met do
Sample a minibatch of m examples from the training set {𝒙(1) , ⋯ , 𝒙(𝑚) } with
corresponding targets 𝒚(𝑖) .
1
̂ ← +
Compute gradient estimate: 𝒈 ∇𝜽 ∑𝑖 𝐿(𝑓(𝒙(𝑖) ; 𝜽), 𝒚(𝑖) )
𝑚
̂
Apply update: 𝜽 ← 𝜽 − ϵ𝒈
end while
A crucial parameter for the SGD algorithm is the learning rate. Previously, we have described
SGD as using a fixed learning rate ϵ. In practice, it is necessary to gradually decrease the
learning rate over time, so we now denote the learning rate at iteration k as ϵk.
The most important property of SGD and related minibatch or online gradient based
optimization is that computation time per update does not grow with the number of training
examples. This allows convergence even when the number of training examples becomes very
129
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
large. For a large enough dataset, SGD may converge to within some fixed tolerance of its
final test set error before it has processed the entire training set.
6.3.2 Momentum
While stochastic gradient descent remains a very popular optimization strategy, learning with
it can sometimes be slow. The method of momentum is designed to accelerate learning,
especially in the face of high curvature, small but consistent gradients, or noisy gradients. The
momentum algorithm accumulates an exponentially decaying moving average of past
gradients and continues to move in their direction.
Formally, the momentum algorithm introduces a variable v that plays the role of velocity—it
is the direction and speed at which the parameters move through parameter space. The
velocity is set to an exponentially decaying average of the negative gradient. The name
momentum derives from a physical analogy, in which the negative gradient is a force moving
a particle through parameter space, according to Newton’s laws of motion. Momentum in
physics is mass times velocity. In the momentum learning algorithm, we assume unit mass,
so the velocity vector v may also be regarded as the momentum of the particle. A
hyperparameter α∈[0 ,1) determines how quickly the contributions of previous gradients
exponentially decay. The update rule is given by:
1
𝒗 ← α𝒗 − ϵ∇𝜽 ( ∑𝑚 𝐿(𝑓(𝒙(𝑖) ; 𝜽), 𝒚(𝑖) )) (6.3)
𝑚 𝑖=1
𝜽 ← 𝜽+𝒗 (6.4)
1
The velocity v accumulates the gradient elements ∇𝜽 ( ∑𝑚 𝐿(𝑓(𝒙(𝑖) ; 𝜽), 𝒚(𝑖) )). The
𝑚 𝑖=1
larger α is relative to ϵ, the more previous gradients affect the current direction. The SGD
algorithm with momentum is given in Algorithm 6.2.
130
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
Algorithm 6.2 Stochastic gradient descent (SGD) with momentum
Require: Learning rate ϵ, momentum parameter α.
Require: Initial parameter θ, initial velocity v.
while stopping criterion not met do
Sample a minibatch of m examples from the training set {𝒙(1) , ⋯ , 𝒙(𝑚) } with
corresponding targets 𝒚(𝑖) .
1
Compute gradient estimate: 𝒈 ← +
𝑚
∇𝜽 ∑𝑖 𝐿(𝑓(𝒙(𝑖) ; 𝜽), 𝒚(𝑖) )
Compute velocity update: 𝒗 ← α𝒗 − ϵ𝒈
Apply update: 𝜽 ← 𝜽 + 𝒗
end while
Previously, the size of the step was simply the norm of the gradient multiplied by the
learning rate. Now, the size of the step depends on how large and how aligned a sequence
of gradients are. The step size is largest when many successive gradients point in exactly
the same direction. If the momentum algorithm always observes gradient g, then it will
accelerate in the direction of −g, until reaching a terminal velocity where the size of each
𝜖‖𝒈‖
step is 1−𝛼
.
1
It is thus helpful to think of the momentum hyperparameter in terms of . For example,
1−𝛼
α = 0.9 corresponds to multiplying the maximum speed by 10 relative to the gradient
descent algorithm.
Common values of α used in practice include 0.5, 0.9, and 0.99. Like the learning rate, α
may also be adapted over time. Typically, it begins with a small value and is later raised.
It is less important to adapt α over time than to shrink ϵ over time.
131
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
6.3.3 Parameter initialization strategy
Some heuristics are available for choosing the initial scale of the weights. One heuristic
is to initialize the weights of a fully connected layer with m inputs and n outputs by
1 1
sampling each weight from 𝑈 (− , ) , while Glorot and Bengio (2010) suggest using
√m √ m
the normalized initialization.
6 6
W𝑖,𝑗 ~ 𝑈 (− , ) (6.5)
√𝑚+𝑛 √𝑚+𝑛
This latter heuristic is designed to compromise between the goal of initializing all layers
to have the same activation variance and the goal of initializing all layers to have the same
gradient variance. The formula is derived using the assumption that the network consists
only of a chain of matrix multiplications, with no nonlinearities. Real neural networks
obviously violate this assumption, but many strategies designed for the linear model
perform reasonably well on its nonlinear counterparts.
6.3.4 Algorithms with Adaptive Learning Rates
Neural network researchers have long realized that the learning rate was reliably one of
the hyperparameters that is the most difficult to set because it has a significant impact on
model performance. Because the cost is often highly sensitive to some directions in
parameter space and insensitive to others. The momentum algorithm can mitigate these
issues somewhat but does so at the expense of introducing another hyperparameter. In the
face of this, it is natural to ask if there is another way. If we believe that the directions of
sensitivity are somewhat axis-aligned, it can make sense to use a separate learning rate for
each parameter, and automatically adapt these learning rates throughout the course of
learning.
More recently, a number of incremental (or mini-batch-based) methods have been
introduced that adapt the learning rates of model parameters. This section will briefly
review a few of these algorithms.
132
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
6.3.4.1 AdaGrad
The AdaGrad algorithm, shown in Algorithm 6.3, individually adapts the learning rates of
all model parameters by scaling them inversely proportional to the square root of the sum
of all of their historical squared values. The parameters with the largest partial derivative
of the loss have a correspondingly rapid decrease in their learning rate, while parameters
with small partial derivatives have a relatively small decrease in their learning rate. The
net effect is greater progress in the more gently sloped directions of parameter space.
In the context of convex optimization, the AdaGrad algorithm enjoys some desirable
theoretical properties. However, empirically it has been found that—for training deep
neural network models—the accumulation of squared gradients from the beginning of
training can result in a premature and excessive decrease in the effective learning rate.
AdaGrad performs well for some but not all deep learning models.
Algorithm 6.3 The AdaGrad algorithm
Require: Global learning rate ϵ.
Require: Initial parameter θ.
Require: Small constant δ, perhaps 10−7, for numerical stability
Initialize gradient accumulation variable r = 0
while stopping criterion not met do
Sample a minibatch of m examples from the training set {𝒙(1) , ⋯ , 𝒙(𝑚) } with
corresponding targets 𝒚(𝑖) .
1
Compute gradient: 𝒈 ← + ∇𝜽 ∑𝑖 𝐿(𝑓(𝒙(𝑖) ; 𝜽), 𝒚(𝑖) )
𝑚
Accumulate squared gradient: 𝒓 ← 𝒓 + 𝒈 ⊙ 𝒈
𝜖
Compute update: ∆𝜽 ← − ⊙ 𝒈. (Division and square root applied element-
𝛿+√𝒓
wise)
Apply update: 𝜽 ← 𝜽 + ∆𝜽
end while
133
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
6.3.4.2 RMSProp
The RMSProp algorithm modifies AdaGrad to perform better in the non-convex setting
by changing the gradient accumulation into an exponentially weighted moving average.
AdaGrad is designed to converge rapidly when applied to a convex function. When
applied to a non-convex function to train a neural network, the learning trajectory may
pass through many different structures and eventually arrive at a region that is a locally
convex bowl. AdaGrad shrinks the learning rate according to the entire history of the
squared gradient and may have made the learning rate too small before arriving at such a
convex structure. RMSProp uses an exponentially decaying average to discard history
from the extreme past so that it can converge rapidly after finding a convex bowl, as if it
were an instance of the AdaGrad algorithm initialized within that bowl.
RMSProp is shown in its standard form in Algorithm 6.4. Compared to AdaGrad, the use
of the moving average introduces a new hyperparameter, ρ, that controls the length scale
of the moving average.
Algorithm 6.4 The RMSProp algorithm
Require: Global learning rate ϵ, decay rate ρ.
Require: Initial parameter θ.
Require: Small constant δ, perhaps 10−6, used to stabilize division by small numbers.
Initialize gradient accumulation variable r = 0
while stopping criterion not met do
Sample a minibatch of m examples from the training set {𝒙(1) , ⋯ , 𝒙(𝑚) } with
corresponding targets 𝒚(𝑖) .
1
Compute gradient: 𝒈 ← + ∇𝜽 ∑𝑖 𝐿(𝑓(𝒙(𝑖) ; 𝜽), 𝒚(𝑖) )
𝑚
Accumulate squared gradient: 𝒓 ← 𝜌𝒓 + (1 − 𝜌)𝒈 ⊙ 𝒈
𝜖 1
Compute update: ∆𝜽 ← − ⊙ 𝒈. ( applied element-wise)
𝛿+√𝒓 𝛿+√𝒓
Apply update: 𝜽 ← 𝜽 + ∆𝜽
end while
Empirically, RMSProp has been shown to be an effective and practical optimization
algorithm for deep neural networks. It is currently one of the go-to optimization methods
being employed routinely by deep learning practitioners.
