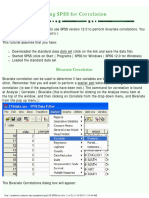
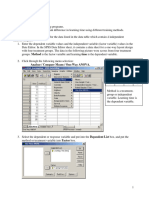
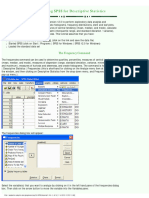
You might also like
- Hypothesis TestingDocument61 pagesHypothesis TestingAlex SPNo ratings yet
- Intro of Hypothesis TestingDocument66 pagesIntro of Hypothesis TestingDharyl BallartaNo ratings yet
- Statistics: Hypothesis TestingDocument32 pagesStatistics: Hypothesis TestingDaisy Rodriguez AcasNo ratings yet
- 06ESL37 Analog Electronics Lab MANUALDocument70 pages06ESL37 Analog Electronics Lab MANUALSan AngadiNo ratings yet
- API 571 Quick ReviewDocument32 pagesAPI 571 Quick ReviewMahmoud Hagag100% (1)
- Hypothesis Tests & Mann-Whitney U-TestDocument2 pagesHypothesis Tests & Mann-Whitney U-Testlastjoe71No ratings yet
- The Fat CatsDocument7 pagesThe Fat CatsMarilo Jimenez AlgabaNo ratings yet
- Inferential StatisticsDocument48 pagesInferential StatisticsNylevon78% (9)
- Introduction of Testing of Hypothesis NotesDocument4 pagesIntroduction of Testing of Hypothesis NotesThammana Nishithareddy100% (1)
- EV Connect What Is EVSE White PaperDocument13 pagesEV Connect What Is EVSE White PaperEV ConnectNo ratings yet
- Activity 5Document28 pagesActivity 5Hermis Ramil TabhebzNo ratings yet
- CSA Pre-Test QuestionnaireDocument16 pagesCSA Pre-Test Questionnairedaniella balaquitNo ratings yet
- 08 A330 Ata 35Document32 pages08 A330 Ata 35Owen100% (1)
- Chapter 6 The Statistical ToolsDocument38 pagesChapter 6 The Statistical ToolsAllyssa Faye PartosaNo ratings yet
- Portable Manual - DIG-360Document44 pagesPortable Manual - DIG-360waelmansour25No ratings yet
- EDUR8132 IntroductoryNotes 17august2010Document5 pagesEDUR8132 IntroductoryNotes 17august2010Nazia SyedNo ratings yet
- 6 Inferential Statistics VI - May 12 2014Document40 pages6 Inferential Statistics VI - May 12 2014Bijay ThapaNo ratings yet
- Chi SquareDocument7 pagesChi SquareLori JeffriesNo ratings yet
- Hypothesis Testing: Applied Statistics - Lesson 8Document6 pagesHypothesis Testing: Applied Statistics - Lesson 8PHO AntNo ratings yet
- I. OBJECTIVES-WPS OfficeDocument6 pagesI. OBJECTIVES-WPS OfficeJohairah Pagayao OmarNo ratings yet
- Guide For Statistical Analysis For IA - Simple VerDocument20 pagesGuide For Statistical Analysis For IA - Simple VerSapreen KaurNo ratings yet
- Nominal MeasurementDocument9 pagesNominal MeasurementAnshul SharmaNo ratings yet
- Lesson 6.1 Hypothesis Testing One Sample TestDocument14 pagesLesson 6.1 Hypothesis Testing One Sample TestJeline Flor EugenioNo ratings yet
- Day 11 & 12 - Hypothesis TestingDocument6 pagesDay 11 & 12 - Hypothesis TestingLianne SedurifaNo ratings yet
- Advanced Educational Statistics - Edu 901CDocument12 pagesAdvanced Educational Statistics - Edu 901CSolomon kiplimoNo ratings yet
- Notes5b TwosamplesttestDocument28 pagesNotes5b TwosamplesttestNazia SyedNo ratings yet
- CH 9 Hypothesis Testing 40-41-2 4Document24 pagesCH 9 Hypothesis Testing 40-41-2 4Ahmed MujtabaNo ratings yet
- Inferential Statistics Masters Updated 1Document27 pagesInferential Statistics Masters Updated 1Joebert CalagosNo ratings yet
- NOTES On UNIT 3 HypothesisDocument3 pagesNOTES On UNIT 3 HypothesispriyankashrivatavaNo ratings yet
