0% found this document useful (0 votes)
143 views12 pagesRegex Special Characters and Classes
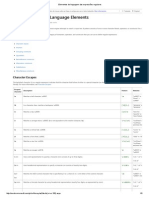
The document describes various character escapes and character classes that are used in regular expressions to match specific characters. It provides examples of escaped characters like \t, \n, \r that match tab, newline, and carriage return characters. It also describes character classes like [aeiou] that match any vowel, and negation classes like [^aeiou] that match any non-vowel. Finally it covers various regex anchors like ^, $, \A, \Z that match the start or end of a string.
Uploaded by
jolzyanthCopyright
© © All Rights Reserved
We take content rights seriously. If you suspect this is your content, claim it here.
Available Formats
Download as PDF, TXT or read online on Scribd
0% found this document useful (0 votes)
143 views12 pagesRegex Special Characters and Classes
The document describes various character escapes and character classes that are used in regular expressions to match specific characters. It provides examples of escaped characters like \t, \n, \r that match tab, newline, and carriage return characters. It also describes character classes like [aeiou] that match any vowel, and negation classes like [^aeiou] that match any non-vowel. Finally it covers various regex anchors like ^, $, \A, \Z that match the start or end of a string.
Uploaded by
jolzyanthCopyright
© © All Rights Reserved
We take content rights seriously. If you suspect this is your content, claim it here.
Available Formats
Download as PDF, TXT or read online on Scribd