134
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
6.3.4.3 Adam
Adam is yet another adaptive learning rate optimization algorithm and is presented in
Algorithm 6.5. The name “Adam” derives from the phrase “adaptive moments.” In the
context of the earlier algorithms, it is perhaps best seen as a variant on the combination of
RMSProp and momentum with a few important distinctions. First, in Adam, momentum
is incorporated directly as an estimate of the first order moment (with exponential
weighting) of the gradient. The most straightforward way to add momentum to RMSProp
is to apply momentum to the rescaled gradients. The use of momentum in combination
with rescaling does not have a clear theoretical motivation. Second, Adam includes bias
corrections to the estimates of both the first-order moments (the momentum term) and the
(uncentered) second-order moments to account for their initialization at the origin (see
Algorithm 6.5). RMSProp also incorporates an estimate of the (uncentered) second-order
moment, however it lacks the correction factor. Thus, unlike in Adam, the RMSProp
second-order moment estimate may have high bias early in training. Adam is generally
regarded as being fairly robust to the choice of hyperparameters, though the learning rate
sometimes needs to be changed from the suggested default.
6.3.4.4 Choosing the Right Optimization Algorithm
At this point, a natural question is: which algorithm should one choose? Unfortunately,
there is currently no consensus on this point. Currently, the most popular optimization
algorithms actively in use include SGD, SGD with momentum, RMSProp, RMSProp with
momentum, AdaDelta and Adam. The choice of which algorithm to use, at this point,
seems to depend largely on the user’s familiarity with the algorithm (for ease of
hyperparameter tuning).
135
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
Algorithm 6.5 The Adam algorithm
Require: Step size ϵ (Suggested default: 0.001).
Require: Exponential decay rates for moment estimates, ρ1 and ρ2 in [0, 1). (Suggested
defaults: 0.9 and 0.999 respectively)
Require: Small constant δ used for numerical stabilization. (Suggested default: 10−8)
Require: Initial parameter θ.
Initialize 1st and 2nd moment variables s = 0, r = 0
Initialize time step t = 0
while stopping criterion not met do
Sample a minibatch of m examples from the training set {𝒙(1) , ⋯ , 𝒙(𝑚) } with
corresponding targets 𝒚(𝑖) .
1
Compute gradient: 𝒈 ← +
𝑚
∇𝜽 ∑𝑖 𝐿(𝑓(𝒙(𝑖) ; 𝜽), 𝒚(𝑖) )
t←t+1
Update biased first moment estimate: 𝒔 ← 𝜌1 𝒔 + (1 − 𝜌1 )𝒈
Update biased second moment estimate: 𝒓 ← 𝜌2 𝒓 + (1 − 𝜌2 )𝒈 ⊙ 𝒈
𝒔
Correct bias in first moment: 𝒔̂ ←
1−𝜌1𝑡
𝒓
Correct bias in second moment: 𝒓̂ ←
1−𝜌2𝑡
𝒔̂
Compute update: ∆𝜽 = −𝜖 𝛿+√𝒓̂ (operations applied element-wise)
Apply update: 𝜽 ← 𝜽 + ∆𝜽
end while
6.3.5 Batch Normalization
Batch normalization (BN) makes networks robust to bad initialization of weights and
usually inserted right before activation layers. It can be able to reduce covariance shift by
normalizing and scaling inputs. The scale and shift parameters are trainable to avoid losing
stability of the network. The Algorithm 6.6 shows the BN transform which is applied to
activation x over a mini-batch.
136
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
Algorithm 6.6 Batch Normalization Transform
Input: Values of x over a mini-batch: 𝛣 = {𝑥1⋯𝑚 };
Parameters to be learned: 𝛾, 𝛽
Output: {𝑦𝑖 = 𝐁𝐍𝛾,𝛽 (𝑥𝑖 )}
1
μΒ ← ∑𝑚
𝑖=1 𝑥𝑖 // mini-batch mean
𝑚
1 2
𝜎 2Β ← ∑𝑚
𝑖=1(𝑥𝑖 − μΒ) // mini-batch variance
𝑚
𝑥𝑖 −μΒ
𝑥̂𝑖 ← // normalise
√𝜎2 Β+ϵ
𝑦𝑖 ← 𝛾𝑥̂𝑖 + 𝛽 ≡ 𝐁𝐍𝛾,𝛽 (𝑥𝑖 ) // scale and shift
References
Bottou, L. (1998). Online algorithms and stochastic approximations. In D. Saad, editor, Online
Learning in Neural Networks. Cambridge University Press, Cambridge, UK.
Duchi, J., Hazan, E., and Singer, Y. (2011). Adaptive subgradient methods for online learning
and stochastic optimization. Journal of Machine Learning Research.
Glorot, X. and Bengio, Y. (2010). Understanding the difficulty of training deep feedforward
neural networks. In AISTATS’2010.
Goodfellow, I. J., Warde-Farley, D., Mirza, M., Courville, A., and Bengio, Y. (2013a).
Maxout networks. In S. Dasgupta and D. McAllester, editors, ICML’13, pages 1319– 1327.
Hinton, G. (2012). Neural networks for machine learning. Coursera, video lectures.
Ioffe, S. and Szegedy, C. (2015). Batch normalization: Accelerating deep network training by
reducing internal covariate shift.
Kingma, D. and Ba, J. (2014). Adam: A method for stochastic optimization. arXiv preprint
arXiv:1412.6980.
Polyak, B. T. (1964). Some methods of speeding up the convergence of iteration methods.
USSR Computational Mathematics and Mathematical Physics, 4(5), 1–17.
Zhou, Y. and Chellappa, R. (1988). Computation of optical flow using a neural network. In
Neural Networks, 1988., IEEE International Conference on, pages 71–78. IEEE.
Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep learning. MIT press.
Johnson, J., Karpathy, A., & Fei-Fei, L. (2016). Cs231n: Convolutional neural networks for
visual recognition. Recuperado de: http://cs231n.github.io.
137
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
CHAPTER SEVEN
GENETIC ALGORITHMS
_______________________________________________________
Chapter 7.1 Introduction to Genetic Algorithm
One of the important issues on neural networks is the learning or training of the networks.
The learning process aims to find a set of optimal network parameters. Conventionally, two
major classes of learning methods, namely the error correction and gradient methods were
proposed (See Chapter 5). One major weakness of the gradient methods is that the derivative
information is necessary such that the error function to be minimized has to be continuous
and differentiable. Also, the learning process is easily trapped in a local optimum especially
when the problems are multimodal and the learning rules are network structure dependent.
To tackle this problem, some global search evolutionary algorithms (EAs), such as the genetic
algorithm (GA), are employed for searching in a large, complex, non-differentiable and
multimodal domain. Recently, neural or neural-fuzzy networks trained by GA are reported .
The same GA can be used to train many different networks regardless of whether they are
feed-forward, recurrent, or of other structure types. This generally saves a lot of human efforts
in developing training algorithms for different types of networks.
A GA for a particular problem must have the following five components:
• a genetic representation for potential solutions to the problem,
• a way to create an initial population of potential solutions,
• an evaluate function that plays the role of the environment, rating solutions in terms
of their “fitness”,
• genetic operators that alter the composition of children,
• values for various parameters that the genetic algorithm uses (population size,
probabilities of applying genetic operators, etc.).
The process of the genetic algorithm is shown in Fig. 7.1. The description is in the following
section (Section 7.1).
138
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
Procedure simple GA
begin
t→0 // : iteration generation
initialise V // Initial population V (see section 7.2.2)
eval (v) // Evaluate function, v is chromosome (see section 7.2.3)
while (not termination condition) do
begin
t→t+1
select 2 parents v 1 and v 2 from v using the selection operation
perform the crossover operation with probability pc (see section 7.2.4)
perform the mutation operation with probability pm (see section 7.2.5)
reproduce a new V // Reproduce new population V
eval (v )
end
end
Figure 7.1 Simple GA (binary-coded) process in pseudo-codes.
Chapter 7.2 Optimisation of a simple function
In this section we discuss the basic features of a genetic algorithm for optimisation of a simple
function of one variable. The function is defined as
f(x) = x sin(10 x)+1.0
and is drawn in Figure 7.2. The problem is to find x from the range [−1.. 2] which maximises
the function f, i.e., to find x0 such that
f(x0) f(x), for all x [−1.. 2].
Figure 7.2 Graph of the function f(x) = x sin(10 x)+1.0
139
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
Assume that we wish to construct a genetic algorithm to solve the above problem, i.e., to
maximise the function f. Let us discuss the major components of such a GA in turn.
7.2.1 Representation
We use a binary vector as a chromosome to represent real values of the variable x. The length
of the vector depends on the required precision, which, in this example, is six places after the
decimal points.
The domain of the variable x has length 3; the precision requirement implies that the range
[−1.. 2] should be divided into at least 3×1,000,000 equal size ranges. This means that 22 bits
are required as a binary vector (chromosome):
2097152=221 < 3000000 222 = 4194304.