- Inferential Statistics PDFDocument48 pagesInferential Statistics PDFBrenda BanderadoNo ratings yet
- Master of Business Administration - MBA Semester 3 MB0034 Research Methodology - 3 Credits BKID: B0800 Assignment Set-1Document17 pagesMaster of Business Administration - MBA Semester 3 MB0034 Research Methodology - 3 Credits BKID: B0800 Assignment Set-1Vishal HandaragalNo ratings yet
- 4 Hypothesis Testing in The Multiple Regression ModelDocument49 pages4 Hypothesis Testing in The Multiple Regression ModelAbhishek RamNo ratings yet
- The Different Steps in Testing of Hypothesis PDFDocument5 pagesThe Different Steps in Testing of Hypothesis PDFSankarNo ratings yet
- SM 38Document19 pagesSM 38ayushNo ratings yet
- Statistical Inference Part IDocument36 pagesStatistical Inference Part ISherlcok HolmesNo ratings yet
- 1.3 Type I Error Type II Error and Power PDFDocument11 pages1.3 Type I Error Type II Error and Power PDFSatish Kumar RawalNo ratings yet
- محاضرة اولى احصاءDocument16 pagesمحاضرة اولى احصاءniiishaan97No ratings yet
- Session 08Document2 pagesSession 08Osman Gani TalukderNo ratings yet
- Lec 7 - Hypothesis TestingDocument29 pagesLec 7 - Hypothesis TestingABDUR -No ratings yet
- Master of Business Administration - MBA Semester 3 MB0050 Research Methodology Assignment Set-1Document9 pagesMaster of Business Administration - MBA Semester 3 MB0050 Research Methodology Assignment Set-1Abhishek JainNo ratings yet
- Research Methodology Hypothesis and Testing: by Shreya Bhagwat & Varun KumarDocument22 pagesResearch Methodology Hypothesis and Testing: by Shreya Bhagwat & Varun KumarVarun KumarNo ratings yet
- Research Methodology: Q1. Give Examples of Specific Situations That Would Call For The Following Types ofDocument17 pagesResearch Methodology: Q1. Give Examples of Specific Situations That Would Call For The Following Types ofersaini83No ratings yet
- Gonzlez HypotestTutorial WebpagesDocument12 pagesGonzlez HypotestTutorial WebpagesYifeng ZhouNo ratings yet
- Statistics Data Analysis and Decision Modeling 5th Edition Evans Solutions Manual 1Document32 pagesStatistics Data Analysis and Decision Modeling 5th Edition Evans Solutions Manual 1jillnguyenoestdiacfq100% (27)
- Hypothesis Testing Basic Terminology:: PopulationDocument19 pagesHypothesis Testing Basic Terminology:: PopulationRahat KhanNo ratings yet
- Hypothesis Testing EnvironmentDocument12 pagesHypothesis Testing EnvironmentMusab OmerNo ratings yet
- BCA 232 Testing of HypothesesDocument80 pagesBCA 232 Testing of HypothesesAzarudheen S StatisticsNo ratings yet
- Week 1-2 Stats and ProbDocument23 pagesWeek 1-2 Stats and ProbName DeldaNo ratings yet
- Research Questions, Variables, and HypothesesDocument60 pagesResearch Questions, Variables, and HypothesesAsk NameNo ratings yet
- 01 - Introduction To Hypothesis TestingDocument4 pages01 - Introduction To Hypothesis TestingChristian CalaNo ratings yet
- CH12Document34 pagesCH12Walid Abd-AllahNo ratings yet
- Chi-Square Test For Feature Selection in Machine LearningDocument15 pagesChi-Square Test For Feature Selection in Machine LearningAmit PhulwaniNo ratings yet
- Statistical Analysis Dr. ShamsuddinDocument62 pagesStatistical Analysis Dr. ShamsuddinHanee Farzana HizaddinNo ratings yet
