You might also like
- RPA Guide: What is Robotic Process AutomationDocument12 pagesRPA Guide: What is Robotic Process Automationchandra502100% (1)
- Jon Holt - Systems Engineering Demystified - A Practitioner's Handbook For Developing Complex Systems Using A Model-Based Approach-Packt Publishing LTD (2021)Document468 pagesJon Holt - Systems Engineering Demystified - A Practitioner's Handbook For Developing Complex Systems Using A Model-Based Approach-Packt Publishing LTD (2021)Rodrigo CalhauNo ratings yet
- Business Continuity Planning & Disaster Recovery Planning Presentation - v1Document17 pagesBusiness Continuity Planning & Disaster Recovery Planning Presentation - v1frimstarNo ratings yet
- Chapter 4. Everything Can Be AutomatedDocument20 pagesChapter 4. Everything Can Be AutomatedCHUA CHONG SHENNo ratings yet
- A108 Rosenberg SuppDocument10 pagesA108 Rosenberg Suppsabitha sabesanNo ratings yet
- DWT-DCT Iris Recognition Using SOM Neural NetworkDocument7 pagesDWT-DCT Iris Recognition Using SOM Neural Networkprofessor_manojNo ratings yet
- A Security Enhanced Robust Steganography Algorithm For Data HidingDocument9 pagesA Security Enhanced Robust Steganography Algorithm For Data HidingKristen TurnerNo ratings yet
- Paper 422Document9 pagesPaper 422KEREN EVANGELINE I (RA1913011011002)No ratings yet
- An Algorithm For Image Clustering and Compression: T Urk Demird Ok Um Fabrikası A.S . Boz Uy Uk Bilecik-TURKEYDocument13 pagesAn Algorithm For Image Clustering and Compression: T Urk Demird Ok Um Fabrikası A.S . Boz Uy Uk Bilecik-TURKEYEliza CristinaNo ratings yet
- Optimal interval clustering DP methodDocument10 pagesOptimal interval clustering DP methodMaría del Carmen ContrerasNo ratings yet
- Particle Swarm Optimization-Based Functional Link Artificial Neural Network For Medical Image DenoisingDocument7 pagesParticle Swarm Optimization-Based Functional Link Artificial Neural Network For Medical Image DenoisingjenithNo ratings yet
- Research On Face Recognition Based On CNNDocument6 pagesResearch On Face Recognition Based On CNNManju SriNo ratings yet
- Deep Learning Meets Sparse Regularization: A Signal Processing PerspectiveDocument23 pagesDeep Learning Meets Sparse Regularization: A Signal Processing PerspectiveJuan ZarateNo ratings yet
- Basic Network Project ProposalDocument4 pagesBasic Network Project ProposalRey DelatinaNo ratings yet
- Darmstadt Vlsi Design CourseDocument533 pagesDarmstadt Vlsi Design Courseapi-3722592100% (1)
- 2019MAST20029 - Assignment 2Document4 pages2019MAST20029 - Assignment 2leonNo ratings yet
- K-Means Clustering Algorithm and Its Improvement RDocument6 pagesK-Means Clustering Algorithm and Its Improvement REdwardNo ratings yet
- Edgar Osuna Robert Freund Federico Girosi Center For Biological and Computational Learning and Operations Research Center Massachusetts Institute of Technology Cambridge, MA, 02139, U.S.ADocument8 pagesEdgar Osuna Robert Freund Federico Girosi Center For Biological and Computational Learning and Operations Research Center Massachusetts Institute of Technology Cambridge, MA, 02139, U.S.ARanaBilalShahidNo ratings yet
- 1560 Quantum Algorithms For Deep CoDocument36 pages1560 Quantum Algorithms For Deep ColokeshNo ratings yet
- E9 205 - Machine Learning For Signal ProcessingDocument3 pagesE9 205 - Machine Learning For Signal Processingrishi guptaNo ratings yet
- ML DSBA Lab7Document6 pagesML DSBA Lab7Houssam FoukiNo ratings yet
- A Chatterjee, An Introduction To The Proper Orthogonal DecompositionDocument11 pagesA Chatterjee, An Introduction To The Proper Orthogonal DecompositionPiyush HotaNo ratings yet