The mapping from a binary string b21b20 … b0 into a real number x from the range [−1.. 2] is
straightforward and is completed in two steps:
• convert the binary string b21b20 … b0 from the base 2 to base 10:
(b21b20 … b0)2 = (∑21 𝑖
𝑖=10 𝑏𝑖 × 2 )10 = x,
• find a corresponding real number x:
3
𝑥 = −1.0 + 𝑥′ × ,
222 −1
where −1.0 is the left boundary of the domain and 3 is the length of the domain.
For example, a chromosome
(1000101110110101000111)
represents the number 0.637197, since
x=(1000101110110101000111)2 = 2288967
3
and 𝑥 = −1.0 + 2288967 ×
222 −1
= 0.637197.
Of course, the chromosomes
(0000000000000000000000) and (1111111111111111111111)
Represent boundaries of the domain, −1.0 and 2.0, respectively.
140
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
7.2.2 Initial population
The initialisation process is very simple: we create a population of chromosomes V, where
each chromosome v is a binary vector of 22 bits. All 22 bits for each chromosome are initialised
randomly.
7.2.3 Evaluation function
Evaluation function eval for binary vector v is equivalent to the function f:
eval(v) = f(x), (7.1)
where the chromosome v represents the real value x.
As noted earlier, the evaluation function plays the role of the environment, rating potential
solutions in terms of their fitness. For example, three chromosomes:
v1 = (1000101110110101000111),
v2 = (0000001110000000010000),
v3 = (1110000000111111000101),
correspond to values x1=0.637197, x2 = −0.958973, and x3 = 1.627888, respectively.
Consequently, the evaluation function would rate them as follows:
eval(v1) = f(x1) = 1.586345,
eval(v2) = f(x2) = 0.078878,
eval(v3) = f(x3) = 2.250650.
Clearly, the chromosome v3 is the best of the three chromosomes, since its evaluation returns
the highest value.
141
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
7.1.4 Genetic operators
During the alteration phase of the genetic algorithm we would use two classical genetic
operators: crossover and mutation.
Crossover Operator
Let us illustrate the crossover operator on chromosomes v2 and v3. Assume that the crossover
point was (randomly) selected after the 5 th gene:
v2 = (00000|01110000000010000),
v3 = (11100|00000111111000101),
The two resulting offspring are
v2 = (00000|00000111111000101),
v3 = (11100|01110000000010000),
These offspring evaluate to
eval(v2) = f(−0.998113) = 0.940865,
eval(v3) = f(1.666028) = 2.459245.
Note that the second offspring has a better evaluate than both of its parents.
Mutation Operator
Mutation alters one or more genes (positions in a chromosome) with a probability equal to the
mutation rate. Assume that the fifth gene from the v3 chromosome was selected for a mutation.
Since the fifth gene in this chromosome is 0, it would be flipped into 1. So the chromosome v3
after this mutation would be
v3 = (1110100000111111000101).
The chromosome represents the value x3 = 1.721638 and f(x3) = −0.082257. This means that
this particular mutation resulted in a significant decrease of the value of the chromosome v3.
On the other hand, of the 10th gene was selected for mutation in the chromosome v3, then
v3 = (1110000001111111000101).
The corresponding value x3 = 1.630818 and f(x3) = 2.343555, an improvement over the
original value of f(x3) = 2.250650.
142
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
7.2.5 Parameters
For this particular problem we have used the following parameters: population size pop_size
= 50, probability of crossover pc = 0.25, probability of mutation pm=0.01. The following section
presents some experimental results for such a genetic system.
7.2.6 Experimental results
In Table 7.1 we provide the generation number for which we noted an improvement in the
evaluation function, together with the value of the function. The best chromosome after 150
generations was
vmax=(1111001101000100000101),
which corresponds to a value xmax = 1.850773. Finally, we obtained xmax = 1.850773 and f(xmax)
= 2.850227 by using GA.
Table 7.1 Experimental results of 150 generations for function f(x) = x sin(10 x)+1.0 using
genetic algorithm
Generation Evaluation
Number function
1 1.441942
6 2.250003
8 2.250283
10 2.250363
12 2.328077
39 2.344251
40 2.345087
51 2.738930
99 2.849246
137 2.850217
145 2.850227
143
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
Chapter 7.3 Genetic Algorithms: How do they work?
In this session, we discuss the actions of a genetic algorithm for a simple parameter
optimisation problem. We start with a few general comments; a detailed example follows.
Let us note first that, without any loss of generality, we can assume maximisation problems
only. If the optimisation problem is to minimise a function f, this is equivalent to maximising
a function g where g = −f , i.e.,
min f(x) = max g(x) = max { −f(x) }. (7.2)
Moreover, we may assume that the objective function f takes positive values on its domain;
otherwise we can add some positive constant C, i.e.,
max g(x) = max{ g(x) +C}. (7.3)
Now suppose we wish to maximise a function of k variables, f(x1,… , xk):Rk→R. Suppose
further that each variable xi can take values from a domain Di = [ ai , bi] R and f(x1,… ,
xk)>0 for all xi Di. We wish to optimise the function f with some required precision: suppose
six decimal places for the variable’s values is desirable.
It is clear that to achieve such precision each domain Di should be cut into (bi − ai)×106 equal
size ranges. Let us denote by mi the smallest integer such that (bi − ai)×106 2𝑚𝑖 −1. Then, a
representation having each variable xi coded as a binary string of length mi clearly satisfies
the precision requirement. Additionally, the follow formula interprets each such string:
𝑏 −𝑎
xi = ai + decimal(1001…0012) × 2𝑖𝑚𝑖 −1𝑖 , (7.4)
where decimal(string2) represents the decimal value of that binary string.
Now, each chromosome (as a potential solution) is represented by a binary string of length
𝑚 = ∑𝑘𝑖=1 𝑚𝑖 ; the first m1 bits map into a value from the range [a1, b1], the next group of m2
bit map into a value from the range [a2, b2], so on; the last group of mk bit map into a value
from the range [ak, bk].
To initialise a population, we can simply set some pop_size number of chromosomes
randomly in a bitwise fashion. However, if we do have some knowledge about the distribution
of potential optima, we may use such information in arranging the set of initial (potential)
solutions.
144
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
The rest of the algorithm is straightforward: in each generation we evaluate each chromosome
(using the function f on the decoded sequences of variables), select new population with
respect to the probability distribution based on fitness values, and alter the chromosomes in
the new population by crossover and mutation operators. After some number of generations,
when no further improvement is observed, the best chromosome represents an (possibly the
global) optimal solution. Often we stop the algorithm after a fixed number of iterations
depending on speed and resource criteria.
For the selection process (selection of a new population with respect to the probability
distribution based on fitness values), a roulette wheel with slots sized according to fitness is
used. We construct such a roulette wheel as follows:
• Calculate the fitness value eval(vi) for each chromosome vi (i = 1, …, pop_size).
• Find the total fitness of the population
𝐹 = ∑𝑝𝑜𝑝_𝑠𝑖𝑧𝑒
𝑖=1 𝑒𝑣𝑎𝑙(𝒗𝑖 ). (7.5)
• Calculate the probability of a selection pi for each chromosome vi (i = 1, …, pop_size):
𝑝𝑖 = 𝑒𝑣𝑎𝑙(𝒗𝑖 )/𝐹. (7.6)
• Calculate a cumulative probability qi for each chromosome vi (i = 1, …, pop_size):
𝑞𝑖 = ∑𝑖𝑗=1 𝑝𝑗 . (7.7)
The selection process is based on spinning the roulette wheel pop_size times; each time we
select a single chromosome for a new population in the following way:
• Generate a random (float) number r from the range [0..1].
• If r < q1 then select the first chromosome (v1); otherwise select i-th chromosome vi (2
i pop_size) such that qi−1 < r < qi.
Obviously, some chromosomes would be selected more than once. The best chromosomes get
more copies, the average stay even, and the worst die off.
Now we are ready to apply the recombination operator, crossover, to the individuals in the
new population. As mentioned earlier, one of the parameters of a genetic algorithm is
probability of crossover pc. This probability gives us the expected number pc×pop_size of
chromosomes which undergo the crossover operation. We proceed in the following way:
For each chromosome in the (new) population:
• Generate a random (float) number r from the range [0..1];
• If r < pc, select given chromosome for crossover.
145
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
Now we mate selected chromosomes randomly: for each pair of coupled chromosomes we
generate a random integer number pos from the range [1..m−1] (m is the total length – number
of bits – in a chromosome). The number pos indicates the position of the crossing point. Two
chromosomes
(b1 b2… bpos bpos+1… bm) and
(c1 c2… cpos cpos+1… cm)
are replaced by a pair of their offspring:
(b1 b2… bpos cpos+1… cm) and
(c1 c2… cpos bpos+1… bm).
The next operator, mutation, is performed on a bit-by-bit basis. Another parameter of the
genetic algorithm, probability of mutation pm, given us the expected number of mutated bits
pm×m×pop_size. Every bit (in all chromosomes in the whole population) has an equal chance
to undergo mutation, i.e., change from 0 to 1 or vice verse. So we proceed in the following
way.
For each chromosome in the current (i.e., after crossover) population and for each bit within
the chromosome:
• Generate a random (float) number r from the range [0..1];
• If r < pm, mutate the bit.
