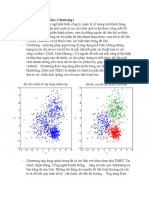
You might also like
- Tìm Hiểu Và Thử Nghiệm Thuật Toán Khai Phá Dữ Liệu GspDocument29 pagesTìm Hiểu Và Thử Nghiệm Thuật Toán Khai Phá Dữ Liệu GspMan EbookNo ratings yet
- Lam Ngoc Len - Df20tt476 - MSSV - 140120103Document6 pagesLam Ngoc Len - Df20tt476 - MSSV - 140120103fgngNo ratings yet
- Data MiningDocument4 pagesData Miningahuyduy.69No ratings yet
- Bài mẫu khai phá 2Document27 pagesBài mẫu khai phá 2nguyenanhbim6No ratings yet
- Áp dụng kỹ thuật phân tích dữ liệu trực tuyến olap phục vụ công tác quản lý điều hành (tt)Document19 pagesÁp dụng kỹ thuật phân tích dữ liệu trực tuyến olap phục vụ công tác quản lý điều hành (tt)Nghia NguyenNo ratings yet
- Tiểu Luận - "Áp Dụng Kỹ Thuật Phân Tích Dữ Liệu Trực Tuyến (OLAP) Phục Vụ Công Tác Quản Lý Và Điều Hành - 789893Document24 pagesTiểu Luận - "Áp Dụng Kỹ Thuật Phân Tích Dữ Liệu Trực Tuyến (OLAP) Phục Vụ Công Tác Quản Lý Và Điều Hành - 789893Nguyen khanhNo ratings yet
- Chuyên đề CNTTDocument46 pagesChuyên đề CNTTdomanhson2608No ratings yet
- Báo cáo Khai phá dữ liệuDocument22 pagesBáo cáo Khai phá dữ liệuTrường NguyễnNo ratings yet
- 1. Phân Cụm Dữ Liệu (Clustering)Document10 pages1. Phân Cụm Dữ Liệu (Clustering)TiếnNo ratings yet
- TT LV THS TranThiThuy 2013Document26 pagesTT LV THS TranThiThuy 2013hunghiveNo ratings yet
- Chuong 1 - Tong Quan Ve KPDLDocument43 pagesChuong 1 - Tong Quan Ve KPDLgiaanh0810No ratings yet
- KPDL DiamondDocument20 pagesKPDL DiamondThi Xuan Rin LeNo ratings yet
- Bài Tập Lớn Kết Thúc Học Phần Khai Phá Dữ LiệuDocument22 pagesBài Tập Lớn Kết Thúc Học Phần Khai Phá Dữ LiệuTam Nguyen ThiNo ratings yet
- Trường Đại Học Kinh Tế Tp.Hcm: Bộ Giáo Dục Và Đào TạoDocument25 pagesTrường Đại Học Kinh Tế Tp.Hcm: Bộ Giáo Dục Và Đào TạoHIEN TRAN THI THUNo ratings yet
- Khai Pha-1Document29 pagesKhai Pha-1Pham Van MinhNo ratings yet
- TỔNG QUAN VỀ KHAI PHÁ DỮ LIỆUDocument23 pagesTỔNG QUAN VỀ KHAI PHÁ DỮ LIỆUNC musicNo ratings yet
- Baitapbuoi 1Document5 pagesBaitapbuoi 1shark fizzNo ratings yet
- Khai phá dữ liệuDocument25 pagesKhai phá dữ liệuVu Tien DucNo ratings yet
- KPDLDocument19 pagesKPDLVũ MạnhNo ratings yet
- Lý thuyếtDocument5 pagesLý thuyếtkhanhndfx21606No ratings yet
- 74779-Điều văn bản-180407-1-10-20221221Document9 pages74779-Điều văn bản-180407-1-10-20221221Nguyễn Văn Quân - D16HTTMDTNo ratings yet
- KHDL Nhóm 5Document18 pagesKHDL Nhóm 5THU NGUYỄN THỊ NGỌCNo ratings yet
- Thuật toán k-Means và cách cài đặtDocument22 pagesThuật toán k-Means và cách cài đặtThu ThyNo ratings yet
- PACuong TIM HIEU THUAT TOAN APRIORIDocument19 pagesPACuong TIM HIEU THUAT TOAN APRIORIThương PhanNo ratings yet
- DataMining - Chuong 2Document14 pagesDataMining - Chuong 2Ngọc Liên LêNo ratings yet
- Do An Phan Cum Du LieuDocument100 pagesDo An Phan Cum Du LieuSeven LoveNo ratings yet
- Bài giữa kì điều tra sốDocument60 pagesBài giữa kì điều tra sốNguễn HânNo ratings yet
- KHDLDocument45 pagesKHDLduyNo ratings yet
- Các Bài Toán Khai Phá Dữ Liệu Và Ứng Dụng Của Khai Phá Dữ LiệuDocument21 pagesCác Bài Toán Khai Phá Dữ Liệu Và Ứng Dụng Của Khai Phá Dữ LiệuMan EbookNo ratings yet
- Tailieuxanh Tieu Luan Datamining 3908Document27 pagesTailieuxanh Tieu Luan Datamining 3908HẠNH CAO THỊ MỸNo ratings yet
- Báo cáo khai phá dữ liệuDocument24 pagesBáo cáo khai phá dữ liệuSARA TV100% (1)
- KhaiphadulieuDocument16 pagesKhaiphadulieuKhoa LeeNo ratings yet
- PTDLDocument360 pagesPTDLYenNo ratings yet