- K-Means Clustering and Related Algorithms: Ryan P. AdamsDocument16 pagesK-Means Clustering and Related Algorithms: Ryan P. AdamsNafi SiamNo ratings yet
- International Refereed Journal of Engineering and Science (IRJES)Document8 pagesInternational Refereed Journal of Engineering and Science (IRJES)www.irjes.comNo ratings yet
- A Comparison of Extreme Learning Machines and Back-Propagation Trained Feed-Forward Networks Processing The Mnist DatabaseDocument4 pagesA Comparison of Extreme Learning Machines and Back-Propagation Trained Feed-Forward Networks Processing The Mnist DatabaseAnonymous qTIkKTNo ratings yet
- Reinforcement Learning Based Scheduling Algorithm For Optimizing Age of Information in Ultra Reliable Low Latency NetworksDocument6 pagesReinforcement Learning Based Scheduling Algorithm For Optimizing Age of Information in Ultra Reliable Low Latency NetworksMuhammad Nadeem AliNo ratings yet
- EMBC 2022 v2Document5 pagesEMBC 2022 v2WA FANo ratings yet
- Fingerprint Classification Using Kohonen Topologic MapDocument4 pagesFingerprint Classification Using Kohonen Topologic MapMohd Razif ShamsuddinNo ratings yet
- A Comparison of Two Neural Network Architectures For Fast Structural Response PredictionDocument3 pagesA Comparison of Two Neural Network Architectures For Fast Structural Response Predictionhouda khaterNo ratings yet
- A Hardware-Oriented Echo State Network and Its FPGA ImplementationDocument5 pagesA Hardware-Oriented Echo State Network and Its FPGA ImplementationGeraud Russel Goune ChenguiNo ratings yet
- Mathias de Wachter, Kris Demuynck and Dirk Van CompernolleDocument4 pagesMathias de Wachter, Kris Demuynck and Dirk Van CompernolleZia'ul HaqNo ratings yet
- KNN, LVQ, SomDocument37 pagesKNN, LVQ, SomKimberley Rodriguez LopezNo ratings yet
- E9 205 - Machine Learning For Signal ProcessingDocument3 pagesE9 205 - Machine Learning For Signal ProcessingUday GulghaneNo ratings yet
- Artificial Neural Networks (The Tutorial With MATLAB)Document6 pagesArtificial Neural Networks (The Tutorial With MATLAB)DanielNo ratings yet
- Random Projections Asymmetric Quantization 2020Document10 pagesRandom Projections Asymmetric Quantization 2020Jacob EveristNo ratings yet
- Kernel MethodDocument37 pagesKernel MethodNisha KamarajNo ratings yet
- Image Signature: Highlighting Sparse Salient Regions: Xiaodi Hou, Jonathan Harel, and Christof KochDocument8 pagesImage Signature: Highlighting Sparse Salient Regions: Xiaodi Hou, Jonathan Harel, and Christof KochSiddharth ShirodkarNo ratings yet
- A Deep Learning Approach To DNA Sequence Classification: (Ricrizzo, Fiannaca, Larosa, Urso) @pa - Icar.cnr - ItDocument12 pagesA Deep Learning Approach To DNA Sequence Classification: (Ricrizzo, Fiannaca, Larosa, Urso) @pa - Icar.cnr - ItArpita SahaNo ratings yet
- AN Overview Artificial Neural Network Approach AN Overview Artificial Neural Network ApproachDocument34 pagesAN Overview Artificial Neural Network Approach AN Overview Artificial Neural Network ApproachSonaAjithNo ratings yet
- NeurIPS 2020 Timeseries Anomaly Detection Using Temporal Hierarchical One Class Network PaperDocument11 pagesNeurIPS 2020 Timeseries Anomaly Detection Using Temporal Hierarchical One Class Network Paperkai zhaoNo ratings yet
- Ororbia Maze LearningDocument10 pagesOrorbia Maze LearningTom WestNo ratings yet
- Lab ManualDocument13 pagesLab ManualakhilNo ratings yet
- Clutter Simulation Overview: Yawei Liu, Zhiqiang LiDocument5 pagesClutter Simulation Overview: Yawei Liu, Zhiqiang LiShashank MuthaNo ratings yet