Following selection, crossover, and mutation, the new population is ready for its next
evaluation. This evaluation is used to build the probability distribution (for the next selection
process), i.e., for a construction of a roulette wheel with slots sized according to current fitness
values. The rest of the evolution is just cyclic repetition of the above steps (see Figure 7.2).
Example 7.1
The whole process is illustrated by an example. We run a simulation of a genetic algorithm
for function optimisation. We assume that the population size pop_size = 20, and the
probabilities of genetic operators are pc=0.25 and pm=0.01.
Let us assume also that we maximise the following function:
f(x1,x2) = 21.5+ x1 sin(4 x1) + x2 sin(20 x2),
where −3.0 x1 12.1 and 4.1 x2 5.8. The graph of the function f is given in Figure 7.3.
146
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
Figure 7.3 Graph of the function f(x1,x2) = 21.5+ x1 sin(4 x1) + x2 sin(20 x2)
Let assume further that the required precision is four decimal places for each variable. The
domain of variable x1 has length 15.1; the precision requirement implies that the range [−3.0,
12.1] should be divided into at least 15.1×10000 equal size ranges. This means that 18 bits
are required as the first part of the chromosome:
217<151000218 .
The domain of variable x1 has length 1.7; the precision requirement implies that the range
[4.1, 5.8] should be divided into at least 1.7×10000 equal size ranges. This means that 15 bits
are required as the second part of the chromosome:
214<17000215 .
The total length of a chromosome (solution vector) is then m = 18+15 = 33 bits; the first 18
bits code x1 and remaining 15 bits code x2.
Let us consider an example chromosome:
(010001001011010000111110010100010).
The first 18 bits,
010001001011010000,
147
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
12.1 − (−3)
represent x1 = −3.0+decimal(010001001011010000)2 ×
218 −1
15.1
= −3+70352× = 1.052426.
262143
The next 15 bits,
111110010100010,
5.8 −4.1
represent x2 = −3.0+decimal(111110010100010)2 ×
215 −1
1.7
= 4.1+31906× = 5.755330.
32767
So the chromosome (010001001011010000111110010100010) corresponds to x1, x2 =
1.052426, 5.755330. The fitness value for this chromosome is
f(1.052426, 5.755330) = 20.252640.
To optimise the function f using a genetic algorithm, we create a population of pop_size = 20
chromosomes. All 33 bits in all chromosomes are initialised randomly.
Assume that after the initialisation process we get the following population:
v1 = (100110100000001111111010011011111)
v2 = (111000100100110111001010100011010)
v3 = (000010000011001000001010111011101)
v4 = (100011000101101001111000001110010)
v5 = (000111011001010011010111111000101)
v6 = (000101000010010101001010111111011)
v7 = (001000100000110101111011011111011)
v8 = (100001100001110100010110101100111)
v9 = (010000000101100010110000001111100)
v10= (000001111000110000011010000111011)
v11= (011001111110110101100001101111000)
v12= (110100010111101101000101010000000)
v13= (111011111010001000110000001000110)
v14= (010010011000001010100111100101001)
v15= (111011101101110000100011111011110)
v16= (110011110000011111100001101001011)
v17= (011010111111001111010001101111101)
v18= (011101000000001110100111110101101)
v19= (000101010011111111110000110001100)
v20= (101110010110011110011000101111110)
148
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
During the evaluation phase we decode each chromosome and calculate the fitness function
values from (x1, x2) values just decoded. We get:
eval(v1) = f (6.084492, 5.652242) = 26.019600
eval(v2) = f (10.348434, 4.380264) = 7.580015
eval(v3) = f (−2.516603, 4.390381) = 19.526329
eval(v4) = f (5.278638, 5.593460) = 17.406725
eval(v5) = f (−1.255173, 4.734458) = 25.341160
eval(v6) = f (−1.811725, 4.391937) = 18.100417
eval(v7) = f (−0.991471, 5.680258) = 16.020812
eval(v8) = f (4.910618, 4.703018) = 17.959701
eval(v9) = f (0.795406, 5.381472) = 16.127799
eval(v10)= f (−2.554851, 4.793707) = 21.278435
eval(v11)= f (3.130078, 4.996097) = 23.410669
eval(v12)= f (9.356179, 4.239457) = 15.011619
eval(v13)= f (11.134646, 5.378671) = 27.316702
eval(v14)= f (1.335944, 5.151378) = 19.876294
eval(v15)= f (11.089025, 5.054515) = 30.060205
eval(v16)= f (9.211598, 4.993762) = 23.867227
eval(v17)= f (3.367514, 4.571343) = 13.696165
eval(v18)= f (3.843020, 5.158226) = 15.414128
eval(v19)= f (−1.746635, 5.395584) = 20.095903
eval(v20)= f (7.935998, 4.757338) = 13.666916
It is clear, that the chromosome v15 is the strongest one, and the chromosome v2 is the weakest.
Now the system constructs a roulette wheel for the selection process. The total fitness of the
population (refer to equation (7.5)) is
𝐹 = ∑20
𝑖=1 𝑒𝑣𝑎𝑙(𝒗𝑖 ) = 387.776822.
The probability of a selection i (refer to equation (7.6)) for each chromosome vi (i = 1, …,
20) is :
1 = 𝑒𝑣𝑎𝑙(𝒗1 )/𝐹 = 0.067099 2 = 𝑒𝑣𝑎𝑙(𝒗2 )/𝐹 = 0.019547
3 = 𝑒𝑣𝑎𝑙(𝒗3 )/𝐹 = 0.050355 4 = 𝑒𝑣𝑎𝑙(𝒗4 )/𝐹 = 0.044889
5 = 𝑒𝑣𝑎𝑙(𝒗1 )/𝐹 = 0.065350 6 = 𝑒𝑣𝑎𝑙(𝒗2 )/𝐹 = 0.046677
7 = 𝑒𝑣𝑎𝑙(𝒗3 )/𝐹 = 0.041315 8 = 𝑒𝑣𝑎𝑙(𝒗4 )/𝐹 = 0.046315
9 = 𝑒𝑣𝑎𝑙(𝒗1 )/𝐹 = 0.041590 10 = 𝑒𝑣𝑎𝑙(𝒗2 )/𝐹 = 0.054873
11 = 𝑒𝑣𝑎𝑙(𝒗3 )/𝐹 = 0.060372 12 = 𝑒𝑣𝑎𝑙(𝒗4 )/𝐹 = 0.038712
13 = 𝑒𝑣𝑎𝑙(𝒗1 )/𝐹 = 0.070444 14 = 𝑒𝑣𝑎𝑙(𝒗2 )/𝐹 = 0.051257
15 = 𝑒𝑣𝑎𝑙(𝒗3 )/𝐹 = 0.077519 16 = 𝑒𝑣𝑎𝑙(𝒗4 )/𝐹 = 0.061549
17 = 𝑒𝑣𝑎𝑙(𝒗1 )/𝐹 = 0.035320 18 = 𝑒𝑣𝑎𝑙(𝒗2 )/𝐹 = 0.039750
19 = 𝑒𝑣𝑎𝑙(𝒗19 )/𝐹 = 0.051823 20 = 𝑒𝑣𝑎𝑙(𝒗20 )/𝐹 = 0.035244
149
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
The cumulative probabilities qi for each chromosome vi (i = 1, …, 20) are :
q1 = 0.067009 q2 = 0.086647 q3 = 0.137001 q4 = 0.181890
q5 = 0.247240 q6 = 0.293917 q7 = 0.335232 q8 = 0.381546
q9 = 0.423137 q10 = 0.478009 q11 = 0.538381 q12 = 0.577093
q13 = 0.647537 q14 = 0.698794 q15 = 0.776314 q16 = 0.837863
q17 = 0.873182 q18 = 0.912932 q19 = 0.964756 q20 = 1.000000
Now we are ready to spin the roulette wheel 20 times; each time we select a single
chromosome for a new population. Let us assume that a (random) sequence of 20 numbers
from the range [0..1] is:
0.513870 0.175741 0.308652 0.534534 0.947628
0.171736 0.702231 0.226431 0.494773 0.424720
0.703899 0.389647 0.277226 0.368071 0.983437
0.005398 0.765682 0.646473 0.767139 0.780237
The first number r = 0.513870 is greater than q10 and smaller than q11, meaning the
chromosome v11 is selected for the new population; the second number r = 175741 is greater
than q3 and smaller than q4, meaning the chromosome v4 is selected for the new population,
etc.
