You might also like
- Advanced Excel - Excel 2016 DashboardsDocument18 pagesAdvanced Excel - Excel 2016 DashboardsMuhammad AsifNo ratings yet
- SpagoBI TutorialsDocument39 pagesSpagoBI TutorialsShiva RokaNo ratings yet
- Practical Thermal Design of Shell-And-tube Heat ExchangersDocument243 pagesPractical Thermal Design of Shell-And-tube Heat ExchangersPato Banda100% (5)
- Adapt Formula SheetDocument6 pagesAdapt Formula SheetUngoliant101No ratings yet
- Minitab Guide for Statistics AnalysisDocument14 pagesMinitab Guide for Statistics AnalysisNanoManNo ratings yet
- Build advanced Tableau table calculationsDocument14 pagesBuild advanced Tableau table calculationsAnupam VermaNo ratings yet
- The ancient Mayan mathematics systemDocument5 pagesThe ancient Mayan mathematics systemDebby Wura AbiodunNo ratings yet
- Lab Assignment 2 Ms Excel 2 InstructionsDocument2 pagesLab Assignment 2 Ms Excel 2 Instructionssangeet711No ratings yet
- Sailor Rt2048Document94 pagesSailor Rt2048Belha Lozano SanchezNo ratings yet
- Origin Software TutorialsDocument26 pagesOrigin Software TutorialsGideon KipkiruiNo ratings yet
- Metal Casting Full Lecture NotesDocument51 pagesMetal Casting Full Lecture Notesumarnasar_1987105074% (19)
- JMP ManualDocument212 pagesJMP ManualMyk TorresNo ratings yet
- SpreadsheetDocument11 pagesSpreadsheetShiva JK0% (1)
- TableauDocument10 pagesTableauzara khanNo ratings yet
- Bullet Charts: Comparing Measures VisuallyDocument2 pagesBullet Charts: Comparing Measures VisuallyHarik CNo ratings yet
- Problem Set 1Document3 pagesProblem Set 1David MoradiNo ratings yet
- Create Your Own Measures in Power BI DesktopDocument18 pagesCreate Your Own Measures in Power BI DesktopHermann Akouete AkueNo ratings yet
- Graphing 2007Document2 pagesGraphing 2007mikrokosmosNo ratings yet
- Note - SPSS For Customer Analysis 2018Document22 pagesNote - SPSS For Customer Analysis 2018Avinash KumarNo ratings yet
- Mary Swanson Starbucks ProjectDocument5 pagesMary Swanson Starbucks Projectdinesh_as0% (1)
- Fathom TutorialDocument24 pagesFathom TutorialMudassir YousufNo ratings yet
- How To Create A Histogram in ExcelDocument5 pagesHow To Create A Histogram in ExcelAdquisiciones Mayores CADENo ratings yet
- The Cereal Box Problem: A Statistical Problem Involving Expected Value Has Come To Be Known As "The Cereal Box Problem"Document4 pagesThe Cereal Box Problem: A Statistical Problem Involving Expected Value Has Come To Be Known As "The Cereal Box Problem"Sairam PailaNo ratings yet
- Lesson 3 - Introduction To Graphing: Return To Cover PageDocument9 pagesLesson 3 - Introduction To Graphing: Return To Cover PagezaenalkmiNo ratings yet
- KaleidaGraph Quick Start Guide in 38 CharactersDocument16 pagesKaleidaGraph Quick Start Guide in 38 CharactersIsac LavariegaNo ratings yet
- Picturing Distributions With GraphsDocument23 pagesPicturing Distributions With Graphs1ab4cNo ratings yet
- Graphs Excel 2003Document7 pagesGraphs Excel 2003Rick ChatterjeeNo ratings yet
- How To Build MC in ExcelDocument15 pagesHow To Build MC in ExcelPaola VerdiNo ratings yet
- Creating A Positioning MapDocument6 pagesCreating A Positioning MapEmily100% (2)