- Automatic Detection of Welding Defects Using Deep PDFDocument11 pagesAutomatic Detection of Welding Defects Using Deep PDFahmadNo ratings yet
- A Nulling-Resistor Output Amplifier in The Framework of Heterostructures Based On Nonlinear Partial Differential EquationsDocument20 pagesA Nulling-Resistor Output Amplifier in The Framework of Heterostructures Based On Nonlinear Partial Differential EquationsInternational Journal of Advances in Applied Sciences (IJAAS)No ratings yet
- Fey, Yuen, Weichert - 2020 - Hierarchical Inter-Message Passing For Learning On Molecular GraphsDocument6 pagesFey, Yuen, Weichert - 2020 - Hierarchical Inter-Message Passing For Learning On Molecular Graphsrenly XNNo ratings yet
- Set - 01 (7 Files Merged)Document133 pagesSet - 01 (7 Files Merged)Surya PrakashNo ratings yet
- An Introduction To TransformersDocument8 pagesAn Introduction To TransformersNono NonoNo ratings yet
- CNN: Understanding Convolutional Neural NetworksDocument19 pagesCNN: Understanding Convolutional Neural NetworksHasnain AhmadNo ratings yet
- ICCASM 2010: Identification and Diagnosis of Electrical Fault of Asynchronous Motor Using Wavelet and Neural NetworkDocument3 pagesICCASM 2010: Identification and Diagnosis of Electrical Fault of Asynchronous Motor Using Wavelet and Neural Networkddatdh1No ratings yet
- Machine Learning: Algorithms and Applications: Philip O. OgunbonaDocument29 pagesMachine Learning: Algorithms and Applications: Philip O. OgunbonaNguyễn Hoàng Phương TrầnNo ratings yet
- Lab 05Document14 pagesLab 05Nga V. DaoNo ratings yet
- Digital Arithmetic Using Analog ArraysDocument6 pagesDigital Arithmetic Using Analog ArraysBeru RazaNo ratings yet
- Hamiltonian Quantized Gossip: Mauro Franceschelli, Alessandro Giua, Carla SeatzuDocument15 pagesHamiltonian Quantized Gossip: Mauro Franceschelli, Alessandro Giua, Carla SeatzuEvariste OuattaraNo ratings yet
- CH5530-Simulation Lab: MATLAB Additional Graded Session 01/04/2020Document3 pagesCH5530-Simulation Lab: MATLAB Additional Graded Session 01/04/2020KATTURI SAI RAGHAVA ch19m017No ratings yet
- Matlab Homework Experts 2Document10 pagesMatlab Homework Experts 2Franklin DeoNo ratings yet
- Optimally Rotation-Equivariant DirectionalDocument8 pagesOptimally Rotation-Equivariant DirectionalEloisa PotrichNo ratings yet
- Time series segmentation for mobile context recognitionDocument8 pagesTime series segmentation for mobile context recognitionQiming XieNo ratings yet
- El Moufatich PapemjhjlklkllllllllrDocument9 pagesEl Moufatich PapemjhjlklkllllllllrNeerav AroraNo ratings yet
- Image Fusion Using Various Transforms: IPASJ International Journal of Computer Science (IIJCS)Document8 pagesImage Fusion Using Various Transforms: IPASJ International Journal of Computer Science (IIJCS)International Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Green's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)From EverandGreen's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)No ratings yet
- LocalGLMnet: A Deep Learning Architecture For ActuariesDocument35 pagesLocalGLMnet: A Deep Learning Architecture For Actuariespapatest123No ratings yet
- SSRN Id3547887Document51 pagesSSRN Id3547887lolNo ratings yet
- Unsupervised LearninDocument54 pagesUnsupervised LearninMohamed CHNo ratings yet
- SSRN Id3402687 PDFDocument39 pagesSSRN Id3402687 PDFqqp_shiroNo ratings yet
- SHAP For Actuaries: Explain Any ModelDocument25 pagesSHAP For Actuaries: Explain Any Modelpapatest123No ratings yet