Finally, the new population consists of the following chromosomes:
v1 = (011001111110110101100001101111000) (v11)
v2 = (100011000101101001111000001110010) (v4)
v3 = (001000100000110101111011011111011) (v7)
v4= (011001111110110101100001101111000) (v11)
v5= (000101010011111111110000110001100) (v19)
v6 = (100011000101101001111000001110010) (v4)
v7= (111011101101110000100011111011110) (v15)
v8 = (000111011001010011010111111000101) (v5)
v9= (011001111110110101100001101111000) (v11)
v10 = (000010000011001000001010111011101) (v3)
v11= (111011101101110000100011111011110) (v15)
v12 = (010000000101100010110000001111100) (v9)
v13 = (000101000010010101001010111111011) (v6)
v14 = (100001100001110100010110101100111) (v8)
v15= (101110010110011110011000101111110) (v20)
v16 = (100110100000001111111010011011111) (v1)
v17= (000001111000110000011010000111011) (v10)
v18= (111011111010001000110000001000110) (v13)
v19= (111011101101110000100011111011110) (v15)
v20= (110011110000011111100001101001011) (v16)
150
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
Now we are ready to apply the recombination operator, crossover, to the individuals in the
new population (vectors vi). The probability of crossover pc=0.25, so we expect that (on
average) 25% of chromosomes (i.e., 5 out of 20) undergo crossover. We proceed in the
following way: for each chromosome in the (new) population we generate a random number
r from the range [0..1]; if r < 0.25, we select that the sequence of random number is:
0.822951 0.151932 0.625477 0.314685 0.346901
0.917204 0.519760 0.401154 0.606758 0.785402
0.031523 0.869921 0.166525 0.674520 0.758400
0.581893 0.389248 0.200232 0.355635 0.826927
This means that the chromosomes v2, v11, v13, v18 were selected for crossover. (We were
lucky: the number of selected chromosomes is even, so we can pair them easily. If the number
of selected chromosomes were odd, we would either add one extra chromosome or remove
one selected chromosome – this choice is made randomly as well.) Now we mate selected
chromosomes randomly: say, the first two (i.e., v2 and v11) and the next two (i.e., v13 and
v18) are coupled together. For each of these two pairs, we generate a random integer number
pos from the range [1..32] (33 is the total length – number of bits – in a chromosome). The
number pos indicates the position of the crossing point. The first pair of chromosome is
v2 = (100011000|101101001111000001110010)
v11= (111011101|101110000100011111011110)
and the generated number pos = 9. These chromosomes are cut after the 9th bit and replaced
by a pair of their offspring:
v2 = (100011000|101110000100011111011110)
v11= (111011101|101101001111000001110010)
The second pair of chromosomes is
v13 = (00010100001001010100|1010111111011)
v18= (11101111101000100011|0000001000110)
and the generated number pos = 20. These chromosomes are cut after the 9th bit and replaced
by a pair of their offspring:
v13 = (00010100001001010100|0000001000110)
v18= (11101111101000100011|1010111111011)
151
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
The current version of the population is:
v1 = (011001111110110101100001101111000)
v2 = (100011000101110000100011111011110)
v3 = (001000100000110101111011011111011)
v4= (011001111110110101100001101111000)
v5= (000101010011111111110000110001100)
v6 = (100011000101101001111000001110010)
v7= (111011101101110000100011111011110)
v8 = (000111011001010011010111111000101)
v9= (011001111110110101100001101111000)
v10 = (000010000011001000001010111011101)
v11= (111011101101101001111000001110010)
v12 = (010000000101100010110000001111100)
v13 = (000101000010010101001010111111011)
v14 = (100001100001110100010110101100111)
v15= (101110010110011110011000101111110)
v16 = (100110100000001111111010011011111)
v17= (000001111000110000011010000111011)
v18= (111011111010001000111010111111011)
v19= (111011101101110000100011111011110)
v20= (110011110000011111100001101001011)
The next operator, mutation, is performed on a bit-by-bit basis. The probability of mutation
pm = 0.01, so we expect that (on average) 1% of bits would undergo mutation. There are m ×
pop_size = 33×20 = 660 bits in the whole population; we expect (on average) 6.6 mutations
per generation. Every bit has an equal chance to be mutated, so, for every bit in the population,
we generate a random number r from the range [0..1]; if r < 0.01, we mutate the bit.
This means that we have to generate 660 random numbers. In a sample run, 5 of these numbers
were smaller than 0.01; the bit number and the random number are listed below:
Bit position Random number
112 0.000213
349 0.009945
418 0.008809
429 0.005425
602 0.002836
The following table translates the bit position into chromosome number and the bit number
within the chromosome:
152
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
Bit position Chromosome number Bit number within
chromosome
112 4 13
349 11 19
418 13 22
429 13 33
602 19 8
This means that four chromosomes are affected by the mutation operator; one of the
chromosomes (the 13th ) has two bits changed.
The final population is listed below; the mutated bits are typed in boldface. We drop primes
for modified chromosomes: the population is listed as new vectors vi:
v1 = (011001111110110101100001101111000)
v2 = (100011000101110000100011111011110)
v3 = (001000100000110101111011011111011)
v4= (011001111110110101100001101111000)
v5= (000101010011111111110000110001100)
v6 = (100011000101101001111000001110010)
v7= (111011101101110000100011111011110)
v8 = (000111011001010011010111111000101)
v9= (011001111110110101100001101111000)
v10 = (000010000011001000001010111011101)
v11= (111011101101101001111000001110010)
v12 = (010000000101100010110000001111100)
v13 = (000101000010010101001010111111011)
v14 = (100001100001110100010110101100111)
v15= (101110010110011110011000101111110)
v16 = (100110100000001111111010011011111)
v17= (000001111000110000011010000111011)
v18= (111011111010001000111010111111011)
v19= (111011101101110000100011111011110)
v20= (110011110000011111100001101001011)
We have just completed one iteration (i.e., one generation) of the while loop in the genetic
procedure (Figure 7.1). It is interesting to examine the results of the evaluation process of the
new population. During the evaluation phase we decode each chromosome and calculate the
fitness function values from (x1, x2) values just decoded.
153
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
We get:
eval(v1) = f (3.130078, 4.996097) = 23.410669
eval(v2) = f (5.279042, 5.054515) = 18.201083
eval(v3) = f (−0.991471, 5.680258) = 16.020812
eval(v4) = f (3.128235, 4.996097) = 23.412613
eval(v5) = f (−1.746635, 5.395584) = 20.095903
eval(v6) = f (5.278638, 5.593460) = 17.406725
eval(v7) = f (11.089025, 5.054515) = 30.060205
eval(v8) = f (−1.255173, 4.734458) = 25.341160
eval(v9) = f (3.130078, 4.996097) = 23.410669
eval(v10)= f (−2.516603, 4.390380) = 19.526329
eval(v11)= f (11.088621, 4.743434) = 33.351874
eval(v12)= f (0.785406, 5.381472) = 16.127799
eval(v13)= f (−1.811725, 4.209937) = 22.692462
eval(v14)= f (4.910618, 4.703018) = 17.959701
eval(v15)= f (7.935998, 4.757338) = 13.666916
eval(v16)= f (6.084492, 5.652242) = 26.019600
eval(v17)= f (−2.554851, 4.793707) = 21.278435
eval(v18)= f (11.134646, 5.666976) = 27.591064
eval(v19)= f (11.059532, 5.054515) = 27.608441
eval(v20)= f (9.211598, 4.993762) = 23.867227
The total fitness of the new population F is 447.049688, much higher than total fitness of the
previous population, 387.776822. Also, the best chromosome now (v11) has a better evaluate
(33.351874) than the best chromosome (v15) from the previous population (30.060205).
Now we are ready to run the selection process again and apply the genetic operators, evaluate
the next generation, etc. After 1000 generations the population is:
v1 = (111011110110011011100101010111011)
v2 = (111001100110000100010101010111000)
v3 = (111011110111011011100101010111011)
v4= (111001100010000110000101010111001)
v5= (111011110111011011100101010111011)
v6 = (111001100110000100000100010100001)
v7= (110101100010010010001100010110000)
v8 = (111101100010001010001101010010001)
v9= (111001100010010010001100010110001)
v10 = (111011110111011011100101010111011)
v11= (110101100000010010001100010110000)
v12 = (110101100010010010001100010110001)
v13 = (111011110111011011100101010111011)
v14 = (111001100110000100000101010111011)
v15= (111001101010111001010100110110001)
v16 = (111001100110000101000100010100001)
v17= (111001100110000100000101010111011)
v18= (111001100110000100000101010111001)
v19= (111101100010001010001110000010001)
v20= (111001100110000100000101010111001)
154
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
The fitness values are:
eval(v1) = f (11.120940, 5.092514) = 30.298543
eval(v2) = f (10.588756, 4.667358) = 26.869724
eval(v3) = f (11.124627, 5.092514) = 30.316575
eval(v4) = f (10.574125, 4.242410) = 31.933120
eval(v5) = f (11.124627, 5.092514) = 30.316575
eval(v6) = f (10.588756, 4.214603) = 34.356125
eval(v7) = f (9.631066, 4.427881) = 35.458636
eval(v8) = f (11.518106, 4.452835) = 23.309078
eval(v9) = f (10.574816, 4.427933) = 34.393820
eval(v10)= f (11.124627, 5.092514) = 30.316575
eval(v11)= f (9.623693, 4.427881) = 35.477938
eval(v12)= f (9.631066, 4.427933) = 35.456066
eval(v13)= f (11.124627, 5.092514) = 30.316575
eval(v14)= f (10.588756, 4.242514) = 32.932098
eval(v15)= f (10.606555, 4.653714) = 30.746768
eval(v16)= f (10.588814, 4.214603) = 34.359545
eval(v17)= f (10.588756, 4.242514) = 32.932098
eval(v18)= f (10.588756, 4.242410) = 32.956664
eval(v19)= f (11.518106, 4.472757) = 19.669670
eval(v20)= f (10.588756, 4.242410) = 32.956664
However, if we look carefully at the progress during the run, we may discover that in earlier
generations the fitness values of some chromosomes were better than the value 35.477938 of
the best chromosome after 1000 generations. For example, the best chromosome in generation
396 had value of 38.827553. It is relatively easy to keep track of the best individual in the
evolution process. It is customary to store “ the best ever” individual at a separate location; in
that way, the algorithm would report the best value found during the whole process (as
opposed to the best value in the final population).