- Khai phá dữ liệuDocument44 pagesKhai phá dữ liệucute panda channelNo ratings yet
- Chủ đề 3 Nhóm TNPLDocument19 pagesChủ đề 3 Nhóm TNPLTung PhamNo ratings yet
- 231 - 71miss40233 - 02 - Kiểm Tra Cuối KỳDocument25 pages231 - 71miss40233 - 02 - Kiểm Tra Cuối KỳThúy NgânNo ratings yet
- Ung Dung Phan Cum Du Lieu Trong Phan Tich Danh Gia Ket Qua Diem Cua Hoc SinhDocument26 pagesUng Dung Phan Cum Du Lieu Trong Phan Tich Danh Gia Ket Qua Diem Cua Hoc SinhNhư Ý Đặng VạnNo ratings yet
- Nghiên Cứu Ứng Dụng Luật Kết Hợp Trong Khai Phá Dữ Liệu Phục Vụ Quản Lý Vật Tư, Thiết Bị Trường Trung Học Phổ ThôngDocument26 pagesNghiên Cứu Ứng Dụng Luật Kết Hợp Trong Khai Phá Dữ Liệu Phục Vụ Quản Lý Vật Tư, Thiết Bị Trường Trung Học Phổ Thônglan anh nguyễnNo ratings yet
- Data AnalysisDocument11 pagesData AnalysisVan AnhNo ratings yet
- Nhom 7Document24 pagesNhom 7Nguyên ThắngNo ratings yet
- (123doc) - Tim-Hieu-Thuat-Toan-Som-Trong-Gom-Cum-Du-LieuDocument33 pages(123doc) - Tim-Hieu-Thuat-Toan-Som-Trong-Gom-Cum-Du-LieuPhúc TrầnNo ratings yet
- Phân Cụm Dữ Liệu Trong DatamingDocument48 pagesPhân Cụm Dữ Liệu Trong DatamingMan EbookNo ratings yet
- Tailieuxanh Quan Ly Diem 7077Document7 pagesTailieuxanh Quan Ly Diem 7077Lê Minh TriệuNo ratings yet
- Ôn Tập Công Nghệ 4.0Document13 pagesÔn Tập Công Nghệ 4.0Quan Phương LêNo ratings yet
- DataMining - Chuong 3Document17 pagesDataMining - Chuong 3Ngọc Liên LêNo ratings yet
- PhamQuangTrung TranQuangDuy KhaiphadulieuDocument24 pagesPhamQuangTrung TranQuangDuy KhaiphadulieuDuy Tran100% (1)
- Chuong1 Phan2Document58 pagesChuong1 Phan2Lưu Ngọc Anh DươngNo ratings yet
- Data Warehouse-Nhom 7Document33 pagesData Warehouse-Nhom 7Sương GiangNo ratings yet
- Báo Cáo KPDLDocument66 pagesBáo Cáo KPDLHữu Thọ TrầnNo ratings yet
- Bao Cao Bai Tap Lon Mon Khai Pha Du Lieu Phan Lop Du Lieu So Bang Giai Thuat K NNDocument19 pagesBao Cao Bai Tap Lon Mon Khai Pha Du Lieu Phan Lop Du Lieu So Bang Giai Thuat K NNSơn Trần ThanhNo ratings yet
- Trường Đại học CNTT - Khoa Hệ thống thông tinDocument23 pagesTrường Đại học CNTT - Khoa Hệ thống thông tinTiến Hồ MạnhNo ratings yet
- KHAI PHÁ DỮ LIỆU - nhom3 - Hiếu - Lợi - LuânDocument66 pagesKHAI PHÁ DỮ LIỆU - nhom3 - Hiếu - Lợi - LuânNguyen Huong GiangNo ratings yet
- Tailieuchung 5 8653Document61 pagesTailieuchung 5 8653hieu62605No ratings yet
- TRQĐDocument26 pagesTRQĐmi miNo ratings yet
- MI3031 Chương1Document31 pagesMI3031 Chương1Dinhthai NguyenNo ratings yet
- Chương 1 - Tổng Quan Về PTDLDocument24 pagesChương 1 - Tổng Quan Về PTDLMai LehoangNo ratings yet
- Tieu Luan KHDL-Nhom 5Document50 pagesTieu Luan KHDL-Nhom 5Nguyễn Đức MinhNo ratings yet
- Báo Cáo MiningDocument33 pagesBáo Cáo MiningViệt AnhNo ratings yet
- Giaotrinh HeThongSoDocument57 pagesGiaotrinh HeThongSoĐen CừuNo ratings yet
- Mơ MơDocument94 pagesMơ MơĐen CừuNo ratings yet
- Luat CNTTDocument21 pagesLuat CNTTĐen CừuNo ratings yet
- Wu2018 MơiDocument10 pagesWu2018 MơiĐen CừuNo ratings yet
- Group 02Document10 pagesGroup 02Đen CừuNo ratings yet
- Wireless Communications Andrea Goldsmith, Stanford University-300-572Document273 pagesWireless Communications Andrea Goldsmith, Stanford University-300-572Đen CừuNo ratings yet
- 14 09 2022 02 12 43 Duancuoikhoa BCDocument4 pages14 09 2022 02 12 43 Duancuoikhoa BCĐen CừuNo ratings yet
- BÁO CÁO THÍ NGHIỆM- HÓA HỌC LIPIDDocument3 pagesBÁO CÁO THÍ NGHIỆM- HÓA HỌC LIPIDĐen Cừu100% (1)