- Stat 130n-Answers To LAs in Lessons 5.1-5.3Document18 pagesStat 130n-Answers To LAs in Lessons 5.1-5.3Faith GarfinNo ratings yet
- MB 0034-1Document10 pagesMB 0034-1mehulctxNo ratings yet
- Tutorial Week 5: Hypotheses and Statistical Testing Part A. HypothesesDocument5 pagesTutorial Week 5: Hypotheses and Statistical Testing Part A. Hypotheses励宛欣No ratings yet
- Chapter 6Document16 pagesChapter 6Serenity ManaloNo ratings yet
- ACCTY 312 - Lesson 4Document9 pagesACCTY 312 - Lesson 4shsNo ratings yet
- Chapter 3 HTDocument20 pagesChapter 3 HTmuslim yasinNo ratings yet
- Chapter 5.test of HypDocument47 pagesChapter 5.test of HypMarianne MabiniNo ratings yet
- PS-UNIT5-Test of HypothesisDocument95 pagesPS-UNIT5-Test of HypothesisSK Endless SoulNo ratings yet
- Research Questions, Variables, and HypothesesDocument60 pagesResearch Questions, Variables, and HypothesesSaleh Muhammed BareachNo ratings yet
- Hypothesis TestingDocument86 pagesHypothesis TestingMohammed AdusNo ratings yet
- 4 Hypothesis Testing in The Multiple Regression ModelDocument49 pages4 Hypothesis Testing in The Multiple Regression Modelhirak7No ratings yet
- PH D Agric EconomicsSeminarinAdvancedResearchMethodsHypothesistestingDocument24 pagesPH D Agric EconomicsSeminarinAdvancedResearchMethodsHypothesistestingJummy Dr'chebatickNo ratings yet
- 0 Data Entry BDocument5 pages0 Data Entry BNazia SyedNo ratings yet
- 0 T-Tests ADocument17 pages0 T-Tests ANazia SyedNo ratings yet
- Edur 8131 Notes 5 T TestDocument23 pagesEdur 8131 Notes 5 T TestNazia SyedNo ratings yet
- 1 Correlation BDocument3 pages1 Correlation BNazia SyedNo ratings yet
- 0 Data Entry ADocument7 pages0 Data Entry ANazia SyedNo ratings yet
- Edur 8131 Notes 2 Normal Standard ScoresDocument9 pagesEdur 8131 Notes 2 Normal Standard ScoresNazia SyedNo ratings yet
- 0 Anova Oneway ADocument10 pages0 Anova Oneway ANazia SyedNo ratings yet
- Edur 8131 Notes 7 Chi SquareDocument16 pagesEdur 8131 Notes 7 Chi SquareNazia SyedNo ratings yet
- 1 Frequencies BDocument3 pages1 Frequencies BNazia SyedNo ratings yet
- 0 Correlation ADocument5 pages0 Correlation ANazia SyedNo ratings yet
- 0 Regression ADocument9 pages0 Regression ANazia SyedNo ratings yet
- Fraas Johnson Neyman Interaction ProcedureDocument11 pagesFraas Johnson Neyman Interaction ProcedureNazia SyedNo ratings yet
- Homework 2 Correlated Ttests AnswersDocument2 pagesHomework 2 Correlated Ttests AnswersNazia SyedNo ratings yet
- Edur 8131 Graphical Display ExamplesDocument9 pagesEdur 8131 Graphical Display ExamplesNazia SyedNo ratings yet
- Edur 8131 Notes 6 CorrelationDocument25 pagesEdur 8131 Notes 6 CorrelationNazia SyedNo ratings yet
- 1 Anova Oneway BDocument3 pages1 Anova Oneway BNazia SyedNo ratings yet
- 1 Stemleaf CDocument3 pages1 Stemleaf CNazia SyedNo ratings yet
- 1 Graphs CDocument30 pages1 Graphs CNazia SyedNo ratings yet
- EDUR 8131 Notes 8a Simple RegressionDocument19 pagesEDUR 8131 Notes 8a Simple RegressionNazia SyedNo ratings yet
- Edur 8131 Notes 4 (Revised) Hypothesis Testing and One Sample Z TestDocument16 pagesEdur 8131 Notes 4 (Revised) Hypothesis Testing and One Sample Z TestNazia SyedNo ratings yet
- Correlated Samples T-Test ExerciseDocument2 pagesCorrelated Samples T-Test ExerciseNazia SyedNo ratings yet