Chapter 7.4 Real-coded Genetic Algorithms
In Chapters 7.1-7.2, binary coded genetic algorithm (BCGA) is discussed. The BCGA
has some drawbacks when applying to multidimensional, high-precision numerical problems.
For example, if 100 variables in the range [−500, 500] are involved, and a precision of 6 digits
after the decimal point is required, the length of the binary solution vector is 3000. This, in
turn, generates a search space of about 23000 points. The performance of the BCGA will then
be poor. The situation can be improved if the GA in real (floating-point) numbers is used.
Each chromosome is coded as a vector of floating point numbers of the same length as the
155
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
solution vector. We called it is a real-coded generic algorithm (RCGA). A large domain can
thus be handled (e.g. the parameter space of a neural network).
Procedure RCGA
begin
t→0 // t: iteration generation
initialise P // Initial population P
eval (p) // Evaluate fitness function
while (not termination condition) do
begin
t→t+1
select 2 parents p 1 and p 2 from p using the selection operation
perform the crossover operation with probability pc
perform the mutation operation with probability pm
reproduce a new P // Reproduce new population P
eval (p )
end
end
Figure 7.4 Real Coded GA process in pseudo-codes.
The process of the RCGA is same as BCGA which shown in Figure 7.4. Noting that to
distinguish the chromosome and the genes of a population, we use P represent the population
for RCGA instead of V for BCGA, p represent the chromosomes for RCGA instead of v for
BCGA. A population of chromosomes P is first initialised, where 𝑷=
[𝒑1 𝒑2 ⋯ 𝒑𝑝𝑜𝑝_𝑠𝑖𝑧𝑒 ] , pop _ size is the number of chromosomes in the population.
Each chromosome pi contains some genes (variables) pi j .
𝒑𝑖 = [𝑝𝑖1 𝑝𝑖2 ⋯ 𝑝𝑖𝑗 ⋯ 𝑝𝑖no_vars ] , i = 1, 2,…, pop _ size ; j = 1, 2, …, no_vars ,
(7.8)
j
paramin pi j paramax
j
, (7.9)
p max = para1max 2
paramax no _ vars
paramax , (7.10)
p m in = para 1m in para m2 in
para mnoin_ vars , (7.11)
𝑗 𝑗
where no_vars denotes the number of variables (genes); 𝑝𝑎𝑟𝑎𝑚𝑖𝑛 and 𝑝𝑎𝑟𝑎𝑚𝑎𝑥 are the
minimum and maximum values of 𝑝𝑖𝑗 respectively for all j.
156
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
The population evolves from generation 𝑡 to 𝑡 +1 by repeating the procedures as
follows. (1) Based on the selection operation, two parents (𝒑𝟏 and 𝒑𝟐 ) are selected from P in
such a way that the probability of selection is proportional to their fitness values. (2) A new
offspring is generated from these parents after undergoing the crossover and mutation
operations, which are governed by the probabilities of crossover (𝜇𝑐 ) and mutation (𝜇𝑚 ). (3)
The population thus generated replaces the current population. The above procedures are
repeated until a certain termination condition is satisfied. The termination condition may be
that the algorithm stops when a predefined number of iteration (generations) have been
processed.
Different genetic operations have been proposed to improve the efficiency of the RCGA.
Genetic operations usually refer to crossover and mutation.
7.4.1 Crossover operations
For the crossover operation, single-point crossover (SPX), the arithmetic crossover, blend-
crossover (BLX-) have been developed.
7.4.1.1 Single-point crossover
Single-point crossover exchanges information from two selected chromosomes (p1 and p2),
where
𝒑1 = [𝑝11 𝑝12 𝑝13 ⋯ 𝑝1𝑛𝑜_𝑣𝑎𝑟 ] (7.12)
𝒑2 = [𝑝21 𝑝22 𝑝23 ⋯ 𝑝2𝑛𝑜_𝑣𝑎𝑟 ] (7.13)
It generates a random integer number r from a uniform distribution from 1 to no_var, and
creates new offspring 𝒑1′ and 𝒑′2 as follows.
𝒑1′ = [𝑝′11 𝑝′1
2
⋯ 𝑝′1
𝑟
𝑝′2
𝑟+1
⋯ 𝑝′2
𝑛𝑜_𝑣𝑎𝑟 ] (7.14)
𝒑′2 = [𝑝′21 𝑝′2
2
⋯ 𝑝′2
𝑟
𝑝′1𝑟+1 ⋯ 𝑝′1𝑛𝑜_𝑣𝑎𝑟 ] (7.15)
no_var denotes the number of variables (genes) in a chromosome.
157
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
7.4.1.2 Arithmetic crossover
Arithmetic crossover is defined as a linear combination of two selected chromosomes (𝒑1 and
𝒑2 ). The resulting offspring 𝒑1′ and 𝒑′2 are defined as,
𝒑1′ = 𝐶𝑎𝑟𝑖𝑡ℎ × 𝒑1 + (1 − 𝐶𝑎𝑟𝑖𝑡ℎ ) × 𝒑2 (7.16)
𝒑′2 = 𝐶𝑎𝑟𝑖𝑡ℎ × 𝒑2 + (1 − 𝐶𝑎𝑟𝑖𝑡ℎ ) × 𝒑1 (7.17)
Obviously, this operation depends on a coefficient𝐶𝑎𝑟𝑖𝑡ℎ , which should be a constant when
the operation is a uniform convex crossover. Otherwise, if 𝐶𝑎𝑟𝑖𝑡ℎ ∈ [0 1] varies, it is a non-
uniform convex crossover.
7.4.1.3 Blend- crossover
Blend- crossover is defined as a combination of two selected parents 𝒑1 and 𝒑2 . The
resulting offspring 𝒑1′ is chosen randomly from the interval [𝑋𝑖1 , 𝑋𝑖2 ] following the uniform
distribution, where
𝑋𝑖1 = 𝑚𝑖𝑛(𝑝1 𝑖 , 𝑝2𝑖 ) − 𝛼𝑑𝑖 , (7.18)
𝑋𝑖2 = 𝑚𝑎𝑥(𝑝1 𝑖 , 𝑝2𝑖 ) + 𝛼𝑑𝑖 , (7.19)
where 𝑑𝑖 = |𝑝1𝑖 − 𝑝2𝑖 |, 𝑝1𝑖 and 𝑝2𝑖 are the i-th elements of 𝒑1 and 𝒑2 , respectively, and is a
positive constant.
7.4.2 Mutation operations
For the mutation operation, the uniform mutation (random mutation), the boundary mutation
and non-uniform mutation can be found.
158
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
7.4.2.1 Uniform mutation (Random mutation)
Uniform mutation is a simple random mutation operation. It randomly selects one
gene and sets it equal to a random number between its upper and lower bound. 𝑝1 =
[𝑝11 𝑝12 ⋯ 𝑝1𝑗 ⋯ ⋯ 𝑝1𝑛𝑜_𝑣𝑎𝑟 ] is a chromosome and a gene 𝑝1𝑗 is randomly
𝑗 𝑗
selected for mutation (the value of 𝑝′1𝑗 (mutated gene) is inside [𝑝𝑎𝑟𝑎𝑚𝑎𝑥 , 𝑝𝑎𝑟𝑎𝑚𝑖𝑛 ]), the
resulting chromosome is then given by 𝒑1′ = [𝑝11 𝑝12 ⋯ 𝑝′1
𝑗
⋯ ⋯ 𝑝1𝑛𝑜_𝑣𝑎𝑟 ], j
{1, 2, … no_vars}, and
𝑗 𝑗
𝑝′1𝑗 = 𝑈(𝑝𝑎𝑟𝑎𝑚𝑎𝑥 , 𝑝𝑎𝑟𝑎𝑚𝑖𝑛 ), (7.20)
𝑗 𝑗
where 𝑈(𝑝𝑎𝑟𝑎𝑚𝑎𝑥 , 𝑝𝑎𝑟𝑎𝑚𝑖𝑛 ) is random number between the upper and lower bounds.
7.4.2.2 Non-uniform mutation
Non-uniform mutation is an operation with a fine-tuning capability. Its action depends
on the generation number of the population. The operation takes place as follows. If 𝑝1 =
[𝑝11 𝑝12 ⋯ 𝑝1𝑗 ⋯ ⋯ 𝑝1𝑛𝑜_𝑣𝑎𝑟 ] is a chromosome and the gene 𝑝1 is randomly 𝑗
𝑗 𝑗
selected for mutation (the value of 𝑝′1𝑗 (mutated gene) is inside [𝑝𝑎𝑟𝑎𝑚𝑎𝑥 , 𝑝𝑎𝑟𝑎𝑚𝑖𝑛 ]), the
resulting chromosome is then given by 𝒑1′ = [𝑝11 𝑝12 ⋯ 𝑝′1
𝑗
⋯ ⋯ 𝑝1𝑛𝑜_𝑣𝑎𝑟 ], j
{1, 2, … no_vars}, and
𝑗
𝑝1𝑗 + 𝛥 (𝑡, 𝑝𝑎𝑟𝑎𝑚𝑎𝑥 − 𝑝1𝑗 ) if 𝑟𝑑 = 0
𝑝′1𝑗 = { 𝑗
, (7.21)
𝑝1𝑗 − 𝛥 (𝑡, 𝑝1𝑗 − 𝑝𝑎𝑟𝑎𝑚𝑖𝑛 ) if 𝑟𝑑 = 1
where 𝑟𝑑 is a random number equal to 0 or 1 only. The function 𝛥(𝑡, 𝑦) returns a value in the
range [0, y] such that 𝛥(𝑡, 𝑦) approaches 0 as t increases. It is defined as follows.