- Excel Training UnlockedDocument34 pagesExcel Training Unlockedsayantanpaul482No ratings yet
- IT SKILLS FILE Anjali MishraDocument24 pagesIT SKILLS FILE Anjali MishraAnjali MishraNo ratings yet
- Excel TipsDocument4 pagesExcel TipsJayson PintoNo ratings yet
- Activity ExcelDocument9 pagesActivity Excelcaroline_amideast8101No ratings yet
- Create Excel ChartsDocument24 pagesCreate Excel ChartsAvneesh KumarNo ratings yet
- Gretl Skills for Economics 201Document2 pagesGretl Skills for Economics 201greatluckforuNo ratings yet
- Editing Charts in SPSS 14Document12 pagesEditing Charts in SPSS 14ReGielNo ratings yet
- Flowjo-Guide - EMBLDocument11 pagesFlowjo-Guide - EMBLMasse Ak-FaNo ratings yet
- Unsupervised Classfication Using ER MapperDocument9 pagesUnsupervised Classfication Using ER MapperavisenicNo ratings yet
- Student Records and Performance ReportsDocument11 pagesStudent Records and Performance ReportsShekhar AvacNo ratings yet
- Using KyplotDocument14 pagesUsing KyplotAli AbdelrahemNo ratings yet
- Excel Chap 2 Describe DataDocument5 pagesExcel Chap 2 Describe Datasymtgywsq8No ratings yet
- Chap4.Data AnalysisDocument37 pagesChap4.Data Analysistungnguyenquang1306No ratings yet
- Practical File On ": Financial Modelling With Spreadsheets"Document23 pagesPractical File On ": Financial Modelling With Spreadsheets"Swini SinglaNo ratings yet
- Quick Start PDFDocument17 pagesQuick Start PDFRafaelNo ratings yet
- By Microsoft Website: DURATION: 6 Weeks Amount Paid: Yes: Introduction To Data ScienceDocument21 pagesBy Microsoft Website: DURATION: 6 Weeks Amount Paid: Yes: Introduction To Data ScienceVishal AgrawalNo ratings yet
- Tableau Lab Introduction Music SalesDocument4 pagesTableau Lab Introduction Music SalesSAURABH SINGHNo ratings yet
- Fama-French 3-Factor AnalysisDocument39 pagesFama-French 3-Factor AnalysisShihab HasanNo ratings yet
- Electronic Spreadsheet WatermarkDocument10 pagesElectronic Spreadsheet WatermarkjjjdklcfjsdcfNo ratings yet
- Charts: A. Enter DataDocument21 pagesCharts: A. Enter DataKyle DepanteNo ratings yet
- Excel Lab 3 - Sort Filter SubtotalDocument8 pagesExcel Lab 3 - Sort Filter Subtotalpalak2407No ratings yet
- DA LabDocument12 pagesDA Labkumarshravan66712No ratings yet
- Bio353 EXCEL ModuleDocument11 pagesBio353 EXCEL ModulekcbijuNo ratings yet
- Chapter 6 Normal Distibutions: Graphs of Normal Distributions (Section 6.1 of UnderstandableDocument8 pagesChapter 6 Normal Distibutions: Graphs of Normal Distributions (Section 6.1 of UnderstandableAsiongMartinez12No ratings yet
- Plotting Using Originpro 8.: Vytautas AstromskasDocument21 pagesPlotting Using Originpro 8.: Vytautas AstromskasFallNo ratings yet
- Microsoft Excel Quiz1Document5 pagesMicrosoft Excel Quiz1mohsin ahmadNo ratings yet
- Presentation 2Document34 pagesPresentation 2Zeleke GeresuNo ratings yet
- Excel Statistics & SPSS GuideDocument32 pagesExcel Statistics & SPSS GuideUdbhav SharmaNo ratings yet
- Exponential SmoothingDocument2 pagesExponential SmoothingarnabpramanikNo ratings yet
- Mba Unit5Document19 pagesMba Unit5balrampal500No ratings yet