- Edur 8131 Notes 3 Statistical InferenceDocument9 pagesEdur 8131 Notes 3 Statistical InferenceNazia SyedNo ratings yet
- Engqvist ANCOVA Interaction TermDocument5 pagesEngqvist ANCOVA Interaction TermNazia SyedNo ratings yet
- 1 Frequencies ADocument8 pages1 Frequencies ANazia SyedNo ratings yet
- EDUR 8131 Notes 8b Multiple RegressionDocument16 pagesEDUR 8131 Notes 8b Multiple RegressionNazia SyedNo ratings yet
- HypothesesDocument11 pagesHypothesesNazia SyedNo ratings yet
- Homework 1 Ttests AnswersDocument2 pagesHomework 1 Ttests AnswersNazia SyedNo ratings yet
- RegressionResults1 Myles DissertatonTablesDocument2 pagesRegressionResults1 Myles DissertatonTablesNazia SyedNo ratings yet
- Chi Square ExerciseDocument5 pagesChi Square ExerciseNazia SyedNo ratings yet
- Pahlavi PoemDocument9 pagesPahlavi PoemBatsuren BarangasNo ratings yet
- The Russian Review - 2020 - ROTH EY - Listening Out Listening For Listening in Cold War Radio Broadcasting and The LateDocument22 pagesThe Russian Review - 2020 - ROTH EY - Listening Out Listening For Listening in Cold War Radio Broadcasting and The LateOkawa TakeshiNo ratings yet
- Catalogue Mp200Document33 pagesCatalogue Mp200Adrian TudorNo ratings yet
- MC 1Document109 pagesMC 1ricogamingNo ratings yet
- Yamaha rx-v395 v395rds htr-5130 5130rdsDocument55 pagesYamaha rx-v395 v395rds htr-5130 5130rdsdomino632776No ratings yet
- Department of Mechanical EnginneringDocument11 pagesDepartment of Mechanical EnginneringViraj SukaleNo ratings yet
- The Lower Parts of The Lock Stitch Sewing MachineDocument3 pagesThe Lower Parts of The Lock Stitch Sewing MachineHazelAnnCandelarioVitug20% (5)
- Quarter 4 - Week 1Document44 pagesQuarter 4 - Week 1Sol Taha MinoNo ratings yet
- 1753-Article Text-39640-3-10-20220815Document9 pages1753-Article Text-39640-3-10-20220815Inah SaritaNo ratings yet
- DST Tmpm370fydfg-Tde en 21751Document498 pagesDST Tmpm370fydfg-Tde en 21751trân văn tuấnNo ratings yet
- CJR Fisika Umum IDocument17 pagesCJR Fisika Umum IveronikaNo ratings yet
- Earthing ResistanceDocument4 pagesEarthing ResistanceNeeraj Purohit100% (1)
- TamasDocument180 pagesTamaslike 2No ratings yet
- 2020 Landfill Capacity Calculation Work SheetDocument4 pages2020 Landfill Capacity Calculation Work SheetLYNo ratings yet
- CA InsideDocument1 pageCA InsideariasnomercyNo ratings yet
- An Infallible JusticeDocument7 pagesAn Infallible JusticeMani Gopal DasNo ratings yet
- 2006 - Dong Et Al - Bulk and Dispersed Aqueous Phase Behavior of PhytantriolDocument7 pages2006 - Dong Et Al - Bulk and Dispersed Aqueous Phase Behavior of PhytantriolHe ZeeNo ratings yet
- BIOC32 Practice QuestionsDocument7 pagesBIOC32 Practice QuestionsLydia DuncanNo ratings yet
- Ligamentele LargiDocument2 pagesLigamentele LargiIoana IonicaNo ratings yet
- Recipes G.garvin Copy1 Scribd 5Document7 pagesRecipes G.garvin Copy1 Scribd 5Peggy Bracken StagnoNo ratings yet
- Mits Chocolates: Let The Life Be More Sweet'Document30 pagesMits Chocolates: Let The Life Be More Sweet'Azaz NathaniNo ratings yet
- Quran On GeologyDocument10 pagesQuran On GeologyMM NabeelNo ratings yet
- Transportation ProblemDocument4 pagesTransportation ProblemPrejit RadhakrishnaNo ratings yet