𝑡 𝜁𝑛𝑢𝑚
(1− )
𝛥(𝑡, 𝑦) = 𝑦 (1 − 𝑟 𝑇 ), (7.22)
where r is a random number in range of [0, 1], t is the present generation number of the
population, T is the maximum generation number of the population, and 𝜁𝑛𝑢𝑚 is a system
parameter that determines the degree of non-uniformity.
159
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
Chapter 7.5 Training the neural network using Genetic Algorithm
One of the important issues on neural networks is the learning or training of the networks.
The learning process aims to find a set of optimal network parameters. One major weakness
of the gradient methods is that the derivative information is necessary such that the error
function to be minimized has to be continuous and differentiable. Also, the learning process
is easily trapped in a local optimum especially when the problems are multimodal and the
learning rules are network structure dependent. To tackle this problem, some global search
evolutionary algorithms (EAs), such as the genetic algorithm (GA), are employed for
searching in a large, complex, non-differentiable and multimodal domain.
For a single layer neural network shown in Figure. 7.5, the output of network is
governed by:
𝑤11 ⋯ 𝑤1𝐽
𝒛 = 𝜞(𝐖𝐲) where 𝐖 = [ ⋮ ⋱ ⋮ ] (7.23)
𝑤𝐾1 ⋯ 𝑤𝐾𝐽
y denotes input vector, z denotes output vector, W denotes the weight matrix, d denotes
desired output and (v) denotes non-linear operator respectively.
𝑦1 𝑧1 𝑑1 𝑤11 ⋯ 𝑤1𝐽
𝑦2 𝑧
𝐲 = [ … ], 𝐳 = [ …2 ], 𝐝 = [ 𝑑…2 ], 𝐖 = [ ⋮ ⋱ ⋮ ]
𝑦𝐽 𝑧𝐾 𝑑𝐾 𝑤𝐾1 ⋯ 𝑤𝐾𝐽
The objective of the Genetic Algorithm (GA) is used to optimise the W to minimise the mean
square error of the application.
The fitness (evaluate) function is defined as,
1
𝑓𝑖𝑡𝑛𝑒𝑠𝑠 = (7.24)
1+𝑒𝑟𝑟
1
𝑒𝑟𝑟 = ∑𝐾
𝑖=1(𝑑𝑖 − 𝑧𝑖 )
2
(7.25)
𝐾
The objective is to maximize the fitness value of (7.24) using the GA by setting the
chromosome to be [𝑤11 … 𝑤𝑘𝑗 … 𝑤𝐾𝐽 ] for all j, k. It can be seen from (7.24) and (7.25)
that a larger fitness value implies a smaller error value.
160
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
lOMoARcPSD|27553903
49275 Neural Networks and Fuzzy Logic
Figure 7.5 Single-layer neural network
References
Eshelman, L. J. and Schaffer, J. D. 1993, Real-coded genetic algorithms and interval-
schemata, Foundations of Genetic Algorithms, pp. 187-202.
Michalewicz, Z. 1996, Genetic Algorithm + Data Structures=Evolution Programs,
Spring-Verlag Berlin.
Ling, S.H. 2010, Genetic Algorithm and Variable Neural Networks: Theory and Application,
Lambert Academic Publishing.
161
Downloaded by Phúc Nguy?n (hphuc4499@gmail.com)
You might also like
- Mixed-Signal-Electronics: PD Dr.-Ing. Stephan HenzlerDocument26 pagesMixed-Signal-Electronics: PD Dr.-Ing. Stephan HenzlerAhmed HamoudaNo ratings yet
- Yanr MLSDocument11 pagesYanr MLSdignor.sign3941No ratings yet
- Smitch ChartDocument3 pagesSmitch ChartBharat ChNo ratings yet
- Modulation and Coding Project: DVB-S2 Communication Chain: Quentin Bolsee Huong Nguyen Ilias Fassi-Fihri May 18, 2016Document15 pagesModulation and Coding Project: DVB-S2 Communication Chain: Quentin Bolsee Huong Nguyen Ilias Fassi-Fihri May 18, 2016HuongNguyenNo ratings yet
- Timer ParametersDocument4 pagesTimer ParametersOJ ACNo ratings yet
- Effectiveness-NTU Curves For Shell and Tube Heat Exchangers: Min MaxDocument2 pagesEffectiveness-NTU Curves For Shell and Tube Heat Exchangers: Min MaxKwark SangNo ratings yet
- An Efficient IDS Using FIS To Detect DDoS in IoT Networks - Slide - NicsDocument26 pagesAn Efficient IDS Using FIS To Detect DDoS in IoT Networks - Slide - NicsTuấn AnnhNo ratings yet
- LTE FDD MIMO Technology: ZTE UniversityDocument33 pagesLTE FDD MIMO Technology: ZTE UniversityjedossousNo ratings yet
- Datasheet c5707Document5 pagesDatasheet c5707amernasserNo ratings yet
- ECE333 Renewable Energy Systems 2015 Lect10Document30 pagesECE333 Renewable Energy Systems 2015 Lect10rdelgranadoNo ratings yet
- p4f Mockup v3Document1 pagep4f Mockup v3beisenbergNo ratings yet
- Real-Time, Scalable Epistemologies For Checksums: Florin SalamDocument4 pagesReal-Time, Scalable Epistemologies For Checksums: Florin SalamcatarogerNo ratings yet
- 8x2 LCD DatasheetDocument1 page8x2 LCD DatasheetSENTES CONSTANTIN100% (1)
- Latching and UnlatchingDocument12 pagesLatching and UnlatchingOJ ACNo ratings yet
- 2sc5585, 2sc5663 RohmDocument4 pages2sc5585, 2sc5663 RohmRe Ma (Master)No ratings yet
- Experiment No 13 AnalogDocument6 pagesExperiment No 13 AnalogMohsin TariqNo ratings yet
- System AnalysisDocument18 pagesSystem AnalysisRobCharlyNo ratings yet
- Process Management Interface - ExascaleDocument19 pagesProcess Management Interface - ExascaleSudhakar LakkarajuNo ratings yet
- Design of Source Degenerated Cascode Dual FunctionDocument25 pagesDesign of Source Degenerated Cascode Dual Functionmaia.df11No ratings yet
- A General Approach To Sensitivity AnalysisDocument37 pagesA General Approach To Sensitivity AnalysisjimmymorelosNo ratings yet
- Neural Network & Fuzzy Logic SRMDocument42 pagesNeural Network & Fuzzy Logic SRMharipriyailangoNo ratings yet
- RC1602D DatasheetDocument1 pageRC1602D DatasheetAmr Ayuob SalemNo ratings yet
- IMX1Document4 pagesIMX1prnchaNo ratings yet
- Datasheet Encoder 9720 V02-1747EN-952646Document12 pagesDatasheet Encoder 9720 V02-1747EN-952646HGL PrintNo ratings yet
- Datasheet k104Document3 pagesDatasheet k104Luigi PortugalNo ratings yet
- Refinement of Context-Free GrammarDocument4 pagesRefinement of Context-Free GrammarSreekar SahaNo ratings yet
- MIP301Document3 pagesMIP301tvtecnico2011No ratings yet
- Cluster Based Hierarchical Routing Protocol For Wireless Sensor NetworkDocument4 pagesCluster Based Hierarchical Routing Protocol For Wireless Sensor Networkvol2no5No ratings yet
- BRUCE:Standing (0:12) : 7 / Kalpana / 47 Yrs / Female / 155 CM / 68 KGDocument11 pagesBRUCE:Standing (0:12) : 7 / Kalpana / 47 Yrs / Female / 155 CM / 68 KGeven.hebbalNo ratings yet
- Ijest12 04 10 100Document8 pagesIjest12 04 10 100Carmina IlieNo ratings yet
- Raystar Optronics, Inc.: RC2002A Character 20x2Document1 pageRaystar Optronics, Inc.: RC2002A Character 20x2Zeyad AymanNo ratings yet
- 1979 Bookmatter DigitalTechniquesDocument8 pages1979 Bookmatter DigitalTechniquesJayant KoshtiNo ratings yet
- Schottky Barrier Diode RB088B150Document5 pagesSchottky Barrier Diode RB088B150rosvm rosvmNo ratings yet
- sin (2 πt+π 2) sin (2 πt−π 2)Document13 pagessin (2 πt+π 2) sin (2 πt−π 2)Huba KhalidNo ratings yet
- "Introduction To Communication Systems": Chapter-1Document16 pages"Introduction To Communication Systems": Chapter-1Mohamed SaeeDNo ratings yet
- Droid Slam SupplementalDocument4 pagesDroid Slam SupplementalGeorge PachitariuNo ratings yet
- Lab 5Document7 pagesLab 5qpqp1939No ratings yet
- IC Report1 Damp 1 PDFDocument26 pagesIC Report1 Damp 1 PDFLautaroNo ratings yet
- 100ma / - 50V Digital Transistors (With Built-In Resistors) : DTA123EM / DTA123EE / DTA123EUA / DTA123EKADocument3 pages100ma / - 50V Digital Transistors (With Built-In Resistors) : DTA123EM / DTA123EE / DTA123EUA / DTA123EKAahmad sulaimanNo ratings yet