- 13 - Digital Controller DesignDocument22 pages13 - Digital Controller DesignEverton CollingNo ratings yet
- Automatic Control Automatic Control: Dr. Ayman Yousef Dr. Emad SamiDocument41 pagesAutomatic Control Automatic Control: Dr. Ayman Yousef Dr. Emad Samiمحمود السيسىNo ratings yet
- Toward A New ATM Software Safety Assessment MethodologyDocument16 pagesToward A New ATM Software Safety Assessment Methodologyme_idungNo ratings yet
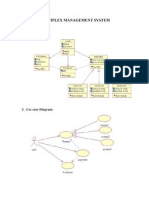
- Multiplex Management System (Uml Diagrams) - KaushalDocument2 pagesMultiplex Management System (Uml Diagrams) - Kaushalkaushalp_27No ratings yet
- Ross Macmillan - The Structure of The Life Course - Standardized - Individualized - Differentiated - Jai Press (2005)Document381 pagesRoss Macmillan - The Structure of The Life Course - Standardized - Individualized - Differentiated - Jai Press (2005)frankmhowellNo ratings yet
- On Sager Reciprocal Relations SignificanceDocument7 pagesOn Sager Reciprocal Relations SignificanceGaurav DharNo ratings yet
- Software Testing Fundamentals QuizDocument123 pagesSoftware Testing Fundamentals Quiz1raju1234No ratings yet
- Table of ContentDocument16 pagesTable of Contentprince8585990503No ratings yet
- Lecture 3.2.1 Procedural DesignDocument8 pagesLecture 3.2.1 Procedural DesignSahil GoyalNo ratings yet
- VTT P422 HRA Methods For Probabilistic Safety AssessmentDocument0 pagesVTT P422 HRA Methods For Probabilistic Safety AssessmentpiolinwallsNo ratings yet
- Transportation Problem 2 MarksDocument3 pagesTransportation Problem 2 Markscheran pandian100% (1)
- All Units Ppts Walker RoyceDocument110 pagesAll Units Ppts Walker RoyceSatyam Singh50% (2)
- 1 5-TutorialforWeek1Document6 pages1 5-TutorialforWeek1rickyNo ratings yet
- Intelligent Instrumentation Course ModulesDocument11 pagesIntelligent Instrumentation Course ModulesMegha Srivastava0% (1)
- Applied Optimal Control: Optimization, Estimation, and ControlDocument3 pagesApplied Optimal Control: Optimization, Estimation, and ControlisraelNo ratings yet
- MIL STD 785RevB PDFDocument88 pagesMIL STD 785RevB PDFPradeep RNo ratings yet
- Analysis of Actuator Raeete Limit Effects On First Order Plus Time de - 2018 - IFACDocument6 pagesAnalysis of Actuator Raeete Limit Effects On First Order Plus Time de - 2018 - IFACsrhtsrtjyjmngcmnuNo ratings yet
- DeltaV SIS With Electronic Marshalling Certificate Rev 1.2 Oct 2 2014Document2 pagesDeltaV SIS With Electronic Marshalling Certificate Rev 1.2 Oct 2 2014Danny PuchaNo ratings yet
- Stochastic source term estimation algorithms and uncertaintyDocument19 pagesStochastic source term estimation algorithms and uncertaintywayneNo ratings yet
- Software Engineering Chapter: Software Testing: Mca Cs1T03Document17 pagesSoftware Engineering Chapter: Software Testing: Mca Cs1T03partha pratim BanerjeeNo ratings yet
- SFC ExamDocument10 pagesSFC Examma.bakeerNo ratings yet
- GoodtechPCS7 enDocument1 pageGoodtechPCS7 enDhp CiaNo ratings yet
- Equalizer Using MatlabDocument11 pagesEqualizer Using Matlabjporras2005No ratings yet
- Plase Plane Analysis: Sakina Fathel XurshidDocument33 pagesPlase Plane Analysis: Sakina Fathel Xurshidsfk1479No ratings yet
- Underwood C. P., "HVAC Control Systems, Modelling Analysis and Design" RoutledgeDocument2 pagesUnderwood C. P., "HVAC Control Systems, Modelling Analysis and Design" Routledgeatif shaikhNo ratings yet
- Software Engineering: Prof. Archana DeshpandeDocument34 pagesSoftware Engineering: Prof. Archana Deshpandesumit_choudhary002No ratings yet