- Use of Pivot Table Scout InventoryDocument13 pagesUse of Pivot Table Scout Inventorymoira libresNo ratings yet
- Note - SPSS For Customer AnalysisDocument18 pagesNote - SPSS For Customer Analysisصالح الشبحيNo ratings yet
- Grade 11 - Week 8 - NotesDocument2 pagesGrade 11 - Week 8 - NotesRoshinie SukhrajNo ratings yet
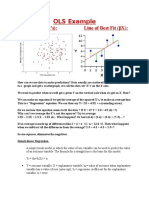
- OLS Example: Sample Data (X's) : Line of Best Fit (βX)Document3 pagesOLS Example: Sample Data (X's) : Line of Best Fit (βX)Stephen OndiekNo ratings yet
- How To Explort Gerber Files From KicadDocument10 pagesHow To Explort Gerber Files From KicadjackNo ratings yet
- Mensuration: Area of A TrapeziumDocument61 pagesMensuration: Area of A TrapeziumSahil EduNo ratings yet
- Manual M1Document77 pagesManual M1odbilegNo ratings yet
- OnTarget ARA Software InstructionsDocument7 pagesOnTarget ARA Software InstructionsMpmendoNo ratings yet
- ThermodynamicsDocument9 pagesThermodynamicssamir boseNo ratings yet
- January 2019 Paper 2Document16 pagesJanuary 2019 Paper 2Anderson AlfredNo ratings yet
- ps08 sp12 PDFDocument8 pagesps08 sp12 PDFQ_TNo ratings yet
- Electric Towing Tractors: NTT/NTF SeriesDocument5 pagesElectric Towing Tractors: NTT/NTF SeriesВася100% (1)
- Mineral-Insulated Thermocouples According To DIN 43710 and DIN EN 60584Document11 pagesMineral-Insulated Thermocouples According To DIN 43710 and DIN EN 60584Veryco BudiantoNo ratings yet
- Jurnalratna Haryo Soni2016Document14 pagesJurnalratna Haryo Soni2016hafizhmmNo ratings yet
- Detecting deception through languageDocument15 pagesDetecting deception through languageSara EldalyNo ratings yet
- Soil Organic Carbon: Relating The Walkley-Black Wet Oxidation Method To Loss On Ignition and Clay ContentDocument8 pagesSoil Organic Carbon: Relating The Walkley-Black Wet Oxidation Method To Loss On Ignition and Clay ContentAmin MojiriNo ratings yet
- Needle Roller Bearing Combined TypeDocument5 pagesNeedle Roller Bearing Combined TypeNemish KanwarNo ratings yet
- EGCC ChartsDocument51 pagesEGCC Chartsmk45a0% (1)
- D5G6 DatasheetDocument3 pagesD5G6 DatasheetchichedemorenoNo ratings yet
- Power Wave I400: MIG, Pulsed-MIG, Flux-Cored, Metal-Cored, TIG (Lift Start Only)Document6 pagesPower Wave I400: MIG, Pulsed-MIG, Flux-Cored, Metal-Cored, TIG (Lift Start Only)nobamoNo ratings yet
- Topographic Map of Mount NeboDocument1 pageTopographic Map of Mount NeboHistoricalMapsNo ratings yet
- Priority List JEEDocument3 pagesPriority List JEE6r5x5znb8bNo ratings yet
- 124 KW 166 HP at 2000 RPM: Net HorsepowerDocument12 pages124 KW 166 HP at 2000 RPM: Net HorsepowerAwanNo ratings yet
- Chapter 4Document100 pagesChapter 4khgvouy hvogyflNo ratings yet
- NadIR v1.0.0 User Manual PDFDocument10 pagesNadIR v1.0.0 User Manual PDFPaul GarridoNo ratings yet
- Application of Neutralization Titrations for Acid-Base AnalysisDocument21 pagesApplication of Neutralization Titrations for Acid-Base AnalysisAdrian NavarraNo ratings yet
- Dyno ShortcutsDocument9 pagesDyno ShortcutsJordy CinqvalNo ratings yet
- Forming Project ManualDocument4 pagesForming Project ManualNikos VaxevanidisNo ratings yet
- Yokogawa CVP - Old.Document11 pagesYokogawa CVP - Old.Karthikeya Rao KNo ratings yet