- MECH3780 Fluid Mechanics 2 and CFD: Computation Fluid Dynamics (CFD) Lecture 6 - Evaluation of Numerical SolutionsDocument12 pagesMECH3780 Fluid Mechanics 2 and CFD: Computation Fluid Dynamics (CFD) Lecture 6 - Evaluation of Numerical SolutionsninibearNo ratings yet
- CH4-Root Locus Design PDFDocument11 pagesCH4-Root Locus Design PDFLove StrikeNo ratings yet
- AN010 - CT's Specification Guidelines For Pro-N, Xmore & Smart - 11 - 2022 PDFDocument12 pagesAN010 - CT's Specification Guidelines For Pro-N, Xmore & Smart - 11 - 2022 PDFPrje AccNo ratings yet
- Rpi-574 Rohm Phot InterrupterDocument4 pagesRpi-574 Rohm Phot InterrupterxxNo ratings yet
- Features: Voltage 100 V 10.0 Amp Schottky Barrier Rectifiers Elektronische BauelementeDocument2 pagesFeatures: Voltage 100 V 10.0 Amp Schottky Barrier Rectifiers Elektronische Bauelementefahmy najibNo ratings yet
- مختبر الكترونيات تجربة 2Document8 pagesمختبر الكترونيات تجربة 2أحمد الحريريNo ratings yet
- Data Sheet: Low VF Switching DiodeDocument7 pagesData Sheet: Low VF Switching DiodeCess FaridilNo ratings yet
- Marco Vardaro - PHD Thesis - 2018 01 14 (168-192)Document25 pagesMarco Vardaro - PHD Thesis - 2018 01 14 (168-192)mjd rNo ratings yet
- Safety CultureDocument11 pagesSafety CultureSam SunNo ratings yet
- PID Loop Simulator AutomationforumDocument8 pagesPID Loop Simulator Automationforumboyievmuhriddin5No ratings yet
- Paper 04Document6 pagesPaper 04HarukiNo ratings yet
- Revision Control: Details Accepted Prepared Rev Date Rev NRDocument31 pagesRevision Control: Details Accepted Prepared Rev Date Rev NRRupam BaruahNo ratings yet
- Lab #6 Proton NMR AnalysisDocument9 pagesLab #6 Proton NMR AnalysisSanta GreyNo ratings yet
- Dtlab 6Document12 pagesDtlab 6HaiderNo ratings yet
- Key Unification of Scatter Gather IO and DHTsDocument4 pagesKey Unification of Scatter Gather IO and DHTsGathNo ratings yet
- CompstatvalidationDocument151 pagesCompstatvalidationFrancisco Mateo ElguedaNo ratings yet
- All ResultsDocument29 pagesAll ResultsAndrew EwersNo ratings yet
- DownloadDocument3 pagesDownloadCloakManiaNo ratings yet
- Introduction To Logic Gates and Circuit Design: Hernandez, John Patrick A. EE-3104 Intended Learning OutcomesDocument17 pagesIntroduction To Logic Gates and Circuit Design: Hernandez, John Patrick A. EE-3104 Intended Learning OutcomesJohn Patrick HernandezNo ratings yet
- The Effect of Event-Driven Models On TheoryDocument3 pagesThe Effect of Event-Driven Models On TheorygarthogNo ratings yet
- Embedded SoPC Design with Nios II Processor and Verilog ExamplesFrom EverandEmbedded SoPC Design with Nios II Processor and Verilog ExamplesNo ratings yet
- Bilingualism and Second Language AcquisitionDocument27 pagesBilingualism and Second Language Acquisitionlaode rioNo ratings yet
- A Mini Project Report Tic Tac ToeDocument11 pagesA Mini Project Report Tic Tac ToekapuNo ratings yet
- Computational Learning Theory by Safdar KhanDocument10 pagesComputational Learning Theory by Safdar Khanskhan_wah897No ratings yet
- Cs8492 Database Management Systems 359992518 DbmsDocument149 pagesCs8492 Database Management Systems 359992518 DbmsK.KAMALNATHNo ratings yet
- AI Lecture+18+ Expert+SystemsDocument51 pagesAI Lecture+18+ Expert+SystemsM MNo ratings yet
- Overshoot (Signal) - Wikipedia, The Free EncyclopediaDocument5 pagesOvershoot (Signal) - Wikipedia, The Free EncyclopediadediekosNo ratings yet
- PIDDocument17 pagesPIDFlorian Pjetri100% (1)
- Classification and Clustering (HAREN SHARMA (03529802018) )Document9 pagesClassification and Clustering (HAREN SHARMA (03529802018) )VishalNo ratings yet
- Glocal-K: Global and Local Kernels For Recommender Systems: Soyeon Caren Han Taejun Lim Siqu LongDocument5 pagesGlocal-K: Global and Local Kernels For Recommender Systems: Soyeon Caren Han Taejun Lim Siqu LongD20DIT084 JAY PATELNo ratings yet
- Bag of Tricks For Efficient Text Classification: Armand Joulin Edouard Grave Piotr Bojanowski Tomas MikolovDocument5 pagesBag of Tricks For Efficient Text Classification: Armand Joulin Edouard Grave Piotr Bojanowski Tomas Mikolovaarthi devNo ratings yet
- Gujarat Technological UniversityDocument3 pagesGujarat Technological Universityrashmin tannaNo ratings yet
- Text Analytics and Text Mining OverviewDocument16 pagesText Analytics and Text Mining OverviewShivangi PatelNo ratings yet
- English 4 It Praktyczny Kurs Jezyka Angielskiego Dla Specjalistow It I Nie Tylko Beata BlaszczykDocument30 pagesEnglish 4 It Praktyczny Kurs Jezyka Angielskiego Dla Specjalistow It I Nie Tylko Beata BlaszczykAniaBrakowskaNo ratings yet
- Hardware Implementation Design of Partially Parallel Clustering System Based On Fuzzy Art Using LabviewDocument2 pagesHardware Implementation Design of Partially Parallel Clustering System Based On Fuzzy Art Using LabviewPavloNo ratings yet
- Module 3 Slides PDFDocument65 pagesModule 3 Slides PDFyashar2500No ratings yet
- Physical Symbol SystemDocument5 pagesPhysical Symbol SystemKostasBaliotisNo ratings yet
- 5th Sem AI 2023-24Document84 pages5th Sem AI 2023-24Nandyala Venkanna BabuNo ratings yet
- Xiong Qiang 2007Document142 pagesXiong Qiang 2007verna85mNo ratings yet
- Artificial Neural Network - Genetic Algorithm - TutorialspointDocument2 pagesArtificial Neural Network - Genetic Algorithm - Tutorialspointprabhuraaj101No ratings yet
- AlgorithmsDocument30 pagesAlgorithmsjose manuel gomez jimenezNo ratings yet
- The Use of Arduino Interface and Date Palm (Phoenix Dactylifera) Seeds in Making An Improvised Air Ionizer-PurifierDocument7 pagesThe Use of Arduino Interface and Date Palm (Phoenix Dactylifera) Seeds in Making An Improvised Air Ionizer-PurifierIJRASETPublicationsNo ratings yet
- An Overview of Popular Deep Learning Methods PDFDocument12 pagesAn Overview of Popular Deep Learning Methods PDFOussama El B'charriNo ratings yet
- Transfer Learning Based Plant Diseases Detection Using ResNet50Document6 pagesTransfer Learning Based Plant Diseases Detection Using ResNet50Madhusmita SahuNo ratings yet
- Template MatchingDocument17 pagesTemplate MatchingShankaranarayanan GopalNo ratings yet
- Iisc Cds BrochureDocument16 pagesIisc Cds Brochurerohitgoyal_ddsNo ratings yet
- Matthias Schonlau, Ph.D. Statistical Learning - Classification Stat441Document30 pagesMatthias Schonlau, Ph.D. Statistical Learning - Classification Stat4411plus12No ratings yet
- Paper-6 Data Mining and Natural Language Processing Methods For Extracting Opinions From Customer ReviewsDocument7 pagesPaper-6 Data Mining and Natural Language Processing Methods For Extracting Opinions From Customer ReviewsRachel WheelerNo ratings yet
- Nature of LanguageDocument6 pagesNature of LanguageSangay Deki100% (2)
- Semi-Supervised Variational Autoencoder For WiFi Indoor LocalizationDocument8 pagesSemi-Supervised Variational Autoencoder For WiFi Indoor Localizationissam sayyafNo ratings yet
- Media Information Literacy Lesson 1Document3 pagesMedia Information Literacy Lesson 1Joan B LangamNo ratings yet